Jak usunąć wartości odstające z zbioru danych
Mam kilka wielowymiarowych danych piękna vs wieku. Wiek waha się od 20-40 w odstępach 2 (20, 22, 24....40), a dla każdego zapisu danych otrzymują ocenę wieku i urody od 1-5. Kiedy robię boxplots z tych danych (wiek w osi X, oceny piękna w osi Y), istnieją pewne odstające wykreślone poza wąsami każdego pudełka.
Chcę usunąć te wartości odstające z samej ramki danych, ale nie jestem pewien, jak R oblicza wartości odstające dla swoich działek pudełkowych. Poniżej znajduje się przykład, jak mogą wyglądać moje dane.
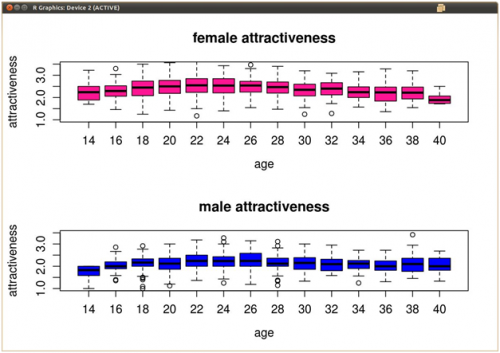
8 answers
Ok, powinieneś zastosować coś takiego do swojego zbioru danych. Nie zastępuj i nie zapisuj, bo zniszczysz swoje dane! I, btw, powinieneś (prawie) nigdy nie usuwać odstających danych:
remove_outliers <- function(x, na.rm = TRUE, ...) {
qnt <- quantile(x, probs=c(.25, .75), na.rm = na.rm, ...)
H <- 1.5 * IQR(x, na.rm = na.rm)
y <- x
y[x < (qnt[1] - H)] <- NA
y[x > (qnt[2] + H)] <- NA
y
}
Aby zobaczyć go w akcji:
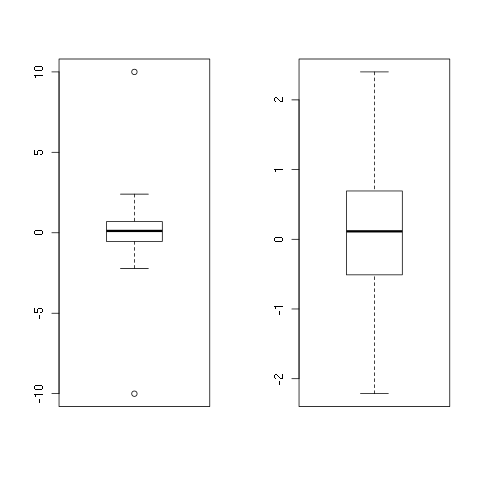
set.seed(1)
x <- rnorm(100)
x <- c(-10, x, 10)
y <- remove_outliers(x)
## png()
par(mfrow = c(1, 2))
boxplot(x)
boxplot(y)
## dev.off()
I jeszcze raz, nigdy nie powinieneś tego robić sam, odstające są po prostu przeznaczone! =)
EDIT: dodałem na.rm = TRUE jako domyślne.
EDIT2: usunięto funkcję quantile, dodano subscripting, dzięki czemu funkcja była szybsza! =)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-01-25 00:16:18
Nikt nie napisał najprostszej odpowiedzi:
x[!x %in% boxplot.stats(x)$out]
Zobacz też: http://www.r-statistics.com/2011/01/how-to-label-all-the-outliers-in-a-boxplot/
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-02-08 19:24:08
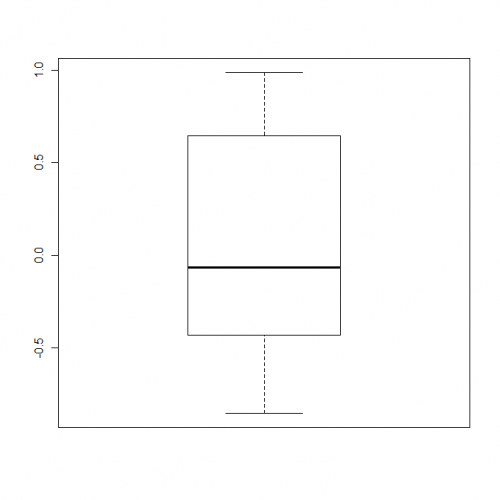
Użyj outline = FALSE jako opcji, gdy robisz boxplot (przeczytaj pomoc!).
