Czy bazy danych OLAP powinny być denormalizowane pod kątem wydajności odczytu?
Zawsze uważałem, że bazy danych powinny być denormalizowane dla wydajności odczytu, tak jak to się robi w przypadku projektowania baz danych OLAP, a nie przesadzać znacznie dalej 3NF dla projektowania OLTP.
Wykonywany w różnych postach, dla ex., w Wydajność różnych aproksymacji do danych opartych na czasie Broni paradygmatu, że baza danych powinna być zawsze dobrze zaprojektowana przez normalizację do 5NF i 6NF (postać normalna).
Czy dobrze zrozumiałem (i co właściwie zrozumiałem)?
Co jest nie tak z tradycyjnym podejściem denormalizacyjnym / paradygmatem projektowania baz danych OLAP (poniżej 3NF) i radą, że 3NF wystarcza dla większości praktycznych przypadków baz danych OLTP?
Na przykład:
Muszę przyznać, że nigdy nie mogłem pojąć teorii, że denormalizacja ułatwia odczyt. Czy ktoś może mi dać odniesienia z dobrymi logicznymi wyjaśnieniami tego i przeciwnych przekonań?
Jakie są źródła, do których mogę się odwoływać, próbując przekonać interesariuszy, że bazy danych OLAP / hurtowni danych powinny być znormalizowane?
Aby poprawić widoczność skopiowałem tutaj z Komentarzy:
" byłoby miło, gdyby uczestnicy Dodaj (a) ile realnych (nie wśród projektów naukowych znalazły się) wdrożenia hurtowni danych w 6NF widzieli lub uczestniczyli do środka. Coś w rodzaju szybkiego basenu. Ja = 0."- Damir Sudarevic
Artykuł hurtowni danych Wikipedii mówi:
" znormalizowane podejście [vs. dimensional one by Ralph Kimball], także nazywany modelem 3NF (trzecia postać normalna) , którego zwolennikami są określani jako "Inmonici", wierzą w podejście Billa Inmona, w którym stwierdza się, że hurtownia danych powinna być modelowana za pomocą E-R model / model znormalizowany."
Wygląda na to, że znormalizowane podejście do hurtowni danych (Bill Inmon) jest postrzegane jako nie przekraczające 3NF (?)
Chcę tylko zrozumieć, jakie jest pochodzenie mitu (lub wszechobecnego aksjomatycznego przekonania), że hurtownia danych/OLAP jest synonimem denormalizacji?
Damir Sudarevic odpowiedział, że są dobrze wybrukowane podejście. Powrócę do pytania: dlaczego uważa się, że denormalizacja ułatwia czytanie?
9 answers
Mitologia
zawsze uważałem, że bazy danych powinny być denormalizowane do czytania, tak jak to się robi w przypadku projektowania baz danych OLAP, a nie przesadzać znacznie dalej 3NF do projektowania OLTP.
Istnieje mit na ten temat. W kontekście relacyjnej bazy danych ponownie zaimplementowałem sześć bardzo dużych tzw." de-normalizowanych ""baz danych"; i wykonałem ponad osiemdziesiąt zadań poprawiających problemy na innych, po prostu normalizując je, stosując standardy i zasady inżynierii. Nigdy nie widziałem żadnych dowodów na istnienie mitu. Tylko ludzie powtarzają mantrę, jakby była to jakaś magiczna modlitwa.
Normalizacja vs unormalizacja
("De-normalizacja" to nieuczciwe określenie, którego nie używam.)
Jest to przemysł naukowy (przynajmniej ten bit, który dostarcza oprogramowanie, które nie pęka; który umieszcza ludzi na księżycu; który uruchamia systemy bankowe itp.). Rządzi się prawami fizyki, nie magii. Komputery a oprogramowanie to wszystkie skończone, namacalne, fizyczne obiekty, które podlegają prawom fizyki. Zgodnie z wykształceniem średnim i wyższym, które otrzymałem:
Nie jest możliwe, aby większy, grubszy, mniej zorganizowany obiekt działał lepiej niż mniejszy, cieńszy, bardziej zorganizowany obiekt.
Normalizacja daje więcej tabel, tak, ale każda tabela jest znacznie mniejsza. I chociaż jest więcej tabel, w rzeczywistości jest (a) mniej złączeń i (b) złączeń są szybsze, ponieważ zestawy są mniejsze. Ogólnie potrzeba mniej indeksów, ponieważ każda mniejsza tabela potrzebuje mniej indeksów. Znormalizowane tabele dają również znacznie krótsze rozmiary wierszy.
-
Dla dowolnego zbioru zasobów, tabele znormalizowane:
- Dopasuj więcej wierszy do tego samego rozmiaru strony W ten sposób można dopasować więcej wierszy do tej samej przestrzeni pamięci podręcznej, co zwiększa ogólną przepustowość)
- dlatego zmieścić więcej wierszy w tej samej przestrzeni dyskowej, dlatego nie I/O jest zmniejszona; a gdy wymagane jest i / O, każde I / O jest bardziej wydajne.
.
Ogólny wynik był więc znacznie, znacznie wyższą wydajnością.
Z mojego doświadczenia, które dostarcza zarówno OLTP, jak i OLAP z tej samej bazy danych, nigdy nie było potrzeby "de-normalizacji" moich znormalizowanych struktur, aby uzyskać większą prędkość dla zapytań tylko do odczytu (OLAP). To też mit.
- nie, żądana przez innych "de-normalizacja" zmniejszyła prędkość i została wyeliminowana. Nie dziwi mnie to, ale ponownie, prośba była zaskoczony.
Wiele książek zostało napisanych przez ludzi, sprzedających mit. Należy uznać, że są to ludzie nietechniczni; ponieważ sprzedają magię, magia, którą sprzedają, nie ma podstaw naukowych i wygodnie unikają praw fizyki w swojej sprzedaży.
(dla każdego, kto chce zakwestionować powyższą naukę fizyczną, samo powtarzanie mantry nie będzie miało żadnego skutku, prosimy o dostarczenie konkretnych dowodów potwierdzających mantrę.)
Dlaczego czy mit jest rozpowszechniony ?
