W Javie można & być szybszym niż &&?
W tym kodzie:
if (value >= x && value <= y) {
Gdy value >= x i value <= y są tak samo prawdopodobne, jak false bez określonego wzorca, użycie operatora & byłoby szybsze niż użycie &&?
W szczególności myślę o tym, jak && leniwie ocenia wyrażenie po prawej stronie (tj. tylko jeśli LHS jest prawdziwe), co implikuje warunkowe, podczas gdy w Javie & w tym kontekście gwarantuje ścisłą ocenę obu (boolowskich) pod-wyrażeń. Wynik wartości jest taki sam albo sposób.
Ale podczas gdy >= lub <= operator użyje prostej instrukcji porównawczej, &&musi obejmować gałąź i ta gałąź jest podatna na awarię przewidywania gałęzi - Jak na to bardzo znane pytanie: dlaczego jest szybciej przetwarzać posortowaną tablicę niż niesortowaną tablicę?
Więc zmuszanie wyrażenia do braku leniwych składników z pewnością będzie bardziej deterministyczne i nie będzie podatne na niepowodzenie przewidywania. Prawda?
Przypisy:
- oczywiście odpowiedź na moje pytanie brzmiałaby Nie gdyby kod wyglądał tak:
if(value >= x && verySlowFunction()). Skupiam się na" wystarczająco prostych " wyrażeniach RHS. - tam i tak jest oddział warunkowy (
if). Nie mogę do końca udowodnić sobie, że jest to nieistotne i że Alternatywne sformułowania mogą być lepszymi przykładami, takimi jak {13]} - to wszystko wchodzi w świat horrendalnych mikro-optymalizacji. Tak, wiem: -)... ciekawe chociaż?
Update Aby wyjaśnić, dlaczego jestem zainteresowany: wpatrywałem się w systemy, o których Martin Thompson pisał na swoim blogu Mechanical Sympathy, Po tym, jak przyszedł i wygłosił przemówienie o Aeron. Jednym z kluczowych komunikatów jest to, że nasz sprzęt ma w sobie wszystkie te magiczne rzeczy, a my programiści tragicznie nie możemy z nich skorzystać. Nie martw się, nie zamierzam iść s/& & /\ & / na całym moim kodzie :-) ... ale istnieje wiele pytania na tej stronie na temat poprawy przewidywania gałęzi poprzez usunięcie gałęzi, i przyszło mi do głowy, że warunkowe operatory logiczne są w rdzeniu warunków testowych.
Oczywiście @StephenC zwraca uwagę na fakt, że wyginanie kodu w dziwne kształty może sprawić, że jitsowi łatwiej będzie dostrzec typowe optymalizacje-jeśli nie teraz, to w przyszłości. I że bardzo słynne pytanie wymienione powyżej jest szczególne, ponieważ przesuwa złożoność przewidywania daleko poza praktyczna optymalizacja.
Jestem całkiem świadomy, że w większości (lub prawie we wszystkich ) sytuacji, && jest najczystszą, najprostszą, najszybszą, najlepszą rzeczą do zrobienia-chociaż jestem bardzo wdzięczny ludziom, którzy opublikowali odpowiedzi demonstrujące to! Jestem naprawdę zainteresowany, aby zobaczyć, czy są rzeczywiście jakieś przypadki w czyimś doświadczeniu, gdzie odpowiedź na "Czy {4]} może być szybsza?"może być Tak...
Aktualizacja 2 :
(zwracając się do Rady, że pytanie jest zbyt szeroka. Nie chcę wprowadzać większych zmian w tym pytaniu, ponieważ może to zagrozić niektórym z poniższych odpowiedzi, które są wyjątkowej jakości!Jest to jeden z najbardziej znanych i cenionych w świecie gier komputerowych na świecie.]}
Widzisz to pierwsze public static boolean isPowerOfTwo(long x) {
return x > 0 & (x & (x - 1)) == 0;
}
&? A jeśli sprawdzisz link, to metoda next nazywa się lessThanBranchFree(...), co wskazuje na to, że jesteśmy na terenie branch-avoid-and Guava is really szeroko stosowane: każdy zapisany cykl powoduje widoczny spadek poziomu morza. Więc postawmy pytanie w ten sposób: czy użycie & (Gdzie && byłoby bardziej normalne) jest prawdziwą optymalizacją?
7 answers
Ok, więc chcesz wiedzieć, jak się zachowuje na niższym poziomie... Przyjrzyjmy się zatem kodowi bajtowemu!
EDIT: na końcu dodano wygenerowany kod asemblera dla AMD64. Poszukaj ciekawych notek.
EDIT 2( re: OP ' s "Update 2"): dodano kod asm dla metody isPowerOfTwo .
