Jaki jest najskuteczniejszy sposób kasowania duplikatów i sortowania wektora?
Muszę wziąć wektor C++ z potencjalnie dużą ilością elementów, usunąć duplikaty i posortować.
Obecnie mam poniższy kod, ale nie działa.
vec.erase(
std::unique(vec.begin(), vec.end()),
vec.end());
std::sort(vec.begin(), vec.end());
Jak prawidłowo to zrobić?
Dodatkowo, czy szybciej jest najpierw usunąć duplikaty (podobnie jak w powyższym kodowaniu) lub najpierw wykonać sortowanie? Jeśli najpierw wykonam sortowanie, czy gwarantowane pozostanie sortowane po wykonaniu std::unique?
A może jest inny (może więcej skuteczny) sposób na to wszystko?
23 answers
Zgadzam się z R. Pate i Todd Gardner ; a std::set to może być dobry pomysł. Nawet jeśli utkniesz za pomocą wektorów, jeśli masz wystarczająco dużo duplikatów, może lepiej będzie stworzyć zestaw do brudnej roboty.
Porównajmy trzy podejścia:
Wystarczy użyć wektora, sort + unique
sort( vec.begin(), vec.end() );
vec.erase( unique( vec.begin(), vec.end() ), vec.end() );
Konwertuj na set (ręcznie)
set<int> s;
unsigned size = vec.size();
for( unsigned i = 0; i < size; ++i ) s.insert( vec[i] );
vec.assign( s.begin(), s.end() );
Convert to set (using a constructor)
set<int> s( vec.begin(), vec.end() );
vec.assign( s.begin(), s.end() );
Oto jak występują one jako liczba zmian duplikatów:
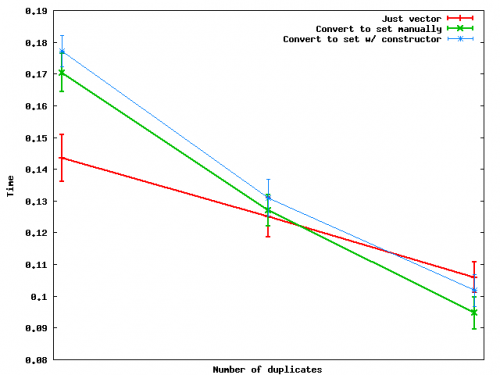
Summary: gdy liczba duplikatów jest wystarczająco duża, w rzeczywistości szybsza jest konwersja do zbioru, a następnie zrzut danych z powrotem do wektora.
I z jakiegoś powodu ręczne wykonanie konwersji zestawu wydaje się być szybsze niż użycie konstruktora zestawu-przynajmniej na przypadkowych danych zabawki, których użyłem.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-28 11:38:45
Zmieniłem profil Nate ' a Kohla i otrzymałem Inne wyniki. Dla mojego przypadku testowego, bezpośrednie sortowanie wektora jest zawsze bardziej efektywne niż użycie zbioru. Dodałem nową, bardziej efektywną metodę, używając unordered_set.
Należy pamiętać, że metoda unordered_set działa tylko wtedy, gdy masz dobrą funkcję hashową dla typu, którego potrzebujesz. Dla ints to proste! (Biblioteka standardowa zapewnia domyślny hash, który jest po prostu funkcją tożsamości.) Również nie zapomnij sortować na końcu, ponieważ unordered_set jest, cóż, unordered :)
Poszperałem trochę w implementacji set i unordered_set i odkryłem, że konstruktor rzeczywiście konstruuje nowy węzeł dla każdego elementu, zanim sprawdzi jego wartość, aby określić, czy powinien zostać wstawiony (przynajmniej w implementacji Visual Studio).
Oto 5 metod:
F1: tylko za pomocą vector, sort + unique
sort( vec.begin(), vec.end() );
vec.erase( unique( vec.begin(), vec.end() ), vec.end() );
F2: Convert to set (using a konstruktor)
set<int> s( vec.begin(), vec.end() );
vec.assign( s.begin(), s.end() );
F3: konwersja na set (ręcznie)
set<int> s;
for (int i : vec)
s.insert(i);
vec.assign( s.begin(), s.end() );
F4: Convert to unordered_set (using a constructor)
unordered_set<int> s( vec.begin(), vec.end() );
vec.assign( s.begin(), s.end() );
sort( vec.begin(), vec.end() );
F5: konwersja na unordered_set (ręcznie)
unordered_set<int> s;
for (int i : vec)
s.insert(i);
vec.assign( s.begin(), s.end() );
sort( vec.begin(), vec.end() );
Wyniki (w sekundach mniejsze jest lepsze):
range f1 f2 f3 f4 f5
[1,10] 1.6821 7.6804 2.8232 6.2634 0.7980
[1,1000] 5.0773 13.3658 8.2235 7.6884 1.9861
[1,100000] 8.7955 32.1148 26.5485 13.3278 3.9822
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-05-13 02:06:19
std::unique usuwa zduplikowane elementy tylko wtedy, gdy są sąsiadami: musisz najpierw posortować wektor, zanim będzie działał tak, jak chcesz.
