Tuning wydajności w Mathematica?
Jakich sztuczek strojenia wydajności używasz, aby aplikacja Mathematica była szybsza? MATLAB ma niesamowity profiler, ale z tego co mogę powiedzieć, Mathematica nie ma podobnej funkcjonalności.
4 answers
Ponieważ Mathematica jest systemem symbolicznym, z symbolicznym ewaluatorem znacznie więcej ogólnie niż w Matlab, nie dziwi fakt, że Tuning wydajności może być bardziej skomplikowane. Istnieje wiele technik, ale wszystkie można zrozumieć z jednej głównej zasady. Jest:
unikaj pełnego procesu symbolicznej oceny Mathematica w jak największym stopniu.
Wszystkie techniki zdają się odzwierciedlać pewien aspekt tego. Główną ideą jest to, że większość czas, powolna Matematyka program jest taki, ponieważ wiele funkcji Mathematica są bardzo ogólne. To ogólność jest wielką siłą, ponieważ umożliwia językowi wspieranie lepszych i potężniejszych abstrakcji, ale w wielu miejscach w programie taka ogólność, używana bez opieki, może być (ogromną) przesadą.
Nie będę w stanie podać wielu przykładów ilustracyjnych w ograniczonej przestrzeni, ale można je znaleźć w kilka miejsc, w tym niektóre raporty techniczne WRI (Daniel Lichtblau one on efficient data struktur w Mathematica przychodzi na myśl), bardzo dobry książka Davida Wagnera o programowaniu Mathematica, a przede wszystkim wiele grup matematycznych postów. Omawiam również ograniczony ich podzbiór w mojej książce . Wkrótce dostarczę więcej referencji.
Oto kilka najczęstszych (wymieniam tylko te dostępne w Mathematica samego języka, nie wspominając o CUDA \ OpenCL, czy linkach do innych języków, które są oczywiście również możliwości):
-
Push jak najwięcej pracy w jądrze na raz, praca z tak dużym w 2007 roku firma została założona przez Johna F. Kennedy 'ego, a w 2008 roku została założona przez Johna F. Kennedy' ego.]}
1.1. Użyj wbudowanych funkcji, gdy to możliwe. Ponieważ są one realizowane w jądrze, w języku niższego poziomu (C), są one zazwyczaj (ale nie zawsze!) znacznie szybsze niż zdefiniowane przez użytkownika rozwiązanie tego samego problemu. Bardziej wyspecjalizowane wersji wbudowanej funkcji, z której jesteś w stanie korzystać, tym większe szanse masz na Przyspiesz.
1.2. Użyj programowania funkcyjnego (
Map, Apply, i przyjaciele). Ponadto użyj czystych funkcji w notacji#-&Kiedy można, Są one szybsze niż Funkcja-s o nazwie argumenty lub te oparte na wzorcach (szczególnie dla nie wymagających obliczeniowo funkcje mapowane na dużych listach).1.3. Użyj operacji strukturalnych i wektorowych (
Transpose, Flatten, Partition, Parti przyjaciele), są one jeszcze szybsze niż funkcjonalne.1.4. Unikaj używania programowania proceduralnego (pętli itp.), ponieważ to programowanie styl ma tendencję do łamania dużych struktur na kawałki (indeksowanie tablic itp.). To wypycha większą część obliczeń poza jądro i czyni je wolniejszymi.