Java source
Napisałem te dwie szybkie metody:
public boolean AndSC(int x, int value, int y) {
return value >= x && value <= y;
}
public boolean AndNonSC(int x, int value, int y) {
return value >= x & value <= y;
}
Jak widać, są one dokładnie to samo, z wyjątkiem rodzaju i operatora.
Java bytecode
A to jest wygenerowany bajt:
public AndSC(III)Z
L0
LINENUMBER 8 L0
ILOAD 2
ILOAD 1
IF_ICMPLT L1
ILOAD 2
ILOAD 3
IF_ICMPGT L1
L2
LINENUMBER 9 L2
ICONST_1
IRETURN
L1
LINENUMBER 11 L1
FRAME SAME
ICONST_0
IRETURN
L3
LOCALVARIABLE this Ltest/lsoto/AndTest; L0 L3 0
LOCALVARIABLE x I L0 L3 1
LOCALVARIABLE value I L0 L3 2
LOCALVARIABLE y I L0 L3 3
MAXSTACK = 2
MAXLOCALS = 4
// access flags 0x1
public AndNonSC(III)Z
L0
LINENUMBER 15 L0
ILOAD 2
ILOAD 1
IF_ICMPLT L1
ICONST_1
GOTO L2
L1
FRAME SAME
ICONST_0
L2
FRAME SAME1 I
ILOAD 2
ILOAD 3
IF_ICMPGT L3
ICONST_1
GOTO L4
L3
FRAME SAME1 I
ICONST_0
L4
FRAME FULL [test/lsoto/AndTest I I I] [I I]
IAND
IFEQ L5
L6
LINENUMBER 16 L6
ICONST_1
IRETURN
L5
LINENUMBER 18 L5
FRAME SAME
ICONST_0
IRETURN
L7
LOCALVARIABLE this Ltest/lsoto/AndTest; L0 L7 0
LOCALVARIABLE x I L0 L7 1
LOCALVARIABLE value I L0 L7 2
LOCALVARIABLE y I L0 L7 3
MAXSTACK = 3
MAXLOCALS = 4
The AndSC (&&) metoda generuje dwa skoki warunkowe, zgodnie z oczekiwaniami:
- ładuje
valueixna stos i przeskakuje do L1, jeślivaluejest niższa. W przeciwnym razie działa dalej. - ładuje
valueiyna stos, a także przeskakuje do L1, jeślivaluejest większa. / Align = "left" / linie. - co stało się
return truew przypadku, gdy żaden z dwóch skoków nie został wykonany. - i mamy linie oznaczone jako L1, które są
return false.
The AndNonSC (&) metoda generuje jednak trzy skoki warunkowe!
- ładuje
valueixna stos i przeskakuje do L1, jeślivaluejest niższa. Ponieważ teraz musi zapisać wynik, aby porównać go z drugą częścią AND, więc musi wykonać "savetrue" lub "savefalse", nie może wykonać obu z tą samą instrukcją. - ładuje
valueiyna stos i przeskakuje do L1, jeślivaluejest większa. Po raz kolejny trzeba zapisaćtruelubfalsei to są dwie różne linie w zależności od wyniku porównania. - Teraz, gdy oba porównania zostały wykonane, kod faktycznie wykonuje operację AND -- I jeśli oba są prawdziwe, przeskakuje (po raz trzeci), aby zwrócić true; lub kontynuuje wykonywanie na następnej linii do return false.
(Wstępny) Wniosek
Chociaż nie jestem zbyt doświadczony w obsłudze kodu bajtowego Javy i mogłem coś przeoczyć, wydaje mi się, że & faktycznie wykona gorzej niż&& w każdym przypadku: generuje więcej instrukcji do wykonania, w tym więcej skoków warunkowych do przewidzenia i ewentualnie niepowodzenia.
Przepisanie kodu w celu zastąpienia porównań operacjami arytmetycznymi, jak ktoś inny zaproponował, może być sposób na uczynienie & lepszą opcją, ale kosztem uczynienia kodu znacznie mniej przejrzystym.
IMHO nie jest to warte kłopotów dla 99% scenariuszy(może być bardzo warte dla pętli 1%, które muszą być bardzo zoptymalizowane).
EDIT: amd64 assembly
Jak zauważono w komentarzach, ten sam bajt Javy może prowadzić do powstania innego kodu maszynowego w różnych systemach, więc chociaż bajt Javy może dać nam podpowiedź, która I wersja działa lepiej, uzyskując rzeczywisty ASM wygenerowany przez kompilator jest jedynym sposobem, aby naprawdę się dowiedzieć.
Wydrukowałem instrukcje AMD64 ASM dla obu metod; poniżej znajdują się odpowiednie linie (pozbawione punktów wejścia itp.).
uwaga: wszystkie metody skompilowane z java 1.8.0_91, chyba że podano inaczej.
