Cel wyrównania pamięci
Nie rozumiem. Powiedzmy, że masz pamięć ze słowem pamięci o długości 1 bajtu. Dlaczego nie można uzyskać dostępu do zmiennej o długości 4 bajtów w jednym dostępie do pamięci na niepodpisanym adresie (tzn. nie podzielnym przez 4), Jak to ma miejsce w przypadku wyrównanych adresów?
8 answers
To ograniczenie wielu podstawowych procesorów. Zwykle można to obejść, wykonując 4 nieefektywne pobieranie pojedynczych bajtów zamiast jednego efektywnego pobierania słów, ale wielu specyfikatorów języka zdecydowało, że łatwiej będzie je zakazać i zmusić do wyrównania wszystkiego.
Jest o wiele więcej informacji w tym linku , który odkrył OP.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2008-12-19 17:39:22
[[3]}podsystem pamięci w nowoczesnym procesorze jest ograniczony do dostępu do pamięci przy ziarnistości i wyrównaniu jej rozmiaru słowa; dzieje się tak z wielu powodów.
Speed
[3]}nowoczesne procesory mają wiele poziomów pamięci podręcznej, przez które dane muszą być pobierane; obsługa odczytów jednobajtowych sprawiłaby, że przepustowość podsystemu pamięci byłaby ściśle powiązana z przepustowością jednostki wykonawczej (aka CPU-bound); wszystko to przypomina, jak tryb PIO został przekroczony przez DMA z wielu tych samych powodów w dyskach twardych.PROCESOR zawsze odczytuje swój rozmiar słowa (4 bajty na 32-bitowym procesorze), więc kiedy wykonasz niepodpisany dostęp do adresu-na procesorze, który go obsługuje-procesor będzie odczytywał wiele słów. Procesor odczyta każde słowo pamięci, które zawiera żądany adres. Powoduje to zwiększenie do 2X liczby transakcji pamięci wymaganych do uzyskania dostępu do żądanych danych.
Z tego powodu, to bardzo łatwo może być wolniej odczytać dwa bajty niż cztery. Na przykład, powiedzmy, że masz strukturę w pamięci, która wygląda tak:
struct mystruct {
char c; // one byte
int i; // four bytes
short s; // two bytes
}
Na 32-bitowym procesorze najprawdopodobniej będzie wyrównany jak pokazano tutaj:
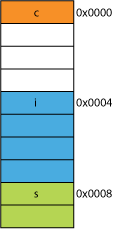
Procesor może odczytać każdy z tych członków w jednej transakcji.
Powiedzmy, że masz spakowaną wersję struktury, może z sieci, w której została spakowana dla wydajności transmisji; może wyglądać to jak to:
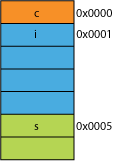
Odczyt pierwszego bajtu będzie taki sam.
Kiedy poprosisz procesor o podanie 16 bitów z 0x0005, będzie musiał odczytać słowo z 0x0004 i przesunąć w lewo 1 bajt, aby umieścić je w rejestrze 16-bitowym; trochę dodatkowej pracy, ale większość może to obsłużyć w jednym cyklu.
Gdy poprosisz o 32 bity z 0x0001 otrzymasz wzmocnienie 2X. Procesor odczyta z 0x0000 do rejestru wyników i przesunie w lewo 1 bajt, a następnie ponownie odczyta z 0x0004 do rejestru tymczasowego, przesuń w prawo 3 bajty, a następnie OR go z rejestrem wynikowym.
Zakres
Dla dowolnej przestrzeni adresowej, jeśli architektura może założyć, że 2 LSB są zawsze 0 (np. maszyny 32-bitowe), to może uzyskać dostęp do 4 razy więcej pamięci (2 zapisane bity mogą reprezentować 4 różne stany), lub taką samą ilość pamięci z 2 bitami dla czegoś takiego jak flagi. Usunięcie 2 LSBs z adresu daje wyrównanie 4-bajtowe; zwane również stride z 4 bajtów. Za każdym razem, gdy adres jest zwiększany, efektywnie zwiększa się bit 2, a nie bit 0, tzn. ostatnie 2 bity zawsze będą 00.
