Grupowanie funkcji (tapply, by, aggregate) i rodziny * apply
Kiedy chcę zrobić coś "map"py w R, zwykle staram się użyć funkcji z rodziny apply.
Jednak nigdy do końca nie rozumiałem różnic między nimi-jak {sapply, lapply, itd.} zastosuj funkcję do wejścia / zgrupowania wejścia, jak będzie wyglądać wyjście, a nawet jakie może być wejście -- więc często po prostu przeglądam je wszystkie, dopóki nie dostanę tego, czego chcę.
Czy ktoś może wyjaśnić jak używać który kiedy?
Mój obecny (prawdopodobnie niepoprawne/niekompletne) rozumienie jest...
-
sapply(vec, f): Wejście jest wektorem. wyjście jest wektorem / macierzą, gdzie elementijestf(vec[i]), dając macierz, JeślifmA wyjście wieloelementowe lapply(vec, f): to samo cosapply, ale wyjście jest listą?-
apply(matrix, 1/2, f): Wejście jest macierzą. wyjście jest wektorem, gdzie elementijest f (wiersz / col i macierzy) -
tapply(vector, grouping, f): wyjście jest macierzą / tablicą, gdzie element w macierzy / tablicy jest wartościąfw grupowaniegwektora i {[13] } zostaje przesunięte do nazw wierszy / col -
by(dataframe, grouping, f): niechgbędzie zbiorem. Zastosujfdo każdej kolumny grupy / ramki danych. pretty wyświetla grupowanie i wartośćfw każdej kolumnie. -
aggregate(matrix, grouping, f): podobne doby, ale zamiast ładnego drukowania danych wyjściowych, agregat przykleja wszystko do ramki danych.
Pytanie poboczne: nadal nie nauczyłam się plyra czy przeformułowania -- czy plyr czy reshape zastąpić te wszystkie całkowicie?
9 answers
R posiada wiele funkcji * apply, które są umiejętnie opisane w plikach pomocy (np. ?apply). Jest ich jednak dość, że początkujący użytkownicy mogą mieć trudności z podjęciem decyzji, który z nich jest odpowiedni dla ich sytuacji, a nawet zapamiętaniem ich wszystkich. Mogą mieć ogólne poczucie, że "powinienem używać funkcji * apply tutaj", ale może być trudno utrzymać je wszystkie prosto na początku.
Pomimo faktu (zaznaczonego w innych odpowiedziach), że duża część funkcjonalności rodziny * apply jest objęte niezwykle popularnym pakietem plyr, podstawowe funkcje pozostają użyteczne i warte poznania.
Ta odpowiedź ma działać jako drogowskaz dla nowych użytkowników, aby pomóc im w przekierowaniu do właściwej funkcji *apply dla konkretnego problemu. Uwaga, jest to nie przeznaczone po prostu do zwrócenia lub zastąpienia dokumentacji R! Mamy nadzieję, że ta odpowiedź pomoże Ci zdecydować ,która funkcja * zastosuj odpowiada twojej sytuacji, a następnie do ciebie należy jej zbadanie dalej. Z jednym wyjątkiem różnice w wydajności nie będą rozwiązywane.
-
Zastosuj - gdy chcesz zastosować funkcję do wierszy lub kolumn macierzy (i analogów wyższych wymiarów); zazwyczaj nie jest to wskazane dla ramek danych, ponieważ najpierw zostanie wymuszone na macierzy.
