Czy powinienem nauczyć się / używać MapReduce, lub innego rodzaju równoległości dla tego zadania?
Po rozmowie z moim przyjacielem z Google, chciałbym zaimplementować jakiś model pracy / pracownika do aktualizacji mojego zbioru danych.
Ten zestaw danych odzwierciedla dane usługi 3rd party, więc, aby wykonać aktualizację, muszę wykonać kilka zdalnych połączeń do ich API. Myślę, że dużo czasu spędzimy czekając na odpowiedzi od tej usługi 3rd party. Chciałbym przyspieszyć i lepiej wykorzystać moje godziny obliczeniowe, porównując te żądania i utrzymując wiele z nich otwartych naraz, ponieważ czekają na indywidualne odpowiedzi.
Zanim wyjaśnię mój konkretny zbiór danych i przejdę do problemu, chciałbym wyjaśnić, jakich odpowiedzi Szukam:
- czy jest to przepływ, który dobrze nadaje się do równoległego porównywania z MapReduce?
- Jeśli tak , czy byłoby to opłacalne, aby uruchomić na module mapreduce Amazona, który rachunki przez godzinę, a rounds godzina kończy się, gdy zadanie jest zakończone? (Nie jestem pewien, co dokładnie liczy się jako "praca", więc nie wiem dokładnie Jak będę rozliczany)
- Jeśli Nie , czy jest inny system / wzór, którego powinienem użyć? i czy jest jakaś biblioteka, która pomoże mi to zrobić w Pythonie (na AWS, usign EC2 + EBS)? Widzisz jakieś problemy ze sposobem, w jaki zaprojektowałem tę pracę?
Ok, przejdźmy teraz do szczegółów:
Zbiór danych składa się z użytkowników, którzy mają ulubione przedmioty i którzy śledzą innych użytkowników. Celem jest możliwość aktualizacji kolejki każdego użytkownika - listy elementów, które użytkownik będzie zobacz, kiedy ładują stronę, na podstawie ulubionych elementów użytkowników, których śledzi. Ale zanim będę mógł schrupać Dane i zaktualizować kolejkę użytkownika, muszę się upewnić, że mam najbardziej aktualne dane, czyli gdzie przychodzą wywołania API.
Mogę wykonać dwa połączenia:
- Get Followed Users -- który zwraca wszystkich użytkowników obserwowanych przez żądanego użytkownika i
- Get Favorite Items -- który zwraca wszystkie ulubione przedmioty żądany użytkownik.
Po wywołaniu get followed users aby użytkownik był aktualizowany, muszę zaktualizować ulubione elementy dla każdego obserwowanego użytkownika. Tylko wtedy, gdy wszystkie ulubione zostaną zwrócone dla wszystkich obserwowanych użytkowników, mogę rozpocząć przetwarzanie kolejki dla tego oryginalnego użytkownika. Przepływ ten wygląda następująco:
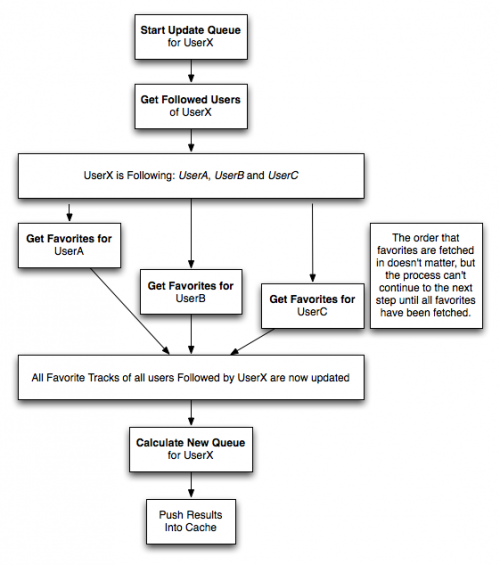
Jobs in this flow include:
- rozpocznij aktualizację kolejki dla usera -- uruchamia proces, pobierając użytkowników następnie użytkownik jest aktualizowany, przechowuje je, a następnie tworzy Get Favorites zadania dla każdego użytkownika.
