RegEx dla pasujących kodów pocztowych w Wielkiej Brytanii
Szukam wyrażenia regularnego, które potwierdzi pełny złożony Kod Pocztowy UK tylko w ciągu wejściowym. Wszystkie nietypowe formularze kodów pocztowych muszą być objęte, jak również zwykłe. Na przykład:
Mecze
- CW3 9SS
- SE5 0EG
- SE50EG
- se5 0EG
- WC2H 7LT
No Match
- aWC2H 7LT
- WC2H 7LTa
- WC2H
Jak rozwiązać ten problem?
30 answers
Polecam spojrzeć na Brytyjski rządowy Standard danych dla kodów pocztowych [link teraz Martwy; archiwum XML , Zobacz Wikipedia do dyskusji]. Istnieje Krótki opis danych, a załączony schemat xml zawiera wyrażenie regularne. Może nie jest to dokładnie to, czego chcesz, ale byłby dobrym punktem wyjścia. RegEx różni się nieco od XML, ponieważ znak P na trzeciej pozycji w formacie A9A 9AA jest dozwolony przez podaną definicję.
RegEx dostarczone przez rząd brytyjski było:
([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([A-Za-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9][A-Za-z]?))))\s?[0-9][A-Za-z]{2})
Jak wspomniano w dyskusji na Wikipedii, pozwoli to na niektóre nierealne kody pocztowe (np. te rozpoczynające AA, ZY) i zapewniają bardziej rygorystyczny test, który możesz wypróbować.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-08-16 18:33:28
Ostatnio zamieściłem odpowiedź na to pytanie na brytyjskich kodach pocztowych dla języka R. Odkryłem, że wzór regex rządu brytyjskiego jest nieprawidłowy i nie sprawdza poprawnie} niektórych kodów pocztowych. Niestety, wiele odpowiedzi tutaj opiera się na tym błędnym wzorze.
Przedstawię poniżej niektóre z tych problemów i przedstawię poprawione Wyrażenie regularne, które w rzeczywistości działa.
Uwaga
Moja odpowiedź (i ogólnie wyrażenia regularne):
- tylko waliduje kod pocztowy formaty.
-
nie zapewnia legalnego istnienia kodu pocztowego .
- w tym celu użyj odpowiedniego API! Zobacz odpowiedź Bena aby uzyskać więcej informacji.
jeśli nie zależy ci na bad regex i po prostu chcesz przejść do odpowiedź, przewiń w dół do sekcji odpowiedź.
Zły Regex
Wyrażenia regularne w tej sekcji nie powinny być używane.
To jest błąd regex, który rząd Wielkiej Brytanii dostarczył deweloperom (Nie wiem, jak długo ten link będzie aktywny, ale możesz go zobaczyć w ich zbiorczej dokumentacji transferu danych):
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z]))))[0-9][A-Za-z]{2})$
Problemy
Problem 1-Kopiuj / Wklej
Zobacz Wyrażenie regularne w użyciu tutaj .
Jak wielu programistów, kopiują / wklejają kod (zwłaszcza wyrażenia regularne) i wklejają oczekując, że zadziała. Chociaż teoretycznie jest to świetne, w tym konkretnym przypadku nie powiedzie się, ponieważ kopiowanie / wklejanie z tego dokumentu faktycznie zmienia jeden ze znaków (spację) na znak nowej linii, jak pokazano poniżej: {]}
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z]))))
[0-9][A-Za-z]{2})$
Pierwszą rzeczą, którą zrobi większość programistów, jest usunięcie nowej linii bez zastanowienia. Teraz regex nie będzie pasował do kodów pocztowych z spacje w nich (inne niż GIR 0AA Kod Pocztowy).
Aby rozwiązać ten problem, znak nowej linii należy zastąpić znakiem spacji:
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2})$
^
Problem 2-Granice
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2})$
^^ ^ ^ ^^
Regex kodu pocztowego nieprawidłowo zakotwicza regex. Każdy, kto używa tego wyrażenia regularnego do walidacji kodów pocztowych, może być zaskoczony, jeśli wartość taka jak fooA11 1AA przejdzie. To dlatego, że zakotwiczyli początek pierwszej opcji i koniec druga opcja (niezależnie od siebie), jak wskazano w regex powyżej.