# Two dimensional matrix M <- matrix(seq(1,16), 4, 4) # apply min to rows apply(M, 1, min) [1] 1 2 3 4 # apply max to columns apply(M, 2, max) [1] 4 8 12 16 # 3 dimensional array M <- array( seq(32), dim = c(4,4,2)) # Apply sum across each M[*, , ] - i.e Sum across 2nd and 3rd dimension apply(M, 1, sum) # Result is one-dimensional [1] 120 128 136 144 # Apply sum across each M[*, *, ] - i.e Sum across 3rd dimension apply(M, c(1,2), sum) # Result is two-dimensional [,1] [,2] [,3] [,4] [1,] 18 26 34 42 [2,] 20 28 36 44 [3,] 22 30 38 46 [4,] 24 32 40 48Jeśli chcesz, aby wiersz / kolumna oznacza lub sumy dla macierzy 2D, upewnij się, że zbadaj wysoce zoptymalizowany, błyskawiczny
colMeans,rowMeans,colSums,rowSums. -
Lapply - gdy chcesz zastosować funkcję do każdego elementu lista po kolei i dostać listę z powrotem.
Jest to koń pociągowy wielu innych funkcji * apply. Skórka Cofnij ich kod, a często znajdziesz
lapplypod spodem.x <- list(a = 1, b = 1:3, c = 10:100) lapply(x, FUN = length) $a [1] 1 $b [1] 3 $c [1] 91 lapply(x, FUN = sum) $a [1] 1 $b [1] 6 $c [1] 5005 -
Sapply - gdy chcesz zastosować funkcję do każdego elementu lista z kolei, ale chcesz wektor Z powrotem, a nie lista.
Jeśli znajdziesz się pisząc
unlist(lapply(...)), zatrzymaj się i rozważsapply.x <- list(a = 1, b = 1:3, c = 10:100) # Compare with above; a named vector, not a list sapply(x, FUN = length) a b c 1 3 91 sapply(x, FUN = sum) a b c 1 6 5005W bardziej zaawansowanych zastosowaniach {[21] } będzie próbował zmusić wynik do tablicy wielowymiarowej, jeśli jest to właściwe. Na przykład, jeśli nasza funkcja zwróci wektory o tej samej długości,
sapplyużyje ich jako kolumn macierzy:sapply(1:5,function(x) rnorm(3,x))Jeśli nasza funkcja zwróci macierz dwuwymiarową,
sapplyzrobi zasadniczo to samo, traktując każdą zwróconą macierz jako jedną długą wektor:sapply(1:5,function(x) matrix(x,2,2))Jeśli nie określimy
simplify = "array", W takim przypadku będzie on używał poszczególnych macierzy do zbudowania wielowymiarowej tablicy:sapply(1:5,function(x) matrix(x,2,2), simplify = "array")Każde z tych zachowań jest oczywiście zależne od naszej funkcji zwracającej wektory lub macierze o tej samej długości lub wymiarze.
-
Vapply - kiedy chcesz użyć
sapply, ale być może potrzebujesz wyciśnij więcej prędkości z kodu.Dla
vapply, W zasadzie dajesz r przykład jakie rzeczy twoja funkcja powróci, co może zaoszczędzić trochę czasu wartości mieszczące się w jednym wektorze atomowym.x <- list(a = 1, b = 1:3, c = 10:100) #Note that since the advantage here is mainly speed, this # example is only for illustration. We're telling R that # everything returned by length() should be an integer of # length 1. vapply(x, FUN = length, FUN.VALUE = 0L) a b c 1 3 91 -
Mapply - gdy masz kilka struktur danych (np. wektory, listy) i chcesz zastosować funkcję do 1 elementów każdego, a następnie 2 elementy każdego, itp., wymuszanie wyniku do wektora / tablicy jak w
sapply.Jest to wielowymiarowe w tym sensie, że twoja funkcja musi Akceptuj wiele argumentów.
#Sums the 1st elements, the 2nd elements, etc. mapply(sum, 1:5, 1:5, 1:5) [1] 3 6 9 12 15 #To do rep(1,4), rep(2,3), etc. mapply(rep, 1:4, 4:1) [[1]] [1] 1 1 1 1 [[2]] [1] 2 2 2 [[3]] [1] 3 3 [[4]] [1] 4 -
Mapka - wrapper do
mapplyZSIMPLIFY = FALSE, więc jest gwarantowane zwrócenie listy.Map(sum, 1:5, 1:5, 1:5) [[1]] [1] 3 [[2]] [1] 6 [[3]] [1] 9 [[4]] [1] 12 [[5]] [1] 15 -
Rapply - jeśli chcesz zastosować funkcję do każdego elementu struktury zagnieżdżonej listy, rekurencyjnie.
