Czym różnią się iloc i loc?
Czy ktoś może wyjaśnić, czym różnią się te dwie metody krojenia?
I ' ve seen the docs ,
i widziałem te odpowiedzi , ale nadal nie jestem w stanie zrozumieć, jak te trzy są różne. Dla mnie wydają się w dużej mierze wymienne, ponieważ są na niższych poziomach krojenia.
Na przykład, powiedzmy, że chcemy uzyskać pierwsze pięć wierszy DataFrame. Jak to jest, że ci dwaj pracują?
df.loc[:5]
df.iloc[:5]
Dawno, dawno temu, chciałem również wiedzieć, jak te dwie funkcje różnią się od df.ix[:5], ale {[3] } została usunięta z pandas 1.0, więc mam to gdzieś.
5 answers
Etykieta vs. lokalizacja
Główne rozróżnienie między tymi dwoma metodami to:
-
locpobiera wiersze (i / lub kolumny) z konkretnymi etykietami . -
ilocpobiera wiersze (i / lub kolumny) w miejscach całkowitych .
Aby zademonstrować, rozważ serię s znaków o niemonotonicznym indeksie całkowitym:
>>> s = pd.Series(list("abcdef"), index=[49, 48, 47, 0, 1, 2])
49 a
48 b
47 c
0 d
1 e
2 f
>>> s.loc[0] # value at index label 0
'd'
>>> s.iloc[0] # value at index location 0
'a'
>>> s.loc[0:1] # rows at index labels between 0 and 1 (inclusive)
0 d
1 e
>>> s.iloc[0:1] # rows at index location between 0 and 1 (exclusive)
49 a
Oto niektóre z różnic / podobieństw między s.loc i s.iloc po przejściu różnych obiektów:
| Opis | s.loc[<object>] |
s.iloc[<object>] |
|
|---|---|---|---|
0 |
pojedynczy element | wartość w indeksie Etykieta 0 (ciąg 'd') |
wartość w indeksie lokalizacja 0 (ciąg 'a') |
0:1 |
plasterek |
dwa wiersze (etykiety 0 i 1) |
jeden wiersz (pierwszy wiersz w miejscu 0) |
1:47 |
plasterek z końcówką out-of-bounds | Zero wiersze (seria pusta) | pięć wierszy (Lokalizacja 1) |
1:47:-1 |
plasterek z ujemnym krokiem |
cztery wiersze (etykiety 1 powrót do 47) |
Zero wiersze (seria pusta) |
[2, 0] |
lista liczb całkowitych | dwa wiersze z podanym etykiety | dwa wiersze o podanych miejscach |
s > 'e' |
seria Bool (wskazująca, które wartości mają właściwość) |
jeden wiersz (zawierający 'f') |
NotImplementedError |
(s>'e').values |
tablica Bool |
jeden wiersz (zawierający 'f') |
tak samo jak loc
|
999 |
int obiekt nie w indeksie | KeyError |
IndexError (Z granice) |
-1 |
int obiekt nie w indeksie | KeyError |
zwraca ostatnią wartość w s
|
lambda x: x.index[3] |
wywołanie stosowane do szeregów (tutaj zwracając 3 Rd pozycja w indeksie) | s.loc[s.index[3]] |
s.iloc[s.index[3]] |
loc'możliwości wyszukiwania etykiet s znacznie wykraczają poza indeksy całkowite i warto zwrócić uwagę na kilka dodatkowych przykładów.
Oto seria, w której indeks zawiera obiekty typu string:
>>> s2 = pd.Series(s.index, index=s.values)
>>> s2
a 49
b 48
c 47
d 0
e 1
f 2
Ponieważ {[9] } jest oparte na etykiecie, może pobrać pierwszą wartość z serii za pomocą s2.loc['a']. Może również wycinać z obiektami nie-całkowitymi:
>>> s2.loc['c':'e'] # all rows lying between 'c' and 'e' (inclusive)
c 47
d 0
e 1
W przypadku Indeksów DateTime nie musimy podawać dokładnej daty/czasu, aby pobrać według etykiety. Na przykład:
>>> s3 = pd.Series(list('abcde'), pd.date_range('now', periods=5, freq='M'))
>>> s3
2021-01-31 16:41:31.879768 a
2021-02-28 16:41:31.879768 b
2021-03-31 16:41:31.879768 c
2021-04-30 16:41:31.879768 d
2021-05-31 16:41:31.879768 e
>>> s3.loc['2021-03':'2021-04']
2021-03-31 17:04:30.742316 c
2021-04-30 17:04:30.742316 d
Wiersze i kolumny
loc i iloc działają tak samo z ramkami danych, jak z seriami. Warto zauważyć, że obie metody mogą adresować kolumny i wiersze razem.
