Kiedy stosować RabbitMQ nad Kafką? [zamknięte]
chcesz poprawić to pytanie? Zaktualizuj pytanie, aby mogło być odpowiedź z faktami i cytatami przez edytując ten post .
Zamknięte 7 miesięcy temu .
Popraw to pytaniePoproszono mnie o ocenę RabbitMQ zamiast Kafki, ale trudno było znaleźć sytuację, w której Kolejka komunikatów jest bardziej odpowiednia niż Kafka. Czy ktoś zna przypadki użycia, w których Kolejka komunikatów lepiej pasuje pod względem przepustowości, trwałości, opóźnień lub łatwości użycia?
16 answers
RabbitMQ jest solidnym brokerem wiadomości ogólnego przeznaczenia , który obsługuje kilka protokołów, takich jak AMQP, MQTT, STOMP, itp. Może obsługiwać wysoką przepustowość. RabbitMQ jest często używany do obsługi zadań w tle lub długotrwałych zadań, takich jak skanowanie plików , skalowanie obrazów lub Konwersja plików PDF. RabbitMQ jest również używany między mikroserwisami, gdzie służy jako środek komunikacji między aplikacjami, unikając wąskich gardeł przekazujących wiadomości.
Kafka to autobus komunikacyjny zoptymalizowany pod kątem strumieni danych o dużej przepustowości i powtórek. Korzystaj z Kafki, gdy musisz przenieść dużą ilość danych, przetwarzać dane w czasie rzeczywistym lub analizować dane w określonym czasie. Innymi słowy, gdzie dane muszą być gromadzone, przechowywane i przetwarzane. Przykładem może być śledzenie aktywności użytkownika w sklepie internetowym i generowanie sugerowanych produktów do zakupu. Innym przykładem jest analiza danych w celu śledzenia, przechwytywania, rejestrowania lub bezpieczeństwa.
Kafka może być postrzegana jako trwała message broker gdzie aplikacje mogą przetwarzać i ponownie przetwarzać strumieniowane dane na dysku. Kafka ma bardzo proste podejście do routingu. RabbitMQ ma lepsze opcje, jeśli chcesz kierować swoje wiadomości w złożony sposób do swoich konsumentów. Użyj Kafka, jeśli chcesz obsługiwać konsumentów wsadowych, którzy mogą być w trybie offline lub konsumentów, którzy chcą wiadomości z małym opóźnieniem.
Aby zrozumieć, jak odczytać dane z Kafki, musimy najpierw zrozumieć jej konsumentów i grupy konsumentów. Partycje pozwalają na zrównoleglenie tematu, dzieląc dane na wiele węzłów. Każdy rekord na partycji jest przypisany i identyfikowany przez jego unikalne przesunięcie. Przesunięcie to wskazuje na rekord w partycji. W najnowszej wersji Kafka, Kafka utrzymuje numeryczne przesunięcie dla każdego rekordu w partycji. Konsument w Kafka może albo automatycznie dokonywać korekt okresowo, albo może zdecydować się na ręczną kontrolę tej pozycji. RabbitMQ zachowa wszystkie stany o konsumowanych / potwierdzonych/nie potwierdzonych wiadomości. Uważam, że Kafka jest bardziej skomplikowana do zrozumienia niż przypadek RabbitMQ, gdzie wiadomość jest po prostu usuwana z kolejki po jej zablokowaniu.
Kolejki RabbitMQ są najszybsze, gdy są puste, podczas gdy Kafka przechowuje duże ilości danych z bardzo małym obciążeniem-Kafka jest przeznaczona do przechowywania i dystrybucji dużych ilości wiadomości. (Jeśli planujesz mieć bardzo długie kolejki w RabbitMQ, możesz rzucić okiem na leniwe kolejki .)
Kafka zbudowana jest od podstaw z skalowanie poziome (skalowanie przez dodanie większej liczby maszyn), podczas gdy RabbitMQ jest głównie przeznaczony do skalowania pionowego (skalowanie przez dodanie większej mocy).
