Różnica między ramką danych (w Spark 2.0 i.E DataSet[Row]) a RDD w Spark
Zastanawiam się tylko jaka jest różnica między RDD a DataFrame (Spark 2.0.0 DataFrame jest zwykłym aliasem typu dla Dataset[Row]) W Apache Spark?
11 answers
A DataFrame jest dobrze zdefiniowana za pomocą wyszukiwarki google dla "definicji ramki danych":
Ramka danych jest tabelą lub dwuwymiarową strukturą podobną do tablicy, w które każda kolumna zawiera pomiary na jednej zmiennej, a każdy wiersz zawiera jedną walizkę.
Tak więc, DataFrame ma dodatkowe metadane ze względu na swój format tabelaryczny, który pozwala Spark uruchomić pewne optymalizacje na sfinalizowanym zapytaniu.
An RDD, z drugiej strony, jest tylko R esilient D istributed d ataset, który jest bardziej czarną skrzynką danych, której nie można zoptymalizować, ponieważ operacje, które można wykonać na niej, nie są tak ograniczone.
Można jednak przejść z ramki danych do RDD za pomocą metody rdd, A Z RDD do DataFrame (jeśli RDD jest w formacie tabelarycznym) za pomocą metody toDF
Ogólnie zaleca się użycie DataFrame tam, gdzie jest to możliwe ze względu na wbudowaną optymalizację zapytań.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-09-09 18:44:15
Po pierwsze,
DataFramezostał wyewoluowany zSchemaRDD.

Dataframe i RDD jest absolutnie możliwa.
Poniżej kilka przykładowych fragmentów kodu.
-
df.rddjestRDD[Row]
Poniżej przedstawiamy kilka opcji tworzenia ramki danych.
1)
yourrddOffrow.toDFkonwertuje naDataFrame.-
[[49]} 2) Używanie
createDataFramekontekstu sqlval df = spark.createDataFrame(rddOfRow, schema)
Gdzie schemat może być z niektórych z poniższych opcji zgodnie z opisem nice SO post..
Od scala case class i Scala reflection apiimport org.apache.spark.sql.catalyst.ScalaReflection val schema = ScalaReflection.schemaFor[YourScalacaseClass].dataType.asInstanceOf[StructType]Lub używając
Encodersimport org.apache.spark.sql.Encoders val mySchema = Encoders.product[MyCaseClass].schemaZgodnie z opisem schematu można również utworzyć za pomocą
StructTypeiStructFieldval schema = new StructType() .add(StructField("id", StringType, true)) .add(StructField("col1", DoubleType, true)) .add(StructField("col2", DoubleType, true)) etc...

W rzeczywistości są teraz 3 Apache Spark API..

RDDAPI :
API
RDD(Resilient Distributed Dataset) jest w Spark od wydanie 1.0.API
RDDzapewnia wiele metod transformacji, takich jakmap(),filter() ireduce() do wykonywania obliczeń na danych. Każdy z tych metod wynika NowaRDDreprezentująca przekształcone data. Metody te są jednak tylko definiowaniem operacji, które mają być wykonywane i przekształcenia nie są wykonywane do momentu wykonania akcji metoda jest wywoływana. Przykładami metod działania sącollect() isaveAsObjectFile().
przykład RDD:
rdd.filter(_.age > 21) // transformation
.map(_.last)// transformation
.saveAsObjectFile("under21.bin") // action
Przykład: Filtruj według atrybutu za pomocą RDD
rdd.filter(_.age > 21)
-
DataFrameAPI
Spark 1.3 wprowadził nowe API
DataFramew ramach projektu Inicjatywa Tungsten, która ma na celu poprawę wydajności i skalowalność Spark. APIDataFramewprowadza pojęcie schemat do opisać dane, umożliwiając Spark zarządzanie schematem i tylko przekazać dane między węzłami, w znacznie bardziej efektywny sposób niż przy użyciu Java serialization.API
DataFrameróżni się radykalnie od APIRDD, ponieważ jest API do budowania relacyjnego planu zapytań, który Spark ' s Catalyst optymalizator może następnie wykonać. API jest naturalne dla programistów, którzy są znajomość planów zapytań budowlanych
przykładowy styl SQL:
df.filter("age > 21");
ograniczenia: Ponieważ kod odnosi się do atrybutów danych po nazwie, kompilator nie może wychwycić żadnych błędów. Jeśli nazwy atrybutów są nieprawidłowe, błąd zostanie wykryty tylko podczas wykonywania, gdy plan zapytań jest tworzony.