Oznacza to, że ^ (zapewnia pozycję na początku linii) działa tylko na pierwszej opcji ([Gg][Ii][Rr] 0[Aa]{2}), więc druga opcja potwierdzi wszystkie ciągi znaków, które kończą się w kodzie pocztowym (niezależnie od tego, co nastąpi wcześniej).
Podobnie, pierwsza opcja nie jest zakotwiczona na końcu linii $, więc GIR 0AAfoo jest również akceptowana.
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z]))))[0-9][A-Za-z]{2})$
Aby rozwiązać ten problem, obie opcje powinny być w przeciwieństwie do innych grup, nie jest to grupa przechwytywania, a kotwice umieszczone wokół niej to:
^(([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2}))$
^^ ^^
Problem 3-Niewłaściwy Zestaw Znaków
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2})$
^^
Regex brakuje - tutaj, aby wskazać zakres znaków. Jeśli kod pocztowy jest w formacie ANA NAA (gdzie A reprezentuje literę, a N reprezentuje liczbę) i zaczyna się od czegoś innego niż A lub Z, to się nie powiedzie.
To znaczy będzie pasować A1A 1AA i Z1A 1AA, ale nie B1A 1AA.
Aby rozwiązać ten problem, znak - powinien być umieszczony pomiędzy A i Z w odpowiednim zestawie znaków:
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([A-Za-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2})$
^
Problem 4-Niewłaściwy Opcjonalny Zestaw Znaków
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2})$
^
Przysięgam, że nawet nie przetestowali tego przed opublikowaniem go w Internecie. Zrobili niewłaściwy zestaw znaków opcjonalny. Zrobili [0-9] opcję w czwartym podwariancie wariantu 2 (Grupa 9). To pozwala regex dopasować niepoprawnie sformatowane kody pocztowe, takie jak AAA 1AA.
Aby rozwiązać ten problem, upewnij się, że następna klasa znaków jest opcjonalna (a następnie upewnij się, że Zestaw [0-9] pasuje dokładnie raz):
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9][A-Za-z]?)))) [0-9][A-Za-z]{2})$
^
Problem 5-Wydajność
Wydajność tego wyrażenia regularnego jest bardzo słaba. Po pierwsze, umieścili najmniej prawdopodobną opcję wzorca, aby dopasować GIR 0AA na początku. Ilu użytkowników prawdopodobnie będzie miało ten kod pocztowy w porównaniu z jakimkolwiek innym kodem pocztowym; pewnie nigdy? Oznacza to, że za każdym razem, gdy regex jest używany, musi najpierw wyczerpać tę opcję przed przejściem do następnej opcji. Aby zobaczyć, jak wpływa na wydajność, sprawdź liczbę kroków oryginalne Wyrażenie regularne wykonało (35) wobec tego samego wyrażenia regularnego po odwróceniu opcji (22).
Drugi problem z wydajnością wynika ze sposobu, w jaki cały regex jest zorganizowany. Nie ma sensu cofać się nad każdą opcją, jeśli jedna nie powiedzie się. Sposób, w jaki obecne regex jest strukturę można znacznie uprościć. Podaję poprawkę w sekcji odpowiedź .
Problem 6-Spacje
To może nie być traktowane jako problem , sam w sobie, ale budzi to obawy większości deweloperów. Spacje w regex nie są opcjonalne, co oznacza, że użytkownicy wprowadzający swoje kody pocztowe muszą umieścić spację w kodzie pocztowym. Jest to Łatwa poprawka, po prostu dodając ? po spacjach do renderowania są opcjonalne. Zobacz sekcję odpowiedź , aby uzyskać poprawkę.
Odpowiedź
1. Naprawa Regex rządu brytyjskiego
Naprawienie wszystkich problemów opisanych w sekcji problemy i uproszczenie wzoru daje następujący, krótszy, bardziej zwięzły wzór. Możemy również usunąć większość grup, ponieważ sprawdzamy Kod Pocztowy jako całość (nie pojedyncze części): {]}
^([A-Za-z][A-Ha-hJ-Yj-y]?[0-9][A-Za-z0-9]? ?[0-9][A-Za-z]{2}|[Gg][Ii][Rr] ?0[Aa]{2})$
To może być dalej skrócony poprzez usunięcie wszystkich zakresów z jednej z przypadków (wielkich lub małych liter) i użycie znacznika niewrażliwego na wielkość liter. Uwaga : niektóre języki nie mają takiego, więc użyj dłuższego powyżej. Każdy język implementuje flagę case-niewrażliwości inaczej.