- Get Favorites for user -- Requests, and stores, a list of favorites for the specified user, from the 3rd party service.
- Oblicz nową kolejkę dla użytkownika -- przetwarza nową kolejkę, teraz, gdy wszystkie dane zostały pobrane, a następnie przechowuje wyniki w buforze, który jest używany przez warstwę aplikacji.
Więc znowu moje pytania są:
- czy jest to przepływ, który dobrze nadaje się do równoległego porównywania z MapReduce? Nie wiem, czy to pozwoli mi rozpocząć proces dla UserX, pobrać wszystkie powiązane dane, i wrócić do przetwarzania kolejki UserX dopiero po tym wszystkim.
- Jeśli tak , czy byłoby to opłacalne, aby uruchomić na module mapreduce Amazona, który rachunki przez godzinę, a rounds godzina kończy się, gdy zadanie jest zakończone? Czy istnieje limit na ile" wątków " mogę czekać na open API prośby, Jeśli używam ich modułu?
- Jeśli Nie , czy jest inny system / wzór, którego powinienem użyć? i czy jest jakaś biblioteka, która pomoże mi to zrobić w Pythonie (na AWS, usign EC2 + EBS?)? Widzisz jakieś problemy ze sposobem, w jaki zaprojektowałem tę pracę?
Dzięki za przeczytanie, czekam na jakąś dyskusję z wami wszystkimi.
Edit , w odpowiedzi dla JimR:
Dzięki za solidną odpowiedź. W mojej lekturze odkąd napisałem oryginalne pytanie, odchyliłem się od korzystania z MapReduce. Nie zdecydowałem jeszcze na pewno, jak chcę to zbudować, ale zaczynam czuć, że MapReduce jest lepszy do dystrybucji / równoległego ładowania obliczeniowego, kiedy naprawdę Szukam równoległego żądania HTTP.
To, co byłoby moim zadaniem "reduce", część, która pobiera wszystkie pobrane dane i przetwarza je w wyniki, nie jest tak intensywne obliczeniowo. Jestem pewien, że skończy się to jednym wielkim zapytaniem SQL, które wykonuje na sekundę lub dwie na użytkownika.
Więc to, do czego się skłaniam, to:
- a non-MapReduce Job / Worker model, napisany w Python. Mój znajomy z google zwrócił mnie na naukę Pythona, ponieważ jest niski narzut i dobrze skaluje.
- używanie Amazon EC2 jako warstwy obliczeniowej. Myślę, że to oznacza, że potrzebuję również kawałek EBS do przechowywania mojej bazy danych.
- prawdopodobnie używając prostej kolejki komunikatów Amazona. To brzmi jak ta trzecia Amazonka widżet jest przeznaczony do śledzenia kolejek zadań, przenoszenia wyników z jednego zadania do danych wejściowych innego i z wdziękiem obsługuje nieudane zadania. Jest bardzo tani. Może warto zaimplementować zamiast niestandardowego systemu kolejki zadań.
3 answers
Praca, którą opisujesz, prawdopodobnie pasuje do kolejki lub kombinacji kolejki i serwera zadań. Z pewnością może również działać jako zestaw kroków MapReduce.
[[3]}dla serwera pracy, polecam spojrzeć na Gearman. Dokumentacja nie jest niesamowita, ale prezentacje wykonują świetną robotę, dokumentując ją, a moduł Pythona jest dość oczywisty.Zasadniczo tworzysz funkcje na serwerze zadań, a te funkcje są wywoływane przez klientów za pośrednictwem API. Funkcje mogą być wywoływane synchronicznie lub asynchronicznie. W twoim przykładzie prawdopodobnie chcesz asynchronicznie dodać zadanie "rozpocznij aktualizację". To wykona wszelkie zadania przygotowawcze, a następnie asynchronicznie wywoła zadanie "śledź użytkowników". To zadanie pobierze użytkowników, a następnie wywoła zadanie "Uaktualnij użytkowników". To prześle wszystkie" Get favorites for UserA " i friend jobs razem za jednym zamachem i synchronicznie czekać na wynik wszystkich z nich. Gdy mają wszystkie zwrócone, wywoła zadanie "Oblicz nową kolejkę".