Metoda AndSC z domyślnymi opcjami
# {method} {0x0000000016da0810} 'AndSC' '(III)Z' in 'AndTest'
...
0x0000000002923e3e: cmp %r8d,%r9d
0x0000000002923e41: movabs $0x16da0a08,%rax ; {metadata(method data for {method} {0x0000000016da0810} 'AndSC' '(III)Z' in 'AndTest')}
0x0000000002923e4b: movabs $0x108,%rsi
0x0000000002923e55: jl 0x0000000002923e65
0x0000000002923e5b: movabs $0x118,%rsi
0x0000000002923e65: mov (%rax,%rsi,1),%rbx
0x0000000002923e69: lea 0x1(%rbx),%rbx
0x0000000002923e6d: mov %rbx,(%rax,%rsi,1)
0x0000000002923e71: jl 0x0000000002923eb0 ;*if_icmplt
; - AndTest::AndSC@2 (line 22)
0x0000000002923e77: cmp %edi,%r9d
0x0000000002923e7a: movabs $0x16da0a08,%rax ; {metadata(method data for {method} {0x0000000016da0810} 'AndSC' '(III)Z' in 'AndTest')}
0x0000000002923e84: movabs $0x128,%rsi
0x0000000002923e8e: jg 0x0000000002923e9e
0x0000000002923e94: movabs $0x138,%rsi
0x0000000002923e9e: mov (%rax,%rsi,1),%rdi
0x0000000002923ea2: lea 0x1(%rdi),%rdi
0x0000000002923ea6: mov %rdi,(%rax,%rsi,1)
0x0000000002923eaa: jle 0x0000000002923ec1 ;*if_icmpgt
; - AndTest::AndSC@7 (line 22)
0x0000000002923eb0: mov $0x0,%eax
0x0000000002923eb5: add $0x30,%rsp
0x0000000002923eb9: pop %rbp
0x0000000002923eba: test %eax,-0x1c73dc0(%rip) # 0x0000000000cb0100
; {poll_return}
0x0000000002923ec0: retq ;*ireturn
; - AndTest::AndSC@13 (line 25)
0x0000000002923ec1: mov $0x1,%eax
0x0000000002923ec6: add $0x30,%rsp
0x0000000002923eca: pop %rbp
0x0000000002923ecb: test %eax,-0x1c73dd1(%rip) # 0x0000000000cb0100
; {poll_return}
0x0000000002923ed1: retq
Metoda AndSC z opcją -XX:PrintAssemblyOptions=intel
# {method} {0x00000000170a0810} 'AndSC' '(III)Z' in 'AndTest'
...
0x0000000002c26e2c: cmp r9d,r8d
0x0000000002c26e2f: jl 0x0000000002c26e36 ;*if_icmplt
0x0000000002c26e31: cmp r9d,edi
0x0000000002c26e34: jle 0x0000000002c26e44 ;*iconst_0
0x0000000002c26e36: xor eax,eax ;*synchronization entry
0x0000000002c26e38: add rsp,0x10
0x0000000002c26e3c: pop rbp
0x0000000002c26e3d: test DWORD PTR [rip+0xffffffffffce91bd],eax # 0x0000000002910000
0x0000000002c26e43: ret
0x0000000002c26e44: mov eax,0x1
0x0000000002c26e49: jmp 0x0000000002c26e38
Metoda AndNonSC z domyślną opcje
# {method} {0x0000000016da0908} 'AndNonSC' '(III)Z' in 'AndTest'
...
0x0000000002923a78: cmp %r8d,%r9d
0x0000000002923a7b: mov $0x0,%eax
0x0000000002923a80: jl 0x0000000002923a8b
0x0000000002923a86: mov $0x1,%eax
0x0000000002923a8b: cmp %edi,%r9d
0x0000000002923a8e: mov $0x0,%esi
0x0000000002923a93: jg 0x0000000002923a9e
0x0000000002923a99: mov $0x1,%esi
0x0000000002923a9e: and %rsi,%rax
0x0000000002923aa1: cmp $0x0,%eax
0x0000000002923aa4: je 0x0000000002923abb ;*ifeq
; - AndTest::AndNonSC@21 (line 29)
0x0000000002923aaa: mov $0x1,%eax
0x0000000002923aaf: add $0x30,%rsp
0x0000000002923ab3: pop %rbp
0x0000000002923ab4: test %eax,-0x1c739ba(%rip) # 0x0000000000cb0100
; {poll_return}
0x0000000002923aba: retq ;*ireturn
; - AndTest::AndNonSC@25 (line 30)
0x0000000002923abb: mov $0x0,%eax
0x0000000002923ac0: add $0x30,%rsp
0x0000000002923ac4: pop %rbp
0x0000000002923ac5: test %eax,-0x1c739cb(%rip) # 0x0000000000cb0100
; {poll_return}
0x0000000002923acb: retq
Metoda AndNonSC z opcją -XX:PrintAssemblyOptions=intel
# {method} {0x00000000170a0908} 'AndNonSC' '(III)Z' in 'AndTest'
...
