Czy apache spark może działać bez hadoop?
Czy są jakieś zależności między Iskra oraz Hadoop?
Jeśli nie, czy są jakieś funkcje, których będę brakowało podczas biegu Iskra Bez Hadoop?
8 answers
Spark może działać bez Hadoop, ale część jego funkcjonalności opiera się na kodzie Hadoop (np. obsługa plików parkietowych). Uruchamiamy Spark na Mesos i S3, który był trochę trudny do skonfigurowania, ale działa naprawdę dobrze po wykonaniu (możesz przeczytać podsumowanie tego, co potrzebne do prawidłowego ustawienia tutaj).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-08-15 12:00:06
Spark jest rozproszonym silnikiem obliczeniowym w pamięci.
Hadoop jest frameworkiem dla distributed storage (HDFS) i distributed processing ( YARN).
Spark może pracować z komponentami Hadoop lub bez nich (HDFS/YARN)
Rozproszona Pamięć Masowa:
Ponieważ Spark nie ma własnego rozproszonego systemu przechowywania, musi zależeć od jednego z tych systemów przechowywania dla rozproszonego Informatyka.
S3 - nie-pilne zadania wsadowe. S3 pasuje do bardzo konkretnych przypadków użycia, gdy lokalizacja danych nie jest krytyczna.
Cassandra - Idealny do strumieniowej analizy danych i przesady Dla zadań wsadowych.
HDFS - doskonale nadaje się do zadań wsadowych bez uszczerbku dla lokalizacji danych.
przetwarzanie rozproszone:
Możesz uruchomić Spark w trzech różnych trybach: Standalone, YARN i Mesos
Mieć spójrz na poniższe pytanie SE, aby uzyskać szczegółowe wyjaśnienie zarówno rozproszonej pamięci masowej, jak i rozproszonego przetwarzania.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-23 12:26:35
Domyślnie Spark nie posiada mechanizmu przechowywania.
Do przechowywania danych potrzebny jest szybki i skalowalny system plików. Możesz użyć S3 lub HDFS lub dowolnego innego systemu plików. Hadoop jest ekonomiczną opcją ze względu na niski koszt.
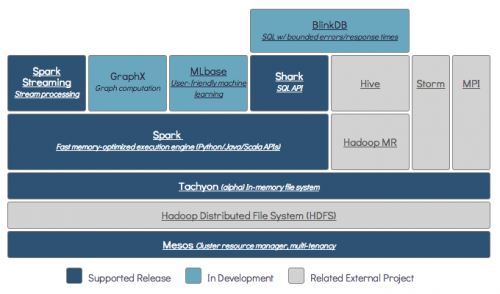
DODATKOWO, jeśli używasz Tachion, zwiększy to wydajność z Hadoop. Jest to wysoce zalecane Hadoop do przetwarzania apache spark .
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-07-13 20:45:57
Tak, spark może działać bez hadoop. Wszystkie podstawowe funkcje spark będą nadal działać, ale przegapisz takie rzeczy, jak łatwe rozprowadzanie wszystkich plików (kodu, a także danych) do wszystkich węzłów w klastrze za pośrednictwem hdfs itp.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-08-15 07:28:46
Tak, można zainstalować Spark bez Hadoop. To byłoby trochę trudne. Możesz odwołać się do arnon link, aby użyć parquet do skonfigurowania na S3 jako przechowywania danych. http://arnon.me/2015/08/spark-parquet-s3/
Spark jest tylko do przetwarzania i używa pamięci dynamicznej do wykonania zadania, ale do przechowywania danych potrzebujesz jakiegoś systemu przechowywania danych. Tutaj hadoop wchodzi w rolę Spark, zapewnia miejsce do przechowywania Spark. Jeszcze jeden powód dla korzystania z Hadoop z Spark jest to, że są one open source i oba mogą łatwo integrować się ze sobą w porównaniu do innych systemów przechowywania danych. W przypadku innych magazynów, takich jak S3, powinieneś być trudny do skonfigurowania, jak wzmianka w powyższym linku.
Ale Hadoop ma również swoją jednostkę przetwarzania zwaną Mapreduce.
Chcesz poznać różnicę w obu?
Zobacz ten artykuł: https://www.dezyre.com/article/hadoop-mapreduce-vs-apache-spark-who-wins-the-battle/83
Myślę, że ten artykuł pomoże Ci zrozumieć
-
Czego używać,
Kiedy stosować i
Jak używać !!!
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-01-17 00:47:55
Zgodnie z dokumentacją Spark, Spark może działać bez Hadoop.
Można go uruchomić jako samodzielny tryb bez żadnego Menedżera zasobów.
Ale jeśli chcesz uruchomić w konfiguracji wielu węzłów, potrzebujesz Menedżera zasobów, takiego jak YARN lub Mesos i rozproszonego systemu plików, takiego jak HDFS, S3 itp.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-06-07 15:38:16
Tak, oczywiście. Spark jest niezależnym frameworkiem obliczeniowym. Hadoop jest dystrybucyjnym systemem pamięci masowej (HDFS) z frameworkiem obliczeniowym MapReduce. Spark może pobierać dane z HDFS, a także z dowolnego innego źródła danych, takiego jak tradycyjna baza danych(JDBC), kafka lub nawet dysk lokalny.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-08-18 15:12:26
Nie. Wymaga pełnej instalacji Hadoop do rozpoczęcia pracy - https://issues.apache.org/jira/browse/SPARK-10944
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-10-09 09:40:25