To podejście tylko do pracy na serwerze będzie początkowo nieco mniej wytrzymałe, ponieważ upewnienie się, że poprawnie radzisz sobie z błędami i wszelkimi serwerami w dół i wytrwałością będzie zabawne.
Dla kolejki, SQS jest oczywistym wyborem. Jest solidny jak skała, bardzo szybki dostęp z EC2 i tani. I o wiele łatwiejsze do skonfigurowania i utrzymania niż inne kolejki, gdy dopiero zaczynasz.
Zasadniczo umieścisz wiadomość na Kolejka, podobnie jak byś przesłał zadanie na powyższy serwer zadań, tyle że prawdopodobnie nic nie zrobisz synchronicznie. Zamiast synchronicznie wywoływać" Get favorites For UserA " i tak dalej, zrobisz je asynchronicznie, a następnie otrzymasz komunikat, który mówi, aby sprawdzić, czy wszystkie z nich zostały zakończone. Będziesz potrzebował pewnego rodzaju wytrwałości (znanej Ci bazy danych SQL lub SimpleDB Amazona, jeśli chcesz przejść w pełni AWS), aby śledzić, czy praca jest wykonana - nie możesz sprawdzić na postęp pracy w SQS (chociaż można w innych kolejkach). Komunikat, który sprawdzi, czy wszystkie są skończone, wykona sprawdzenie - jeśli nie wszystkie są skończone, nic nie rób, a następnie wiadomość zostanie powtórzona w ciągu kilku minut (na podstawie visibility_timeout). W przeciwnym razie możesz umieścić następną wiadomość w kolejce.
To podejście tylko do kolejki powinno być solidne, zakładając, że nie wykorzystasz wiadomości kolejki przez pomyłkę bez wykonywania pracy. Popełnienie takiego błędu jest trudne do zrób z SQS-naprawdę musisz spróbować. Nie używaj automatycznych kolejek ani protokołów - w przypadku błędu możesz nie być w stanie upewnić się, że umieścisz wiadomość zastępczą z powrotem w kolejce.
Kombinacja kolejki i serwera zadań może być użyteczna w tym przypadku. Możesz uniknąć braku sklepu uporczywości, aby sprawdzić postępy zadań - serwer zadań pozwoli Ci śledzić postępy zadań. Twoja wiadomość "get favorites for users " może umieścić wszystkie zadania" get favorites for UserA/B/C" do serwera pracy. Następnie umieść w kolejce komunikat "sprawdź wszystkie ulubione pobieranie zrobione" z listą zadań, które muszą być ukończone(i wystarczającą ilością informacji, aby ponownie uruchomić wszystkie zadania, które w tajemniczy sposób znikną).
Za punkty bonusowe:
Robienie tego jako MapReduce powinno być dość łatwe.Twoje pierwsze zadanie będzie listą wszystkich Twoich użytkowników. Mapa zabierze każdego użytkownika, pobiera obserwowanych użytkowników i linie wyjściowe dla każdego użytkownika i ich obserwowanych użytkownik:
"UserX" "UserA"
"UserX" "UserB"
"UserX" "UserC"
Krok redukcji tożsamości pozostawi to bez zmian. Będzie to stanowiło wkład drugiego zadania. Mapa dla drugiego zadania otrzyma ulubione dla każdej linii (możesz użyć memcached, aby zapobiec pobieraniu ulubionych dla combo UserX/UserA i UserY / UserA przez API) i wyświetli linię dla każdego ulubionego:
"UserX" "UserA" "Favourite1"
"UserX" "UserA" "Favourite2"
"UserX" "UserA" "Favourite3"
"UserX" "UserB" "Favourite4"
Krok reduce dla tego zadania przekonwertuje to na:
"UserX" [("UserA", "Favourite1"), ("UserA", "Favourite2"), ("UserA", "Favourite3"), ("UserB", "Favourite4")]
W tym momencie możesz mieć inne zadanie MapReduce, aby zaktualizować swoją bazę danych dla każdego użytkownika z tymi wartościami, lub może być w stanie użyć niektórych narzędzi związanych z Hadoop, takich jak Pig, Hive i HBase do zarządzania Bazą Danych dla Ciebie.