0x0000000002c270b5: cmp r9d,r8d
0x0000000002c270b8: jl 0x0000000002c270df ;*if_icmplt
0x0000000002c270ba: mov r8d,0x1 ;*iload_2
0x0000000002c270c0: cmp r9d,edi
0x0000000002c270c3: cmovg r11d,r10d
0x0000000002c270c7: and r8d,r11d
0x0000000002c270ca: test r8d,r8d
0x0000000002c270cd: setne al
0x0000000002c270d0: movzx eax,al
0x0000000002c270d3: add rsp,0x10
0x0000000002c270d7: pop rbp
0x0000000002c270d8: test DWORD PTR [rip+0xffffffffffce8f22],eax # 0x0000000002910000
0x0000000002c270de: ret
0x0000000002c270df: xor r8d,r8d
0x0000000002c270e2: jmp 0x0000000002c270c0
- po pierwsze, wygenerowany kod ASM różni się w zależności od tego, czy wybieramy domyślną składnię AT&T, czy składnię Intela.
- ze składnią AT & T:
- kod ASM jest w rzeczywistości dłuższy dla metody
AndSC, z każdym bajtowym kodemIF_ICMP*tłumaczonym na dwie instrukcje skoku ASM, W Sumie 4 skoki warunkowe. - tymczasem dla
AndNonSCmetoda kompilator generuje bardziej prosty kod, gdzie każdy bajtIF_ICMP*jest tłumaczony tylko na jedną instrukcję skoku asemblera, zachowując oryginalną liczbę 3 skoków warunkowych.
- kod ASM jest w rzeczywistości dłuższy dla metody
- ze składnią Intela:
- kod ASM dla
AndSCjest krótszy, z tylko 2 skokami warunkowymi (nie licząc warunkowegojmpna końcu). Właściwie to tylko dwa CMP, dwa JL / E i XOR / MOV w zależności od wyniku. - kod ASM dla
AndNonSCjest teraz dłuższe niżAndSCone! jednak , ma tylko 1 skok warunkowy( dla pierwszego porównania), używając rejestrów do bezpośredniego porównania pierwszego wyniku z drugim, bez żadnych więcej skoków.
- kod ASM dla
Wniosek po analizie kodu ASM
- na poziomie języka maszynowego AMD64 operator
&wydaje się generować kod ASM z mniejszą liczbą skoków warunkowych, co może być lepsze dla wysokich wskaźników przewidywań (na przykład losowevalues). - z drugiej strony, operator
&&wydaje się generować kod ASM z mniejszą ilością instrukcji (z opcją-XX:PrintAssemblyOptions=intelw każdym razie), co może być lepsze dlanaprawdę długich pętli z wejściami przyjaznymi przewidywaniu, gdzie mniejsza liczba cykli procesora dla każdego porównania może mieć znaczenie w dłuższej perspektywie.
Jak stwierdziłem w niektórych komentarzach, to będzie się znacznie różnić między systemami, więc jeśli mówimy o optymalizacji przewidywania gałęzi, jedynym prawdziwa odpowiedź brzmiałaby: to zależy od implementacji JVM, kompilatora, procesora i danych wejściowych .
Dodatek: metoda Guava ' s isPowerOfTwo
W tym miejscu Programiści Guava wymyślili zgrabny sposób obliczania, jeśli dana liczba jest potęgą 2:]}
public static boolean isPowerOfTwo(long x) {
return x > 0 & (x & (x - 1)) == 0;
}
Cytowanie OP:
czy użycie
&(gdzie&&byłoby bardziej normalne) jest prawdziwą optymalizacją?
Aby dowiedzieć się, czy jest, dodałem dwa podobne metody do mojej klasy testowej:
public boolean isPowerOfTwoAND(long x) {
return x > 0 & (x & (x - 1)) == 0;
}
public boolean isPowerOfTwoANDAND(long x) {
return x > 0 && (x & (x - 1)) == 0;
}
Kod ASM Intela dla wersji Guava
# {method} {0x0000000017580af0} 'isPowerOfTwoAND' '(J)Z' in 'AndTest'
# this: rdx:rdx = 'AndTest'
# parm0: r8:r8 = long
...