std::unique jest zdefiniowany jako stabilny, więc wektor będzie nadal sortowany po uruchomieniu unique na nim.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-05-12 20:25:30
Nie jestem pewien, do czego tego używasz, więc nie mogę powiedzieć tego ze 100% pewnością, ale zwykle, gdy myślę o" sortowanym, unikalnym " kontenerze, myślę o std:: set . To może być lepsze dopasowanie do Twojego zastosowania:
std::set<Foo> foos(vec.begin(), vec.end()); // both sorted & unique already
W przeciwnym razie, sortowanie przed wywołaniem unique (jak wskazywały inne odpowiedzi) jest drogą do zrobienia.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2009-06-25 01:02:35
std::unique działa tylko na kolejnych uruchomieniach zduplikowanych elementów, więc lepiej najpierw posortować. Jest jednak stabilny, więc twój wektor pozostanie posortowany.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2009-06-25 00:32:08
Oto szablon, który zrobi to za Ciebie:
template<typename T>
void removeDuplicates(std::vector<T>& vec)
{
std::sort(vec.begin(), vec.end());
vec.erase(std::unique(vec.begin(), vec.end()), vec.end());
}
Nazwij to tak:
removeDuplicates<int>(vectorname);
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2009-06-25 03:02:41
Jeśli nie chcesz zmieniać kolejności elementów, możesz wypróbować takie rozwiązanie:
template <class T>
void RemoveDuplicatesInVector(std::vector<T> & vec)
{
set<T> values;
vec.erase(std::remove_if(vec.begin(), vec.end(), [&](const T & value) { return !values.insert(value).second; }), vec.end());
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-07-31 14:36:17
Efektywność to skomplikowana koncepcja. Istnieją względy czasu i przestrzeni, a także ogólne pomiary(gdzie można uzyskać tylko niejasne odpowiedzi, takie jak O (n)) kontra konkretne (np. sortowanie bąbelkowe może być znacznie szybsze niż quicksort, w zależności od właściwości wejściowych).
Jeśli masz stosunkowo niewiele duplikatów, Sortuj, a następnie unique i erase wydaje się być dobrym rozwiązaniem. Jeśli masz stosunkowo wiele duplikatów, Tworzenie zestawu z wektora i pozwalając mu na podnoszenie ciężarów może łatwo go pokonać.
Nie tylko skupić się na efektywności czasu albo. Sort+unique + erase działa w przestrzeni O( 1), podczas gdy konstrukcja zbioru działa w przestrzeni O(n). I żaden bezpośrednio nie nadaje się do map-zmniejszyć równoległość (dla naprawdę ogromne zbiorów danych).
Musisz to posortować zanim zadzwonisz unique ponieważ unique usuwa tylko duplikaty znajdujące się obok siebie.
Edycja: 38 sekund...
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2009-06-25 00:32:46
unique usuwa tylko kolejne zduplikowane elementy (co jest konieczne, aby działać w czasie liniowym), więc najpierw powinieneś wykonać sortowanie. Zostanie on posortowany po wywołaniu unique.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2009-06-25 00:33:03
Zakładając, że a jest wektorem, Usuń sąsiadujące ze sobą duplikaty używając
a.erase(unique(a.begin(),a.end()),a.end()); działa w czasie O (n).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-08-16 17:47:36
Możesz to zrobić w następujący sposób:
std::sort(v.begin(), v.end());
v.erase(std::unique(v.begin(), v.end()), v.end());
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-08-17 20:54:50
Z biblioteką Ranges v3, możesz po prostu użyć
action::unique(vec);
Zauważ, że w rzeczywistości usuwa zduplikowane elementy, a nie tylko je przenosi.
Niestety, działania nie były standaryzowane w C++20, ponieważ inne części biblioteki zakresów były nadal potrzebne do korzystania z oryginalnej biblioteki nawet w C++20.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-08-23 23:53:13
Jak już wspomniano, unique wymaga posortowanego kontenera. Dodatkowo unique nie usuwa elementów z kontenera. Zamiast tego, są one kopiowane do końca, unique zwraca iterator wskazujący na pierwszy taki duplikat elementu i oczekuje się, że wywołasz erase aby faktycznie usunąć elementy.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2009-12-23 09:04:40
Standardowe podejście zaproponowane przez Nate ' a Kohla, po prostu używając wektora, sort + unique:
sort( vec.begin(), vec.end() );
vec.erase( unique( vec.begin(), vec.end() ), vec.end() );
Nie działa dla wektora wskaźników.