Kolejną wadą API DataFrame jest to, że jest bardzo Scala-centric i chociaż obsługuje Javę, wsparcie jest ograniczone.
Na przykład podczas tworzenia DataFrame z Spark Catalyst optimizer, istniejący RDD obiektów Javy, nie może wywnioskować schematu i zakłada, że wszelkie obiekty w ramce danych implementują interfejs scala.Product. Scala case class działa poprawnie, ponieważ implementuje ten interfejs.
-
DatasetAPI
[[49]} APIDataset, wydane jako podgląd API w Spark 1.6, ma na celu zapewnić to, co najlepsze z obu światów; znany obiekt zorientowany styl programowania i typ kompilacji-bezpieczeństwoRDDAPI ale z korzyści wydajnościowe narzędzia Catalyst query optimizer. Zestawy danych również korzystać z tego samego wydajnego mechanizmu magazynowania off-heap, coDataFrameAPI.Jeśli chodzi o serializację danych, API
Datasetma koncepcję kodery które tłumaczą pomiędzy reprezentacjami (obiektami) JVM i Wewnętrzny format binarny Spark. Spark posiada wbudowane Enkodery, które są bardzo zaawansowane, ponieważ generują kod bajtowy do interakcji z off-heap danych i zapewnić dostęp na żądanie do poszczególnych atrybutów bez konieczności de-serializacji całego obiektu. Spark jeszcze nie dostarczyć API do implementacji niestandardowych koderów, ale jest to planowane na przyszłe wydanie.Dodatkowo, API
Datasetjest zaprojektowane tak, aby równie dobrze współpracować z zarówno Java jak i Scala. Podczas pracy z obiektami Javy ważne jest że są w pełni zgodne z przepisami.
przykład Dataset API styl SQL:
dataset.filter(_.age < 21);
/ align = "left" / między DataFrame & DataSet :

Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-09-11 22:41:32
RDD
Główną abstrakcją dostarczaną przez Spark jest odporny rozproszony zbiór danych (RDD), który jest zbiorem elementów podzielonych na węzły klastra, które mogą być obsługiwane równolegle.
Funkcje RDD: -
Zbiór rozproszony:
RDD wykorzystuje operacje MapReduce, które są powszechnie stosowane do przetwarzania i generowania dużych zbiorów danych za pomocą równoległego, rozproszonego algorytmu na klastrze. Pozwala użytkownikom na pisz obliczenia równoległe, używając zestawu operatorów wysokiego poziomu, bez martwienia się o rozkład pracy i tolerancję błędów.Immutable: RDDs składa się ze zbioru zapisów, które są podzielone na partycje. Partycja jest podstawową jednostką równoległości w RDD, a każda partycja jest jednym logicznym podziałem danych, który jest niezmienny i utworzony przez pewne przekształcenia na istniejących partycjach.Niezmienność pomaga osiągnąć spójność w obliczenia.
Tolerancja błędu: W przypadku utraty pewnej partycji RDD, możemy odtworzyć transformację na tej partycji w linii, aby osiągnąć te same obliczenia, zamiast replikacji danych w wielu węzłach.Ta cecha jest największą zaletą RDD, ponieważ oszczędza wiele wysiłku w zarządzaniu danymi i replikacji, a tym samym osiąga szybsze obliczenia.
Leniwe oceny: wszystkie przekształcenia w Spark są leniwi, ponieważ nie obliczają swoich wyników od razu. Zamiast tego po prostu zapamiętują transformacje zastosowane do jakiegoś bazowego zbioru danych . Transformacje są obliczane tylko wtedy, gdy akcja wymaga zwrócenia wyniku do programu sterownika.
Przekształcenia funkcjonalne: RDD obsługują dwa typy operacji: transformacje, które tworzą nowy zbiór danych z istniejącego, oraz akcje, które zwracają wartość do programu sterownika po uruchomieniu obliczenia na zbiorze danych.
Formaty przetwarzania danych:
Może łatwo i efektywnie przetwarzać dane, które są zarówno ustrukturyzowane, jak i nieustrukturyzowane.
-
obsługiwane języki programowania:
RDD API jest dostępne w Javie, Scali, Pythonie i R.
