Dlaczego std:: fill(0) jest wolniejsze od std::fill (1)?
Zaobserwowałem na układzie, który {[1] } na dużym std::vector<int> był znacząco i konsekwentnie wolniejszy przy ustawianiu stałej wartości 0 w porównaniu do stałej wartości 1 lub wartości dynamicznej:
5.8 GiB / s vs 7.5 GiB / s
Jednak wyniki są różne dla mniejszych rozmiarów danych, gdzie {[5] } jest szybszy:
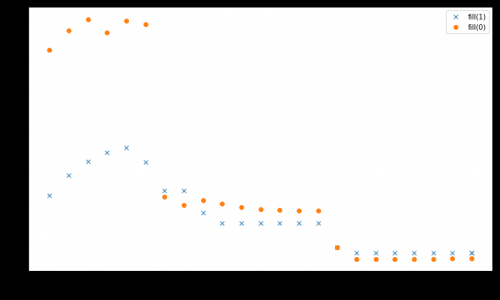
Z więcej niż jednym wątkiem, przy wielkości danych 4 GiB, fill(1) pokazuje wyższe nachylenie, ale osiąga znacznie niższy szczyt niż fill(0) (51 GiB/s vs 90 GiB/s):

fill(1) jest o wiele niższe.
Procesor Intel Xeon E5-2680 V3 z podwójnym gniazdem 2,5 GHz (via /sys/cpufreq) z 8x16 GiB DDR4-2133. Testowałem z GCC 6.1.0 (-O3) i Intel compiler 17.0.1 (-fast), oba uzyskać identyczne wyniki. GOMP_CPU_AFFINITY=0,12,1,13,2,14,3,15,4,16,5,17,6,18,7,19,8,20,9,21,10,22,11,23 został ustawiony. Strem/add / 24 threads pobiera 85 GiB / s w systemie.
Udało mi się odtworzyć efekt ten ma wpływ na inny system serwerów Haswell dual socket, ale nie na żadną inną architekturę. Na przykład w Sandy Bridge EP wydajność pamięci jest identyczna, podczas gdy w pamięci podręcznej fill(0) jest znacznie szybsza.
Oto kod do odtworzenia:
#include <algorithm>
#include <cstdlib>
#include <iostream>
#include <omp.h>
#include <vector>
using value = int;
using vector = std::vector<value>;
constexpr size_t write_size = 8ll * 1024 * 1024 * 1024;
constexpr size_t max_data_size = 4ll * 1024 * 1024 * 1024;
void __attribute__((noinline)) fill0(vector& v) {
std::fill(v.begin(), v.end(), 0);
}
void __attribute__((noinline)) fill1(vector& v) {
std::fill(v.begin(), v.end(), 1);
}
void bench(size_t data_size, int nthreads) {
#pragma omp parallel num_threads(nthreads)
{
vector v(data_size / (sizeof(value) * nthreads));
auto repeat = write_size / data_size;
#pragma omp barrier
auto t0 = omp_get_wtime();
for (auto r = 0; r < repeat; r++)
fill0(v);
#pragma omp barrier
auto t1 = omp_get_wtime();
for (auto r = 0; r < repeat; r++)
fill1(v);
#pragma omp barrier
auto t2 = omp_get_wtime();
#pragma omp master
std::cout << data_size << ", " << nthreads << ", " << write_size / (t1 - t0) << ", "
<< write_size / (t2 - t1) << "\n";
}
}
int main(int argc, const char* argv[]) {
std::cout << "size,nthreads,fill0,fill1\n";
for (size_t bytes = 1024; bytes <= max_data_size; bytes *= 2) {
bench(bytes, 1);
}
for (size_t bytes = 1024; bytes <= max_data_size; bytes *= 2) {
bench(bytes, omp_get_max_threads());
}
for (int nthreads = 1; nthreads <= omp_get_max_threads(); nthreads++) {
bench(max_data_size, nthreads);
}
}
Przedstawiono wyniki zestawione z g++ fillbench.cpp -O3 -o fillbench_gcc -fopenmp.