^([A-Z][A-HJ-Y]?[0-9][A-Z0-9]? ?[0-9][A-Z]{2}|GIR ?0A{2})$
Shorter ponownie zamieniając [0-9] na \d (jeśli twój silnik regex go obsługuje):
^([A-Z][A-HJ-Y]?\d[A-Z\d]? ?\d[A-Z]{2}|GIR ?0A{2})$
2. Uproszczone Wzory
Bez zapewnienia określonych znaków alfabetycznych można użyć następujących znaków (należy pamiętać o uproszczeniu z 1. W tym miejscu stosuje się również regex rządu brytyjskiego ([73]}):
^([A-Z]{1,2}\d[A-Z\d]? ?\d[A-Z]{2}|GIR ?0A{2})$
GIR 0AA:
^[A-Z]{1,2}\d[A-Z\d]? ?\d[A-Z]{2}$
3. Skomplikowane Wzory
Nie sugerowałbym nadmiernej weryfikacji kodu pocztowego jako nowych obszarów, dzielnic i Podokręgi mogą pojawić się w dowolnym momencie. To, co proponuję potencjalnie robi, jest dodane wsparcie dla edge-cases. Niektóre szczególne przypadki istnieją i są opisane w w tym artykule Wikipedii.
Oto złożone wyrażenia regularne zawierające podrozdziały 3. (3.1, 3.2, 3.3).
W stosunku do wzorców w 1. W związku z tym, że nie jest to możliwe, nie jest to możliwe.]}
Oraz w odniesieniu do 2. Wzory Uproszczone : ^(([A-Z][A-HJ-Y]?\d[A-Z\d]?|ASCN|STHL|TDCU|BBND|[BFS]IQQ|PCRN|TKCA) ?\d[A-Z]{2}|BFPO ?\d{1,4}|(KY\d|MSR|VG|AI)[ -]?\d{4}|[A-Z]{2} ?\d{2}|GE ?CX|GIR ?0A{2}|SAN ?TA1)$
3.1 Brytyjskie Terytoria Zamorskie]}
[[67]}artykuł Wikipedii obecnie stwierdza (niektóre formaty nieco uproszczone): ^(([A-Z]{1,2}\d[A-Z\d]?|ASCN|STHL|TDCU|BBND|[BFS]IQQ|PCRN|TKCA) ?\d[A-Z]{2}|BFPO ?\d{1,4}|(KY\d|MSR|VG|AI)[ -]?\d{4}|[A-Z]{2} ?\d{2}|GE ?CX|GIR ?0A{2}|SAN ?TA1)$
-
AI-1111: Anguila -
ASCN 1ZZ: Wyspa Wniebowstąpienia -
STHL 1ZZ: Święta Helena -
TDCU 1ZZ: Tristan da Cunha -
BBND 1ZZ: Brytyjskie Terytorium Oceanu Indyjskiego -
BIQQ 1ZZ: Brytyjskie Terytorium Antarktyczne -
FIQQ 1ZZ: Falklandy -
GX11 1ZZ: Gibraltar -
PCRN 1ZZ: Wyspy Pitcairn -
SIQQ 1ZZ: Georgia Południowa i Sandwich Południowy -
TKCA 1ZZ: Wyspy Turks i Caicos -
BFPO 11: Akrotiri i Dhekelia -
ZZ 11&GE CX: Bermudy (według tego dokumentu) -
KY1-1111: Kajmany (zgodnie z ten dokument) -
VG1111: Brytyjskie Wyspy Dziewicze (według to dokument ) -
MSR 1111: Montserrat (zgodnie z ten dokument )
Uniwersalny regex pasujący tylko do brytyjskich terytoriów zamorskich może wyglądać tak:
^((ASCN|STHL|TDCU|BBND|[BFS]IQQ|GX\d{2}|PCRN|TKCA) ?\d[A-Z]{2}|(KY\d|MSR|VG|AI)[ -]?\d{4}|(BFPO|[A-Z]{2}) ?\d{2}|GE ?CX)$
3.2 Poczta Sił Brytyjskich
Chociaż zostały one ostatnio zmienione, aby lepiej dostosować się do brytyjskiego systemu kodów pocztowych do BF# (gdzie # reprezentuje liczbę), są one uważane za opcjonalne alternatywne kody pocztowe . W 2011 roku w ramach programu "Horyzont 2020" w ramach programu Horyzont 2020 w ramach programu Horyzont 2020 "Horyzont 2020" zrealizowano]}