0x0000000003103bbe: movabs rax,0x0
0x0000000003103bc8: cmp rax,r8
0x0000000003103bcb: movabs rax,0x175811f0 ; {metadata(method data for {method} {0x0000000017580af0} 'isPowerOfTwoAND' '(J)Z' in 'AndTest')}
0x0000000003103bd5: movabs rsi,0x108
0x0000000003103bdf: jge 0x0000000003103bef
0x0000000003103be5: movabs rsi,0x118
0x0000000003103bef: mov rdi,QWORD PTR [rax+rsi*1]
0x0000000003103bf3: lea rdi,[rdi+0x1]
0x0000000003103bf7: mov QWORD PTR [rax+rsi*1],rdi
0x0000000003103bfb: jge 0x0000000003103c1b ;*lcmp
0x0000000003103c01: movabs rax,0x175811f0 ; {metadata(method data for {method} {0x0000000017580af0} 'isPowerOfTwoAND' '(J)Z' in 'AndTest')}
0x0000000003103c0b: inc DWORD PTR [rax+0x128]
0x0000000003103c11: mov eax,0x1
0x0000000003103c16: jmp 0x0000000003103c20 ;*goto
0x0000000003103c1b: mov eax,0x0 ;*lload_1
0x0000000003103c20: mov rsi,r8
0x0000000003103c23: movabs r10,0x1
0x0000000003103c2d: sub rsi,r10
0x0000000003103c30: and rsi,r8
0x0000000003103c33: movabs rdi,0x0
0x0000000003103c3d: cmp rsi,rdi
0x0000000003103c40: movabs rsi,0x175811f0 ; {metadata(method data for {method} {0x0000000017580af0} 'isPowerOfTwoAND' '(J)Z' in 'AndTest')}
0x0000000003103c4a: movabs rdi,0x140
0x0000000003103c54: jne 0x0000000003103c64
0x0000000003103c5a: movabs rdi,0x150
0x0000000003103c64: mov rbx,QWORD PTR [rsi+rdi*1]
0x0000000003103c68: lea rbx,[rbx+0x1]
0x0000000003103c6c: mov QWORD PTR [rsi+rdi*1],rbx
0x0000000003103c70: jne 0x0000000003103c90 ;*lcmp
0x0000000003103c76: movabs rsi,0x175811f0 ; {metadata(method data for {method} {0x0000000017580af0} 'isPowerOfTwoAND' '(J)Z' in 'AndTest')}
0x0000000003103c80: inc DWORD PTR [rsi+0x160]
0x0000000003103c86: mov esi,0x1
0x0000000003103c8b: jmp 0x0000000003103c95 ;*goto
0x0000000003103c90: mov esi,0x0 ;*iand
0x0000000003103c95: and rsi,rax
0x0000000003103c98: and esi,0x1
0x0000000003103c9b: mov rax,rsi
0x0000000003103c9e: add rsp,0x50
0x0000000003103ca2: pop rbp
0x0000000003103ca3: test DWORD PTR [rip+0xfffffffffe44c457],eax # 0x0000000001550100
0x0000000003103ca9: ret
Kod ASM Intela dla wersji &&
# {method} {0x0000000017580bd0} 'isPowerOfTwoANDAND' '(J)Z' in 'AndTest'
# this: rdx:rdx = 'AndTest'
# parm0: r8:r8 = long
...
0x0000000003103438: movabs rax,0x0
0x0000000003103442: cmp rax,r8
0x0000000003103445: jge 0x0000000003103471 ;*lcmp
0x000000000310344b: mov rax,r8
0x000000000310344e: movabs r10,0x1
0x0000000003103458: sub rax,r10
0x000000000310345b: and rax,r8
0x000000000310345e: movabs rsi,0x0
0x0000000003103468: cmp rax,rsi
0x000000000310346b: je 0x000000000310347b ;*lcmp
0x0000000003103471: mov eax,0x0
0x0000000003103476: jmp 0x0000000003103480 ;*ireturn
0x000000000310347b: mov eax,0x1 ;*goto
0x0000000003103480: and eax,0x1
0x0000000003103483: add rsp,0x40
0x0000000003103487: pop rbp
0x0000000003103488: test DWORD PTR [rip+0xfffffffffe44cc72],eax # 0x0000000001550100
0x000000000310348e: ret
W tym konkretnym przykładzie kompilator JIT generuje o wiele mniej kodu asemblera dla wersji && niż dla wersji & (a po wczorajszych wynikach szczerze mnie to zaskoczyło).
Wersja && tłumaczy się na 25% mniej bajtowego kodu dla JIT do kompilacji, 50% mniej instrukcji montażu i tylko dwa skoki warunkowe (wersja & ma cztery z nich).
... A może jest?
Jak wspomniano wcześniej, uruchamiam powyższe przykłady z Java 8:
C:\....>java -version
java version "1.8.0_91"
Java(TM) SE Runtime Environment (build 1.8.0_91-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.91-b14, mixed mode)
Ale co jeśli przełączę się na Javę 7?