2 answers
Z twojego pytania + kompilator-wygenerowany asm z twojej odpowiedzi:
-
fill(0)jest ERMSBrep stosbktóry będzie używał sklepów 256b w zoptymalizowanej mikrokodowanej pętli. (Działa najlepiej, jeśli bufor jest wyrównany, prawdopodobnie do co najmniej 32B lub może 64B). -
fill(1)jest prostą 128-bitową pętląmovapswektorową. Tylko jeden magazyn może wykonać jeden cykl zegara rdzenia, niezależnie od szerokości, do 256B AVX. Tak więc sklepy 128b mogą wypełnić tylko połowę zapisu pamięci podręcznej L1D Haswella przepustowość. dlategofill(0)jest około 2x szybszy dla buforów do ~32kib. Skompiluj z-march=haswelllub-march=native, aby to naprawić .Haswell ledwo nadąża za pętlą, ale nadal może uruchomić 1 sklep na zegar, nawet jeśli nie jest rozwijany. Ale z 4 zespolonymi domenami uops na zegar, to dużo wypełniacza zajmującego miejsce w oknie poza zamówieniem. Niektóre rozwinięcia mogą pozwolić TLB misses zacząć rozwiązywać dalej przed tym, gdzie dzieje się sklepy, ponieważ jest większa przepustowość dla UOP adresów magazynowych niż dla danych magazynowych. Rozwinięcie może pomóc uzupełnić resztę różnicy między ERMSB a tą pętlą wektorową dla buforów mieszczących się w L1D. (komentarz do pytania mówi, że
-march=nativepomógł tylkofill(1)dla L1.)
Zauważ, że rep movsd (które mogą być użyte do implementacji fill(1) dla int elementów) prawdopodobnie będzie działać tak samo jak rep stosb Na Haswell.
Chociaż tylko oficjalna dokumentacja gwarantuje, że ermsb daje szybkie rep stosb (ale nie rep stosd), rzeczywiste Procesory obsługujące ERMSB wykorzystują podobnie wydajne mikrokody dla rep stosd. Istnieją pewne wątpliwości co do IvyBridge, gdzie może tylko b jest szybki. Zobacz @ BeeOnRope ' s excellent ERMSB odpowiedź dla aktualizacji na ten temat.
Gcc ma kilka opcji strojenia x86 dla string ops ( Jak -mstringop-strategy=alg i -mmemset-strategy=strategy), ale IDK jeśli któraś z nich będzie mogła emitować rep movsd dla fill(1). Prawdopodobnie nie, ponieważ zakładam, że kod zaczyna się jako pętli, a nie memset.
Fill(1) pokazuje wyższe nachylenie, ale osiąga znacznie niższy szczyt niż fill (0) (51 GiB/s vs 90 GiB/s):]}
Standard movaps store to a cold cache line wyzwala Read For Ownership (RFO). Duża część rzeczywistej przepustowości pamięci DRAM zużywana jest na odczyt linii pamięci podręcznej, gdy movaps zapisuje pierwsze 16 bajtów. Sklepy ERMSB używają protokołu no-RFO dla swoich sklepów, więc kontrolery pamięci tylko zapisują. (Z wyjątkiem różnych odczytów, takich jak tabele stron, jeśli jakiekolwiek spacery po stronach są pomijane nawet w pamięci podręcznej L3, a może niektóre pominięcia ładowania w procedurach obsługi przerwań lub cokolwiek innego).