Ograniczenia RDD: -
Brak wbudowanego silnika optymalizacji: Podczas pracy z danymi strukturalnymi RDD nie może korzystać z zalet Zaawansowane optymalizatory Spark, w tym catalyst optimizer i Tungsten execution engine. Programiści muszą zoptymalizować każdy RDD na podstawie jego atrybutów.
Obsługa danych strukturalnych: W przeciwieństwie do ramki danych i zestawów danych, RDD nie wnioskuje schematu przyjmowanych danych i wymaga podania go przez użytkownika.
Dataframes
Spark wprowadził ramki danych w wersji Spark 1.3. Dataframe radzi sobie z kluczowymi wyzwaniami, z jakimi borykały się RDDs.A DataFrame jest rozproszonym zbiorem danych zorganizowanym w nazwane kolumny. Jest koncepcyjnie odpowiednikiem tabeli w relacyjnej bazie danych lub ramce danych R / Python. Oprócz Dataframe, Spark wprowadził również catalyst optimizer, który wykorzystuje zaawansowane funkcje programowania do budowy rozszerzalnego optymalizatora zapytań.
Funkcje Ramki Danych: -
Rozproszony zbiór obiektu Row: Ramka danych jest rozproszonym zbiorem danych zorganizowanym w nazwane kolumny. Jest to koncepcyjnie równoważne tabeli w relacyjnej bazie danych, ale z bogatszymi optymalizacjami pod maską.
Przetwarzanie Danych: Przetwarzanie ustrukturyzowanych i nieustrukturyzowanych formatów danych (Avro, CSV, elastic search i Cassandra) oraz systemów pamięci masowej (HDFS, HIVE tables, MySQL itp.). Może odczytywać i zapisywać ze wszystkich tych różnych źródeł danych.
-
Optymalizacja za pomocą catalyst optimizer: Zasila zarówno zapytania SQL jak i DataFrame API. Dataframe używać catalyst tree transformation framework w czterech fazach,
1.Analyzing a logical plan to resolve references 2.Logical plan optimization 3.Physical planning 4.Code generation to compile parts of the query to Java bytecode. Kompatybilność Hive: Używając Spark SQL, możesz uruchamiać niezmodyfikowane zapytania Hive na istniejących magazynach Hive. Reuses Hive frontend and MetaStore and gives you full compatibility with existing Hive data, queries, and UDFs.
Tungsten zapewnia fizyczny backend wykonawczy, który domyślnie zarządza pamięcią i dynamicznie generuje bajtowy kod do oceny wyrażenia.
-
Obsługiwane języki programowania:
Dataframe API jest dostępne w Javie, Scali, Pythonie i R.
Ograniczenia Ramki Danych: -
- bezpieczeństwo typu kompilacji: Jak wspomniano, Dataframe API nie obsługuje bezpieczeństwa czasu kompilacji, co ogranicza cię od manipulowania danymi, gdy struktura nie jest znana. Poniższy przykład działa podczas kompilacji. Jednak otrzymasz Runtime wyjątek podczas wykonywania tego kodu.
Przykład:
case class Person(name : String , age : Int)
val dataframe = sqlContect.read.json("people.json")
dataframe.filter("salary > 10000").show
=> throws Exception : cannot resolve 'salary' given input age , name
Jest to trudne szczególnie, gdy pracujesz z kilkoma krokami transformacji i agregacji.
- Nie można operować na obiekcie domeny (lost domain object): Po przekształceniu obiektu domeny w ramkę danych nie można go z niej zregenerować. W poniższym przykładzie, po utworzeniu personDF z personRDD, nie odzyskamy oryginalnego RDD klasy Person (RDD [osoba]).
Przykład:
case class Person(name : String , age : Int)
val personRDD = sc.makeRDD(Seq(Person("A",10),Person("B",20)))
val personDF = sqlContect.createDataframe(personRDD)
personDF.rdd // returns RDD[Row] , does not returns RDD[Person]
Datasets API
Dataset API jest rozszerzeniem DataFrames, które zapewnia bezpieczny dla typu, obiektowy interfejs programowania. Jest to silnie typowana, niezmienna kolekcja obiektów, które są odwzorowywane na schemacie relacyjnym.