> m <- c(rnorm(10),5,10)
> bp <- boxplot(m, outline = FALSE)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-01-24 21:44:29
Funkcja boxplot zwraca wartości używane do tworzenia wykresów (co w rzeczywistości jest wykonywane przez BXP ():
bstats <- boxplot(count ~ spray, data = InsectSprays, col = "lightgray")
#need to "waste" this plot
bstats$out <- NULL
bstats$group <- NULL
bxp(bstats) # this will plot without any outlier points
Celowo nie odpowiedziałem na konkretne pytanie, ponieważ uważam, że usunięcie "odstających"jest statystycznym błędem. Uważam, że akceptowalną praktyką jest nie wykreślanie ich w kartotece, ale ich usunięcie jest systematycznym i nieuzasadnionym zniekształcaniem zapisu obserwacyjnego.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-01-24 23:40:10
x<-quantile(retentiondata$sum_dec_incr,c(0.01,0.99))
data_clean <- data[data$attribute >=x[1] & data$attribute<=x[2],]
Uważam, że jest to bardzo łatwe do usunięcia odstających. W powyższym przykładzie wyodrębniam od 2 percentyla do 98 percentyla wartości atrybutów.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-10-23 04:55:07
Szukałem pakietów związanych z usuwaniem odstających wartości i znalazłem ten pakiet (zaskakująco zwany "odstającymi"!): https://cran.r-project.org/web/packages/outliers/outliers.pdf
jeśli przejdziesz przez to zobaczysz różne sposoby usuwania odstających i wśród nich znalazłem rm.outlier najwygodniejszy w użyciu i jak to jest napisane w linku powyżej:
"Jeśli wartość odstająca zostanie wykryta i potwierdzona testami statystycznymi, funkcja ta może ją usunąć lub zastąpić przez
przykładowa średnia lub mediana", a także tutaj jest część użytkowa z tego samego źródła:
"użycie
rm.outlier(x, fill = FALSE, median = FALSE, opposite = FALSE)
Argumenty
x zbiór danych, najczęściej wektor. Jeśli argument jest dataframe, to outlier jest
usunięte z każdej kolumny przez sapply. To samo zachowanie jest stosowane przez apply
gdy dana jest macierz.
fill jeśli jest ustawione na TRUE, mediana lub średnia jest umieszczana zamiast wartości outlier. W przeciwnym razie
outlier(S) jest / są po prostu usunięte.
mediana Jeśli ustawiona jest na TRUE, mediana jest używana zamiast średniej w zastępstwie outlier.
opposite jeśli jest ustawione na TRUE, daje wartość przeciwną (jeśli największa wartość ma maksymalną różnicę
ze średniej daje najmniejsze i odwrotnie)
"
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-12-29 01:10:13
Dodając do sugestii @sefarkas i używając kwantylu jako odcięcia, można zbadać następującą opcję:
newdata <- subset(mydata,!(mydata$var > quantile(mydata$var, probs=c(.01, .99))[2] | mydata$var < quantile(mydata$var, probs=c(.01, .99))[1]) )
Spowoduje to usunięcie punktów poza kwantylem 99. Należy zachować ostrożność, jak to, co aL3Xa mówił o utrzymywaniu wartości odstających. Należy go usunąć tylko w celu uzyskania alternatywnego konserwatywnego widoku danych.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-03-23 16:33:39
Nie:
z <- df[df$x > quantile(df$x, .25) - 1.5*IQR(df$x) &
df$x < quantile(df$x, .75) + 1.5*IQR(df$x), ] #rows
Wykonać to zadanie dość łatwo?
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-08-30 19:17:35