Aby dać ci trochę pojęcia, jak rzadko
rapplyjest, zapomniałem o tym, gdy po raz pierwszy publikując tę odpowiedź! Oczywiście, jestem pewien, że wiele osób go używa, ale YMMV.rapplynajlepiej zilustrować za pomocą funkcji zdefiniowanej przez użytkownika do zastosowania:# Append ! to string, otherwise increment myFun <- function(x){ if(is.character(x)){ return(paste(x,"!",sep="")) } else{ return(x + 1) } } #A nested list structure l <- list(a = list(a1 = "Boo", b1 = 2, c1 = "Eeek"), b = 3, c = "Yikes", d = list(a2 = 1, b2 = list(a3 = "Hey", b3 = 5))) # Result is named vector, coerced to character rapply(l, myFun) # Result is a nested list like l, with values altered rapply(l, myFun, how="replace") -
Tapply - Dla gdy chcesz zastosować funkcję do podzbiorów Z wektor i podzbiory są określone przez jakiś inny wektor, Zwykle factor.
Czarna owca z rodziny * apply. Korzystanie z pliku pomocy fraza "ragged array" może być nieco myląca, ale w rzeczywistości jest całkiem proste.A wektor:
x <- 1:20Współczynnik (tej samej długości!) definiowanie grup:
y <- factor(rep(letters[1:5], each = 4))Dodaj wartości w
xw każdej podgrupie zdefiniowanej przezy:tapply(x, y, sum) a b c d e 10 26 42 58 74Bardziej złożone przykłady mogą być obsługiwane, gdy podgrupy są zdefiniowane przez unikalne kombinacje listy kilku czynników.
tapplyjest podobne w duchu do funkcji split-apply-combine, które są często w R (aggregate,by,ave,ddply, itd.) Stąd jego status czarnej owcy.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-10-03 19:54:11
Na marginesie, oto jak różne funkcje plyr odpowiadają funkcjom bazowym *apply (z intro do dokumentu plyr ze strony internetowej plyr http://had.co.nz/plyr/)
Base function Input Output plyr function
---------------------------------------
aggregate d d ddply + colwise
apply a a/l aaply / alply
by d l dlply
lapply l l llply
mapply a a/l maply / mlply
replicate r a/l raply / rlply
sapply l a laply
Jednym z celów plyr jest zapewnienie spójnych konwencji nazewnictwa dla każdej z funkcji, kodowanie wejściowych i wyjściowych typów danych w nazwie funkcji. Zapewnia również spójność wyjściową, ponieważ wyjście z dlply() jest łatwo przejezdne do ldply(), aby uzyskać użyteczne wyjście, itd.
plyr nie jest trudniejsze niż zrozumienie podstawowych funkcji *apply.
plyr i reshape Funkcje zastąpiły prawie wszystkie te funkcje w moim codziennym użytkowaniu. Ale również z Intro do dokumentu Plyr:
Powiązane funkcje
tapplyisweepnie mają odpowiedniej funkcji wplyri pozostają użyteczne. {[13] } jest przydatny do łączenia podsumowań z oryginalnymi danymi.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-08-17 19:20:09
Ze slajdu 21 z http://www.slideshare.net/hadley/plyr-one-data-analytic-strategy :
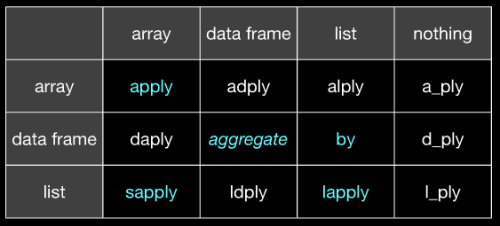
(miejmy nadzieję, że jest jasne, że apply odpowiada aaply @Hadley i aggregate odpowiada ddply @Hadley itd. Slajd 20 tego samego slideshare wyjaśni, jeśli nie dostaniesz go z tego obrazu.)