W jądrze zbioru danych, API jest nową koncepcją zwaną enkoderem, który jest odpowiedzialny za konwersję między obiektami JVM i reprezentacją tabelaryczną. Reprezentacja tabelaryczna jest przechowywany przy użyciu Spark wewnętrznego formatu binarnego Tungsten, co pozwala na operacje na serializowanych danych i lepsze wykorzystanie pamięci. Spark 1.6 jest wyposażony w obsługę automatycznego generowania koderów dla szerokiej gamy typów, w tym typów prymitywnych (np. String, Integer, Long), klas przypadków Scala i Java Beans.
Funkcje Zestawu Danych: -
-
Zapewnia najlepsze zarówno RDD, jak i Dataframe: RDD (functional programming, type safe), DataFrame (relational model, Optymalizacja zapytań, wykonanie, sortowanie i tasowanie)
Kodery: Za pomocą koderów można łatwo przekonwertować dowolny obiekt JVM na zbiór danych, umożliwiając użytkownikom pracę zarówno ze strukturyzowanymi, jak i nieustrukturyzowanymi danymi w przeciwieństwie do ramki danych.
Obsługiwane języki programowania: Datasets API jest obecnie dostępne tylko w Scala i Java. Python i R nie są obecnie obsługiwane w wersji 1.6. Obsługa Pythona przeznaczona jest dla Wersja 2.0.
Bezpieczeństwo Typu: Datasets API zapewnia bezpieczeństwo w czasie kompilacji, które nie było dostępne w Dataframes. W poniższym przykładzie możemy zobaczyć, jak Dataset może działać na obiektach domeny z kompilowanymi funkcjami lambda.
Przykład:
case class Person(name : String , age : Int)
val personRDD = sc.makeRDD(Seq(Person("A",10),Person("B",20)))
val personDF = sqlContect.createDataframe(personRDD)
val ds:Dataset[Person] = personDF.as[Person]
ds.filter(p => p.age > 25)
ds.filter(p => p.salary > 25)
// error : value salary is not a member of person
ds.rdd // returns RDD[Person]
- interoperacyjne: Datasets pozwala na łatwą konwersję istniejących RDD i ramek danych do zestawów danych bez kodu boilerplate.
Datasets API Ograniczenie: -
- wymaga typu casting Do String: Odpytywanie danych ze zbiorów danych wymaga obecnie, abyśmy określili pola w klasie jako łańcuch znaków. Po zapytaniu danych, jesteśmy zmuszeni do oddania kolumny do wymaganego typu danych. Z drugiej strony, jeśli użyjemy operacji map na zestawach danych, nie użyje Catalyst optimizer.
Przykład:
ds.select(col("name").as[String], $"age".as[Int]).collect()
Brak wsparcia dla Pythona i R: od wersji 1.6, zbiory danych obsługują tylko Scala i Java. Python wsparcie zostanie wprowadzone w Spark 2.0.
Datasets API przynosi kilka zalet w stosunku do istniejących RDD i Dataframe API z lepszym bezpieczeństwem typu i programowania funkcjonalnego.Z wyzwaniem wymagania odlewania typu W API, nadal nie będzie wymagane bezpieczeństwo typu i sprawi, że Twój kod kruche.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-03-18 09:59:28
Wszystkie (RDD, DataFrame i DataSet) w jednym obrazku
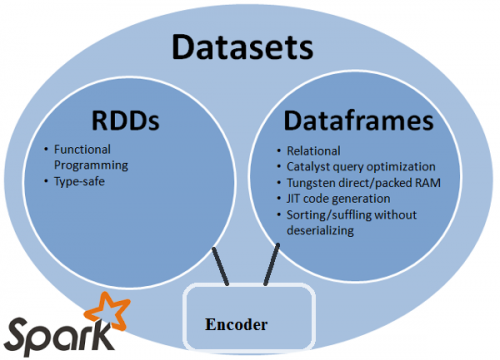
RDD
RDDjest odpornym na uszkodzenia zbiorem elementów, które mogą być obsługiwane równolegle.
DataFrame
DataFramejest zbiorem danych zorganizowanym w nazwane kolumny. On koncepcyjnie odpowiednikiem tabeli w relacyjnej bazie danych lub danych ramki w R / Pythonie, , ale z bogatszymi optymalizacjami pod hood .