Przyjrzyj się uważnie temu przykładowi na cplusplus.com .
W ich przykładzie "tak zwane duplikaty" przeniesione na koniec są faktycznie pokazane jako ? (undefined values), ponieważ te "tzw. duplikaty" są czasami "dodatkowymi elementami", a czasami "brakującymi elementami", które znajdowały się w oryginalnym wektorze.
Problem występuje przy użyciu std::unique() na wektorze wskaźników do obiektów (wycieki pamięci, zły odczyt danych ze sterty, duplikaty zwolnień, które powodują błędy segmentacji, itp.).
Oto moje rozwiązanie problemu: zamień std::unique() na ptgi::unique().
Zobacz plik ptgi_unique.hpp poniżej:
// ptgi::unique()
//
// Fix a problem in std::unique(), such that none of the original elts in the collection are lost or duplicate.
// ptgi::unique() has the same interface as std::unique()
//
// There is the 2 argument version which calls the default operator== to compare elements.
//
// There is the 3 argument version, which you can pass a user defined functor for specialized comparison.
//
// ptgi::unique() is an improved version of std::unique() which doesn't looose any of the original data
// in the collection, nor does it create duplicates.
//
// After ptgi::unique(), every old element in the original collection is still present in the re-ordered collection,
// except that duplicates have been moved to a contiguous range [dupPosition, last) at the end.
//
// Thus on output:
// [begin, dupPosition) range are unique elements.
// [dupPosition, last) range are duplicates which can be removed.
// where:
// [] means inclusive, and
// () means exclusive.
//
// In the original std::unique() non-duplicates at end are moved downward toward beginning.
// In the improved ptgi:unique(), non-duplicates at end are swapped with duplicates near beginning.
//
// In addition if you have a collection of ptrs to objects, the regular std::unique() will loose memory,
// and can possibly delete the same pointer multiple times (leading to SEGMENTATION VIOLATION on Linux machines)
// but ptgi::unique() won't. Use valgrind(1) to find such memory leak problems!!!
//
// NOTE: IF you have a vector of pointers, that is, std::vector<Object*>, then upon return from ptgi::unique()
// you would normally do the following to get rid of the duplicate objects in the HEAP:
//
// // delete objects from HEAP
// std::vector<Object*> objects;
// for (iter = dupPosition; iter != objects.end(); ++iter)
// {
// delete (*iter);
// }
//
// // shrink the vector. But Object * pointers are NOT followed for duplicate deletes, this shrinks the vector.size())
// objects.erase(dupPosition, objects.end));
//
// NOTE: But if you have a vector of objects, that is: std::vector<Object>, then upon return from ptgi::unique(), it
// suffices to just call vector:erase(, as erase will automatically call delete on each object in the
// [dupPosition, end) range for you:
//
// std::vector<Object> objects;
// objects.erase(dupPosition, last);
//
//==========================================================================================================
// Example of differences between std::unique() vs ptgi::unique().
//
// Given:
// int data[] = {10, 11, 21};
//
// Given this functor: ArrayOfIntegersEqualByTen:
// A functor which compares two integers a[i] and a[j] in an int a[] array, after division by 10:
//
// // given an int data[] array, remove consecutive duplicates from it.
// // functor used for std::unique (BUGGY) or ptgi::unique(IMPROVED)
//
// // Two numbers equal if, when divided by 10 (integer division), the quotients are the same.
// // Hence 50..59 are equal, 60..69 are equal, etc.
// struct ArrayOfIntegersEqualByTen: public std::equal_to<int>
// {
// bool operator() (const int& arg1, const int& arg2) const
// {
// return ((arg1/10) == (arg2/10));
// }
// };
//
// Now, if we call (problematic) std::unique( data, data+3, ArrayOfIntegersEqualByTen() );
//
// TEST1: BEFORE UNIQ: 10,11,21
// TEST1: AFTER UNIQ: 10,21,21
// DUP_INX=2
//
// PROBLEM: 11 is lost, and extra 21 has been added.
//
// More complicated example:
//
// TEST2: BEFORE UNIQ: 10,20,21,22,30,31,23,24,11
// TEST2: AFTER UNIQ: 10,20,30,23,11,31,23,24,11
// DUP_INX=5
//
// Problem: 21 and 22 are deleted.
// Problem: 11 and 23 are duplicated.