-
użyj precyzji maszynowej, gdy to możliwe
2.1. Bądź świadomy i korzystaj z wbudowanych funkcji numerycznych, stosując je do Duże listy danych zamiast używać
Maplub pętli.2.2. Użyj
Compile, Kiedy możesz. Korzystać z nowych możliwościCompile, takich jakCompilationTarget->"C", i uczynienie naszych funkcji kompilacyjnych równoległymi i Listownymi.2.3. Jeśli to możliwe, użyj wektoryzowanych operacji (
UnitStep, Clip, Sign, Abs, itp) wewnątrzCompile, aby zrealizować konstrukcje "wektoryzowanego przepływu sterowania", takie jakIf, tak aby można unikać pętli jawnych (przynajmniej jako najbardziej wewnętrznych) również wewnątrzCompile. To może przenieść prędkość z kodu bajtowego Mathematica do prawie natywnej prędkości C, w niektórych przypadkach.2.4. Podczas używania
Compile, Upewnij się, że skompilowana funkcja nie nie skompilowana ocena. Zobacz przykłady W tym wątku grupy Matematycznej . -
należy pamiętać, że listy są zaimplementowane jako tablice w Mathematica
3.1. Wstępnie przydzielaj Duże listy
3.2. Unikać
Append, Prepend, AppendToiPrependTow pętlach, do budowania listy itp. (ponieważ kopiują całą listę, aby dodać pojedynczy element, co prowadzi do kwadratowej, a nie liniowej złożoności dla budowania listy)3.3. Używaj list połączonych (struktur typu
{1,{2,{3,{}}}}) zamiast listy zwykłe do akumulacji list w programie. Typowy idiom toa = {new element, a}. Ponieważ a jest odniesieniem, pojedyncze zadanie jest stałym czasem.3.4. Należy pamiętać, że dopasowanie wzorca do wzorców sekwencji (BlankSequence, BlankNullSequence) opiera się również na sekwencjach będących tablicami. Dlatego zasada
{fst_,rest___}:>{f[fst],g[rest]}skopiuje całą listę po zastosowaniu. W szczególności nie użyj rekursji w sposób, który może wyglądać naturalnie w innych językach. Jeśli chcesz użyć rekurencji na listach, najpierw przekonwertuj swoje Listy Do List połączonych. -
unikaj nieefektywnych wzorców, konstruuj efektywne wzorce
4.1. Programowanie oparte na regułach może być zarówno bardzo szybkie, jak i bardzo wolne, w zależności od tego, jak budujesz swoje struktury i zasady, ale w praktyce łatwiej jest zwolnij. Będzie wolno Dla zasad, które zmuszają pattern-matcher do wielu przeorysznych prób dopasowania, np. poprzez niedostateczne wykorzystanie każdego biegu wzór-matcher przez długi list (wyrażenie). Dobrym przykładem jest sortowanie elementów:
list//.{left___,x_,middle___,y_,right___}/;x>y:>{left,y,middle,x,right}- ma złożoność sześcienną w rozmiar listy (Wyjaśnienie to np. tutaj ).4.2. Budować wydajne wzorce i odpowiednie struktury do przechowywania danych, dzięki czemu pattern-matcher, aby tracić jak najmniej czasu na fałszywe próby dopasowania, jak to możliwe.
4.3. Unikaj używania wzorców z intensywnymi obliczeniowo warunkami lub testami. Na pattern-matcher da ci największą szybkość, gdy wzory są głównie składniowe w charakter (struktura badania, głowice itp.). Za każdym razem, gdy warunek
(/;)lub test wzorca(?)jest używany, dla każdego potencjalnego dopasowania, ewaluator jest wywoływany przez pattern-matcher, a to spowalnia. -
należy pamiętać o niezmiennej naturze większości wbudowanych funkcji Mathematica
Większość wbudowanych funkcji Mathematica, które przetwarzają listy, tworzy kopię oryginalnej listy i operuj tą kopią. Dlatego mogą mieć czas liniowy (i przestrzeni) złożoność w rozmiar oryginalnej listy, nawet jeśli modyfikują ją tylko w kilku miejscach. One universal wbudowana funkcja, która nie tworzy kopii, modyfikuje oryginalne wyrażenie i nie mieć ten problem, jest
Part.5.1. Unikaj używania większości wbudowanych funkcji modyfikujących listę dla dużej liczby małe niezależne modyfikacje listy, których nie można sformułować w jednym kroku (na przykład,
NestWhile[Drop[#,1]&,Range[1000],#<500&])5.2. Użyj rozszerzonej funkcjonalności
Partdo wyodrębnić i zmodyfikować dużą liczbę lista (lub bardziej ogólne wyrażenie) elementów w tym samym czasie. To jest bardzo szybkie, i nie tylko dla zapakowanych tablic numerycznych (Partmodyfikuje oryginalną listę).5.3. Użyj
Extract, aby wyodrębnić wiele elementów na różnych poziomach jednocześnie, przechodząc do niego prawdopodobnie duża lista pozycji elementów. -
wykorzystanie efektywnych wbudowanych struktur danych
Następujące wewnętrzne struktury danych są bardzo wydajne i mogą być używany w o wiele więcej sytuacji, niż mogłoby się wydawać z ich głównego celu. Wiele takich przykładów można znaleźć, przeszukując Archiwum Mathgroup, szczególnie wkład Carla Wolla.