Cóż, po pierwsze, nie jest to powszechne wśród typów naukowych, którzy nie szukają sposobów przezwyciężenia praw fizyki.
Z mojego doświadczenia, zidentyfikowałem trzy główne przyczyny występowania:
Dla osób, które nie mogą znormalizować swoich danych, jest to wygodne uzasadnienie, aby tego nie robić. Mogą odnosić się do magicznej księgi i bez żadnych dowodów na magię mogą z szacunkiem powiedzieć: "zobacz słynnego pisarza co zrobiłem". Nie zrobione, najdokładniej.
Wiele koderów SQL może pisać tylko prosty, jednopoziomowy SQL. Znormalizowane struktury wymagają trochę możliwości SQL. Jeśli nie mają tego; jeśli nie mogą tworzyć Selektów bez użycia tabel tymczasowych; jeśli nie mogą pisać zapytań podrzędnych, zostaną psychologicznie przyklejone do bioder do płaskich plików( czyli czym są "znormalizowane" struktury), które mogą przetworzyć.
-
Ludzie miłość do czytać książki i dyskutować teorie. Bez doświadczenia. Szczególnie re magic. To jest tonik, substytut prawdziwego doświadczenia. Każdy, kto prawidłowo znormalizował bazę danych, nigdy nie stwierdził, że "znormalizowana jest szybsza niż znormalizowana". Do każdego, kto wypowiada mantrę, po prostu mówię: "Pokaż mi dowody", a oni nigdy nie stworzyli żadnych. Tak więc rzeczywistość jest taka, że ludzie powtarzają mitologię z tych powodów, bez doświadczenia normalizacji . Jesteśmy zwierzętami stadnymi i nieznane jest jednym z naszych największych lęków.
Dlatego zawsze włączam "zaawansowany" SQL i mentoring w każdym projekcie.
Moja Odpowiedź
Ta odpowiedź będzie śmiesznie długa, jeśli odpowiem na każdą część twojego pytania lub jeśli odpowiem na nieprawidłowe elementy w niektórych innych odpowiedziach. Np. na powyższe odpowiedzi udzielono tylko w jednym punkcie. Dlatego odpowiem na twoje pytanie w sumie bez zajmowania się konkretnymi komponentami i wezmę inny podejdźcie. Będę zajmował się tylko nauką związaną z twoim pytaniem, że jestem wykwalifikowany, i bardzo doświadczony.
Pozwól, że przedstawię ci naukę w przystępnych segmentach.
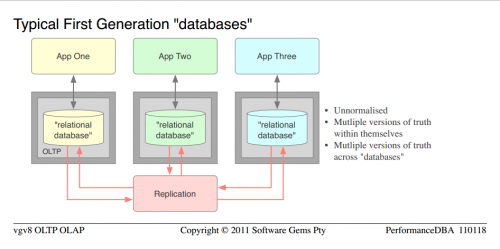
Typowy model sześciu dużych kompleksowych zadań wdrożeniowych.
- Były to zamknięte "bazy danych" powszechnie spotykane w małych firmach, a organizacje były dużymi bankami.]}
- bardzo ładne jak na pierwszą generację, get-the-app-running nastawienie, ale kompletna porażka pod względem wydajności, integralności i jakości Zostały one zaprojektowane dla każdej aplikacji, osobno.]}
- raportowanie nie było możliwe, mogli raportować tylko za pośrednictwem każdej aplikacji
- ponieważ "znormalizowane" to mit, dokładna definicja techniczna jest, były unormalizowane
- aby" de-normalizować", trzeba najpierw normalizować; potem nieco odwrócić proces w każdym przypadku, gdy ludzie pokazywali mi swoje "znormalizowane" modele danych, prostym faktem było, że nie znormalizował się w ogóle, więc "de-normalizacja" nie była możliwa; po prostu nie znormalizowano [24]}
Ponieważ nie miały one zbyt wielu technologii relacyjnych, struktur i kontroli baz danych, ale były przekazywane jako "bazy danych", umieściłem te słowa w cudzysłowie [24]}
- Jak jest naukowo zagwarantowane dla unormowanych struktur, cierpiały one na wiele wersji prawdy (powielanie danych), a tym samym wysoką niezgodność i niską współbieżność, w ramach każdy z nich W 2007 roku firma została założona przez firmę Microsoft, która od 2007 roku zajmuje się dystrybucją i dystrybucją danych.]} Organizacja próbowała zsynchronizować wszystkie duplikaty, więc zaimplementowała replikację, co oczywiście oznaczało dodatkowy serwer; ETL i skrypty synchronizujące miały być rozwijane i utrzymywane itp.]} Nie trzeba dodawać, że synchronizacja nigdy nie była wystarczająca i na zawsze ją zmieniali.]}
- z całą tą niezgodnością i niską przepustowością, nie było problem w ogóle uzasadniający oddzielny serwer dla każdej "bazy danych". To niewiele pomogło.
Rozważaliśmy prawa fizyki i zastosowaliśmy trochę nauki.
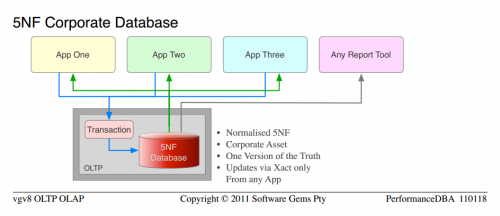
Wdrożyliśmy standardową koncepcję, że dane należą do korporacji (nie działów), a korporacja chciała jednej wersji prawdy. Baza danych była czysto relacyjna, znormalizowana do 5NF. Czysta otwarta architektura, dzięki czemu każda aplikacja lub narzędzie do raportowania może uzyskać do niej dostęp. Wszystkie transakcje w przechowywane proc (w przeciwieństwie do niekontrolowanych ciągów SQL w całej sieci). Ci sami programiści dla każdej aplikacji kodowali nowe aplikacje, po naszej "zaawansowanej" edukacji.