^BFPO ?\d{1,4}$
3.3 Mikołaj?
Jest jeszcze jeden specjalny przypadek z Mikołajem (jak wspomniano w innych odpowiedziach): SAN TA1 to ważny kod pocztowy. Jest to bardzo proste:
^SAN ?TA1$
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-10-04 14:11:22
Wygląda na to, że będziemy używać ^(GIR ?0AA|[A-PR-UWYZ]([0-9]{1,2}|([A-HK-Y][0-9]([0-9ABEHMNPRV-Y])?)|[0-9][A-HJKPS-UW]) ?[0-9][ABD-HJLNP-UW-Z]{2})$, która jest nieco zmodyfikowaną wersją tego sugested przez minglis powyżej.
Będziemy jednak musieli dokładnie zbadać, jakie są zasady, ponieważ różne rozwiązania wymienione powyżej wydają się stosować różne zasady, które litery są dozwolone.
Po pewnych badaniach, znaleźliśmy więcej informacji. Widocznie strona na "govtalk.gov.uk" wskazuje na specyfikację kodu pocztowego govtalk-kody pocztowe . Wskazuje to na XML schema at XML Schema, który dostarcza 'pseudo regex' instrukcji reguł kodu pocztowego.
Wzięliśmy to i trochę nad tym pracowaliśmy, aby dać nam następujące wyrażenie:
^((GIR &0AA)|((([A-PR-UWYZ][A-HK-Y]?[0-9][0-9]?)|(([A-PR-UWYZ][0-9][A-HJKSTUW])|([A-PR-UWYZ][A-HK-Y][0-9][ABEHMNPRV-Y]))) &[0-9][ABD-HJLNP-UW-Z]{2}))$
To czyni spacje opcjonalnymi, ale ogranicza cię do jednej spacji (zastąp ' & 'na' {0,} dla nieograniczonej liczby spacji). Zakłada, że cały tekst musi być pisany wielkimi literami.
Jeśli chcesz zezwolić na małe litery, z dowolną liczbą spacji, użyj:
^(([gG][iI][rR] {0,}0[aA]{2})|((([a-pr-uwyzA-PR-UWYZ][a-hk-yA-HK-Y]?[0-9][0-9]?)|(([a-pr-uwyzA-PR-UWYZ][0-9][a-hjkstuwA-HJKSTUW])|([a-pr-uwyzA-PR-UWYZ][a-hk-yA-HK-Y][0-9][abehmnprv-yABEHMNPRV-Y]))) {0,}[0-9][abd-hjlnp-uw-zABD-HJLNP-UW-Z]{2}))$
Może przyjmować następujące formaty:
- "GIR 0AA"
- A9 9ZZ
- A99 9ZZ
- AB9 9ZZ
- AB99 9ZZ
- A9C 9ZZ
- AD9E 9ZZ
Gdzie:
- 9 może być dowolną liczbą jednocyfrową.
- A może być dowolną literą z wyjątkiem Q, V lub X.
- B może być dowolną literą z wyjątkiem I, J lub Z.
- C może być dowolną literą z wyjątkiem I, L, M, N, O, P, Q, R, V, X, Y lub Z.
- D może być dowolną literą z wyjątkiem I, J lub Z.
- E może być dowolnym z A, B, E, H, M, N, P, R, V, W, X lub Y.
- Z może być dowolną literą z wyjątkiem C, i, K, M, O lub V.
Najlepsze życzenia
Colin
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-10-16 12:13:21
Nie ma czegoś takiego jak kompleksowe Wyrażenie regularne kodu pocztowego w Wielkiej Brytanii, które jest zdolne do walidacji kodu pocztowego. Możesz sprawdzić, czy kod pocztowy jest w odpowiednim formacie za pomocą wyrażenia regularnego; nie, że w rzeczywistości istnieje.
Kody Pocztowe są arbitralnie złożone i stale się zmieniają. Na przykład, outcode W1 nie ma i nigdy nie może mieć każdej liczby od 1 do 99 dla każdego obszaru kodu pocztowego.
Nie można oczekiwać, że to, co obecnie jest prawdą na zawsze. Na przykład, w 1990 roku, Poczta zdecydowała, że Aberdeen robi się trochę tłoczno. Dodali 0 do końca AB1-5, co czyni go AB10-50, a następnie utworzyli kilka kodów pocztowych pomiędzy nimi.