(po lewej stronie jest wejście, na górze jest wyjście)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-02-15 23:42:48
Zacznij od doskonałej odpowiedzi Jorana -- wątpliwe, że wszystko może to poprawić.
Następnie następujące mnemotechniki mogą pomóc zapamiętać rozróżnienia między każdym z nich. Podczas gdy niektóre są oczywiste, inne mogą być mniej - - - dla nich znajdziesz uzasadnienie w dyskusjach Jorana.
Mnemotechnika
-
lapplyjest listą, która działa na liście lub wektorze i zwraca listę. -
sapplyjest prostąlapply(funkcja domyślnie zwraca wektor lub macierz, jeśli to możliwe) -
vapplyis a verified apply (pozwala na zdefiniowanie typu obiektu zwrotnego) -
rapplyjest rekurencyjnym stosowanym do list zagnieżdżonych, czyli list wewnątrz list -
tapplyjest otagowane zastosuj, gdzie znaczniki identyfikują podzbiory -
applyjest ogólnym : stosuje funkcję do wierszy lub kolumn macierzy (lub, bardziej ogólnie, do wymiarów array)
Budowanie WŁAŚCIWEGO tła
Jeśli Korzystanie z rodziny apply nadal wydaje ci się trochę obce, to może być tak, że brakuje Ci kluczowego punktu widzenia.
Te dwa artykuły mogą pomóc. Stanowią one niezbędne zaplecze do motywowania technik programowania funkcyjnego , które są dostarczane przez rodzinę funkcji apply.
Użytkownicy Lispu natychmiast rozpozna paradygmat. Jeśli nie jesteś zaznajomiony z Lisp, gdy już opanujesz FP, zyskasz potężny punkt widzenia do użycia w R -- i apply będzie miał o wiele więcej sensu.
- W 2006 roku został wybrany na stanowisko Dyrektora ds.]}
- W 2005 roku został wybrany na stanowisko dyrektora ds.]}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-23 10:31:37
Ponieważ zdałem sobie sprawę, że (bardzo doskonałe) odpowiedzi tego postu brak by i aggregate wyjaśnienia. Oto mój wkład.
BY
Funkcja by, jak podano w dokumentacji, może być jednak "opakowaniem" dla tapply. Moc by powstaje, gdy chcemy obliczyć zadanie, z którym tapply nie poradzi sobie. Jednym z przykładów jest ten kod:
ct <- tapply(iris$Sepal.Width , iris$Species , summary )
cb <- by(iris$Sepal.Width , iris$Species , summary )
cb
iris$Species: setosa
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.300 3.200 3.400 3.428 3.675 4.400
--------------------------------------------------------------
iris$Species: versicolor
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.000 2.525 2.800 2.770 3.000 3.400
--------------------------------------------------------------
iris$Species: virginica
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.200 2.800 3.000 2.974 3.175 3.800
ct
$setosa
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.300 3.200 3.400 3.428 3.675 4.400
$versicolor
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.000 2.525 2.800 2.770 3.000 3.400
$virginica
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.200 2.800 3.000 2.974 3.175 3.800
Jeśli wydrukujemy te dwa obiekty, ct i cb," zasadniczo " mamy te same wyniki i tylko różnice dotyczą sposobu ich wyświetlania oraz różnych atrybutów class, odpowiednio by dla cb i array dla ct.
Jak już powiedziałem, moc by powstaje, gdy nie możemy użyć tapply; poniższy kod jest jednym z przykładów:
tapply(iris, iris$Species, summary )
Error in tapply(iris, iris$Species, summary) :
arguments must have same length
R mówi, że argumenty muszą mieć takie same długości, powiedzmy " chcemy obliczyć summary wszystkich zmiennych w iris wzdłuż czynnika Species": ale R po prostu nie może tego zrobić, ponieważ nie wie, jak sobie z tym poradzić.
