Jak powolna jest konkatenacja strun Pythona vs. str.dołączyć?
W wyniku komentarzy w mojej odpowiedzi na ten wątek , chciałem się dowiedzieć jaka jest różnica prędkości między operatorem += a ''.join()
Więc jakie jest porównanie prędkości między tymi dwoma?
5 answers
From: Efektywna Konkatenacja Ciągu
Metoda 1:
def method1():
out_str = ''
for num in xrange(loop_count):
out_str += 'num'
return out_str
Metoda 4:
def method4():
str_list = []
for num in xrange(loop_count):
str_list.append('num')
return ''.join(str_list)
Teraz zdaję sobie sprawę, że nie są one ściśle reprezentatywne, a czwarta metoda dołącza się do listy przed iteracją i dołączeniem każdego elementu, ale jest to uczciwa wskazówka.
Łączenie łańcuchów jest znacznie szybsze niż konkatenacja.
Dlaczego? Ciągi są niezmienne i nie mogą być zmieniane na miejscu. Aby zmienić jedną, należy utworzyć nową reprezentację (konkatenacja tych dwóch).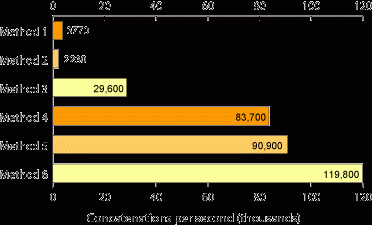
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-12-06 16:15:42
Mój oryginalny kod był zły, wygląda na to, że + konkatenacja jest zwykle szybsza (szczególnie w nowszych wersjach Pythona na nowszym sprzęcie)
Czasy są następujące:
Iterations: 1,000,000
Python 3.3 na Windows 7, Core i7
String of len: 1 took: 0.5710 0.2880 seconds
String of len: 4 took: 0.9480 0.5830 seconds
String of len: 6 took: 1.2770 0.8130 seconds
String of len: 12 took: 2.0610 1.5930 seconds
String of len: 80 took: 10.5140 37.8590 seconds
String of len: 222 took: 27.3400 134.7440 seconds
String of len: 443 took: 52.9640 170.6440 seconds
Python 2.7 Na Windows 7, Core i7
String of len: 1 took: 0.7190 0.4960 seconds
String of len: 4 took: 1.0660 0.6920 seconds
String of len: 6 took: 1.3300 0.8560 seconds
String of len: 12 took: 1.9980 1.5330 seconds
String of len: 80 took: 9.0520 25.7190 seconds
String of len: 222 took: 23.1620 71.3620 seconds
String of len: 443 took: 44.3620 117.1510 seconds
Na Linux Mint, Python 2.7, jakiś wolniejszy procesor
String of len: 1 took: 1.8840 1.2990 seconds
String of len: 4 took: 2.8394 1.9663 seconds
String of len: 6 took: 3.5177 2.4162 seconds
String of len: 12 took: 5.5456 4.1695 seconds
String of len: 80 took: 27.8813 19.2180 seconds
String of len: 222 took: 69.5679 55.7790 seconds
String of len: 443 took: 135.6101 153.8212 seconds
A oto kod:
from __future__ import print_function
import time
def strcat(string):
newstr = ''
for char in string:
newstr += char
return newstr
def listcat(string):
chars = []
for char in string:
chars.append(char)
return ''.join(chars)
def test(fn, times, *args):
start = time.time()
for x in range(times):
fn(*args)
return "{:>10.4f}".format(time.time() - start)
def testall():
strings = ['a', 'long', 'longer', 'a bit longer',
'''adjkrsn widn fskejwoskemwkoskdfisdfasdfjiz oijewf sdkjjka dsf sdk siasjk dfwijs''',
'''this is a really long string that's so long
it had to be triple quoted and contains lots of
superflous characters for kicks and gigles
@!#(*_#)(*$(*!#@&)(*E\xc4\x32\xff\x92\x23\xDF\xDFk^%#$!)%#^(*#''',
'''I needed another long string but this one won't have any new lines or crazy characters in it, I'm just going to type normal characters that I would usually write blah blah blah blah this is some more text hey cool what's crazy is that it looks that the str += is really close to the O(n^2) worst case performance, but it looks more like the other method increases in a perhaps linear scale? I don't know but I think this is enough text I hope.''']
for string in strings:
print("String of len:", len(string), "took:", test(listcat, 1000000, string), test(strcat, 1000000, string), "seconds")
testall()
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-07-27 04:41:18
Istniejące odpowiedzi są bardzo dobrze napisane i zbadane, ale oto kolejna odpowiedź dla ery Pythona 3.6, ponieważ teraz mamy dosłowną interpolację łańcuchów (AKA, f-strings):
>>> import timeit
>>> timeit.timeit('f\'{"a"}{"b"}{"c"}\'', number=1000000)
0.14618930302094668
>>> timeit.timeit('"".join(["a", "b", "c"])', number=1000000)
0.23334730707574636
>>> timeit.timeit('a = "a"; a += "b"; a += "c"', number=1000000)
0.14985873899422586
Nie jest to bynajmniej żaden formalny benchmark, ale wygląda na to, że użycie f-strings jest mniej więcej tak samo wydajne jak użycie += konkatenacji; wszelkie ulepszone metryki lub sugestie są, oczywiście, witamy.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-04-26 01:25:26
Przepisałem ostatnią odpowiedź, czy jou może podzielić się swoją opinią na temat sposobu, w jaki testowałem?
import time
start1 = time.clock()
for x in range (10000000):
dog1 = ' and '.join(['spam', 'eggs', 'spam', 'spam', 'eggs', 'spam','spam', 'eggs', 'spam', 'spam', 'eggs', 'spam'])
end1 = time.clock()
print("Time to run Joiner = ", end1 - start1, "seconds")
start2 = time.clock()
for x in range (10000000):
dog2 = 'spam'+' and '+'eggs'+' and '+'spam'+' and '+'spam'+' and '+'eggs'+' and '+'spam'+' and '+'spam'+' and '+'eggs'+' and '+'spam'+' and '+'spam'+' and '+'eggs'+' and '+'spam'
end2 = time.clock()
print("Time to run + = ", end2 - start2, "seconds")
Uwaga: Ten przykład jest napisany w Pythonie 3.5, gdzie range() działa jak dawne xrange ()
Wyjście, które dostałem:
Time to run Joiner = 27.086106206103153 seconds
Time to run + = 69.79100515996426 seconds
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-09-21 19:32:29
To właśnie głupie programy są przeznaczone do testowania:)
Użyj plus
import time
if __name__ == '__main__':
start = time.clock()
for x in range (1, 10000000):
dog = "a" + "b"
end = time.clock()
print "Time to run Plusser = ", end - start, "seconds"
Wyjście:
Time to run Plusser = 1.16350010965 seconds
Teraz z join....
import time
if __name__ == '__main__':
start = time.clock()
for x in range (1, 10000000):
dog = "a".join("b")
end = time.clock()
print "Time to run Joiner = ", end - start, "seconds"
Wyjście:
Time to run Joiner = 21.3877386651 seconds
Więc na Pythonie 2.6 na windows powiedziałbym, że + jest około 18 razy szybszy niż join:)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-06-16 17:06:18