RabbitMQ ma wbudowany przyjazny dla użytkownika interfejs, który pozwala monitorować i obsługiwać serwer RabbitMQ z przeglądarki internetowej. Między innymi można obsługiwać kolejki, połączenia, kanały, giełdy, użytkowników i uprawnienia użytkowników-tworzyć, usuwać i wymieniać w przeglądarce, a także monitorować stawki wiadomości i wysyłać/odbierać wiadomości ręcznie. Kafka posiada wiele narzędzi open-source, a także kilka komercyjnych once , oferujących funkcje administracji i monitorowania. Powiedziałbym, że łatwiej/szybciej jest uzyskać dobre zrozumienie RabbitMQ.
Ogólnie rzecz biorąc, jeśli chcesz prostego / tradycyjnego brokera wiadomości pub-sub, oczywistym wyborem jest RabbitMQ, ponieważ najprawdopodobniej będzie on skalowany bardziej niż kiedykolwiek będziesz go potrzebować do skalowania. Wybrałbym RabbitMQ, gdyby moje wymagania były wystarczająco proste, aby poradzić sobie z systemem komunikacja za pośrednictwem kanałów / kolejek oraz tam, gdzie przechowywanie i przesyłanie strumieniowe nie jest wymagane.
Istnieją dwie główne sytuacje, w których wybrałbym RabbitMQ; dla długotrwałych zadań, kiedy muszę uruchomić niezawodne zadania w tle. Jako pośrednik między mikroserwisami ; gdzie system musi po prostu powiadomić inną część systemu, aby rozpocząć pracę nad zadaniem, jak obsługa zamówień w sklepie internetowym (zamówienie złożone, zaktualizuj status zamówienia, wyślij zamówienie, Płatność itp.).
Ogólnie rzecz biorąc, jeśli chcesz mieć framework do przechowywania, czytania (ponownego czytania) i analizowania danych strumieniowych, użyj Apache Kafka.Jest idealny dla Systemów, które są kontrolowane lub tych, które muszą przechowywać wiadomości na stałe. Można je również podzielić na dwa główne przypadki użycia do analizy danych(śledzenie, przechwytywanie, rejestrowanie, bezpieczeństwo itp.) lub przetwarzanie w czasie rzeczywistym.
Więcej lektur, przypadków użycia i niektórych danych porównawczych można znaleziono tutaj: https://www.cloudamqp.com/blog/2019-12-12-when-to-use-rabbitmq-or-apache-kafka.html
Polecam również papier branżowy: "Kafka versus RabbitMQ: a comparative study of two industry reference publish/subscribe implementations": http://dl.acm.org/citation.cfm?id=3093908
Pracuję w firmie dostarczającej zarówno Apache Kafka jak i RabbitMQ jako usługę.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2021-01-03 14:46:17
Słyszę to pytanie co tydzień... Podczas gdy RabbitMQ (podobnie jak IBM MQ lub JMS lub inne rozwiązania do przesyłania wiadomości w ogóle) jest używany do tradycyjnego przesyłania wiadomości, Apache Kafka jest używany jako platforma strumieniowa (wiadomości + rozproszona pamięć masowa + przetwarzanie danych). Oba są zbudowane dla różnych przypadków użycia.
Możesz używać Kafki do "tradycyjnego przesyłania wiadomości", ale nie używać MQ do scenariuszy specyficznych dla Kafki.
Artykuł " Apache Kafka vs. Enterprise Service Bus (ESB)-przyjaciele, wrogowie lub Wrogowie? (https://www.confluent.io/blog/apache-kafka-vs-enterprise-service-bus-esb-friends-enemies-or-frenemies/)"omawia, dlaczego Kafka nie jest konkurencyjna, ale komplementarna do rozwiązań integracyjnych i komunikatorów (w tym RabbitMQ) i jak zintegrować oba.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-07-27 07:17:00
5 Główne różnice pomiędzy Kafką a RabbitMQ, klientem, który ich używa:
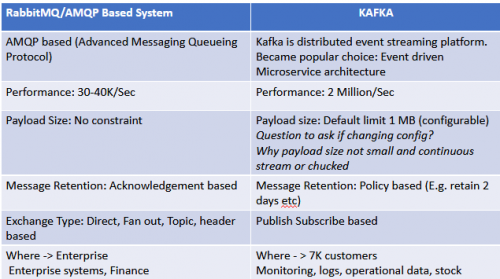
Jaki system wiadomości wybrać, czy powinniśmy zmienić nasz istniejący system wiadomości?