Gdy budowana jest nowa ulica, tworzony jest nowy kod pocztowy. Jest to część procesu uzyskiwania pozwolenia na budowę; władze lokalne są zobowiązane do tego, aby na bieżąco informować pocztę(nie, że wszystkie robią).
Ponadto, jak zauważyło wielu innych użytkowników, są specjalne kody pocztowe, takie jak Girobank, GIR 0AA, i jeden do listów do Mikołaja, SAN TA1-prawdopodobnie nie chcesz tam nic pisać, ale wydaje się, że nie są objęte żadną inną odpowiedzią.
Potem są kody pocztowe BFPO, które teraz zmieniają się na bardziej standardowy format . Oba formaty będą ważne. Są też terytoria zamorskieźródło Wikipedia.
+----------+----------------------------------------------+ | Postcode | Location | +----------+----------------------------------------------+ | AI-2640 | Anguilla | | ASCN 1ZZ | Ascension Island | | STHL 1ZZ | Saint Helena | | TDCU 1ZZ | Tristan da Cunha | | BBND 1ZZ | British Indian Ocean Territory | | BIQQ 1ZZ | British Antarctic Territory | | FIQQ 1ZZ | Falkland Islands | | GX11 1AA | Gibraltar | | PCRN 1ZZ | Pitcairn Islands | | SIQQ 1ZZ | South Georgia and the South Sandwich Islands | | TKCA 1ZZ | Turks and Caicos Islands | +----------+----------------------------------------------+
Następnie należy wziąć pod uwagę, że Wielka Brytania "wyeksportował" swój system kodów pocztowych do wielu miejsc na świecie. Wszystko, co potwierdza Kod Pocztowy" UK " będzie również sprawdzać kody pocztowe wielu innych krajów.
Jeśli chcesz zweryfikować Kod Pocztowy w Wielkiej Brytanii, najbezpieczniejszym sposobem na to jest skorzystanie z wyszukiwania aktualnych kodów pocztowych. Istnieje wiele opcji:
Ordnance Survey uwalnia Code-Point Open na licencji open data. Będzie trochę za późno, ale jest za darmo. To będzie (prawdopodobnie-nie pamiętam) nie zawierają danych Północnoirlandzkich, ponieważ sondaż Ordnance nie ma tam kompetencji. [33]} Pointer produkt. Możesz tego użyć i dołączyć kilka, które nie są dość łatwo objęte.
Royal Mail uwalnia Postcode address File (PAF) , obejmuje to BFPO, które nie jestem pewien, czy Open code-Point robi. Jest zaktualizowany regularnie, ale kosztuje (i mogą być wręcz złośliwe o tym czasami). PAF zawiera pełny adres, a nie tylko kody pocztowe i jest dostarczany z własnym przewodnikiem programistów {16]}. Open Data User Group (Odug) obecnie lobbuje, aby PAF był udostępniany za darmo, oto opis ich pozycji.
Na koniec jest baza adresów. Jest to współpraca Ordnance Survey, władz lokalnych, Royal Mail i firmy dopasowującej do stwórz definitywny katalog wszystkich informacji o wszystkich adresach w Wielkiej Brytanii(również odniosły one dość duży sukces). Jest płatny, ale jeśli pracujesz z władzami lokalnymi, Departamentem rządowym lub usługą rządową, korzystanie z niego jest bezpłatne. Jest o wiele więcej informacji niż tylko kody pocztowe zawarte.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-10-17 08:25:13
Przyjrzałem się niektórym z powyższych odpowiedzi i polecam nie używać wzorca z odpowiedzi @dana (c. Dec 15 '10), ponieważ błędnie oznacza prawie 0,4% ważnych kodów pocztowych jako nieważne, podczas gdy inne nie.
Ordnance Survey zapewnia usługę o nazwie Code Point Open, która:
Zawiera listę wszystkich aktualnych kodów pocztowych w Wielkiej Brytanii
Porównałem wszystkie powyższe wyrażenia regularne z pełną listą kodów pocztowych (Jul 6 '13) z tych danych za pomocą grep:
cat CSV/*.csv |
# Strip leading quotes
sed -e 's/^"//g' |
# Strip trailing quote and everything after it
sed -e 's/".*//g' |
# Strip any spaces
sed -E -e 's/ +//g' |
# Find any lines that do not match the expression
grep --invert-match --perl-regexp "$pattern"
Istnieje 1,686,202 kody pocztowe ogółem.