Atomicity
Procesor może działać na wyrównanym słowie pamięci atomicznie, co oznacza, że żadna inna instrukcja nie może przerwać Ta operacja. Jest to kluczowe dla prawidłowego działania wielu struktur danych bez blokady i innych paradygmatów współbieżności.
Podsumowanie
System Pamięci PROCESORA jest nieco bardziej złożony i zaangażowany niż opisany tutaj; dyskusja na temat jak procesor x86 faktycznie adresuje pamięć może pomóc (wiele procesorów działa podobnie).
Jest o wiele więcej korzyści z przylegania do wyrównania pamięci, które można przeczytać w to Artykuł IBM .
Podstawowym zastosowaniem komputera jest transformacja danych. Nowoczesne architektury i technologie pamięci zostały zoptymalizowane przez dziesięciolecia, aby ułatwić uzyskiwanie większej ilości danych, wchodzenie, wychodzenie oraz między większą liczbą szybszych jednostek wykonawczych–w wysoce niezawodny sposób.
Bonus: Caches
Innym wyrównaniem dla wydajności, o którym wspomniałem wcześniej, jest wyrównanie na liniach pamięci podręcznej, które są (na przykład na niektórych procesorach) 64B.
Aby uzyskać więcej informacji na temat tego, ile można uzyskać wydajności korzystając z pamięci podręcznej, spójrz na galerię efektów pamięci podręcznej procesora; z tego pytania o rozmiary linii pamięci podręcznej
Zrozumienie linii pamięci podręcznej może być ważne dla niektórych typów optymalizacji programu. Na przykład wyrównanie danych może określać, czy operacja dotyka jednej czy dwóch linii pamięci podręcznej. Jak widzieliśmy w powyższym przykładzie, może to z łatwością oznaczać, że w przypadku niewspółosiowości operacja będzie dwa razy wolniejsza.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-10-21 00:52:02
Możesz z niektórymi procesorami (nehalem może to zrobić), ale wcześniej cały dostęp do pamięci był wyrównany na linii 64-bitowej (lub 32-bitowej), ponieważ szyna ma szerokość 64 bitów, trzeba było pobrać 64 bit na raz, a znacznie łatwiej było pobrać je w wyrównanych "kawałkach" 64 bitów.
Więc, jeśli chcesz uzyskać pojedynczy bajt, pobierasz 64-bitowy fragment, a następnie maskujesz te, których nie chcesz. Łatwo i szybko, jeśli twój bajt był na prawym końcu, ale jeśli był w środku z tego 64-bitowego kawałka, musiałbyś zamaskować niechciane bity, a następnie przesunąć dane we właściwe miejsce. Co gorsza, jeśli chciałeś 2-bajtową zmienną, ale która była podzielona na 2 kawałki, to wymagało to podwójnego wymaganego dostępu do pamięci.
Więc, ponieważ wszyscy myślą, że pamięć jest tania, po prostu sprawili, że kompilator wyrównał dane na kawałkach procesora, aby Twój kod działał szybciej i wydajniej kosztem zmarnowanej pamięci.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2008-12-19 15:31:47
Zasadniczo powodem jest to, że szyna pamięci ma określoną długość, która jest znacznie, znacznie mniejsza niż rozmiar pamięci.
Tak więc procesor odczytuje z wbudowanej pamięci podręcznej L1, która obecnie często ma 32KB. Ale szyna pamięci, która łączy pamięć podręczną L1 z procesorem, będzie miała znacznie mniejszą szerokość linii pamięci podręcznej. Będzie to kolejność 128 bitów.
Więc:
262,144 bits - size of memory
128 bits - size of bus
Nieprawidłowy dostęp będzie czasami nakładał się na dwie linie pamięci podręcznej, a to spowoduje wymaga całkowicie nowego odczytu pamięci podręcznej w celu uzyskania danych. Może nawet przegapić całą drogę do DRAM.