Na powyższe pytanie nie ma odpowiedzi. Jednym z możliwych podejść do przeglądu, gdy trzeba zdecydować, który system wiadomości lub należy zmienić istniejący system jest "ocenić zakres i koszt "
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-05-09 05:28:44
Jedna krytyczna różnica, o której zapomnieliście, to RabbitMQ jest systemem komunikacyjnym opartym na push, podczas gdy Kafka jest systemem komunikacyjnym opartym na pull. Jest to ważne w scenariuszu, w którym system przesyłania wiadomości musi zaspokoić różne typy konsumentów o różnych możliwościach przetwarzania. Dzięki systemowi opartemu na Pull konsument może konsumować w oparciu o swoje możliwości, gdzie systemy push będą wysyłać wiadomości niezależnie od stanu konsumenta, narażając konsumenta na wysokie ryzyko.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-06-03 04:39:42
RabbitMQ jest tradycyjnym brokerem komunikatów ogólnego przeznaczenia. Umożliwia serwerom internetowym szybkie reagowanie na żądania i dostarczanie wiadomości do wielu usług. Wydawcy mogą publikować wiadomości i udostępniać je kolejkom, aby konsumenci mogli je odzyskać. Komunikacja może być asynchroniczna lub synchroniczna.
Z drugiej strony, Apache Kafka nie jest tylko brokerem wiadomości. Został początkowo zaprojektowany i wdrożony przez LinkedIn aby służyć jako Kolejka komunikatów. Od 2011 roku Kafka jest open source i szybko przekształciła się w rozproszoną platformę strumieniową, która jest używana do implementacji potoków danych w czasie rzeczywistym i aplikacji strumieniowych.
Jest skalowalny poziomo, odporny na błędy, bardzo szybki i działa w produkcja w tysiącach firm.
Nowoczesne organizacje mają różne potoki danych, które ułatwiają komunikację między systemami lub usługami. Rzeczy się nieco bardziej skomplikowane, gdy rozsądna liczba usług musi komunikować się ze sobą w czasie rzeczywistym.
Architektura staje się złożona, ponieważ różne integracje są wymagane w celu umożliwienia komunikacji między tymi usługami. Dokładniej, dla architektury, która obejmuje usługi M source i N target, n x M oddzielne integracje muszą być napisane. Ponadto każda integracja ma inną specyfikację, co oznacza, że można wymagać innej protokół (HTTP, TCP, JDBC, itp.) lub innej reprezentacji danych (Binary, Apache Avro, JSON itp.), czyniąc to jeszcze większym wyzwaniem. Ponadto usługi źródłowe mogą adresować zwiększone obciążenie połączeń, które może potencjalnie wpływać na opóźnienia.
Apache Kafka prowadzi do prostszych i łatwiejszych w zarządzaniu architektur poprzez oddzielenie potoków danych. Kafka działa jako wysokoprzepustowy system rozproszony, w którym usługi źródłowe przesyłają strumienie danych, udostępniając je docelowym usługom wyciągnij je w czasie rzeczywistym.
Ponadto, wiele otwartych i korporacyjnych interfejsów użytkownika do zarządzania klastrami Kafka jest już dostępnych. Więcej szczegółów w moich artykułach Przegląd narzędzi do monitorowania interfejsu użytkownika dla klastrów Apache Kafka oraz dlaczego Apache Kafka?