Zalecałbym użycie dystrybucji Cloudera dla poleceń zarządzających Hadoop EC2 do tworzenia i niszczenia klastra Hadoop na EC2 (ich ami mają skonfigurowany Python), i użyć czegoś takiego jak Dumbo (na PyPI) do tworzenia zadań MapReduce, ponieważ pozwala to przetestować zadania MapReduce na lokalnej/dev maszynie bez dostępu do komputera. Hadoop.
Powodzenia!Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-12-11 09:41:50
Wygląda na to, że wybieramy węzeł.js i SEQ biblioteka sterowania przepływem. Bardzo łatwo było przejść z mojej mapy / schematu blokowego procesu do stubuu kodu, a teraz jest to tylko kwestia wypełnienia kodu, aby podłączyć się do właściwych interfejsów API.
Dzięki za odpowiedzi, bardzo pomogły w znalezieniu rozwiązania, którego szukałem.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-01-19 19:10:11
Pracuję z podobnym problemem, który muszę rozwiązać. Patrzyłem również na MapReduce i korzystałem z usługi Elastic MapReduce od Amazon.
Jestem przekonany, że MapReduce zadziała na ten problem. Realizacja jest tam, gdzie się rozłączam, bo nie jestem pewien, czy mój reduktor w ogóle musi coś zrobić.
Odpowiem na twoje pytania, ponieważ rozumiem twój (i mój) problem i mam nadzieję, że pomoże.
Tak, myślę, że będzie dobrze pasować. Ty można spojrzeć na wykorzystanie opcji wielu kroków usługi Elastic MapReduce. Możesz użyć 1 kroku, aby pobrać osoby, które śledzi użytkownik, i kolejny krok, aby skompilować listę utworów dla każdego z tych obserwujących, a reduktor dla tego 2. kroku prawdopodobnie będzie tym, który zbuduje pamięć podręczną.
Zależy od rozmiaru zestawu danych i częstotliwości jego uruchamiania. Trudno powiedzieć, nie wiedząc, jak duży zestaw danych jest (lub dostanie), czy będzie opłacalny albo i nie. Początkowo prawdopodobnie będzie to dość opłacalne, ponieważ nie będziesz musiał zarządzać własnym klastrem hadoop ani płacić za instancje EC2 (zakładając, że tego używasz), aby być cały czas aktywnym. Gdy dojdziesz do punktu, w którym faktycznie przetwarzasz te dane przez długi okres czasu, prawdopodobnie będzie coraz mniej sensu korzystanie z usługi MapReduce Amazon, ponieważ będziesz stale mieć węzły online przez cały czas.
Zadanie jest w zasadzie Twoim zadaniem MapReduce. Informatyka może składać się z wielu kroków (każde zadanie MapReduce jest krokiem). Po przetworzeniu danych i wykonaniu wszystkich kroków Twoje zadanie zostanie wykonane. Efektywnie płacisz za czas procesora dla każdego węzła w klastrze Hadoop. tak więc T * n, gdzie T to czas (w godzinach) potrzebny do przetworzenia danych, a n to liczba węzłów, które każesz Amazonowi rozkręcić.
Mam nadzieję, że to pomoże, powodzenia. Chciałbym usłyszeć, jak kończysz wdrażanie swoich maperów i reduktorów, ponieważ rozwiązuję bardzo podobny problem i nie jestem pewien, czy moje podejście jest naprawdę najlepsze.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-12-02 04:03:53