Najwyraźniej nauka zadziałała. Cóż, to nie była moja prywatna nauka czy magia, to była zwykła Inżynieria i prawa fizyki. Wszystko działało na jednej platformie serwerów bazodanowych; dwie pary (produkcja i DR) serwerów zostały zlikwidowane i przekazane innemu działowi. 5" baz danych " o łącznej pojemności 720GB zostało znormalizowanych w jednej bazie danych o łącznej pojemności 450GB. Około 700 tabel (wiele duplikatów i powielonych kolumn) zostało znormalizowanych na 500 tabel nieusuniętych. Działał znacznie szybciej, jak w 10 razy szybciej ogólnie, a ponad 100 razy szybciej w niektórych funkcjach. Nie dziwiło mnie to, ponieważ taki był mój zamiar i nauka to przewidziała, ale zaskoczyło ludzi mantrą.
Więcej Normalizacji
Cóż, po sukcesie normalizacji w każdym projekcie i zaufanie do nauki było naturalnym postępem normalizacji Więcej , nie mniej. W dawnych czasach 3NF był wystarczająco dobry, a później NFs nie zostały jeszcze zidentyfikowane. W ciągu ostatnich 20 lat dostarczałem tylko bazy danych, które nie miały anomalii aktualizacji, więc okazuje się, że do dzisiejszych definicji NFs, zawsze dostarczałem 5NF.
Podobnie, 5NF jest świetny, ale ma swoje ograniczenia. Np. Obracanie dużych tabel (a nie małych zestawów wyników wg rozszerzenia MS PIVOT) było powoli. Tak więc ja (i inni) opracowałem sposób dostarczania znormalizowanych tabel tak, że obracanie było (a) łatwe i (b) bardzo szybkie. Teraz, gdy zdefiniowano 6NF, okazuje się, że te tabele to 6NF.
Ponieważ dostarczam OLAP i OLTP z tej samej bazy danych, odkryłem, że zgodnie z nauką, im bardziej znormalizowane są struktury:
-
Im szybciej wykonują
-
I mogą być używane na więcej sposobów (np. Pivots)
Więc tak, ja mieć spójne i niezmienne doświadczenie, które nie tylko jest znormalizowane znacznie, znacznie szybciej niż unormalizowane lub "znormalizowane"; Więcej znormalizowane jest jeszcze szybsze niż mniej znormalizowane.
Jedną z oznak sukcesu jest wzrost funkcjonalności (oznaką niepowodzenia jest wzrost wielkości bez wzrostu funkcjonalności). Co oznaczało, że natychmiast poprosili nas o więcej funkcji raportowania, co oznaczało, że Znormalizowaliśmy jeszcze więcej i dostarczyliśmy więcej tych specjalistycznych tabel (który po latach okazał się 6NF).
Zawsze byłem specjalistą od baz danych, a nie hurtownią danych, więc moje pierwsze projekty z magazynami nie były pełnowymiarowymi wdrożeniami, ale raczej istotnymi zadaniami dostrajania wydajności. Były w moim ambicie, na produktach, w których się specjalizowałem.
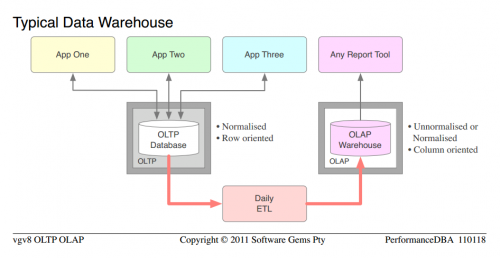
Nie przejmujmy się dokładnym poziomem normalizacji itp., bo przyglądamy się typowemu Przypadkowi. Możemy przyjąć to jak podano że baza danych OLTP była w miarę znormalizowana, ale nie była zdolna do OLAP, a organizacja zakupiła całkowicie oddzielną platformę OLAP, sprzęt; zainwestowała w rozwój i utrzymanie masy kodu ETL itp. A po wdrożeniu spędzili połowę życia zarządzając stworzonymi duplikatami. Tutaj winni są autorzy książek i sprzedawcy, za ogromne marnotrawstwo sprzętu i oddzielnych licencji na oprogramowanie platformowe, które powodują, że organizacje zakup.
- Jeśli jeszcze tego nie zauważyłeś, proszę Cię o zauważenie podobieństw między typową "bazą danych" pierwszej generacji i typową hurtownią danych
Tymczasem na farmie (bazy danych 5NF powyżej) po prostu dodawaliśmy coraz więcej funkcjonalności OLAP. Oczywiście funkcjonalność aplikacji wzrosła, ale to było niewiele, biznes się nie zmienił. Prosiliby o więcej 6NF i było łatwo zapewnić (5NF do 6NF jest mały krok; 0NF do czegokolwiek, nie mówiąc już o 5NF, to duży krok; zorganizowana architektura jest łatwa do rozszerzenia).
Jedną z głównych różnic między OLTP i OLAP, podstawowym uzasadnieniem oddzielnego oprogramowania platformy OLAP, jest to, że OLTP jest zorientowany na wiersze, potrzebuje bezpiecznych transakcyjnie wierszy i szybko; a OLAP nie dba o kwestie transakcyjne, potrzebuje kolumn i szybko. Dlatego wszystkie wysokiej klasy platformy BI lub OLAP są zorientowane kolumnowo, a to dlaczego modele OLAP (Schemat Gwiazdy, wymiar-fakt) są zorientowane kolumnowo.Ale z tabelami 6NF:
-
Nie ma wierszy, tylko kolumny; podajemy wiersze i kolumny z tą samą prędkością Oślepiania
Tabele (tj. widok 5NF struktur 6NF) są już zorganizowane w wymiar-fakty. W rzeczywistości są one zorganizowane w więcej wymiarów niż jakikolwiek model OLAP mógłby kiedykolwiek zidentyfikować, ponieważ są wszystkie Wymiary.
Obracanie całych tabel z agregacją w locie (w przeciwieństwie do obracania niewielkiej liczby kolumn pochodnych) jest (a) łatwe, proste i (b) bardzo szybkie
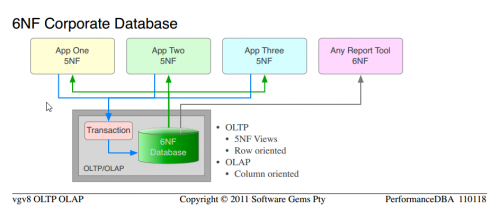
To, co dostarczamy od wielu lat, z definicji, to relacyjne bazy danych z co najmniej 5NF dla zastosowań OLTP i 6NF dla wymagań OLAP.