6.1. Packed arrays
6.2. Sparse arrays
-
użyj tabel hashowych.
Od wersji 10, niezmienne tablice asocjacyjne są dostępne w Mathematica (Asocjacje).]}7.1 skojarzenia
Fakt, że są immutable nie uniemożliwia im skutecznego wstawiania i usuwania par klucz-wartość (tanie kopie różniące się od oryginalnego skojarzenia obecnością lub nieobecnością danej pary klucz-wartość). Reprezentują idiomatyczne tablice asocjacyjne w Mathematica i mają bardzo dobre właściwości użytkowe.
W przypadku wcześniejszych wersji,następujące alternatywy działają całkiem dobrze, bazując na tablicach hashowych wewnętrznych Mathematica:]}7.2. Hash-tabele oparte na
DownValueslubSubValues7.3.
Dispatch -
użyj element-pozycja dualność
Często można pisać szybciej funkcje do pracy z pozycjami elementów, a nie same elementy, ponieważ pozycje są liczbami całkowitymi (dla list płaskich). To może dać ci nawet o rząd wielkości, nawet w porównaniu do ogólnych wbudowanych funkcji (
Positionprzychodzi na myśl jako przykład). -
Use Reap-Loch
ReaporazSowzapewnić skuteczny sposób zbierania wyników pośrednich i ogólnie "tagowanie" części, które chcesz zebrać podczas obliczeń. Te polecenia również idą dobrze z programowaniem funkcjonalnym. -
używaj buforowania, programowania dynamicznego, leniwej oceny
10.1. Memoizacja jest bardzo łatwo zaimplementowana w Mathematica i może zaoszczędzić wiele czasu czas na pewne problemy.
10.2. W Mathematica można zaimplementować bardziej złożone wersje memoizacja, gdzie można definiować funkcje (zamknięcia) w czasie wykonywania, które będą wykorzystywać niektóre wstępnie obliczone części w swoich definicje i dlatego będzie szybciej.
10.3. Niektóre problemy mogą skorzystać z leniwej oceny. To wydaje się bardziej istotne dla pamięci - wydajność, ale może również wpływać na wydajność pracy. Konstrukcje symboliczne Mathematica tworzą to łatwe do wdrożenia.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-12-04 00:27:30
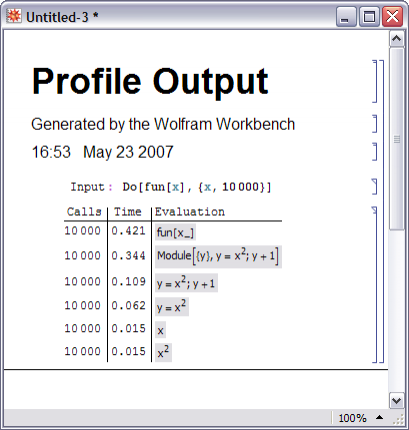
Możesz użyć profilera zawartego w Wolfram Workbench
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-01-18 07:07:45
Zapraszamy do zapoznania się z prezentacją Principles for Efficient Mathematica Programs z konferencji Wolfram Technology Conference 2007.
Kolejną użyteczną prezentacją są Wskazówki dotyczące efektywnego kodowania pamięci w języku Wolfram .
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-09-19 08:05:56
Jeśli chcę przyspieszyć mój kod, sprawdzam, czy mogę użyć FunctionCompile, aby go przyspieszyć:
Https://reference.wolfram.com/language/guide/CodeCompilation.html
Ten kompilator tłumaczy kod WL na kod bajtowy LLVM, który następnie może być skompilowany do natywnego kodu maszynowego. Jest bardzo dobry film instruktażowy na YouTube, który wyjaśnia, co można zrób z tym kompilatorem:
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-10-22 15:34:58