C:\....>c:\jdk1.7.0_79\bin\java -version
java version "1.7.0_79"
Java(TM) SE Runtime Environment (build 1.7.0_79-b15)
Java HotSpot(TM) 64-Bit Server VM (build 24.79-b02, mixed mode)
C:\....>c:\jdk1.7.0_79\bin\java -XX:+UnlockDiagnosticVMOptions -XX:CompileCommand=print,*AndTest.isPowerOfTwoAND -XX:PrintAssemblyOptions=intel AndTestMain
.....
0x0000000002512bac: xor r10d,r10d
0x0000000002512baf: mov r11d,0x1
0x0000000002512bb5: test r8,r8
0x0000000002512bb8: jle 0x0000000002512bde ;*ifle
0x0000000002512bba: mov eax,0x1 ;*lload_1
0x0000000002512bbf: mov r9,r8
0x0000000002512bc2: dec r9
0x0000000002512bc5: and r9,r8
0x0000000002512bc8: test r9,r9
0x0000000002512bcb: cmovne r11d,r10d
0x0000000002512bcf: and eax,r11d ;*iand
0x0000000002512bd2: add rsp,0x10
0x0000000002512bd6: pop rbp
0x0000000002512bd7: test DWORD PTR [rip+0xffffffffffc0d423],eax # 0x0000000002120000
0x0000000002512bdd: ret
0x0000000002512bde: xor eax,eax
0x0000000002512be0: jmp 0x0000000002512bbf
.....
& przez kompilator JIT w Javie 7, ma teraz tylko jeden warunkowy skok i jest o wiele krótszy! Natomiast metoda && (musisz mi zaufać w tej kwestii, nie chcę zaśmiecać zakończenia!) pozostaje mniej więcej taka sama, z dwoma skokami warunkowymi i kilkoma mniejszymi instrukcjami.Wygląda na to, że inżynierowie z guawy wiedzieli, co robią! (jeśli starali się zoptymalizować czas wykonania Java 7, to znaczy; -)
Więc wracając do ostatniego pytania OP:
jest to użycie
&(gdzie&&byłoby bardziej normalne) prawdziwa optymalizacja?
I IMHO odpowiedź jest taka sama , nawet za to (bardzo!) konkretny scenariusz: zależy to od implementacji JVM, kompilatora, procesora i danych wejściowych.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-09-21 14:59:05
W przypadku takich pytań należy uruchomić microbenchmark. Do tego testu użyłem JMH.
Benchmarki są zaimplementowane jako
// boolean logical AND
bh.consume(value >= x & y <= value);
I
// conditional AND
bh.consume(value >= x && y <= value);
I
// bitwise OR, as suggested by Joop Eggen
bh.consume(((value - x) | (y - value)) >= 0)
Z wartościami dla value, x and y zgodnie z nazwą wzorca.
Benchmark Mode Cnt Score Error Units
Benchmark.isBooleanANDBelowRange thrpt 10 386.086 ▒ 17.383 ops/us
Benchmark.isBooleanANDInRange thrpt 10 387.240 ▒ 7.657 ops/us
Benchmark.isBooleanANDOverRange thrpt 10 381.847 ▒ 15.295 ops/us
Benchmark.isBitwiseORBelowRange thrpt 10 384.877 ▒ 11.766 ops/us
Benchmark.isBitwiseORInRange thrpt 10 380.743 ▒ 15.042 ops/us
Benchmark.isBitwiseOROverRange thrpt 10 383.524 ▒ 16.911 ops/us
Benchmark.isConditionalANDBelowRange thrpt 10 385.190 ▒ 19.600 ops/us
Benchmark.isConditionalANDInRange thrpt 10 384.094 ▒ 15.417 ops/us
Benchmark.isConditionalANDOverRange thrpt 10 380.913 ▒ 5.537 ops/us
Wynik nie różni się tak bardzo w przypadku samej oceny. Dopóki nie ma wpływu na wydajność zauważony na tym kawałku kodu nie próbowałbym go optymalizować. W zależności od miejsca w kodzie kompilator hotspot może zdecydować się na pewną optymalizację. Które prawdopodobnie nie są objęte powyższymi wskaźnikami.
Niektóre odniesienia:
Boolean logical AND - wartością wyniku jest true, jeśli obie wartości są true; w przeciwnym razie wynik jest false
conditional and - is like &, but evaluates its right-hand operand only if the value of its operand lewostronny jest true
bitwise OR - wartość wyniku jest bitwise inclusive or wartości operandu
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-09-21 06:24:17
Podejdę do tego z innej perspektywy.