//
//
// NOW if ptgi::unique is called instead of std::unique, both problems go away:
//
// DEBUG: TEST1: NEW_WAY=1
// TEST1: BEFORE UNIQ: 10,11,21
// TEST1: AFTER UNIQ: 10,21,11
// DUP_INX=2
//
// DEBUG: TEST2: NEW_WAY=1
// TEST2: BEFORE UNIQ: 10,20,21,22,30,31,23,24,11
// TEST2: AFTER UNIQ: 10,20,30,23,11,31,22,24,21
// DUP_INX=5
//
// @SEE: look at the "case study" below to understand which the last "AFTER UNIQ" results with that order:
// TEST2: AFTER UNIQ: 10,20,30,23,11,31,22,24,21
//
//==========================================================================================================
// Case Study: how ptgi::unique() works:
// Remember we "remove adjacent duplicates".
// In this example, the input is NOT fully sorted when ptgi:unique() is called.
//
// I put | separatators, BEFORE UNIQ to illustrate this
// 10 | 20,21,22 | 30,31 | 23,24 | 11
//
// In example above, 20, 21, 22 are "same" since dividing by 10 gives 2 quotient.
// And 30,31 are "same", since /10 quotient is 3.
// And 23, 24 are same, since /10 quotient is 2.
// And 11 is "group of one" by itself.
// So there are 5 groups, but the 4th group (23, 24) happens to be equal to group 2 (20, 21, 22)
// So there are 5 groups, and the 5th group (11) is equal to group 1 (10)
//
// R = result
// F = first
//
// 10, 20, 21, 22, 30, 31, 23, 24, 11
// R F
//
// 10 is result, and first points to 20, and R != F (10 != 20) so bump R:
// R
// F
//
// Now we hits the "optimized out swap logic".
// (avoid swap because R == F)
//
// // now bump F until R != F (integer division by 10)
// 10, 20, 21, 22, 30, 31, 23, 24, 11
// R F // 20 == 21 in 10x
// R F // 20 == 22 in 10x
// R F // 20 != 30, so we do a swap of ++R and F
// (Now first hits 21, 22, then finally 30, which is different than R, so we swap bump R to 21 and swap with 30)
// 10, 20, 30, 22, 21, 31, 23, 24, 11 // after R & F swap (21 and 30)
// R F
//
// 10, 20, 30, 22, 21, 31, 23, 24, 11
// R F // bump F to 31, but R and F are same (30 vs 31)
// R F // bump F to 23, R != F, so swap ++R with F
// 10, 20, 30, 22, 21, 31, 23, 24, 11
// R F // bump R to 22
// 10, 20, 30, 23, 21, 31, 22, 24, 11 // after the R & F swap (22 & 23 swap)
// R F // will swap 22 and 23
// R F // bump F to 24, but R and F are same in 10x
// R F // bump F, R != F, so swap ++R with F
// R F // R and F are diff, so swap ++R with F (21 and 11)
// 10, 20, 30, 23, 11, 31, 22, 24, 21
// R F // aftter swap of old 21 and 11
// R F // F now at last(), so loop terminates
// R F // bump R by 1 to point to dupPostion (first duplicate in range)
//
// return R which now points to 31
//==========================================================================================================
// NOTES:
// 1) the #ifdef IMPROVED_STD_UNIQUE_ALGORITHM documents how we have modified the original std::unique().
// 2) I've heavily unit tested this code, including using valgrind(1), and it is *believed* to be 100% defect-free.
//
//==========================================================================================================
// History:
// 130201 dpb [email protected] created
//==========================================================================================================
#ifndef PTGI_UNIQUE_HPP
#define PTGI_UNIQUE_HPP
// Created to solve memory leak problems when calling std::unique() on a vector<Route*>.
// Memory leaks discovered with valgrind and unitTesting.
#include <algorithm> // std::swap
// instead of std::myUnique, call this instead, where arg3 is a function ptr
//
// like std::unique, it puts the dups at the end, but it uses swapping to preserve original
// vector contents, to avoid memory leaks and duplicate pointers in vector<Object*>.
#ifdef IMPROVED_STD_UNIQUE_ALGORITHM
#error the #ifdef for IMPROVED_STD_UNIQUE_ALGORITHM was defined previously.. Something is wrong.
#endif
#undef IMPROVED_STD_UNIQUE_ALGORITHM
#define IMPROVED_STD_UNIQUE_ALGORITHM
// similar to std::unique, except that this version swaps elements, to avoid
// memory leaks, when vector contains pointers.
//
// Normally the input is sorted.
// Normal std::unique:
// 10 20 20 20 30 30 20 20 10
// a b c d e f g h i
//
// 10 20 30 20 10 | 30 20 20 10
// a b e g i f g h i
//
// Now GONE: c, d.
// Now DUPS: g, i.
// This causes memory leaks and segmenation faults due to duplicate deletes of same pointer!
namespace ptgi {
// Return the position of the first in range of duplicates moved to end of vector.
//
// uses operator== of class for comparison
//
// @param [first, last) is a range to find duplicates within.
//
// @return the dupPosition position, such that [dupPosition, end) are contiguous
// duplicate elements.