Zauważ, że jest to ta sama nauka, której używaliśmy od samego początku; aby przejść od typowy unormalized "database" to 5NF Corporate Database . Po prostu stosujemy Więcej sprawdzonej nauki i uzyskujemy wyższe porządki funkcjonalności i wydajności.
Zauważ podobieństwo pomiędzy 5NF Corporate Database i 6NF Corporate Database
Całkowity koszt oddzielnego sprzętu OLAP, oprogramowania platformy, ETL, administracji, konserwacji są wyeliminowane.
-
Jest tylko jeden Wersja danych, bez anomalii aktualizacyjnych lub ich utrzymania; te same dane służyły OLTP jako wiersze, a dla OLAP jako kolumny
Jedyną rzeczą, której nie zrobiliśmy, jest rozpoczęcie nowego projektu i zadeklarowanie czystego 6NF od początku. To jest to, co mam ustawione obok.
Co To jest szósta normalna forma ?
Zakładając, że masz pojęcie o normalizacji (Nie będę jej tutaj definiował), definicje nieakademickie istotne dla tego wątku są jak / align = "left" / Zauważ, że ma ona zastosowanie na poziomie tabeli, dlatego możesz mieć mieszankę tabel 5NF i 6NF w tej samej bazie danych:
-
piąta postać normalna : Wszystkie zależności funkcjonalne rozwiązane w bazie danych
- oprócz 4NF / BCNF
- każda kolumna nie-PK jest 1:: 1 z jej PK
- i do żadnego innego PK
- Brak Anomalii Aktualizacji
.
-
szósta postać normalna : jest nieredukowalnym NF, punktem, w którym dane nie można dalej obniżać ani znormalizować (nie będzie 7NF)
- oprócz 5NF Wiersz składa się z klucza głównego i co najwyżej z jednej kolumny bez klucza
- eliminuje problem Null
Jak wygląda 6NF ?
Modele danych należą do klientów, a nasza własność intelektualna nie jest dostępna do bezpłatnej publikacji. Ale uczęszczam na tę stronę internetową i udzielam konkretnych odpowiedzi na pytania. Potrzebujesz przykład z prawdziwego świata, więc opublikuję model danych dla jednego z naszych narzędzi wewnętrznych.
Ten służy do zbierania danych monitorujących serwer (serwer bazy danych klasy korporacyjnej i system operacyjny) dla dowolnej liczby klientów, przez dowolny okres. Używamy tego do zdalnej analizy problemów z wydajnością i weryfikacji wszelkich modyfikacji wydajności, które wykonujemy. Struktura nie zmieniła się od ponad dziesięciu lat (dodana, bez zmian do istniejących struktur), jest to typowe dla wyspecjalizowanych 5NF, że wiele rok później został zidentyfikowany jako 6NF. Pozwala na pełne obracanie; dowolny wykres lub wykres być rysowane, na dowolnym wymiarze( 22 obrotu są przewidziane, ale to nie jest limit); plaster i kości; mix i mecz. Zauważ, że są Wszystkie Wymiary.
Dane monitorujące lub metryki lub wektory mogą się zmieniać (zmiany wersji serwera; chcemy podnieść coś więcej) bez wpływu na model (możesz przypomnieć sobie w innym poście stwierdziłem, że EAV jest bękartem 6NF; cóż, jest to pełny 6NF, nierozcieńczony ojciec, a zatem zapewnia wszystkie cechy EAV, nie poświęcając żadnych standardów, integralności czy władzy relacyjnej); ty tylko dodajesz wiersze.
▶Model Danych Statystycznych Monitora◀. (za duży dla inline; niektóre przeglądarki nie mogą załadować inline; kliknij link)
Pozwala mi produkować te ▶ / align = "left" / ◀, sześć naciśnięć klawiszy po otrzymaniu surowego pliku statystyk monitorowania od klienta. Zwróć uwagę na mix-and-match; OS i serwer na tym samym wykresy; różne Pivoty. (Użyte za zgodą.)
Czytelnicy, którzy nie znają standardu modelowania relacyjnych baz danych, mogą znaleźć ▶IDEF1X◀ pomocne.
6NF Data Warehouse
Zostało to ostatnio potwierdzone przez Anchor Modeling, ponieważ obecnie prezentują 6NF jako model OLAP "nowej generacji" dla hurtowni danych. (Nie dostarczają OLTP i OLAP z pojedynczej wersji danych, to tylko nasze).
Doświadczenie W Hurtowni Danych (Tylko)
Moje doświadczenie z hurtowniami danych (nie z powyższymi bazami 6NF OLTP-OLAP), było kilka dużych zadań, w przeciwieństwie do pełnych projektów wdrożeniowych. Wyniki były, nic dziwnego:
Zgodnie z nauką, znormalizowane struktury działają znacznie szybciej, są łatwiejsze w utrzymaniu i wymagają mniejszej synchronizacji danych. Inmon, Nie Kimball.
Zgodne z magią, po normalizacji kilku stołów i zapewnieniu znacznie lepszej wydajności poprzez zastosowanie praw fizyki, jedynymi ludźmi zaskoczonymi są magowie z ich mantrami.
Poprawne Uzasadnienie Hurtowni Danych
Dlatego w innych postach pisałem, że jedynym poprawne uzasadnienie dla oddzielnej Platformy Hurtowni Danych, sprzętu, ETL, konserwacji itp. Jest tam, gdzie istnieje wiele baz danych lub "baz danych", wszystkie są scalane w magazyn centralny, do raportowania i OLAP.
Kimball
[[0]}słowo o Kimballu jest konieczne, ponieważ jest on głównym zwolennikiem "znormalizowanej wydajności" w hurtowniach danych. Zgodnie z moimi powyższymi definicjami, jest on jednym z tych ludzi, którzy najwyraźniej nigdy nie znormalizowali się w swoim życiu; jego punkt wyjścia był unormalizowany (zakamuflowany jako "deormalizowany") i po prostu zaimplementował to w modelu wymiarowo-faktycznym.-
Oczywiście, aby uzyskać jakikolwiek występ, musiał jeszcze bardziej "de-normalizować", tworzyć kolejne duplikaty i uzasadniać to wszystko.