Rozważmy te dwa fragmenty kodu,
if (value >= x && value <= y) {
I
if (value >= x & value <= y) {
Jeśli przyjmiemy, że value, x, y mają typ prymitywny, wtedy te dwa (częściowe) polecenia dadzą taki sam wynik dla wszystkich możliwych wartości wejściowych. (Jeśli chodzi o typy wrapperów, to nie są one dokładnie równoważne ze względu na niejawny test null dla y, który może zawieść w wersji &, a nie w wersji &&.)
Jeśli Kompilator JIT robi dobrą robotę, jego optymalizator będzie w stanie wywnioskować, że te dwa stwierdzenia robią to samo:
Jeśli jeden jest przewidywalnie szybszy od drugiego, powinien być w stanie korzystać z szybszej wersji ... w skompilowanym kodzie JIT .
Jeśli nie, to nie ma znaczenia, która wersja jest używana na poziomie kodu źródłowego.
Ponieważ kompilator JIT zbiera statystyki ścieżek przed kompilacją, może potencjalnie mieć więcej informacje o cechach wykonania, które programista (!).
Jeśli kompilator JIT obecnej generacji (na danej platformie) nie zoptymalizuje się wystarczająco dobrze, aby sobie z tym poradzić, może to zrobić następna generacja ... w zależności od tego, czy empiryczne dowody wskazują na to, że jest to wartościowy wzór do optymalizacji.
Rzeczywiście, jeśli piszesz kod Javy w sposób optymalizujący do tego, istnieje } szansa , że wybierając bardziej "niejasna" wersja kodu, Może zahamować zdolność obecnego lub przyszłego kompilatora JIT do optymalizacji.
W skrócie, myślę, że nie powinieneś robić tego rodzaju mikro-optymalizacji na poziomie kodu źródłowego. I jeśli zaakceptujesz ten argument1, i podążać za nim do logicznego wniosku, pytanie, Która wersja jest szybsza jest ... moot2.
1 - nie twierdzę, że jest to w pobliżu dowód.
2 - chyba, że jesteś jedną z maleńkiej społeczności ludzi, którzy faktycznie piszą Kompilatory Java JIT ...
"bardzo znane pytanie" jest interesujące pod dwoma względami:
Z jednej strony jest to przykład, w którym rodzaj optymalizacji wymaganej do dokonania różnicy jest znacznie wykraczający poza możliwości kompilatora JIT.
Z drugiej strony, sortowanie tablicy niekoniecznie byłoby poprawne ... just ponieważ posortowana tablica może być przetwarzana szybciej. Koszt sortowania tablicy, może być (znacznie) większy niż oszczędności.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-09-20 09:56:15
Użycie & lub && nadal wymaga oceny warunku, więc jest mało prawdopodobne, że zaoszczędzi to jakikolwiek czas przetwarzania - może nawet do tego dodać, biorąc pod uwagę, że oceniasz oba wyrażenia, gdy musisz ocenić tylko jedno.
Użycie & over && do zapisania nanosekundy jeśli w bardzo rzadkich sytuacjach jest to bezcelowe, zmarnowałeś już więcej czasu na rozważanie różnicy niż zaoszczędziłbyś używając & over &&.
Edit
Zaciekawiłem się i postanowiłem sprawdzić kilka miejsc na ławce.
I made this class:
public class Main {
static int x = 22, y = 48;
public static void main(String[] args) {
runWithOneAnd(30);
runWithTwoAnds(30);
}
static void runWithOneAnd(int value){
if(value >= x & value <= y){
}
}
static void runWithTwoAnds(int value){
if(value >= x && value <= y){
}
}
}
I przeprowadziłem kilka testów profilowania z NetBeans. Nie używałem żadnych instrukcji print, aby zaoszczędzić czas przetwarzania, po prostu wiem, że oba oceń do true.
Pierwszy test:

Drugi test:

Trzeci test:
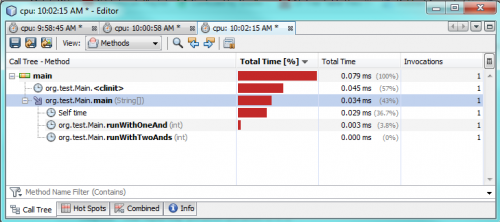
Jak widać po testach profilowania, użycie tylko jednego & w rzeczywistości trwa 2-3 razy dłużej niż użycie dwóch &&. To wydaje się dziwne, ponieważ spodziewałem się lepszej wydajności tylko po jednym &.
Morał historii: konwencja jest dobra, a przedwczesna optymalizacja jest zła.