Poniżej znajdują się numery ważnych kodów pocztowych, które nie pasują do do każdego $pattern:
'^([A-PR-UWYZ0-9][A-HK-Y0-9][AEHMNPRTVXY0-9]?[ABEHMNPRVWXY0-9]?[0-9][ABD-HJLN-UW-Z]{2}|GIR 0AA)$'
# => 6016 (0.36%)
'^(GIR ?0AA|[A-PR-UWYZ]([0-9]{1,2}|([A-HK-Y][0-9]([0-9ABEHMNPRV-Y])?)|[0-9][A-HJKPS-UW]) ?[0-9][ABD-HJLNP-UW-Z]{2})$'
# => 0
'^GIR[ ]?0AA|((AB|AL|B|BA|BB|BD|BH|BL|BN|BR|BS|BT|BX|CA|CB|CF|CH|CM|CO|CR|CT|CV|CW|DA|DD|DE|DG|DH|DL|DN|DT|DY|E|EC|EH|EN|EX|FK|FY|G|GL|GY|GU|HA|HD|HG|HP|HR|HS|HU|HX|IG|IM|IP|IV|JE|KA|KT|KW|KY|L|LA|LD|LE|LL|LN|LS|LU|M|ME|MK|ML|N|NE|NG|NN|NP|NR|NW|OL|OX|PA|PE|PH|PL|PO|PR|RG|RH|RM|S|SA|SE|SG|SK|SL|SM|SN|SO|SP|SR|SS|ST|SW|SY|TA|TD|TF|TN|TQ|TR|TS|TW|UB|W|WA|WC|WD|WF|WN|WR|WS|WV|YO|ZE)(\d[\dA-Z]?[ ]?\d[ABD-HJLN-UW-Z]{2}))|BFPO[ ]?\d{1,4}$'
# => 0
Oczywiście te wyniki dotyczą tylko ważnych kodów pocztowych, które są nieprawidłowo oznaczone jako nieważne. Więc:
'^.*$'
# => 0
Nie mówię nic o tym, który wzór jest najlepszy, jeśli chodzi o filtrowanie nieprawidłowych kodów pocztowych.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-23 12:02:51
^([A-PR-UWYZ0-9][A-HK-Y0-9][AEHMNPRTVXY0-9]?[ABEHMNPRVWXY0-9]? {1,2}[0-9][ABD-HJLN-UW-Z]{2}|GIR 0AA)$
Wyrażenie regularne pasujące do poprawnego UK kody pocztowe. W brytyjskim systemie pocztowym nie wszystkie litery są używane we wszystkich pozycjach (to samo z rejestracją pojazdu płyty) i istnieją różne zasady, aby Zarządzaj tym. Ten regex przyjmuje do rozlicz się z tymi zasadami. Szczegóły dotyczące Zasady: Pierwsza połowa kodu pocztowego ważna formaty [A-Z][A-Z][0-9] [A-Z] [A-Z] [A-Z] [0-9] [0-9] [A-Z] [0-9] [0-9] [A-Z] [A-Z] [0-9] [A-Z] [A-Z][A-Z] [A-Z] [0-9] [A-Z] [A-Z] [0-9] Pozycja-Pierwsza. Contraint-QVX not używana pozycja-druga. Contraint - IJZ Nie stosowany z wyjątkiem gir 0AA Pozycja-Trzecia. Ograniczenie - AEHMNPRTVXY używana tylko pozycja - Naprzód. Contraint-ABEHMNPRVWXY Second połowa ważnych formatów kodów pocztowych [0-9] [A-Z] [A-Z] Pozycja WYJĄTKÓW - Drugi i trzeci. Contraint-CIKMOV nie używane
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-12-15 17:27:07
Według tej tabeli Wikipedii
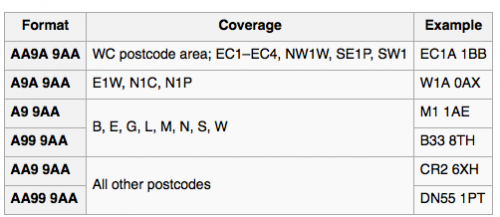
Ten wzór obejmuje wszystkie przypadki
(?:[A-Za-z]\d ?\d[A-Za-z]{2})|(?:[A-Za-z][A-Za-z\d]\d ?\d[A-Za-z]{2})|(?:[A-Za-z]{2}\d{2} ?\d[A-Za-z]{2})|(?:[A-Za-z]\d[A-Za-z] ?\d[A-Za-z]{2})|(?:[A-Za-z]{2}\d[A-Za-z] ?\d[A-Za-z]{2})
Gdy używasz go na Androidzie \ Java użyj \ \ D
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-04-23 10:07:34
Większość odpowiedzi tutaj nie działa dla wszystkich kodów pocztowych mam w bazie danych. W końcu znalazłem taki, który sprawdza się ze wszystkimi, używając nowego wyrażenia regularnego dostarczonego przez rząd:
Nie ma go w żadnej z poprzednich odpowiedzi, więc zamieszczam go tutaj na wypadek, gdyby ktoś usunął link:
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([A-Za-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2})$
UPDATE: Updated regex as wskazywany przez Jamiego Bulla. Nie wiem, czy to był mój błąd kopiowania lub to był błąd w regex rządu, link jest teraz w dół...