Tak więc prawdą jest, w schizofreniczny sposób, że "de-normalizacja" unormowanych struktur, poprzez tworzenie bardziej wyspecjalizowanych kopii, "poprawia wydajność odczytu". Nie jest prawdą, gdy całość jest brana pod uwagę; to prawda tylko w tym małym azylu, nie na zewnątrz.
Podobnie jest prawdą, w ten szalony sposób, że gdzie wszystkie "stoły" są potwory, że "łączy są drogie" i coś, czego należy unikać. Nigdy nie mieli doświadczenia w łączeniu mniejszych stołów i zestawów, więc nie mogą uwierzyć w naukowy fakt, że więcej mniejszych stołów jest szybszych.
Mają doświadczenie, że Tworzenie duplikatów "tabel" jest szybsze, więc nie mogą uwierzyć, że eliminowanie duplikatów jest jeszcze szybsze.
Jego wymiary są dodane do unormowanych danych. Cóż, dane nie są znormalizowane, więc żadne wymiary nie są narażone. Podczas gdy w znormalizowanym modelu wymiary są już eksponowane, jako integralna część danych, nie jest wymagane dodanie .
Ta dobrze wybrukowana ścieżka Kimballa prowadzi do klifu, gdzie więcej lemingów spada na ich śmierć, szybciej. Lemingi są zwierzętami stadnymi, dopóki chodzą razem ścieżką i umierają razem, umierają szczęśliwi. Lemingi nie szukają innych dróg.
Wszystkie tylko historie, części jednej mitologii, które spędzają razem czas i wspierają się nawzajem.
Twoja Misja
Jeśli zdecydujesz się ją zaakceptować. Proszę cię, żebyś myślał za siebie i przestał bawić się myślami sprzecznymi z nauką i prawami fizyki. Nie ważne jak powszechne lub mistyczne lub mitologiczne są. Poszukaj dowodów na cokolwiek, zanim mu zaufasz. Bądź naukowcem, sam zweryfikuj nowe przekonania. Powtarzanie mantry "znormalizowana dla wydajności" nie sprawi, że Twoja baza danych będzie szybsza, po prostu sprawi, że poczujesz się lepiej. Jak gruby dzieciak siedzący z boku wmawiający sobie, że może biec szybciej niż wszystkie dzieciaki w wyścigu.
- na tej podstawie, nawet pojęcie "normalizacji dla OLTP", ale zrobić odwrotnie, "de-normalizacji dla OLAP " jest sprzecznością. W jaki sposób prawa fizyki mogą działać tak, jak podano na jednym komputerze, ale działać odwrotnie na innym komputerze ? Umysł błądzi. Po prostu nie jest to możliwe, praca w ten sam sposób na każdym komputerze.
Pytania ?
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-08-30 13:50:45
Denormalizacja i agregacja to dwie główne strategie stosowane do osiągnięcia wydajności w hurtowni danych. To po prostu głupie sugerować, że nie poprawia wydajności czytania! Chyba muszę coś przegapić?
Agregacja: Rozważmy tabelę zawierającą 1 miliard zakupów. Kontrast z tabelą zawierającą jeden wiersz z sumą zakupów. Co jest szybsze? Select sum (amount) from the one-billion-row table or a select amount from the stół jednorzędowy? To oczywiście głupi przykład, ale dość wyraźnie ilustruje zasadę agregacji. Dlaczego jest szybciej? Ponieważ niezależnie od tego, jakiego magicznego modelu / sprzętu/oprogramowania / religii używamy, odczyt 100 bajtów jest szybszy niż odczyt 100 gigabajtów. To proste.
Denormalizacja: Typowy wymiar produktu w hurtowni danych detalicznych ma mnóstwo kolumn. Niektóre kolumny to łatwe rzeczy, takie jak "nazwa" lub "kolor", ale ma również pewne skomplikowane rzeczy, takie jak hierarchie. Wiele hierarchii (asortyment produktów (5 poziomów), zamierzony nabywca( 3 poziomy), surowce (8 poziomów), sposób produkcji (8 poziomów) wraz z kilkoma liczbami obliczeniowymi, takimi jak średni czas realizacji (Od początku roku), Waga/opakowanie środki etcetera etcetera. Utrzymałem tabelę wymiarów produktu z 200 + kolumnami, która została zbudowana z ~70 tabel z 5 różnych systemów źródłowych. Po prostu głupotą jest dyskutować, czy Zapytanie o znormalizowany model (poniżej)
select product_id
from table1
join table2 on(keys)
join (select average(..)
from one_billion_row_table
where lastyear = ...) on(keys)
join ...table70
where function_with_fuzzy_matching(table1.cola, table37.colb) > 0.7
and exists(select ... from )
and not exists(select ...)
and table20.version_id = (select max(v_id from product_ver where ...)
and average_price between 10 and 20
and product_range = 'High-Profile'
... jest szybsze niż równoważne zapytanie na modelu denormalizowanym:
select product_id
from product_denormalized
where average_price between 10 and 20
and product_range = 'High-Profile';
Oczywiście, użycie denormalizacji i agregacji utrudnia dostosowanie zmian schematu, co jest złe. Z drugiej strony zapewniają wydajność odczytu, co jest dobrą rzeczą.
Więc, czy powinieneś denormalizować swoją bazę danych w celu osiągnięcia wydajności odczytu? Nie ma mowy! Dodaje to tak wiele złożoności do systemu, że nie ma końca, na ile sposobów będzie Cię wkręcić, zanim dostarczysz. Czy warto? Tak, Czasami trzeba to zrobić, aby spotkać się z szczególne wymagania dotyczące wydajności.