Gdy podano krotkę, pierwszy element jest używany do indeksowania wierszy, a jeśli istnieje, drugi element jest używany do indeksowania kolumn.
Rozważ ramkę danych zdefiniowaną poniżej:
>>> import numpy as np
>>> df = pd.DataFrame(np.arange(25).reshape(5, 5),
index=list('abcde'),
columns=['x','y','z', 8, 9])
>>> df
x y z 8 9
a 0 1 2 3 4
b 5 6 7 8 9
c 10 11 12 13 14
d 15 16 17 18 19
e 20 21 22 23 24
Wtedy na przykład:
>>> df.loc['c': , :'z'] # rows 'c' and onwards AND columns up to 'z'
x y z
c 10 11 12
d 15 16 17
e 20 21 22
>>> df.iloc[:, 3] # all rows, but only the column at index location 3
a 3
b 8
c 13
d 18
e 23
Czasami chcemy połączyć metody indeksowania etykiet i pozycji dla wierszy i kolumn, w jakiś sposób łącząc możliwości loc i iloc.
Na przykład, rozważ następującą ramkę danych. Jak najlepiej pokroić wiersze do " c " i wziąć pierwsze cztery kolumny?
>>> import numpy as np
>>> df = pd.DataFrame(np.arange(25).reshape(5, 5),
index=list('abcde'),
columns=['x','y','z', 8, 9])
>>> df
x y z 8 9
a 0 1 2 3 4
b 5 6 7 8 9
c 10 11 12 13 14
d 15 16 17 18 19
e 20 21 22 23 24
Możemy osiągnąć ten wynik za pomocą iloc i pomocy innej metody:
>>> df.iloc[:df.index.get_loc('c') + 1, :4]
x y z 8
a 0 1 2 3
b 5 6 7 8
c 10 11 12 13
get_loc() jest metodą index oznaczającą "uzyskaj pozycję etykiety w tym indeksie". Zauważ, że ponieważ krojenie za pomocą iloc nie obejmuje jego punktu końcowego, musimy dodać 1 do tej wartości, jeśli chcemy również wiersz 'c'.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2021-01-02 17:33:38
iloc Działa w oparciu o pozycjonowanie całkowite. Więc bez względu na to, jakie są etykiety wierszy, zawsze możesz np. uzyskać pierwszy wiersz, wykonując
df.iloc[0]
Lub ostatnie pięć wierszy wykonując
df.iloc[-5:]
Można go również używać na kolumnach. To pobiera trzecią kolumnę:
df.iloc[:, 2] # the : in the first position indicates all rows
Można je łączyć, aby uzyskać przecięcia wierszy i kolumn:
df.iloc[:3, :3] # The upper-left 3 X 3 entries (assuming df has 3+ rows and columns)
Z drugiej strony, .loc użyj nazwanych indeksów. Ustawmy ramkę danych z łańcuchami jako wiersz i kolumnę etykiety:
df = pd.DataFrame(index=['a', 'b', 'c'], columns=['time', 'date', 'name'])
Wtedy możemy otrzymać pierwszy wiersz przez
df.loc['a'] # equivalent to df.iloc[0]
I dwa drugie wiersze 'date' Kolumny przez
df.loc['b':, 'date'] # equivalent to df.iloc[1:, 1]
I tak dalej. Teraz warto zwrócić uwagę, że domyślne indeksy wierszy i kolumn dla DataFrame są liczbami całkowitymi od 0 i w tym przypadku iloc i loc będą działać w ten sam sposób. Dlatego twoje trzy przykłady są równoważne. Jeśli masz indeks nieliczbowy, taki jak strings lub datetimes, df.loc[:5] spowodowałoby to błąd.