Decyzja o wyborze RabbitMQ lub Kafka zależy od wymagań Twojego projektu. Ogólnie rzecz biorąc, jeśli chcesz prostego / tradycyjnego brokera wiadomości pub-sub więc idź na RabbitMQ. Jeśli chcesz zbudować architekturę opartą na zdarzeniach, na której Twoja organizacja będzie działać na wydarzeniach w czasie rzeczywistym, wybierz Apache Kafka, ponieważ zapewnia więcej funkcji dla tego typu architektury (na przykład Kafka Streams lub ksqlDB).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-04-10 21:36:04
Wiem, że jest trochę późno i może już, pośrednio, to powiedziałeś, ale znowu Kafka to nie Kolejka, to log (jak ktoś powiedział powyżej, na podstawie ankiety).
Aby to uprościć, najbardziej oczywistym przypadkiem użycia, kiedy powinieneś preferować RabbitMQ (lub dowolną kolejkę techno) nad Kafką jest następujący:
Masz wielu konsumentów korzystających z kolejki i gdy w kolejce pojawia się nowa wiadomość i dostępny konsument, chcesz, aby ta wiadomość została przetworzona. Jeśli spojrzysz dokładnie jak działa Kafka, zauważysz, że nie wie jak to zrobić, ze względu na skalowanie partycji, będziesz miał klienta dedykowanego partycji i będziesz miał problem z głodem. Problem, którego można łatwo uniknąć za pomocą prostego kolejkowania techno. Można pomyśleć o użyciu wątku, który będzie wysyłał różne wiadomości z tej samej partycji, ale ponownie, Kafka nie ma żadnych selektywnych mechanizmów potwierdzania.
Najlepsze co możesz zrobić to robić jako ci faceci i próbować przekształcić Kafka jak Kolejka : https://github.com/softwaremill/kmq
Yannick
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-08-20 20:08:18
Użyj RabbitMQ gdy:
- nie musisz obsługiwać Bigdata i wolisz wygodny wbudowany interfejs użytkownika do monitorowania
- nie ma potrzeby automatycznego powtarzania kolejek
- Brak wielu subskrybentów dla wiadomości - ponieważ w przeciwieństwie do Kafki, która jest logiem, RabbitMQ jest kolejką, a wiadomości są usuwane po zużyciu i otrzymaniu potwierdzenia
- Jeśli masz wymagania, aby używać symboli wieloznacznych i wyrażeń regularnych dla wiadomości
- Jeśli zdefiniowanie priorytetu wiadomości jest ważne
W Skrócie: RabbitMQ jest dobry do prostych przypadków użycia, z małym ruchem danych, z korzyścią kolejki priorytetów i elastycznych opcji routingu. Dla ogromnych danych i wysokiej przepustowości użyj Kafka.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-08-24 21:44:50
Przedstawię obiektywną odpowiedź na podstawie mojego doświadczenia z obydwoma, pominę również stojącą za nimi teorię, zakładając, że już ją znasz i / lub inne odpowiedzi dostarczyły już wystarczająco dużo.
RabbitMQ: wybrałbym ten, jeśli moje wymagania są na tyle proste, aby poradzić sobie z komunikacją systemową za pośrednictwem kanałów / kolejek, retencja i streaming nie są wymagane. Np. gdy system produkcji zbudował zasób, powiadamia system umowy o skonfigurowaniu kontrakty i tak dalej.