UPDATE: jak znaleziono ctwheels, to wyrażenie regularne działa ze smakiem JavaScript regex. Zobacz jego komentarz dla jednego, który działa z pcre (php) smak.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-08-14 11:11:43
Stary post, ale wciąż dość wysoki w wynikach google, więc pomyślałem, że zaktualizuję. Ten dokument z 14 października definiuje Wyrażenie regularne kodu pocztowego UK jako:
^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([**AZ**a-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) [0-9][A-Za-z]{2})$
From:
Dokument wyjaśnia również logikę stojącą za nim. Jednak ma błąd (pogrubiony), a także dopuszcza małe litery, które choć prawne nie jest zwykle, tak zmieniony wersja:
^(GIR 0AA)|((([A-Z][0-9]{1,2})|(([A-Z][A-HJ-Y][0-9]{1,2})|(([A-Z][0-9][A-Z])|([A-Z][A-HJ-Y][0-9]?[A-Z])))) [0-9][A-Z]{2})$
To działa z nowymi kodami pocztowymi Londynu (np. W1D 5LH), których poprzednie wersje nie miały.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-05-09 10:13:08
To jest regex Google serwuje na ich i18napis.appspot.com domena:
GIR[ ]?0AA|((AB|AL|B|BA|BB|BD|BH|BL|BN|BR|BS|BT|BX|CA|CB|CF|CH|CM|CO|CR|CT|CV|CW|DA|DD|DE|DG|DH|DL|DN|DT|DY|E|EC|EH|EN|EX|FK|FY|G|GL|GY|GU|HA|HD|HG|HP|HR|HS|HU|HX|IG|IM|IP|IV|JE|KA|KT|KW|KY|L|LA|LD|LE|LL|LN|LS|LU|M|ME|MK|ML|N|NE|NG|NN|NP|NR|NW|OL|OX|PA|PE|PH|PL|PO|PR|RG|RH|RM|S|SA|SE|SG|SK|SL|SM|SN|SO|SP|SR|SS|ST|SW|SY|TA|TD|TF|TN|TQ|TR|TS|TW|UB|W|WA|WC|WD|WF|WN|WR|WS|WV|YO|ZE)(\d[\dA-Z]?[ ]?\d[ABD-HJLN-UW-Z]{2}))|BFPO[ ]?\d{1,4}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-04-11 15:44:09
Kody pocztowe mogą ulec zmianie, a jedynym prawdziwym sposobem potwierdzenia kodu pocztowego jest posiadanie pełnej listy kodów pocztowych i sprawdzenie, czy tam jest.
Ale wyrażenia regularne są przydatne, ponieważ:
- są łatwe w użyciu i wdrożeniu
- są krótkie
- są szybkie do uruchomienia Są dość łatwe w utrzymaniu (w porównaniu z pełną listą kodów pocztowych)
- nadal wyłapuje większość błędów wejściowych
Ale wyrażenia regularne są trudne do utrzymania, zwłaszcza dla kogoś, kto na to nie wpadł. Więc musi być:
- tak łatwe do zrozumienia, jak to możliwe
- relatywnie przyszłościowy
Oznacza to, że większość wyrażeń regularnych w tej odpowiedzi nie jest wystarczająco dobra. Np. widzę, że [A-PR-UWYZ][A-HK-Y][0-9][ABEHMNPRV-Y] będzie pasować do obszaru kodu pocztowego formularza AA1A - ale będzie to ból w szyi, jeśli i kiedy zostanie dodany nowy obszar kodu pocztowego, ponieważ trudno zrozumieć, które obszary kodu pocztowego to zapałki.