Możesz również pobrać kolumny za pomocą ramki danych __getitem__:
df['time'] # equivalent to df.loc[:, 'time']
Teraz Załóżmy, że chcesz mieszać indeksowanie pozycji i nazw, to znaczy indeksowanie za pomocą nazw wierszy i pozycji na kolumnach(dla wyjaśnienia, mam na myśli select z naszej ramki danych, zamiast tworzenia ramki danych z łańcuchami w indeksie wiersza i liczbami całkowitymi w indeksie kolumny). To tutaj .ix wchodzi:
df.ix[:2, 'time'] # the first two rows of the 'time' column
Myślę, że warto również wspomnieć, że można przekazać wektory boolowskie do metoda loc. Na przykład:
b = [True, False, True]
df.loc[b]
Zwróci pierwszy i trzeci wiersz df. Jest to równoważne df[b] dla wyboru, ale może być również używane do przypisywania za pomocą wektorów logicznych:
df.loc[b, 'name'] = 'Mary', 'John'
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-12-07 10:29:48
Moim zdaniem, zaakceptowana odpowiedź jest myląca, ponieważ używa ramki danych z brakującymi tylko wartościami. Nie podoba mi się również termin position-based dla .iloc i zamiast tego wolę integer location, ponieważ jest znacznie bardziej opisowy i dokładnie to, co oznacza .iloc. Słowo kluczowe to INTEGER - .iloc potrzebuje liczb całkowitych.
Zobacz moją niezwykle szczegółową serię blogów na temat wyboru podzbiorów po więcej
.ix jest przestarzały i niejednoznaczny i powinien nigdy nie być używane
Ponieważ .ix jest przestarzały, skupimy się tylko na różnicach między .loc i .iloc.
Zanim porozmawiamy o różnicach, ważne jest, aby zrozumieć, że ramki danych mają etykiety, które pomagają zidentyfikować każdą kolumnę i każdy indeks. Spójrzmy na przykładową ramkę danych:
df = pd.DataFrame({'age':[30, 2, 12, 4, 32, 33, 69],
'color':['blue', 'green', 'red', 'white', 'gray', 'black', 'red'],
'food':['Steak', 'Lamb', 'Mango', 'Apple', 'Cheese', 'Melon', 'Beans'],
'height':[165, 70, 120, 80, 180, 172, 150],
'score':[4.6, 8.3, 9.0, 3.3, 1.8, 9.5, 2.2],
'state':['NY', 'TX', 'FL', 'AL', 'AK', 'TX', 'TX']
},
index=['Jane', 'Nick', 'Aaron', 'Penelope', 'Dean', 'Christina', 'Cornelia'])

Wszystkie słowa wpogrubione są etykietami. Etykiety, age, color, food, height, score i {[32] } są używane do kolumny . Pozostałe etykiety, Jane, Nick, Aaron, Penelope, Dean, Christina, Cornelia są używane do indeksu .
Podstawowe sposoby wybierania poszczególnych wierszy w ramce danych są za pomocą indeksatorów .loc i .iloc. Każdy z tych indekserów może być również używany do jednoczesnego wybierania kolumn, ale na razie łatwiej jest skupić się na wierszach. Ponadto każdy z indeksatorów używa zestawu nawiasów, które natychmiast następują po ich nazwie, aby dokonać wyboru.
.loc wybór Danych tylko za pomocą etykiet
Najpierw porozmawiamy o indeksatorze .loc, który wybiera dane tylko za pomocą etykiet indeksów lub kolumn. W naszej przykładowej ramce danych podaliśmy znaczące nazwy jako wartości dla indeksu. Wiele ramek danych nie będzie miało żadnych sensownych nazw, a zamiast tego domyślnie będą to liczby całkowite od 0 do n-1, gdzie n jest długością ramki danych.
Istnieją trzy różne wejścia, których możesz użyć dla .loc
- a string
- A lista ciągów
- notacja wycinka za pomocą łańcuchów jako wartości start i stop
Wybieranie pojedynczego wiersza z .loc with a string
Aby wybrać pojedynczy wiersz danych, umieść etykietę indeksu wewnątrz nawiasów po .loc.
df.loc['Penelope']
Zwraca wiersz danych jako szereg
age 4
color white
food Apple
height 80
score 3.3
state AL
Name: Penelope, dtype: object
Wybieranie wielu wierszy z .loc z listą łańcuchów
df.loc[['Cornelia', 'Jane', 'Dean']]
To zwraca ramkę danych z wierszami w kolejność podana na liście:
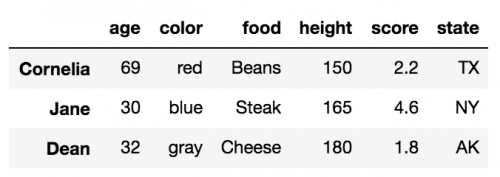
Wybieranie wielu wierszy z .loc z notacją slice
Notacja Slice jest zdefiniowana przez wartości start, stop i step. Przy krojeniu według etykiety, pandy zawierają wartość stop w zwrocie. Następujące plastry od Aarona do Deana, włącznie. Jego rozmiar kroku nie jest jawnie zdefiniowany, ale domyślnie wynosi 1.
df.loc['Aaron':'Dean']

Złożone plastry można przyjmować w ten sam sposób jak list Pythona.