Dataset
Datasetjest rozproszonym zbiorem danych. Spark 1.6 jest nowym interfejsem dodanym do Spark 1.6, który zapewnia korzyści z RDDs (silne typowanie, możliwość korzystania z potężnych funkcji lambda) z korzyści ze zoptymalizowanego silnika wykonawczego Spark SQL.
Uwaga:
Zbiór danych wierszy (
Dataset[Row]) W Scala / Java będzie często odwoływać się jako DataFrames .
Ładne porównanie wszystkich z fragmentem kodu
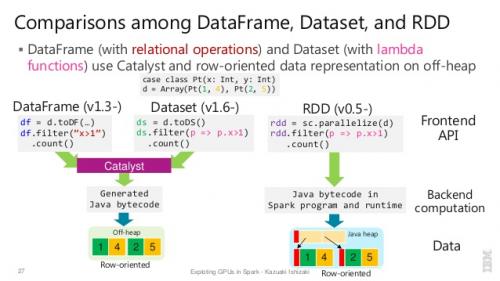
P: Czy możesz przekonwertować jedną na drugą, jak RDD na ramkę danych lub odwrotnie?
Tak, oba są możliwe
1. RDD do DataFrame z .toDF()
val rowsRdd: RDD[Row] = sc.parallelize(
Seq(
Row("first", 2.0, 7.0),
Row("second", 3.5, 2.5),
Row("third", 7.0, 5.9)
)
)
val df = spark.createDataFrame(rowsRdd).toDF("id", "val1", "val2")
df.show()
+------+----+----+
| id|val1|val2|
+------+----+----+
| first| 2.0| 7.0|
|second| 3.5| 2.5|
| third| 7.0| 5.9|
+------+----+----+
2. DataFrame/DataSet do RDD z .rdd() metoda
val rowsRdd: RDD[Row] = df.rdd() // DataFrame to RDD
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-01-17 02:06:37
Po Prostu RDD jest głównym komponentem, ale {[2] } jest API wprowadzonym w spark 1.30.
RDD
Zbiór partycji danych o nazwie RDD. Te {[1] } muszą mieć kilka właściwości takich jak:
- niezmienny,
- Tolerancja Błędów,
- rozproszone,
- więcej.
Tutaj {[1] } jest albo ustrukturyzowany, albo niestrukturalny.
DataFrame
DataFrame jest API dostępnym w Scali, Javie, Pythonie i R. pozwala na przetwarzanie dowolnych rodzaj danych ustrukturyzowanych i częściowo ustrukturyzowanych. Aby zdefiniować DataFrame, zbiór rozproszonych danych zorganizowanych w nazwane kolumny o nazwie DataFrame. Możesz łatwo zoptymalizować RDDs w DataFrame.
Możesz przetwarzać dane JSON, parkiet, HiveQL za pomocą DataFrame.
val sampleRDD = sqlContext.jsonFile("hdfs://localhost:9000/jsondata.json")
val sample_DF = sampleRDD.toDF()
Tutaj sample_df rozważ jako DataFrame. sampleRDD jest (dane surowe) nazywane RDD.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-02-16 12:23:43
Większość odpowiedzi jest poprawna, wystarczy dodać tu jeden punkt
W Spark 2.0 dwa API (DataFrame +DataSet) zostaną zunifikowane w jeden API.
"Unifying DataFrame and Dataset: w Scali i Javie, DataFrame i Dataset zostały zunifikowane, tzn. DataFrame jest tylko aliasem typu dla Dataset of Row. W Pythonie i R, ze względu na brak bezpieczeństwa typu, DataFrame jest głównym interfejsem programistycznym."
Zbiory danych są podobne do RDDs, jednak zamiast używać Javy serializacja lub Kryo używają wyspecjalizowanego enkodera do serializacji obiektów do przetwarzania lub przesyłania przez sieć.
Spark SQL obsługuje dwie różne metody konwersji istniejących RDD na zbiory danych. Pierwsza metoda wykorzystuje odbicie, aby wywnioskować schemat RDD, który zawiera określone typy obiektów. To podejście oparte na refleksji prowadzi do bardziej zwięzłego kodu i działa dobrze, gdy znasz już schemat podczas pisania aplikacji Spark.
Drugi metoda tworzenia zestawów danych jest poprzez interfejs programowy, który pozwala na skonstruowanie schematu, a następnie zastosować go do istniejącego RDD. Chociaż ta metoda jest bardziej wyrazista, pozwala na konstruowanie zestawów danych, gdy kolumny i ich typy nie są znane do czasu uruchomienia.