// IF all items are unique, then it would return last.
//
template <class ForwardIterator>
ForwardIterator unique( ForwardIterator first, ForwardIterator last)
{
// compare iterators, not values
if (first == last)
return last;
// remember the current item that we are looking at for uniqueness
ForwardIterator result = first;
// result is slow ptr where to store next unique item
// first is fast ptr which is looking at all elts
// the first iterator moves over all elements [begin+1, end).
// while the current item (result) is the same as all elts
// to the right, (first) keeps going, until you find a different
// element pointed to by *first. At that time, we swap them.
while (++first != last)
{
if (!(*result == *first))
{
#ifdef IMPROVED_STD_UNIQUE_ALGORITHM
// inc result, then swap *result and *first
// THIS IS WHAT WE WANT TO DO.
// BUT THIS COULD SWAP AN ELEMENT WITH ITSELF, UNCECESSARILY!!!
// std::swap( *first, *(++result));
// BUT avoid swapping with itself when both iterators are the same
++result;
if (result != first)
std::swap( *first, *result);
#else
// original code found in std::unique()
// copies unique down
*(++result) = *first;
#endif
}
}
return ++result;
}
template <class ForwardIterator, class BinaryPredicate>
ForwardIterator unique( ForwardIterator first, ForwardIterator last, BinaryPredicate pred)
{
if (first == last)
return last;
// remember the current item that we are looking at for uniqueness
ForwardIterator result = first;
while (++first != last)
{
if (!pred(*result,*first))
{
#ifdef IMPROVED_STD_UNIQUE_ALGORITHM
// inc result, then swap *result and *first
// THIS COULD SWAP WITH ITSELF UNCECESSARILY
// std::swap( *first, *(++result));
//
// BUT avoid swapping with itself when both iterators are the same
++result;
if (result != first)
std::swap( *first, *result);
#else
// original code found in std::unique()
// copies unique down
// causes memory leaks, and duplicate ptrs
// and uncessarily moves in place!
*(++result) = *first;
#endif
}
}
return ++result;
}
// from now on, the #define is no longer needed, so get rid of it
#undef IMPROVED_STD_UNIQUE_ALGORITHM
} // end ptgi:: namespace
#endif
A oto program do testów jednostkowych, którego użyłem do ich przetestowania:
// QUESTION: in test2, I had trouble getting one line to compile,which was caused by the declaration of operator()
// in the equal_to Predicate. I'm not sure how to correctly resolve that issue.
// Look for //OUT lines
//
// Make sure that NOTES in ptgi_unique.hpp are correct, in how we should "cleanup" duplicates
// from both a vector<Integer> (test1()) and vector<Integer*> (test2).
// Run this with valgrind(1).
//
// In test2(), IF we use the call to std::unique(), we get this problem:
//
// [dbednar@ipeng8 TestSortRoutes]$ ./Main7
// TEST2: ORIG nums before UNIQUE: 10, 20, 21, 22, 30, 31, 23, 24, 11
// TEST2: modified nums AFTER UNIQUE: 10, 20, 30, 23, 11, 31, 23, 24, 11
// INFO: dupInx=5
// TEST2: uniq = 10
// TEST2: uniq = 20
// TEST2: uniq = 30
// TEST2: uniq = 33427744
// TEST2: uniq = 33427808
// Segmentation fault (core dumped)
//
// And if we run valgrind we seen various error about "read errors", "mismatched free", "definitely lost", etc.
//
// valgrind --leak-check=full ./Main7
// ==359== Memcheck, a memory error detector
// ==359== Command: ./Main7
// ==359== Invalid read of size 4
// ==359== Invalid free() / delete / delete[]
// ==359== HEAP SUMMARY:
// ==359== in use at exit: 8 bytes in 2 blocks
// ==359== LEAK SUMMARY:
// ==359== definitely lost: 8 bytes in 2 blocks
// But once we replace the call in test2() to use ptgi::unique(), all valgrind() error messages disappear.
//
// 130212 dpb [email protected] created
// =========================================================================================================
#include <iostream> // std::cout, std::cerr
#include <string>
#include <vector> // std::vector
#include <sstream> // std::ostringstream
#include <algorithm> // std::unique()
#include <functional> // std::equal_to(), std::binary_function()
#include <cassert> // assert() MACRO
#include "ptgi_unique.hpp" // ptgi::unique()
// Integer is small "wrapper class" around a primitive int.