.iloc wybiera dane tylko przez lokalizację całkowitą
Przejdźmy teraz do .iloc. Każdy wiersz i kolumna danych w ramce danych ma lokalizację całkowitą, która go definiuje. jest to dodatek do etykiety, która jest wizualnie wyświetlana na wyjściu. Liczba całkowita to po prostu liczba wierszy / kolumn od góry / lewej strony zaczynająca się od 0.
Istnieją trzy różne wejścia, których możesz użyć dla .iloc
- liczba całkowita
- A lista liczb całkowitych
- notacja wycinka za pomocą liczb całkowitych jako wartości start i stop
Wybieranie pojedynczego wiersza z .iloc z liczbą całkowitą
df.iloc[4]
To zwraca 5. wiersz (integer location 4) jako szereg
age 32
color gray
food Cheese
height 180
score 1.8
state AK
Name: Dean, dtype: object
Wybieranie wielu wierszy z .iloc z listą liczb całkowitych
df.iloc[[2, -2]]
Zwraca ramkę danych z trzeciego i drugiego do ostatniego wiersza:

Wybieranie wielu rzędy z .iloc z notacją slice
df.iloc[:5:3]

Jednoczesne zaznaczanie wierszy i kolumn z .loc i .iloc
Jedną z doskonałych zdolności obu .loc/.iloc jest ich zdolność do zaznaczania zarówno wierszy, jak i kolumn jednocześnie. W powyższych przykładach zwrócono wszystkie kolumny z każdej selekcji. Możemy wybrać kolumny z tymi samymi typami wejść, co dla wierszy. Po prostu musimy oddzielić wybór wierszy i kolumn za pomocą przecinek .
Na przykład, możemy wybrać wiersze Jane i Dean z tylko wysokość kolumn, wynik i stan w następujący sposób:
df.loc[['Jane', 'Dean'], 'height':]

Możemy naturalnie wykonywać podobne operacje z .iloc używając tylko liczb całkowitych.
df.iloc[[1,4], 2]
Nick Lamb
Dean Cheese
Name: food, dtype: object
Jednoczesne zaznaczanie z etykietami i lokalizacją całkowitą
.ix był używany do dokonywania selekcji jednocześnie z etykietami i integer lokalizacja, która była użyteczna, ale mylące i niejednoznaczne w czasach i na szczęście został przestarzały. W przypadku, gdy trzeba dokonać selekcji z mieszanką etykiet i lokalizacji całkowitych, trzeba będzie dokonać zarówno etykiet selekcji, jak i lokalizacji całkowitych.
Na przykład, jeśli chcemy wybrać wiersze Nick i Cornelia wraz z kolumnami 2 i 4, możemy użyć .loc, konwertując liczby całkowite na etykiety o następującej treści:
col_names = df.columns[[2, 4]]
df.loc[['Nick', 'Cornelia'], col_names]
Lub alternatywnie Konwertuj etykiety indeksów na liczby całkowite za pomocą metody get_loc index.
labels = ['Nick', 'Cornelia']
index_ints = [df.index.get_loc(label) for label in labels]
df.iloc[index_ints, [2, 4]]
Wybór Logiczny
The .Loc indexer może również dokonać wyboru logicznego. Na przykład, jeśli jesteśmy zainteresowani znalezieniem wszystkich wierszy, w których wiek jest powyżej 30 i zwracamy tylko kolumny food i score, możemy wykonać następujące czynności:
df.loc[df['age'] > 30, ['food', 'score']]
Możesz powtórzyć to za pomocą .iloc, ale nie możesz przekazać mu serii logicznej. Musisz przekonwertować serię logiczną na tablicę numpy, taką jak to:
df.iloc[(df['age'] > 30).values, [2, 4]]
Zaznaczanie wszystkich wierszy
Możliwe jest użycie .loc/.iloc tylko do wyboru kolumny. Możesz wybrać wszystkie wiersze, używając dwukropka w ten sposób:
df.loc[:, 'color':'score':2]

Operator indeksowania, [], może również wybierać wiersze i kolumny, ale nie jednocześnie.