Z by funkcja R wysyła określoną metodę dla klasy data frame, a następnie niech funkcja summary Działa nawet wtedy, gdy długość pierwszego argumentu (a także Typ) są różne.
bywork <- by(iris, iris$Species, summary )
bywork
iris$Species: setosa
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
Min. :4.300 Min. :2.300 Min. :1.000 Min. :0.100 setosa :50
1st Qu.:4.800 1st Qu.:3.200 1st Qu.:1.400 1st Qu.:0.200 versicolor: 0
Median :5.000 Median :3.400 Median :1.500 Median :0.200 virginica : 0
Mean :5.006 Mean :3.428 Mean :1.462 Mean :0.246
3rd Qu.:5.200 3rd Qu.:3.675 3rd Qu.:1.575 3rd Qu.:0.300
Max. :5.800 Max. :4.400 Max. :1.900 Max. :0.600
--------------------------------------------------------------
iris$Species: versicolor
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
Min. :4.900 Min. :2.000 Min. :3.00 Min. :1.000 setosa : 0
1st Qu.:5.600 1st Qu.:2.525 1st Qu.:4.00 1st Qu.:1.200 versicolor:50
Median :5.900 Median :2.800 Median :4.35 Median :1.300 virginica : 0
Mean :5.936 Mean :2.770 Mean :4.26 Mean :1.326
3rd Qu.:6.300 3rd Qu.:3.000 3rd Qu.:4.60 3rd Qu.:1.500
Max. :7.000 Max. :3.400 Max. :5.10 Max. :1.800
--------------------------------------------------------------
iris$Species: virginica
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
Min. :4.900 Min. :2.200 Min. :4.500 Min. :1.400 setosa : 0
1st Qu.:6.225 1st Qu.:2.800 1st Qu.:5.100 1st Qu.:1.800 versicolor: 0
Median :6.500 Median :3.000 Median :5.550 Median :2.000 virginica :50
Mean :6.588 Mean :2.974 Mean :5.552 Mean :2.026
3rd Qu.:6.900 3rd Qu.:3.175 3rd Qu.:5.875 3rd Qu.:2.300
Max. :7.900 Max. :3.800 Max. :6.900 Max. :2.500
by, która wzdłuż Species (powiedzmy, dla każdej z nich) oblicza summary każdej zmiennej.
Zauważ, że jeśli pierwszym argumentem jest data frame, wywołana funkcja musi mieć metodę dla tej klasy obiektów. Na przykład my użyj tego kodu z funkcją mean będziemy mieli ten kod, który w ogóle nie ma sensu:
by(iris, iris$Species, mean)
iris$Species: setosa
[1] NA
-------------------------------------------
iris$Species: versicolor
[1] NA
-------------------------------------------
iris$Species: virginica
[1] NA
Warning messages:
1: In mean.default(data[x, , drop = FALSE], ...) :
argument is not numeric or logical: returning NA
2: In mean.default(data[x, , drop = FALSE], ...) :
argument is not numeric or logical: returning NA
3: In mean.default(data[x, , drop = FALSE], ...) :
argument is not numeric or logical: returning NA
Agregat
aggregate może być postrzegany jako inny inny sposób użycia tapply, jeśli używamy go w taki sposób.
at <- tapply(iris$Sepal.Length , iris$Species , mean)
ag <- aggregate(iris$Sepal.Length , list(iris$Species), mean)
at
setosa versicolor virginica
5.006 5.936 6.588
ag
Group.1 x
1 setosa 5.006
2 versicolor 5.936
3 virginica 6.588
Dwie bezpośrednie różnice są takie, że drugi argument aggregate must be a list while tapply może (nieobowiązkowe) być listą i że wyjście aggregate jest ramką danych, podczas gdy wyjście tapply jest array.
The power z aggregate jest to, że może obsługiwać łatwo podzbiory danych z argumentem subset oraz że ma metody dla obiektów ts i formula.