// There is no SETTER, so Integer's are IMMUTABLE, just like in JAVA.
class Integer
{
private:
int num;
public:
// default CTOR: "Integer zero;"
// COMPRENSIVE CTOR: "Integer five(5);"
Integer( int num = 0 ) :
num(num)
{
}
// COPY CTOR
Integer( const Integer& rhs) :
num(rhs.num)
{
}
// assignment, operator=, needs nothing special... since all data members are primitives
// GETTER for 'num' data member
// GETTER' are *always* const
int getNum() const
{
return num;
}
// NO SETTER, because IMMUTABLE (similar to Java's Integer class)
// @return "num"
// NB: toString() should *always* be a const method
//
// NOTE: it is probably more efficient to call getNum() intead
// of toString() when printing a number:
//
// BETTER to do this:
// Integer five(5);
// std::cout << five.getNum() << "\n"
// than this:
// std::cout << five.toString() << "\n"
std::string toString() const
{
std::ostringstream oss;
oss << num;
return oss.str();
}
};
// convenience typedef's for iterating over std::vector<Integer>
typedef std::vector<Integer>::iterator IntegerVectorIterator;
typedef std::vector<Integer>::const_iterator ConstIntegerVectorIterator;
// convenience typedef's for iterating over std::vector<Integer*>
typedef std::vector<Integer*>::iterator IntegerStarVectorIterator;
typedef std::vector<Integer*>::const_iterator ConstIntegerStarVectorIterator;
// functor used for std::unique or ptgi::unique() on a std::vector<Integer>
// Two numbers equal if, when divided by 10 (integer division), the quotients are the same.
// Hence 50..59 are equal, 60..69 are equal, etc.
struct IntegerEqualByTen: public std::equal_to<Integer>
{
bool operator() (const Integer& arg1, const Integer& arg2) const
{
return ((arg1.getNum()/10) == (arg2.getNum()/10));
}
};
// functor used for std::unique or ptgi::unique on a std::vector<Integer*>
// Two numbers equal if, when divided by 10 (integer division), the quotients are the same.
// Hence 50..59 are equal, 60..69 are equal, etc.
struct IntegerEqualByTenPointer: public std::equal_to<Integer*>
{
// NB: the Integer*& looks funny to me!
// TECHNICAL PROBLEM ELSEWHERE so had to remove the & from *&
//OUT bool operator() (const Integer*& arg1, const Integer*& arg2) const
//
bool operator() (const Integer* arg1, const Integer* arg2) const
{
return ((arg1->getNum()/10) == (arg2->getNum()/10));
}
};
void test1();
void test2();
void printIntegerStarVector( const std::string& msg, const std::vector<Integer*>& nums );
int main()
{
test1();
test2();
return 0;
}
// test1() uses a vector<Object> (namely vector<Integer>), so there is no problem with memory loss
void test1()
{
int data[] = { 10, 20, 21, 22, 30, 31, 23, 24, 11};
// turn C array into C++ vector
std::vector<Integer> nums(data, data+9);
// arg3 is a functor
IntegerVectorIterator dupPosition = ptgi::unique( nums.begin(), nums.end(), IntegerEqualByTen() );
nums.erase(dupPosition, nums.end());
nums.erase(nums.begin(), dupPosition);
}
//==================================================================================
// test2() uses a vector<Integer*>, so after ptgi:unique(), we have to be careful in
// how we eliminate the duplicate Integer objects stored in the heap.
//==================================================================================
void test2()
{
int data[] = { 10, 20, 21, 22, 30, 31, 23, 24, 11};
// turn C array into C++ vector of Integer* pointers
std::vector<Integer*> nums;
// put data[] integers into equivalent Integer* objects in HEAP
for (int inx = 0; inx < 9; ++inx)
{
nums.push_back( new Integer(data[inx]) );
}
// print the vector<Integer*> to stdout
printIntegerStarVector( "TEST2: ORIG nums before UNIQUE", nums );
// arg3 is a functor
#if 1
// corrected version which fixes SEGMENTATION FAULT and all memory leaks reported by valgrind(1)
// I THINK we want to use new C++11 cbegin() and cend(),since the equal_to predicate is passed "Integer *&"
// DID NOT COMPILE