@BeeOnRope wyjaśnia w komentarzach , że różnica między zwykłymi magazynami RFO a protokołem unikającym RFO używanym przez ERMSB ma wady dla niektórych zakresów rozmiarów buforów na procesorach serwerowych, gdzie występuje duże opóźnienie w pamięci podręcznej uncore/L3. Zobacz też linkowaną odpowiedź ERMSB dla więcej o RFO vs non-RFO, i wysokie opóźnienie uncore (L3 / pamięć) w wielordzeniowych procesorach Intel jest problemem dla przepustowości jednordzeniowej.
movntps (_mm_stream_ps()) pamięci podręczne są słabo uporządkowane, więc mogą ominąć pamięć podręczną i przejść bezpośrednio do pamięci całej linii pamięci podręcznej na raz, bez czytania linii pamięci podręcznej do L1D. movntps unika RFO, tak jak robi to rep stos. (rep stos sklepy mogą zmieniać kolejność ze sobą, ale nie poza granicami Instrukcja.)
Twoje movntps wyniki w zaktualizowanej odpowiedzi są zaskakujące.
dla pojedynczego wątku z dużymi buforami wyniki są movnt >> zwykłe RFO > ERMSB. To naprawdę dziwne, że dwie metody nie-RFO są po przeciwnych stronach zwykłych starych sklepów, a ERMSB jest tak daleko od optymalnego. Obecnie nie mam na to wytłumaczenia. (edycje mile widziane z wyjaśnieniem + dobre dowody).
Zgodnie z oczekiwaniami, movnt pozwala wielu wątkom na osiągnij wysoką przepustowość magazynu agregatów, jak ERMSB. movnt zawsze przechodzi prosto do buforów wypełniania linii, a następnie do pamięci, więc jest znacznie wolniejszy dla rozmiarów buforów, które mieszczą się w buforze. Jeden wektor 128b na zegar wystarczy, aby łatwo nasycić przepustowość pojedynczego rdzenia bez RFO do pamięci DRAM. Prawdopodobnie vmovntps ymm (256b) jest tylko wymierną przewagą nad vmovntps xmm (128b) podczas przechowywania wyników wektoryzowanych obliczeń związanych z procesorem AVX 256B (tzn. tylko wtedy, gdy oszczędza kłopot z rozpakowaniem do 128b).
movnti przepustowość jest niska, ponieważ Przechowywanie w kawałkach 4B powoduje wąskie gardła na 1 store UOP na zegar dodawanie danych do buforów wypełniania linii, a nie wysyłanie tych buforów wypełniania linii do pamięci DRAM(dopóki nie masz wystarczającej ilości wątków, aby nasycić przepustowość pamięci).
@osgx dodał kilka ciekawych linków w komentarzach :
- Agner Fog ' s ASM optimization guide, instruction tables, and microarch guide: http://agner.org/optimize /
Intel optimization guide: http://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-optimization-manual.pdf.
NUMA snooping: http://frankdenneman.nl/2016/07/11/numa-deep-dive-part-3-cache-coherency/
- https://software.intel.com/en-us/articles/intelr-memory-latency-checker
- Cache Coherence Protocol i Pamięć Wydajność architektury Intel Haswell-EP
Zobacz także inne rzeczy w x86 tag wiki.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-07-17 20:12:41
Podzielę się moimi wstępnymi ustaleniami, w nadziei zachęcić do bardziej szczegółowych odpowiedzi. Po prostu czułem, że to zbyt wiele w ramach samego pytania.
Kompilator optymalizuje fill(0) do wewnętrznego memset. Nie może zrobić tego samego dla fill(1), ponieważ memset działa tylko na bajtach.
W szczególności, zarówno glibc __memset_avx2, jak i __intel_avx_rep_memset są zaimplementowane za pomocą pojedynczej instrukcji hot:
rep stos %al,%es:(%rdi)
Gdzie ręczna pętla kompiluje się do rzeczywistego Instrukcja 128-bitowa:
add $0x1,%rax
add $0x10,%rdx
movaps %xmm0,-0x10(%rdx)
cmp %rax,%r8
ja 400f41
Co ciekawe istnieje optymalizacja szablonu / nagłówka do zaimplementowania std::fill poprzez memset dla typów bajtów, ale w tym przypadku jest to optymalizacja kompilatora do przekształcenia rzeczywistej pętli.