Te elementy ułatwiają aggregate pracę z tym tapply w niektórych sytuacjach.
Oto kilka przykładów (dostępnych w dokumentacji):
ag <- aggregate(len ~ ., data = ToothGrowth, mean)
ag
supp dose len
1 OJ 0.5 13.23
2 VC 0.5 7.98
3 OJ 1.0 22.70
4 VC 1.0 16.77
5 OJ 2.0 26.06
6 VC 2.0 26.14
Możemy osiągnąć to samo z tapply, ale składnia jest nieco trudniejsza, a wyjście (w niektórych okolicznościach) mniej czytelne:
att <- tapply(ToothGrowth$len, list(ToothGrowth$dose, ToothGrowth$supp), mean)
att
OJ VC
0.5 13.23 7.98
1 22.70 16.77
2 26.06 26.14
Są inne czasy, kiedy nie możemy użyć by lub {[14] } i musimy użyć aggregate.
ag1 <- aggregate(cbind(Ozone, Temp) ~ Month, data = airquality, mean)
ag1
Month Ozone Temp
1 5 23.61538 66.73077
2 6 29.44444 78.22222
3 7 59.11538 83.88462
4 8 59.96154 83.96154
5 9 31.44828 76.89655
Nie możemy uzyskać poprzedniego wyniku za pomocą tapply w jednym wywołaniu, ale musimy obliczyć średnią wzdłuż Month dla każdego elementu, a następnie połączyć je (należy również pamiętać, że musimy wywołać na.rm = TRUE, ponieważ metody formula funkcji aggregate mają domyślnie na.action = na.omit):
ta1 <- tapply(airquality$Ozone, airquality$Month, mean, na.rm = TRUE)
ta2 <- tapply(airquality$Temp, airquality$Month, mean, na.rm = TRUE)
cbind(ta1, ta2)
ta1 ta2
5 23.61538 65.54839
6 29.44444 79.10000
7 59.11538 83.90323
8 59.96154 83.96774
9 31.44828 76.90000
Podczas gdy z by po prostu nie możemy tego osiągnąć w rzeczywistości poniższe wywołanie funkcji zwraca błąd (ale najprawdopodobniej jest to związane z dostarczonym funkcja, mean):
by(airquality[c("Ozone", "Temp")], airquality$Month, mean, na.rm = TRUE)
Innym razem wyniki są takie same, a różnice są tylko w klasie (a następnie w jaki sposób jest wyświetlany/drukowany i nie tylko -- przykład, jak go podzestawić) obiekt:
byagg <- by(airquality[c("Ozone", "Temp")], airquality$Month, summary)
aggagg <- aggregate(cbind(Ozone, Temp) ~ Month, data = airquality, summary)
Poprzedni kod osiąga ten sam cel i wyniki, w niektórych punktach to, jakiego narzędzia użyć, jest tylko kwestią osobistych gustów i potrzeb; dwa poprzednie obiekty mają bardzo różne potrzeby pod względem podzbioru.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-08-28 10:03:08
Istnieje wiele świetnych odpowiedzi, które omawiają różnice w przypadkach użycia dla każdej funkcji. Żadna z odpowiedzi nie omawia różnic w wydajności. Jest to rozsądne, ponieważ różne funkcje oczekują różnych danych wejściowych i wytwarzają różne dane wyjściowe, ale większość z nich ma ogólny wspólny cel do oceny według serii/grup. Moja odpowiedź będzie skupiać się na wydajności. Ze względu na to, że tworzenie danych wejściowych z wektorów jest uwzględniane w czasie, również funkcja apply nie jest mierzona.