Kafka : Wymaganie pozyskiwania zdarzeń głównie, gdy może być konieczne radzenie sobie ze strumieniami (czasami nieskończonymi), ogromną ilością danych naraz odpowiednio zbalansowanych, przesunięciami powtórek w celu zapewnienia danego stanu i tak dalej. Należy pamiętać, że ta architektura przynosi również większą złożoność, ponieważ zawiera pojęcia takie jak tematy/partycje/brokerzy/wiadomości nagrobkowe itp. jako pierwszorzędne znaczenie.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-06-20 11:34:26
Jeśli masz złożone potrzeby routingu i chcesz wbudowanego GUI do monitorowania brokera, RabbitMQ może być najlepszy dla Twojej aplikacji. W przeciwnym razie, Jeśli szukasz brokera wiadomości, który obsłuży wysoką przepustowość i zapewni dostęp do historii strumieni, Kafka jest prawdopodobnie lepszym wyborem.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-06-09 19:06:47
Jedyną korzyścią, o której myślę, jest funkcja transakcyjna, resztę można zrobić za pomocą Kafki
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-03-15 23:22:20
Skalowanie obu jest trudne w sposób odporny na rozproszone błędy, ale chciałbym powiedzieć, że jest znacznie trudniejsze na masową skalę z RabbitMQ. Nie jest trywialne rozumienie, Federacja, lustrzane kolejki Msg, ACK, problemy Mem, Fault tollerance itp. Nie powiem, że nie będziesz miał też konkretnych problemów z Zookeeperem itp na Kafce, ale jest mniej ruchomych części do zarządzania. To powiedziawszy, dostajesz wymianę poligloty z RMQ, której nie masz z Kafką. Jeśli chcesz streamować, użyj Kafki. Jeśli chcesz proste IoT lub podobne przesyłanie pakietów o dużej objętości, użyj Kafki. Chodzi o inteligentnych konsumentów. Jeśli chcesz elastyczności msg i większej niezawodności przy wyższych kosztach i ewentualnie pewnej złożoności, użyj RMQ.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-04-06 18:11:07
Najczęściej głosowana odpowiedź obejmuje większość części, ale chciałbym wysokiego punktu widzenia przypadku użycia światła. Czy kafka może zrobić, że rabbit mq może zrobić, odpowiedź brzmi tak, ale czy rabbit mq może zrobić wszystko, co kafka robi, odpowiedź brzmi nie.
Rzeczą, której rabbit mq nie może zrobić, która sprawia, że kafka jest oddzielona, jest rozproszone przetwarzanie wiadomości. Z tym teraz czytać z powrotem najbardziej głosował odpowiedź i będzie to miało więcej sensu.
Aby rozwinąć, weź przykład użycia, w którym musisz stworzyć system wiadomości, który ma super wysoka przepustowość, na przykład "Polubienia" na facebook ' u i wybrałeś do tego rabbit mq. Stworzyłeś giełdę i kolejkę oraz konsumenta, w którym wszyscy wydawcy (w tym przypadku użytkownicy FB) mogą publikować wiadomości "Polubienia". Ponieważ twoja przepustowość jest wysoka, utworzysz wiele wątków w programie consumer, aby przetwarzać wiadomości równolegle, ale nadal ograniczasz się do pojemności sprzętowej komputera, na którym pracuje konsument. Zakładając, że jeden konsument nie jest wystarczający do przetworzenia wszystkich wiadomości-co byś zrobić?
- czy możesz dodać jeszcze jednego konsumenta do kolejki-nie możesz tego zrobić.
- czy możesz utworzyć nową kolejkę i powiązać tę kolejkę z exchange, która publikuje wiadomość "Polubienia", odpowiedź nie jest przyczyną, że wiadomości będą przetwarzane dwa razy.
To jest główny problem, który kafka rozwiązuje. Pozwala na tworzenie rozproszonych partycji (kolejka w rabbit mq) i rozproszonych konsumentów, które ze sobą rozmawiają. Dzięki temu Twoje wiadomości w temacie będą przetwarzane przez konsumentów dystrybuowanych w różne węzły (Maszyny).
Kafka brokerzy zapewniają, że wiadomości mają zrównoważone obciążenie na wszystkich partycjach tego tematu. Grupa konsumentów upewnij się, że wszyscy konsumenci rozmawiają ze sobą i wiadomości nie są przetwarzane dwa razy.
Ale w prawdziwym życiu nie napotkasz tego problemu, chyba że Twoja przepustowość jest poważnie wysoka, ponieważ rabbit mq może również przetwarzać dane bardzo szybko, nawet z jednym konsumentem.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2021-01-02 14:18:33
technicznie Kafka oferuje ogromny superset funkcji w porównaniu do zestawu funkcji oferowanych przez Rabbit mq.