Update 1
PerformanceDBA: 1 wiersz będzie aktualizowany miliard razy dziennie
Oznaczałoby to wymaganie (bliskie) czasu rzeczywistego (które z kolei generowałoby zupełnie inny zestaw wymagań technicznych). Wiele (jeśli nie Większość) hurtowni danych nie ma tego wymogu. Wybrałem nierealistyczny przykład agregacji, aby wyjaśnić, dlaczego agregacja działa. Nie chciałem też tłumaczyć strategii rollup :)
Należy również kontrastować z potrzebami typowego użytkownika hurtowni danych i typowego użytkownika podkładowego systemu OLTP. Użytkownik, który chce zrozumieć, jakie czynniki wpływają na koszty transportu, nie może się martwić, czy brakuje 50% dzisiejszych danych lub czy 10 ciężarówek eksplodowało i zabiło kierowców. Przeprowadzając analizę danych na przestrzeni 2 lat, doszedłby do tego samego wniosku, nawet gdyby miał do dyspozycji drugą aktualną informację.
Potrzeb kierowców tej ciężarówki (tych, którzy przeżyli). Nie mogą czekać 5 godzin w jakimś punkcie tranzytowym tylko dlatego, że jakiś głupi proces agregacji musi Posiadanie dwóch oddzielnych kopii danych rozwiązuje obie potrzeby.
Kolejną poważną przeszkodą w udostępnianiu tego samego zestawu danych dla Systemów Operacyjnych i systemów raportowania jest to, że cykle wydania, Pytania i odpowiedzi, wdrażanie, SLA i to, co masz, są bardzo różne. Ponownie, posiadanie dwóch oddzielnych kopii ułatwia to obsługę.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-12-10 09:42:59
Przez "OLAP" rozumiem, że masz na myśli zorientowaną tematycznie relacyjną / SQL bazę danych używaną do wspomagania decyzji-AKA hurtownię danych.
Forma normalna (typowo 5. / 6. forma normalna) jest ogólnie najlepszym modelem dla hurtowni danych. Przyczyny normalizacji hurtowni danych są dokładnie takie same jak w każdej innej bazie danych: redukuje redundancję i unika potencjalnych anomalii aktualizacji; unika wbudowanych błędów i dlatego jest najprostszym sposobem obsługi zmian schematu i nowych wymagań. Korzystanie z normalnej formy w hurtowni danych pomaga również utrzymać proces ładowania danych prosty i spójny.
Nie ma "tradycyjnego" podejścia do denormalizacji. Dobre hurtownie danych zawsze były znormalizowane.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-12-09 08:26:48
Czy baza danych nie powinna być denormalizowana dla wydajności odczytu?
Dobra, oto całkowita "Twój przebieg może się różnić", "To zależy"," używaj odpowiedniego narzędzia do każdego zadania"," Jeden rozmiar nie pasuje do wszystkich "odpowiedź, z odrobiną" nie naprawiaj, jeśli nie jest zepsuty": {]}
Denormalizacja jest jednym ze sposobów poprawy wydajności zapytań w pewnych sytuacjach. W innych sytuacjach może faktycznie zmniejszyć wydajność (ze względu na zwiększone zużycie dysku). To z pewnością sprawia, że aktualizacje trudniej.
Powinno być brane pod uwagę tylko wtedy, gdy napotkasz problem z wydajnością (ponieważ dajesz korzyści z normalizacji i wprowadzasz złożoność).
Wady denormalizacji to mniej problemów z danymi, które nigdy nie są aktualizowane lub aktualizowane tylko w zadaniach wsadowych, tzn. nie dane OLTP.
Jeśli denormalizacja rozwiązuje problem wydajności, który trzeba rozwiązać, a mniej inwazyjne techniki (takie jak indeksy lub pamięci podręczne lub zakup większego serwera) nie Rozwiąż, to tak, powinieneś to zrobić.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-12-09 02:12:46
Najpierw moje opinie, potem analiza
Opinie
Denormalizacja jest postrzegana jako pomoc w odczytywaniu danych, ponieważ powszechne użycie słowa denormalizacja często obejmuje nie tylko łamanie normalnych form, ale także wprowadzanie wszelkich zależności wstawiania, aktualizacji i usuwania do systemu.
To, ściśle mówiąc, jest false , Patrz to pytanie/odpowiedź , Denormalizacja w ścisłym znaczeniu oznacza złamanie jakiejkolwiek normalnej formy z 1NF-6NF, inne zależności wstawiania, aktualizacji i usuwania są rozwiązywane przy użyciu zasady konstrukcji ortogonalnej .
Więc dzieje się tak, że ludzie biorą zasadę kompromisu czasoprzestrzeni {[18] } i pamiętają termin redundancja (związany z denormalizacją, wciąż nie równy) i dochodzą do wniosku, że powinieneś mieć korzyści. Jest to błędna implikacja, ale fałszywe implikacje nie pozwalają na zawarcie odwrotności.
Przełamywanie normalnych formMoże rzeczywiście przyspieszyć niektóre pobieranie danych (szczegóły w analizie poniżej), ale z reguły będzie to również w tym samym czasie:
- faworyzuje tylko określony typ zapytań i spowalnia wszystkie inne ścieżki dostępu [33]} zwiększenie złożoności systemu (co wpływa nie tylko na utrzymanie samej bazy danych, ale także zwiększa złożoność aplikacji, które zużywają dane) {34]}
- zaciemniać i osłabiać semantyczną klarowność bazy danych
- głównym punktem systemów bazodanowych, jako Centralne dane reprezentujące przestrzeń problemu mają być bezstronne w rejestrowaniu faktów, tak aby w przypadku zmiany wymagań nie trzeba było przeprojektowywać części systemu (danych i aplikacji), które są niezależne w rzeczywistości. aby móc wykonać te sztuczne zależności należy zminimalizować-dzisiejszy "krytyczny" wymóg przyspieszenia jednego zapytania często staje się tylko marginalnie ważny.
Analiza
Więc stwierdziłem, żeczasami łamanie normalne formy mogą pomóc w odzyskaniu. Czas podać kilka argumentów
1) Breaking 1NF
Załóżmy, że masz dokumentację finansową w 6NF. Z takiej bazy danych na pewno można uzyskać raport o tym, co jest Saldem dla każdego konta za każdy miesiąc.
Zakładając, że zapytanie, które musiałoby obliczyć taki raport, musiałoby przejść przez N rekordy, możesz utworzyć tabelę
account_balances(month, report)
Które przechowywałyby salda strukturyzowane XML dla każdego rachunku. To łamie 1NF (Patrz uwagi później), ale pozwala na wykonanie jednego konkretnego zapytania z minimum I / o .