Ponadto, pewna część procesora będzie musiała stanąć na głowie, aby złożyć jeden obiekt z tych dwóch różnych linii pamięci podręcznej, z których każda ma kawałek danych. W jednej linii będzie to w bitach bardzo wysokiego rzędu, w drugiej-w bitach bardzo niskiego rzędu.
Będzie dedykowany sprzęt w pełni zintegrowany z rurociągiem, który obsługuje ruch wyrównany obiektów na niezbędne bity magistrali danych procesora, ale takiego sprzętu może brakować w przypadku obiektów niewspółosiowych, ponieważ prawdopodobnie bardziej sensowne jest używanie tych tranzystorów do przyspieszenia poprawnie zoptymalizowanych programów.
W każdym razie, drugi Odczyt pamięci, który jest czasami konieczny, spowolniłby potok, bez względu na to, ile specjalnego sprzętu (hipotetycznie i głupio) poświęcono na łatanie niezgodnych operacji pamięci.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-03-01 18:38:58
@ joshperry dał doskonałą odpowiedź na to pytanie. Oprócz jego odpowiedzi, mam kilka liczb, które pokazują graficznie efekty, które zostały opisane, zwłaszcza wzmocnienie 2X. Oto link do arkusza kalkulacyjnego Google pokazujący, jak wyglądają efekty różnych wyrównań słów. W dodatku tutaj jest link do Github gist z kodem do testu. Kod testowy jest zaadaptowany z artykułu{[2] } napisanego przez Jonathana Rentzscha, który @ joshperry / align = "left" / Testy przeprowadzono na MacBooku Pro z czterordzeniowym 64-bitowym procesorem Intel Core i7 2,8 GHz i 16GB PAMIĘCI RAM.

Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-04-06 14:38:53
Jeśli system z pamięcią adresowalną bajtami ma magistralę pamięci o szerokości 32 bitów, oznacza to, że istnieją cztery systemy pamięci o szerokości bajtów, które są podłączone do odczytu lub zapisu tego samego adresu. Wyrównany odczyt 32-bitowy wymaga informacji przechowywanych pod tym samym adresem we wszystkich czterech systemach pamięci, więc wszystkie systemy mogą dostarczać dane jednocześnie. Niepodpisany odczyt 32-bitowy wymagałby, aby niektóre systemy pamięci zwracały dane z jednego adresu, a inne z następnego adresu wyższego. Chociaż istnieją pewne systemy pamięci, które są zoptymalizowane, aby móc spełnić takie żądania (oprócz ich adresu, faktycznie mają sygnał "plus jeden", który powoduje, że używają adresu wyższego niż określony), taka funkcja dodaje znaczny koszt i złożoność do systemu pamięci; większość systemów pamięci towarowych po prostu nie może zwrócić części różnych 32-bitowych słów w tym samym czasie.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-06-15 20:21:36
Jeśli masz 32-bitową magistralę danych, linie adresowe magistrali adresowej podłączone do pamięci zaczną się od2, Tak więc tylko 32-bitowe wyrównane adresy mogą być dostępne w jednym cyklu magistrali.
Więc jeśli słowo obejmuje granicę wyrównania adresu - tzn.0 dla danych 16/32 bitowych lub1 dla danych 32-bitowych nie jest zero, do uzyskania danych wymagane są dwa cykle magistrali.
Niektóre architektury/zestawy instrukcji nie obsługują dostępu bez przypisania i generują wyjątek przy takich próbach, więc kompilator wygenerowany niezaliczany kod dostępu wymaga nie tylko dodatkowych cykli magistrali, Ale dodatkowych instrukcji, co czyni go jeszcze mniej wydajnym.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-06-19 20:10:06
Na PowerPC można załadować liczbę całkowitą z nieparzystego adresu bez żadnych problemów.
Sparc i I86 i (chyba) Itatnium podnoszą wyjątki sprzętowe przy próbie tego.
Jedno 32-bitowe obciążenie w porównaniu z czterema 8-bitowymi obciążeniami nie będzie miało większego znaczenia na większości nowoczesnych procesorów. To, czy dane są już w pamięci podręcznej, czy nie, będzie miało znacznie większy wpływ.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-06-19 19:53:05