Edit 2
Zmieniłem kod benchmarka z myślą o komentarzach @SvetlinZarev i kilku innych ulepszeniach. Oto zmodyfikowany kod benchmarka:
public class Main {
static int x = 22, y = 48;
public static void main(String[] args) {
oneAndBothTrue();
oneAndOneTrue();
oneAndBothFalse();
twoAndsBothTrue();
twoAndsOneTrue();
twoAndsBothFalse();
System.out.println(b);
}
static void oneAndBothTrue() {
int value = 30;
for (int i = 0; i < 2000; i++) {
if (value >= x & value <= y) {
doSomething();
}
}
}
static void oneAndOneTrue() {
int value = 60;
for (int i = 0; i < 4000; i++) {
if (value >= x & value <= y) {
doSomething();
}
}
}
static void oneAndBothFalse() {
int value = 100;
for (int i = 0; i < 4000; i++) {
if (value >= x & value <= y) {
doSomething();
}
}
}
static void twoAndsBothTrue() {
int value = 30;
for (int i = 0; i < 4000; i++) {
if (value >= x & value <= y) {
doSomething();
}
}
}
static void twoAndsOneTrue() {
int value = 60;
for (int i = 0; i < 4000; i++) {
if (value >= x & value <= y) {
doSomething();
}
}
}
static void twoAndsBothFalse() {
int value = 100;
for (int i = 0; i < 4000; i++) {
if (value >= x & value <= y) {
doSomething();
}
}
}
//I wanted to avoid print statements here as they can
//affect the benchmark results.
static StringBuilder b = new StringBuilder();
static int times = 0;
static void doSomething(){
times++;
b.append("I have run ").append(times).append(" times \n");
}
}
A oto testy wydajności:
Test 1:

Test 2:

Test 3:

Uwzględnia to również różne wartości i różne warunki.
Użycie jednego & zajmuje więcej czasu, gdy oba warunki są prawdziwe, około 60% lub 2 milisekundy więcej czasu. Gdy jeden lub oba warunki są fałszywe, wtedy jeden & działa szybciej, ale działa tylko o 0,30-0,50 milisekundy szybciej. Więc & będzie działać szybciej niż && w większości sytuacji, ale różnica w wydajności jest nadal znikoma.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-09-20 09:24:43
To czego szukasz to coś takiego:
x <= value & value <= y
value - x >= 0 & y - value >= 0
((value - x) | (y - value)) >= 0 // integer bit-or
Ciekawe, prawie chciałoby się spojrzeć na kod bajtowy. Ale trudno powiedzieć. Chciałbym, żeby to było pytanie C.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-09-20 07:55:14
Też byłem ciekaw odpowiedzi, więc napisałem do tego następujący (prosty) test:
private static final int max = 80000;
private static final int size = 100000;
private static final int x = 1500;
private static final int y = 15000;
private Random random;
@Before
public void setUp() {
this.random = new Random();
}
@After
public void tearDown() {
random = null;
}
@Test
public void testSingleOperand() {
int counter = 0;
int[] numbers = new int[size];
for (int j = 0; j < size; j++) {
numbers[j] = random.nextInt(max);
}
long start = System.nanoTime(); //start measuring after an array has been filled
for (int i = 0; i < numbers.length; i++) {
if (numbers[i] >= x & numbers[i] <= y) {
counter++;
}
}
long end = System.nanoTime();
System.out.println("Duration of single operand: " + (end - start));
}
@Test
public void testDoubleOperand() {
int counter = 0;
int[] numbers = new int[size];
for (int j = 0; j < size; j++) {
numbers[j] = random.nextInt(max);
}
long start = System.nanoTime(); //start measuring after an array has been filled
for (int i = 0; i < numbers.length; i++) {
if (numbers[i] >= x & numbers[i] <= y) {
counter++;
}
}
long end = System.nanoTime();
System.out.println("Duration of double operand: " + (end - start));
}
W wyniku czego porównanie z & & zawsze wygrywa pod względem prędkości, będąc o 1,5/2 milisekundy szybsze niż &.
EDIT: Jak zauważył @SvetlinZarev, mierzyłem również czas, jaki zajęło losowe uzyskanie liczby całkowitej. Zmieniono go, aby użyć wstępnie wypełnionej tablicy liczb losowych, co spowodowało, że czas trwania pojedynczego testu operand gwałtownie się wahał; różnice między kilkoma przebiegami wynosiły do 6-7ms.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-09-20 09:13:52
Sposób, w jaki zostało mi to wyjaśnione, jest taki, że & & zwróci false, jeśli pierwsze sprawdzenie w serii jest false, podczas gdy & sprawdza wszystkie pozycje w serii niezależnie od tego, ile z nich jest false. I. E.
If (x>0 & & x
Będzie działać szybciej niż
If (x>0 & x
Jeśli x jest większe niż 10, ponieważ pojedyncze ampersandy będą nadal sprawdzać pozostałe warunki, podczas gdy podwójne ampersandy ulegną złamaniu po pierwszym warunku nieprawdziwym.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-09-29 01:16:31