//OUT IntegerStarVectorIterator dupPosition = ptgi::unique( const_cast<ConstIntegerStarVectorIterator>(nums.begin()), const_cast<ConstIntegerStarVectorIterator>(nums.end()), IntegerEqualByTenPointer() );
// DID NOT COMPILE when equal_to predicate declared "Integer*& arg1, Integer*& arg2"
//OUT IntegerStarVectorIterator dupPosition = ptgi::unique( const_cast<nums::const_iterator>(nums.begin()), const_cast<nums::const_iterator>(nums.end()), IntegerEqualByTenPointer() );
// okay when equal_to predicate declared "Integer* arg1, Integer* arg2"
IntegerStarVectorIterator dupPosition = ptgi::unique(nums.begin(), nums.end(), IntegerEqualByTenPointer() );
#else
// BUGGY version that causes SEGMENTATION FAULT and valgrind(1) errors
IntegerStarVectorIterator dupPosition = std::unique( nums.begin(), nums.end(), IntegerEqualByTenPointer() );
#endif
printIntegerStarVector( "TEST2: modified nums AFTER UNIQUE", nums );
int dupInx = dupPosition - nums.begin();
std::cout << "INFO: dupInx=" << dupInx <<"\n";
// delete the dup Integer* objects in the [dupPosition, end] range
for (IntegerStarVectorIterator iter = dupPosition; iter != nums.end(); ++iter)
{
delete (*iter);
}
// shrink the vector
// NB: the Integer* ptrs are NOT followed by vector::erase()
nums.erase(dupPosition, nums.end());
// print the uniques, by following the iter to the Integer* pointer
for (IntegerStarVectorIterator iter = nums.begin(); iter != nums.end(); ++iter)
{
std::cout << "TEST2: uniq = " << (*iter)->getNum() << "\n";
}
// remove the unique objects from heap
for (IntegerStarVectorIterator iter = nums.begin(); iter != nums.end(); ++iter)
{
delete (*iter);
}
// shrink the vector
nums.erase(nums.begin(), nums.end());
// the vector should now be completely empty
assert( nums.size() == 0);
}
//@ print to stdout the string: "info_msg: num1, num2, .... numN\n"
void printIntegerStarVector( const std::string& msg, const std::vector<Integer*>& nums )
{
std::cout << msg << ": ";
int inx = 0;
ConstIntegerStarVectorIterator iter;
// use const iterator and const range!
// NB: cbegin() and cend() not supported until LATER (c++11)
for (iter = nums.begin(), inx = 0; iter != nums.end(); ++iter, ++inx)
{
// output a comma seperator *AFTER* first
if (inx > 0)
std::cout << ", ";
// call Integer::toString()
std::cout << (*iter)->getNum(); // send int to stdout
// std::cout << (*iter)->toString(); // also works, but is probably slower
}
// in conclusion, add newline
std::cout << "\n";
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-12-10 17:33:56
Jeśli szukasz wydajności i używasz std::vector, polecam ten, który zapewnia ten link do dokumentacji.
std::vector<int> myvector{10,20,20,20,30,30,20,20,10}; // 10 20 20 20 30 30 20 20 10
std::sort(myvector.begin(), myvector.end() );
const auto& it = std::unique (myvector.begin(), myvector.end()); // 10 20 30 ? ? ? ? ? ?
// ^
myvector.resize( std::distance(myvector.begin(),it) ); // 10 20 30
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-03-16 21:25:59
void removeDuplicates(std::vector<int>& arr) {
for (int i = 0; i < arr.size(); i++)
{
for (int j = i + 1; j < arr.size(); j++)
{
if (arr[i] > arr[j])
{
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
}
std::vector<int> y;
int x = arr[0];
int i = 0;
while (i < arr.size())
{
if (x != arr[i])
{
y.push_back(x);
x = arr[i];
}
i++;
if (i == arr.size())
y.push_back(arr[i - 1]);
}
arr = y;
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-10-31 15:28:03
std::set<int> s;
std::for_each(v.cbegin(), v.cend(), [&s](int val){s.insert(val);});
v.clear();
std::copy(s.cbegin(), s.cend(), v.cbegin());
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-11-11 07:13:13
O alexk7 Wypróbowałem je i uzyskałem podobne wyniki, ale gdy zakres wartości wynosi 1 milion, przypadki używając STD:: sort (f1) i używając std:: unordered_set (f5) dają podobny czas. Gdy zakres wartości wynosi 10 milionów f1 jest szybszy niż f5.