Większość ludzi zna podstawowy cel operatora indeksowania DataFrame, jakim jest wybieranie kolumn. Ciąg znaków wybiera pojedynczą kolumnę jako serię lista łańcuchów wybiera wiele kolumn jako ramkę danych.
df['food']
Jane Steak
Nick Lamb
Aaron Mango
Penelope Apple
Dean Cheese
Christina Melon
Cornelia Beans
Name: food, dtype: object
Użycie listy wybiera wiele kolumn
df[['food', 'score']]

Ludzie są mniej zaznajomieni z tym, że gdy używana jest notacja slice, zaznaczanie odbywa się za pomocą etykiet wierszy lub lokalizacji całkowitej. Jest to bardzo mylące i coś, czego prawie nigdy nie używam, ale działa.
df['Penelope':'Christina'] # slice rows by label
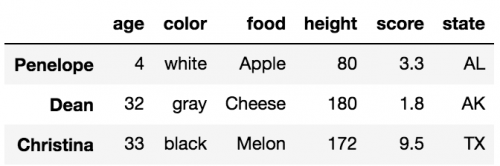
df[2:6:2] # slice rows by integer location

The bardzo preferowana jest jasność .loc/.iloc dla wybierania wierszy. Sam operator indeksowania nie może jednocześnie wybierać wierszy i kolumn.
df[3:5, 'color']
TypeError: unhashable type: 'slice'
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-10-27 01:53:41
- DataFrame.loc (): Select rows by index value
- DataFrame.iloc (): Select rows by rows number
Przykład:
- Wybierz pierwsze 5 wierszy tabeli, df1 to Twój dataframe
Df1.iloc [: 5]
- Wybierz pierwsze wiersze a, b tabeli, df1 to Twój dataframe
Df1.loc ["A", "B"]
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-12-10 06:58:02
.loc i .iloc są używane do indeksowania, tj. do wyciągania części danych. Zasadniczo różnica polega na tym, że .loc umożliwia indeksowanie oparte na etykietach, podczas gdy .iloc umożliwia indeksowanie oparte na pozycjach.
Jeśli pomylisz się przez .loc i .iloc, pamiętaj, że {[5] } opiera się na pozycji index (zaczynającej się od i), podczas gdy .loc opiera się na etykiecie (zaczynającej się od l).
.loc
.loc ma opierać się na etykietach indeksów, a nie na pozycji, jest więc analogiczne do indeksowania opartego na słowniku Pythona. Może jednak akceptować tablice logiczne, plasterki i listę etykiet (z których żadna nie działa ze słownikiem Pythona).
iloc
.iloc czy wyszukiwanie oparte jest na pozycji indeksu, tzn. pandas zachowuje się podobnie do listy Pythona. pandas wywoła IndexError, jeśli w tej lokalizacji nie ma indeksu.
Przykłady
Poniżej przedstawiono przykłady ilustrujące różnice między .iloc a .loc. Rozważmy następujące serie:
>>> s = pd.Series([11, 9], index=["1990", "1993"], name="Magic Numbers")
>>> s
1990 11
1993 9
Name: Magic Numbers , dtype: int64
.iloc przykłady
>>> s.iloc[0]
11
>>> s.iloc[-1]
9
>>> s.iloc[4]
Traceback (most recent call last):
...
IndexError: single positional indexer is out-of-bounds
>>> s.iloc[0:3] # slice
1990 11
1993 9
Name: Magic Numbers , dtype: int64
>>> s.iloc[[0,1]] # list
1990 11
1993 9
Name: Magic Numbers , dtype: int64
.loc przykłady
>>> s.loc['1990']
11
>>> s.loc['1970']
Traceback (most recent call last):
...
KeyError: ’the label [1970] is not in the [index]’
>>> mask = s > 9
>>> s.loc[mask]
1990 11
Name: Magic Numbers , dtype: int64
>>> s.loc['1990':] # slice
1990 11
1993 9
Name: Magic Numbers, dtype: int64
Ponieważ s mA wartości indeksu string, .loc zakończy się niepowodzeniem, gdy
indeksowanie za pomocą liczby całkowitej:
>>> s.loc[0]
Traceback (most recent call last):
...
KeyError: 0
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-12-28 22:39:51