Jeśli pytanie jest
czy królik mq jest technicznie lepszy od Kafki?
Wtedy odpowiedź brzmi
Nie .
Jeśli jednak pytanie jest
Czy Rabbit mq jest lepszy od Kafki z biznesowego punktu widzenia?
Wtedy odpowiedź brzmi
prawdopodobnie "Tak", w niektórych scenariuszach biznesowych
Rabbit MQ może być lepszy od Kafki, z biznesowego punktu widzenia, z następujących powodów:
-
Utrzymanie starszych aplikacji, które zależą od Rabbit MQ
-
Koszty szkolenia personelu i stroma krzywa uczenia się wymagana do wdrożenia Kafka
-
Koszt infrastruktury dla Kafki jest wyższy niż dla Rabbit MQ.
-
Rozwiązywanie problemów w Kafka implementacja jest trudna w porównaniu z implementacją Rabbit mq.
-
Programista Rabbit mq może łatwo utrzymywać i wspierać aplikacje, które używają Rabbit mq.
-
To samo nie jest prawdą z Kafką. Doświadczenie z just Kafka development nie jest wystarczające do utrzymania i wsparcia aplikacji, które używają Kafka. Personel pomocniczy wymaga również innych umiejętności, takich jak opiekun zoo, sieć, pamięć dyskowa.
-
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-06-27 09:44:05
Apache Kafka jest popularnym wyborem do zasilania potoków danych. Apache kafka dodał kafka stream do obsługi popularnych przypadków użycia etl. KSQL ułatwia przekształcanie danych w potoku, przygotowując Wiadomości do czystego lądowania w innym systemie. KSQL jest strumieniowym silnikiem SQL dla Apache Kafka. Zapewnia łatwy w użyciu, ale potężny interaktywny interfejs SQL do przetwarzania strumienia na Kafka, bez konieczności pisania kodu w języku programowania, takim jak Java lub Python. KSQL jest skalowalny, elastyczny, odporny na uszkodzenia i w czasie rzeczywistym. Obsługuje szeroki zakres operacji przesyłania strumieniowego, w tym filtrowanie danych, transformacje, agregacje, połączenia, oknami i sesjonizację.
Https://docs.confluent.io/current/ksql/docs/index.html
Rabbitmq nie jest popularnym wyborem dla Systemów etl, a raczej dla tych systemów, w których wymaga prostych systemów przesyłania wiadomości o mniejszej przepustowości.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-01-02 15:45:28
Zdaję sobie sprawę, że to stare pytanie, ale jednym ze scenariuszy, w którym RabbitMQ może być lepszym wyborem, jest edycja danych.
Z RabbitMQ, domyślnie po zużyciu wiadomości jest ona usuwana. W przypadku Kafki domyślnie wiadomości są przechowywane przez tydzień. Często ustawia się to na znacznie dłuższy czas, a nawet nigdy ich nie usuwa.
Podczas gdy oba produkty można skonfigurować tak, aby zachowywały (lub nie zachowywały) wiadomości, Jeśli zgodność z CCPA lub GDPR jest problemem, wybrałbym RabbitMQ.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-02-01 02:59:47
Krótka odpowiedź to "potwierdzenia wiadomości". RabbitMQ może być skonfigurowany tak, aby wymagał potwierdzenia wiadomości. Jeśli odbiornik zawiedzie, wiadomość wraca do kolejki i inny odbiornik może spróbować ponownie. Chociaż możesz to osiągnąć w Kafka za pomocą własnego kodu, działa on z RabbitMQ po wyjęciu z pudełka.
Z mojego doświadczenia, jeśli masz aplikację, która ma wymagania do zapytania strumień informacji, Kafka i KSql są najlepszym rozwiązaniem. Jeśli chcesz system kolejkowy jesteś lepiej z RabbitMQ.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-06-08 12:08:55