W tym samym czasie, zakładając, że istnieje możliwość aktualizacji dowolnego miesiąca za pomocą wstawiania, aktualizacji lub usuwania zapisów finansowych, wydajność zapytań o aktualizację w systemie może zostać spowolniona o czas proporcjonalny do pewnej funkcji n dla każdej aktualizacji. (powyższy przypadek ilustruje zasadę, w rzeczywistości miałbyś lepsze opcje i korzyści z uzyskania minimum We / Wy przynoszą takie kary, że w przypadku realistycznego systemu, który faktycznie aktualizuje dane, często uzyskujesz złą wydajność nawet dla docelowego zapytania w zależności od rodzaju rzeczywistego obciążenia; możesz wyjaśnić to bardziej szczegółowo, jeśli chcesz) {]}
Uwaga: Jest to właściwie banalny przykład i jest z tym jeden problem-definicja 1NF. Założenie, że powyższy model łamie 1NF jest zgodne z wymogiem, że wartości atrybutu " zawierają dokładnie jedną wartość z applicable domain ".
To pozwala ci powiedzieć, że domena raportu atrybutu jest zbiorem wszystkich możliwych raportów i że z nich wszystkich jest dokładnie jedna wartość i twierdzić, że 1NF nie jest złamany (podobnie jak argument, że przechowywanie słów nie łamie 1NF, mimo że możesz mieć letters relację gdzieś w twoim modelu).
Z drugiej strony istnieją znacznie lepsze sposoby modelowania tej tabeli, co byłoby bardziej przydatne dla szerszego zakresu zapytań (np. do pobierania salda dla jednego konta na wszystkie miesiące w roku). W takim przypadku uzasadniłbyś tę poprawę mówiąc, że to pole nie znajduje się w 1NF.
W każdym razie wyjaśnia to, dlaczego ludzie twierdzą, że złamanie NFs może poprawić wydajność.
2) Breaking 3NF
Zakładanie tabel w 3NF
CREATE TABLE `t` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`member_id` int(10) unsigned NOT NULL,
`status` tinyint(3) unsigned NOT NULL,
`amount` decimal(10,2) NOT NULL,
`opening` decimal(10,2) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `member_id` (`member_id`),
CONSTRAINT `t_ibfk_1` FOREIGN KEY (`member_id`) REFERENCES `m` (`id`) ON DELETE CASCADE ON UPDATE CASCADE
) ENGINE=InnoDB
CREATE TABLE `m` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB
Z przykładowymi danymi (1m wierszy w t, 100K w m)
Załóżmy wspólne zapytanie, które chcesz poprawić
mysql> select sql_no_cache m.name, count(*)
from t join m on t.member_id = m.id
where t.id between 100000 and 500000 group by m.name;
+-------+----------+
| name | count(*) |
+-------+----------+
| omega | 11 |
| test | 8 |
| test3 | 399982 |
+-------+----------+
3 rows in set (1.08 sec)
Możesz znaleźć propozycje przeniesienia atrybutu name do tabeli m, która łamie 3NF (ma FD: member_id -> name I member_id nie jest kluczem t)
Po
alter table t add column varchar(255);
update t inner join m on t.member_id = t.id set t.name = m.name;
Running
mysql> select sql_no_cache name, count(*)
from t where id
between 100000 and 500000
group by name;
+-------+----------+
| name | count(*) |
+-------+----------+
| omega | 11 |
| test | 8 |
| test3 | 399982 |
+-------+----------+
3 rows in set (0.41 sec)
Przypisy: Powyższy czas wykonania zapytania to przecięty na pół, Ale
- tabela nie była w 5NF/6NF na początek
- test został wykonany z no_sql_cache, więc większość mechanizmów pamięci podręcznej została uniknięta (i w rzeczywistych sytuacjach odgrywają one rolę w wydajności systemu)
- zużycie przestrzeni zwiększa się o ok. rozmiar nazwy kolumny x 100k wierszy Aby zachować integralność danych, powinny istnieć wyzwalacze na t, co znacznie spowolniłoby wszystkie aktualizacje nazwy i dodałoby dodatkowe kontrole, przez które wstawki w t musiałyby przejść Prawdopodobnie lepsze wyniki można osiągnąć przez upuszczenie kluczy zastępczych i Przełączenie na klucze naturalne i / lub indeksowanie lub przeprojektowanie na wyższy NFs [34]}
Bottom line
Myślę, że najbardziej trafną odpowiedzią na twoje pytanie jest to, że znajdziesz przemysł i edukację używając terminu "denormalizacja" w
- ścisły sens, dla łamanie NFs
- luźno, za wprowadzanie dowolnych wstawek, aktualizacja i usuwanie zależności (oryginalny cytat Codd komentarze na temat normalizacji mówiąc: " (!) wstawianie, aktualizowanie i usuwanie zależności', zobacz kilka szczegółów tutaj )
Tak więc, zgodnie ze ścisłą definicją, agregacja (tabele podsumowujące) nie są uważane za denormalizację i mogą bardzo pomóc pod względem wydajności (podobnie jak każda pamięć podręczna, która nie jest postrzegana jako denormalizacja).
Luźne użycie obejmuje zarówno łamanie formularze normalne i zasada konstrukcji ortogonalnej , Jak wspomniano wcześniej.
Kolejną rzeczą, która może rzucić trochę światła jest to, że istnieje bardzo ważna różnica między modelem logicznym a modelem fizycznym.
Na przykład indeksy przechowują nadmiarowe dane, ale nikt nie uważa ich za denormalizację, nawet ludzie, którzy używają terminu luźno i istnieją dwa (połączone) powody tego
- nie są częścią model logiczny Są one przejrzyste i gwarantują, że nie naruszają integralności Twojego modelu.]}
Jeśli nie uda Ci się poprawnie modelować swojego modelu logicznego, skończysz z niespójną bazą danych-niewłaściwe typy relacji między twoimi podmiotami ( niezdolność do reprezentowania przestrzeni problemowej), sprzeczne fakty (zdolność do utraty informacji) i powinieneś zastosować wszelkie możliwe metody, aby uzyskać poprawny Model logiczny, jest to podstawa dla wszystkich aplikacji, które zostaną zbudowane na bazie danych. to.