Przetestowałem dwie różne funkcje sum i length na raz. Testowana głośność to 50M na wejściu i 50k na wyjściu. Dodałem również dwa obecnie popularne pakiety, które nie były powszechnie używane w czasie zadawania pytań, data.table i dplyr. Oba są zdecydowanie warto szukać, jeśli dążysz do dobrej wydajności.
library(dplyr)
library(data.table)
set.seed(123)
n = 5e7
k = 5e5
x = runif(n)
grp = sample(k, n, TRUE)
timing = list()
# sapply
timing[["sapply"]] = system.time({
lt = split(x, grp)
r.sapply = sapply(lt, function(x) list(sum(x), length(x)), simplify = FALSE)
})
# lapply
timing[["lapply"]] = system.time({
lt = split(x, grp)
r.lapply = lapply(lt, function(x) list(sum(x), length(x)))
})
# tapply
timing[["tapply"]] = system.time(
r.tapply <- tapply(x, list(grp), function(x) list(sum(x), length(x)))
)
# by
timing[["by"]] = system.time(
r.by <- by(x, list(grp), function(x) list(sum(x), length(x)), simplify = FALSE)
)
# aggregate
timing[["aggregate"]] = system.time(
r.aggregate <- aggregate(x, list(grp), function(x) list(sum(x), length(x)), simplify = FALSE)
)
# dplyr
timing[["dplyr"]] = system.time({
df = data_frame(x, grp)
r.dplyr = summarise(group_by(df, grp), sum(x), n())
})
# data.table
timing[["data.table"]] = system.time({
dt = setnames(setDT(list(x, grp)), c("x","grp"))
r.data.table = dt[, .(sum(x), .N), grp]
})
# all output size match to group count
sapply(list(sapply=r.sapply, lapply=r.lapply, tapply=r.tapply, by=r.by, aggregate=r.aggregate, dplyr=r.dplyr, data.table=r.data.table),
function(x) (if(is.data.frame(x)) nrow else length)(x)==k)
# sapply lapply tapply by aggregate dplyr data.table
# TRUE TRUE TRUE TRUE TRUE TRUE TRUE
# print timings
as.data.table(sapply(timing, `[[`, "elapsed"), keep.rownames = TRUE
)[,.(fun = V1, elapsed = V2)
][order(-elapsed)]
# fun elapsed
#1: aggregate 109.139
#2: by 25.738
#3: dplyr 18.978
#4: tapply 17.006
#5: lapply 11.524
#6: sapply 11.326
#7: data.table 2.686
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-12-08 22:50:30
Być może warto wspomnieć ave. To przyjacielski kuzyn. Zwraca wyniki w formie, którą można podłączyć z powrotem do ramki danych.
dfr <- data.frame(a=1:20, f=rep(LETTERS[1:5], each=4))
means <- tapply(dfr$a, dfr$f, mean)
## A B C D E
## 2.5 6.5 10.5 14.5 18.5
## great, but putting it back in the data frame is another line:
dfr$m <- means[dfr$f]
dfr$m2 <- ave(dfr$a, dfr$f, FUN=mean) # NB argument name FUN is needed!
dfr
## a f m m2
## 1 A 2.5 2.5
## 2 A 2.5 2.5
## 3 A 2.5 2.5
## 4 A 2.5 2.5
## 5 B 6.5 6.5
## 6 B 6.5 6.5
## 7 B 6.5 6.5
## ...
W pakiecie podstawowym nie ma nic, co by działało jak ave dla całych ramek danych (tak jak by jest jak tapply dla ramek danych). Ale można to zrobić:
dfr$foo <- ave(1:nrow(dfr), dfr$f, FUN=function(x) {
x <- dfr[x,]
sum(x$m*x$m2)
})
dfr
## a f m m2 foo
## 1 1 A 2.5 2.5 25
## 2 2 A 2.5 2.5 25
## 3 3 A 2.5 2.5 25
## ...
Pomimo wszystkich wspaniałych odpowiedzi tutaj, są jeszcze 2 funkcje podstawowe, które zasługują na wzmiankę, użyteczna outer Funkcja i niejasne eapply funkcja
Zewnętrzne
outer to bardzo przydatna funkcja ukryta jako bardziej przyziemna. Jeśli czytasz pomoc dla outer jej opis mówi:
The outer product of the arrays X and Y is the array A with dimension
c(dim(X), dim(Y)) where element A[c(arrayindex.x, arrayindex.y)] =
FUN(X[arrayindex.x], Y[arrayindex.y], ...).