O dziwo, dla std::vector<char>, gcc zaczyna optymalizować również fill(1). Kompilator Intela nie, pomimo specyfikacji szablonu memset.
Ponieważ dzieje się tak tylko wtedy, gdy kod faktycznie działa w pamięci, a nie w pamięci podręcznej, sprawia, że wygląda to na architekturę Haswell-EP nie udaje się skutecznie skonsolidować zapisów pojedynczych bajtów.
Byłbym wdzięczny za wszelkie dalsze wglądy W problem i związane z nim szczegóły mikroarchitektury. W szczególności nie jest dla mnie jasne, dlaczego to zachowuje się tak inaczej dla czterech lub więcej wątków i dlaczego memset jest tak szybszy w pamięci podręcznej.
Aktualizacja:
Oto wynik w porównaniu z
- fill(1) który używa
-march=native(avx2vmovdq %ymm0) - Działa Lepiej W L1, ale podobnie domovaps %xmm0wersja dla innych poziomów pamięci. - warianty 32, 128 i 256 bitowych nie-czasowych sklepów. Działają one konsekwentnie z tą samą wydajnością niezależnie od wielkości danych. Wszystkie inne warianty w pamięci, szczególnie dla małej liczby wątków. 128 bit i 256 bit działają dokładnie podobnie, dla małej liczby wątków 32 bit wykonuje się znacznie gorzej.
Dla vmovnt mA 2x przewagę nad rep stos podczas pracy w pamięć.
Przepustowość pojedynczego gwintu:

Łączna przepustowość w pamięci:

Oto kod używany do dodatkowych testów z odpowiednimi hot-loopami:
void __attribute__ ((noinline)) fill1(vector& v) {
std::fill(v.begin(), v.end(), 1);
}
┌─→add $0x1,%rax
│ vmovdq %ymm0,(%rdx)
│ add $0x20,%rdx
│ cmp %rdi,%rax
└──jb e0
void __attribute__ ((noinline)) fill1_nt_si32(vector& v) {
for (auto& elem : v) {
_mm_stream_si32(&elem, 1);
}
}
┌─→movnti %ecx,(%rax)
│ add $0x4,%rax
│ cmp %rdx,%rax
└──jne 18
void __attribute__ ((noinline)) fill1_nt_si128(vector& v) {
assert((long)v.data() % 32 == 0); // alignment
const __m128i buf = _mm_set1_epi32(1);
size_t i;
int* data;
int* end4 = &v[v.size() - (v.size() % 4)];
int* end = &v[v.size()];
for (data = v.data(); data < end4; data += 4) {
_mm_stream_si128((__m128i*)data, buf);
}
for (; data < end; data++) {
*data = 1;
}
}
┌─→vmovnt %xmm0,(%rdx)
│ add $0x10,%rdx
│ cmp %rcx,%rdx
└──jb 40
void __attribute__ ((noinline)) fill1_nt_si256(vector& v) {
assert((long)v.data() % 32 == 0); // alignment
const __m256i buf = _mm256_set1_epi32(1);
size_t i;
int* data;
int* end8 = &v[v.size() - (v.size() % 8)];
int* end = &v[v.size()];
for (data = v.data(); data < end8; data += 8) {
_mm256_stream_si256((__m256i*)data, buf);
}
for (; data < end; data++) {
*data = 1;
}
}
┌─→vmovnt %ymm0,(%rdx)
│ add $0x20,%rdx
│ cmp %rcx,%rdx
└──jb 40
Uwaga: musiałem wykonać ręczne obliczenia wskaźnika, aby pętle były tak kompaktowe. W przeciwnym razie wykonywałby indeksowanie wektorowe w pętli, prawdopodobnie z powodu wewnętrznego zamieszania optymalizatora.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-07-11 14:01:02