Normalizacja, ortogonalna i jasna semantyka Twoich predykatów, dobrze zdefiniowane atrybuty, prawidłowo zidentyfikowane zależności funkcjonalne-wszystko to odgrywa rolę w unikaniu pułapek.
Jeśli chodzi o fizyczną implementację, rzeczy stają się bardziej zrelaksowane w tym sensie, że zmaterializowana kolumna obliczeniowa, która jest zależna od klucza non, może łamać 3NF, ale jeśli istnieją mechanizmy gwarantujące spójność, jest dozwolona w modelu fizycznym w taki sam sposób, jak dozwolone są indeksy, ale musisz bardzo ostrożnie uzasadnić to, ponieważ zazwyczaj normalizacja przyniesie takie same lub lepsze ulepszenia we wszystkich aspektach i nie będzie miała negatywnego lub mniej negatywnego wpływu i utrzyma przejrzysty projekt (co zmniejsza koszty rozwoju i utrzymania aplikacji), co skutkuje oszczędnościami, które można łatwo wydać na modernizację sprzętu, aby poprawić szybkość jeszcze bardziej niż to, co osiąga się przy łamaniu NFs.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-23 12:10:38
Dwie najpopularniejsze metody budowy hurtowni danych (DW) wydają się być Bill Inmon i Ralph Kimball.
Metodologia Inmona wykorzystuje znormalizowane podejście, podczas gdy Kimball używa modelowania wymiarowego-znormalizowanego schematu gwiazd.
Oba są dobrze udokumentowane do małych szczegółów i oba mają wiele udanych wdrożeń. Obie stanowią "szeroką, dobrze utwardzoną drogę" do celu DW.
Nie mogę komentować podejścia 6NF ani modelowania Anchor, ponieważ Nigdy nie widziałem i nie brałem udziału w projekcie DW wykorzystującym tę metodologię. Jeśli chodzi o implementacje, lubię podróżować po sprawdzonych ścieżkach - ale to tylko ja.
Podsumowując, czy DW powinien być znormalizowany czy zdegenerowany? Zależy od metodologii, którą wybierzesz-po prostu wybierz jedną i trzymaj się jej, przynajmniej do końca projektu.
EDIT-przykład
W miejscu, w którym obecnie pracuję, mieliśmy raport, który działa od zawsze na serwerze produkcyjnym. Nie zwykły raport, ale zbiór 30 raportów wysyłanych codziennie do wszystkich i jego mrówek.
Ostatnio wdrożyliśmy DW. Z dwoma serwerami raportów i mnóstwem raportów, miałem nadzieję, że możemy zapomnieć o dziedzictwie. Ale nie, dziedzictwo to dziedzictwo, zawsze je mieliśmy, więc go chcemy, potrzebujemy, nie możemy bez niego żyć itp.
Rzecz w tym, że bałagan skryptu Pythona i SQL zajęło osiem godzin (tak, e-i-G-H-T godzin), aby uruchomić każdy jeden dzień. Nie trzeba dodawać, że baza danych i aplikacja zostały zbudowane przez lata przez kilka partii programistów - więc nie do końca Twój 5NF.
Nadszedł czas, aby odtworzyć dziedzictwo z DW. Ok, żeby było krótko, to jest zrobione i trwa 3 minuty (T-h-R-E-E minut), aby to wyprodukować, 6 sekund na raport podrzędny. I byłem w pośpiechu, aby dostarczyć, więc nie było nawet optymalizacji wszystkich zapytań. Jest to czynnik 8 * 60 / 3 = 160 razy szybciej - nie wspominając o korzyściach z usuwania 8 godzin pracy z serwera produkcyjnego. Myślę, że mogę się ogolić na minutę, ale teraz nikogo to nie obchodzi.
Jako ciekawostkę, użyłem metody Kimballa (modelowanie wymiarowe) dla DW i wszystko użyte w tej historii jest open-source.
To jest to, co to wszystko (hurtownia danych) ma być, myślę. Czy w ogóle ma znaczenie, która metodologia (znormalizowana lub de-znormalizowana) została użyta?
EDIT 2
Jako punkt zainteresowania, Bill Inmon ma ładnie napisany artykuł na swojej stronie internetowej -- opowieść o dwóch architekturach.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-12-22 17:06:27
Problem ze słowem "denormalized" polega na tym, że nie określa w jakim kierunku iść. To tak, jakby próbować dostać się do San Francisco z Chicago, odjeżdżając z Nowego Jorku.
Schemat gwiazdy lub schemat płatka śniegu z pewnością nie jest znormalizowany. I na pewno działa lepiej niż znormalizowany schemat w niektórych wzorcach użytkowania. Są jednak przypadki denormalizacji, w których projektant nie przestrzegał żadnej dyscypliny, a jedynie komponował tabele intuicyjnie. Czasami te wysiłki nie wychodzą.
W skrócie, nie tylko denormalizuj. Postępuj zgodnie z inną dyscypliną projektowania, jeśli jesteś przekonany o jej zaletach, a nawet jeśli nie zgadza się ona z znormalizowanym projektem. Ale nie używaj denormalizacji jako pretekstu do przypadkowego projektowania.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-12-23 22:32:18
Krótka odpowiedź brzmi nie naprawiaj problemu z wydajnością, którego nie masz !
Jeśli chodzi o tabele oparte na czasie, ogólnie przyjęte pardigm ma mieć daty valid_from i valid_to w każdym wierszu. Jest to wciąż w zasadzie 3NF, ponieważ zmienia tylko semantykę z " to jest jedyna i jedyna wersja tego podmiotu "na" to jest jedyna i jedyna wersja tego podmiotu w tym czasie "
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-12-09 02:12:20
Uproszczenie:
Baza danych OLTP powinna zostać znormalizowana (o ile ma to sens).
Hurtownia danych OLAP powinna być denormalizowana na tabele faktów i wymiarów (w celu zminimalizowania złączeń).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-12-09 02:39:56