Co sprawia, że wydaje się, że jest to przydatne tylko dla rzeczy typu algebry liniowej. Można jednak użyć podobnie jak mapply, aby zastosować funkcję do dwóch wektorów wejścia. Różnica polega na tym, że mapply zastosuje funkcję do dwóch pierwszych elementów, a następnie do dwóch drugich itd., podczas gdy outer zastosuje funkcję do każdej kombinacji jednego elementu z pierwszego wektora i jednego z drugiego. Na przykład:
A<-c(1,3,5,7,9)
B<-c(0,3,6,9,12)
mapply(FUN=pmax, A, B)
> mapply(FUN=pmax, A, B)
[1] 1 3 6 9 12
outer(A,B, pmax)
> outer(A,B, pmax)
[,1] [,2] [,3] [,4] [,5]
[1,] 1 3 6 9 12
[2,] 3 3 6 9 12
[3,] 5 5 6 9 12
[4,] 7 7 7 9 12
[5,] 9 9 9 9 12
Osobiście użyłem tego, gdy mam wektor wartości i Wektor warunków i chcę zobaczyć, które wartości spełniają które Warunki.
Eapply
eapply jest jak lapply z tym, że zamiast zastosowanie funkcji do każdego elementu na liście, to stosuje funkcję do każdego elementu w środowisku. Na przykład, jeśli chcesz znaleźć listę funkcji zdefiniowanych przez użytkownika w środowisku globalnym:
A<-c(1,3,5,7,9)
B<-c(0,3,6,9,12)
C<-list(x=1, y=2)
D<-function(x){x+1}
> eapply(.GlobalEnv, is.function)
$A
[1] FALSE
$B
[1] FALSE
$C
[1] FALSE
$D
[1] TRUE
Szczerze mówiąc nie używam tego zbyt często, ale jeśli budujesz wiele pakietów lub tworzysz wiele środowisk, może się to przydać.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-06-03 13:37:53
Niedawno odkryłem dość przydatną funkcję sweep i dodałem ją tutaj dla kompletności:
Sweep
Podstawową ideą jest zamiatanie przez tablicę w wierszu lub kolumnie i zwracanie zmodyfikowanej tablicy. Przykład to wyjaśni (Źródło: datacamp):
Powiedzmy, że masz macierz i chcesz standaryzować to:
dataPoints <- matrix(4:15, nrow = 4)
# Find means per column with `apply()`
dataPoints_means <- apply(dataPoints, 2, mean)
# Find standard deviation with `apply()`
dataPoints_sdev <- apply(dataPoints, 2, sd)
# Center the points
dataPoints_Trans1 <- sweep(dataPoints, 2, dataPoints_means,"-")
print(dataPoints_Trans1)
## [,1] [,2] [,3]
## [1,] -1.5 -1.5 -1.5
## [2,] -0.5 -0.5 -0.5
## [3,] 0.5 0.5 0.5
## [4,] 1.5 1.5 1.5
# Return the result
dataPoints_Trans1
## [,1] [,2] [,3]
## [1,] -1.5 -1.5 -1.5
## [2,] -0.5 -0.5 -0.5
## [3,] 0.5 0.5 0.5
## [4,] 1.5 1.5 1.5
# Normalize
dataPoints_Trans2 <- sweep(dataPoints_Trans1, 2, dataPoints_sdev, "/")
# Return the result
dataPoints_Trans2
## [,1] [,2] [,3]
## [1,] -1.1618950 -1.1618950 -1.1618950
## [2,] -0.3872983 -0.3872983 -0.3872983
## [3,] 0.3872983 0.3872983 0.3872983
## [4,] 1.1618950 1.1618950 1.1618950
NB: dla tego prostego przykładu ten sam wynik można oczywiście osiągnąć więcej łatwo przezapply(dataPoints, 2, scale)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-06-16 16:03:27