Tutaj znajdziesz RDD Tof Data frame conversation answer
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-23 11:47:32
Ramka danych jest odpowiednikiem tabeli w RDBMS i może być również manipulowana w podobny sposób jak "natywne" zbiory rozproszone w RDDs. W przeciwieństwie do RDD, ramki danych śledzą schemat i obsługują różne operacje relacyjne, które prowadzą do bardziej zoptymalizowanego wykonania. Każdy obiekt ramki danych reprezentuje Plan logiczny, ale ze względu na swój "leniwy" charakter nie ma wykonania, dopóki użytkownik nie wywoła określonej "operacji wyjściowej".
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-04-05 17:43:02
Ramka danych jest RDD obiektów Row, z których każdy reprezentuje rekord. A Dataframe zna również schemat (czyli pola danych) swoich wierszy. While Dataframes wyglądają jak zwykłe RDD, wewnętrznie przechowują dane w bardziej efektywny sposób, wykorzystując ich schemat. Ponadto zapewniają one nowe operacje niedostępne na RDDs, takie jak możliwość uruchamiania zapytań SQL. Ramki danych mogą być tworzone z zewnętrznych źródeł danych, z wyników zapytań lub ze zwykłych RDDs.
indeks: Zaharia M., et al. Learning Spark (O ' Reilly, 2015)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-10-20 13:27:26
Kilka spostrzeżeń z perspektywy użytkowania, RDD vs DataFrame:
-
RDD są niesamowite! ponieważ dają nam całą elastyczność, aby poradzić sobie z prawie każdym rodzajem danych; dane niestrukturalne, częściowo ustrukturyzowane i ustrukturyzowane. Ponieważ wiele razy dane nie są gotowe do zmieszczenia się w ramce danych (nawet JSON), RDDs mogą być używane do wstępnego przetwarzania danych, aby mogły zmieścić się w ramce danych. RDD są podstawową abstrakcją danych w Spark.
- nie wszystkie przekształcenia, które są możliwe NA RDD są możliwe na Ramki danych, przykład subtract() jest dla RDD vs except () jest dla ramki danych.
- ponieważ ramki danych są podobne do tabeli relacyjnej, przestrzegają ścisłych zasad przy użyciu przekształceń teorii set/relational, na przykład jeśli chcesz połączyć dwa ramki danych, wymaganiem jest, aby oba dfs miały taką samą liczbę kolumn i powiązanych z nimi typów danych kolumn. Nazwy kolumn mogą być różne. Zasady te nie dotyczą RDD. Oto dobry tutorial wyjaśniający te fakty.
- są wzrost wydajności podczas korzystania z ramek danych, co inni już szczegółowo wyjaśnili.
- używając ramek danych nie musisz przekazywać dowolnej funkcji, tak jak to robisz podczas programowania z RDDs.
- potrzebujesz sqlcontext/HiveContext do programowania ramek danych, ponieważ leżą one w obszarze sparksql ekosystemu spark, ale dla RDD potrzebujesz tylko SparkContext / JavaSparkContext, które znajdują się w bibliotekach Spark Core.
- możesz utworzyć df z RDD, jeśli możesz zdefiniować dla niego schemat. Możesz Konwertuj również df na rdd i rdd na df.
Mam nadzieję, że to pomoże!
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-08-25 21:52:54
Możesz używać RDD ze strukturą i bez struktury, gdzie jako ramka Danych / zbiór danych może przetwarzać tylko dane strukturyzowane i częściowo strukturyzowane (ma odpowiedni schemat)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-12-07 06:51:23
A DataFrame jest RDD, który ma schemat. Możesz myśleć o niej jako o relacyjnej tabeli bazy danych, ponieważ każda kolumna ma nazwę i znany typ. Moc DataFrame wynika z faktu, że podczas tworzenia ramki danych ze zorganizowanego zbioru danych (Json, parkiet..), Spark jest w stanie wywnioskować schemat wykonując przejście na całość (Json, parkiet..) zbiór danych, który jest ładowany. Następnie, przy obliczaniu planu wykonania, Spark, może użyć schematu i zrobić znacznie lepsze optymalizacje obliczeniowe. Zauważ, że DataFrame był nazywany SchemaRDD przed Spark v1.3.0
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-01-07 22:35:19