Jeśli zakres wartości jest ograniczony, a wartości są niepodpisane, można użyć metody std:: vector, której rozmiar odpowiada podanemu zakresowi. Oto kod:
void DeleteDuplicates_vector_bool(std::vector<unsigned>& v, unsigned range_size)
{
std::vector<bool> v1(range_size);
for (auto& x: v)
{
v1[x] = true;
}
v.clear();
unsigned count = 0;
for (auto& x: v1)
{
if (x)
{
v.push_back(count);
}
++count;
}
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-06-16 18:18:30
Jeśli nie chcesz zmodyfikować wektora (wymazać, posortować), możesz użyć Biblioteki Newtona , w podlibrisie algorytmu jest wywołanie funkcji, copy_single
template <class INPUT_ITERATOR, typename T>
void copy_single( INPUT_ITERATOR first, INPUT_ITERATOR last, std::vector<T> &v )
Więc możesz:
std::vector<TYPE> copy; // empty vector
newton::copy_single(first, last, copy);
Gdzie Kopia jest wektorem gdzie do push_back Kopia unikalnych elementów. ale pamiętaj, że push_back elementy i nie tworzysz nowego wektora
W każdym razie, to jest szybsze, ponieważ ty nie usuwaj elementów (co zajmuje dużo czasu, z wyjątkiem pop_back (), z powodu zmiany przypisania)
Robię eksperymenty i jest szybciej.Możesz również użyć:
std::vector<TYPE> copy; // empty vector
newton::copy_single(first, last, copy);
original = copy;
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-04-01 07:24:05
Bardziej zrozumiały Kod od: https://en.cppreference.com/w/cpp/algorithm/unique
#include <iostream>
#include <algorithm>
#include <vector>
#include <string>
#include <cctype>
int main()
{
// remove duplicate elements
std::vector<int> v{1,2,3,1,2,3,3,4,5,4,5,6,7};
std::sort(v.begin(), v.end()); // 1 1 2 2 3 3 3 4 4 5 5 6 7
auto last = std::unique(v.begin(), v.end());
// v now holds {1 2 3 4 5 6 7 x x x x x x}, where 'x' is indeterminate
v.erase(last, v.end());
for (int i : v)
std::cout << i << " ";
std::cout << "\n";
}
Ouput:
1 2 3 4 5 6 7
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-09-10 00:27:44
Oto przykład problemu duplicate delete, który występuje przy STD:: unique (). Na komputerze z Linuksem program ulega awarii. Przeczytaj komentarze po szczegóły.
// Main10.cpp
//
// Illustration of duplicate delete and memory leak in a vector<int*> after calling std::unique.
// On a LINUX machine, it crashes the progam because of the duplicate delete.
//
// INPUT : {1, 2, 2, 3}
// OUTPUT: {1, 2, 3, 3}
//
// The two 3's are actually pointers to the same 3 integer in the HEAP, which is BAD
// because if you delete both int* pointers, you are deleting the same memory
// location twice.
//
//
// Never mind the fact that we ignore the "dupPosition" returned by std::unique(),
// but in any sensible program that "cleans up after istelf" you want to call deletex
// on all int* poitners to avoid memory leaks.
//
//
// NOW IF you replace std::unique() with ptgi::unique(), all of the the problems disappear.
// Why? Because ptgi:unique merely reshuffles the data:
// OUTPUT: {1, 2, 3, 2}
// The ptgi:unique has swapped the last two elements, so all of the original elements in
// the INPUT are STILL in the OUTPUT.
//
// 130215 [email protected]
//============================================================================
#include <iostream>
#include <vector>
#include <algorithm>
#include <functional>
#include "ptgi_unique.hpp"
// functor used by std::unique to remove adjacent elts from vector<int*>
struct EqualToVectorOfIntegerStar: public std::equal_to<int *>
{
bool operator() (const int* arg1, const int* arg2) const
{
return (*arg1 == *arg2);
}
};
void printVector( const std::string& msg, const std::vector<int*>& vnums);
int main()
{
int inums [] = { 1, 2, 2, 3 };
std::vector<int*> vnums;
// convert C array into vector of pointers to integers
for (size_t inx = 0; inx < 4; ++ inx)
vnums.push_back( new int(inums[inx]) );
printVector("BEFORE UNIQ", vnums);
// INPUT : 1, 2A, 2B, 3
std::unique( vnums.begin(), vnums.end(), EqualToVectorOfIntegerStar() );
// OUTPUT: 1, 2A, 3, 3 }
printVector("AFTER UNIQ", vnums);
// now we delete 3 twice, and we have a memory leak because 2B is not deleted.
for (size_t inx = 0; inx < vnums.size(); ++inx)
{
delete(vnums[inx]);
}
}
// print a line of the form "msg: 1,2,3,..,5,6,7\n", where 1..7 are the numbers in vnums vector
// PS: you may pass "hello world" (const char *) because of implicit (automatic) conversion
// from "const char *" to std::string conversion.
void printVector( const std::string& msg, const std::vector<int*>& vnums)
{
std::cout << msg << ": ";
for (size_t inx = 0; inx < vnums.size(); ++inx)
{
// insert comma separator before current elt, but ONLY after first elt
if (inx > 0)
std::cout << ",";
std::cout << *vnums[inx];
}
std::cout << "\n";
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-02-15 18:13:44
void EraseVectorRepeats(vector <int> & v){
TOP:for(int y=0; y<v.size();++y){
for(int z=0; z<v.size();++z){
if(y==z){ //This if statement makes sure the number that it is on is not erased-just skipped-in order to keep only one copy of a repeated number
continue;}
if(v[y]==v[z]){
v.erase(v.begin()+z); //whenever a number is erased the function goes back to start of the first loop because the size of the vector changes
goto TOP;}}}}
Jest to funkcja, którą stworzyłem, której możesz użyć do usuwania powtórzeń. Potrzebne pliki nagłówkowe to tylko <iostream> i <vector>.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-04-10 01:14:11