Chcę również, aby moje Wyrażenie regularne pasowało do pierwszej i drugiej połowy kodu pocztowego w nawiasach.
Więc wymyśliłem to:
(GIR(?=\s*0AA)|(?:[BEGLMNSW]|[A-Z]{2})[0-9](?:[0-9]|(?<=N1|E1|SE1|SW1|W1|NW1|EC[0-9]|WC[0-9])[A-HJ-NP-Z])?)\s*([0-9][ABD-HJLNP-UW-Z]{2})
W formacie PCRE można go zapisać w następujący sposób:
/^
( GIR(?=\s*0AA) # Match the special postcode "GIR 0AA"
|
(?:
[BEGLMNSW] | # There are 8 single-letter postcode areas
[A-Z]{2} # All other postcode areas have two letters
)
[0-9] # There is always at least one number after the postcode area
(?:
[0-9] # And an optional extra number
|
# Only certain postcode areas can have an extra letter after the number
(?<=N1|E1|SE1|SW1|W1|NW1|EC[0-9]|WC[0-9])
[A-HJ-NP-Z] # Possible letters here may change, but [IO] will never be used
)?
)
\s*
([0-9][ABD-HJLNP-UW-Z]{2}) # The last two letters cannot be [CIKMOV]
$/x
Dla mnie jest to właściwa równowaga między walidacją w jak największym stopniu, a jednocześnie przyszłościową i umożliwiającą łatwą konserwację.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-04-29 21:52:50
Szukałem regex kodu pocztowego w Wielkiej Brytanii przez ostatni dzień lub tak i natknąłem się na ten wątek. Przepracowałem większość powyższych sugestii i żaden z nich nie pracował dla mnie, więc wymyśliłem swój własny regex, który, o ile wiem, rejestruje wszystkie ważne kody pocztowe w Wielkiej Brytanii od stycznia ' 13(zgodnie z najnowszą literaturą z Royal Mail).
Regex i kilka prostych kodów pocztowych sprawdzanie kodu PHP jest zamieszczony poniżej. Uwaga: - pozwala na dolne lub wielkie kody pocztowe i GIR 0AA anomalia ale aby poradzić sobie z, bardziej niż prawdopodobne, obecność spacji w środku wprowadzonego kodu pocztowego, również korzysta z prostego str_replace, aby usunąć spację przed testowaniem przeciwko regex. Wszelkie rozbieżności poza tym, a sama Royal Mail nawet nie wspomina o nich w swojej literaturze (Zobacz http://www.royalmail.com/sites/default/files/docs/pdf/programmers_guide_edition_7_v5.pdf i zacznij czytać od strony 17)!
Note: In The Royal Mail ' s own Literatura (link powyżej) istnieje niewielka dwuznaczność wokół 3. i 4. pozycji i wyjątków, jeśli te znaki są literami. Skontaktowalem sie z Royal Mail bezposrednio, aby go wyczyscic i w ich wlasnych slowach " litera w 4 pozycji kodu zewnetrznego z formatem Aana NAA nie ma wyjatków, a 3 pozycje wyjątki dotycza tylko ostatniej litery kodu zewnetrznego z formatem ANA Naa."Prosto z paszczy konia!
<?php
$postcoderegex = '/^([g][i][r][0][a][a])$|^((([a-pr-uwyz]{1}([0]|[1-9]\d?))|([a-pr-uwyz]{1}[a-hk-y]{1}([0]|[1-9]\d?))|([a-pr-uwyz]{1}[1-9][a-hjkps-uw]{1})|([a-pr-uwyz]{1}[a-hk-y]{1}[1-9][a-z]{1}))(\d[abd-hjlnp-uw-z]{2})?)$/i';
$postcode2check = str_replace(' ','',$postcode2check);
if (preg_match($postcoderegex, $postcode2check)) {
echo "$postcode2check is a valid postcode<br>";
} else {
echo "$postcode2check is not a valid postcode<br>";
}
?>
Mam nadzieję, że to pomoże każdemu else kto natrafia na ten wątek szukając rozwiązania.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-08-22 16:37:29
Oto regex oparty na formacie określonym w dokumentach, które są powiązane z odpowiedzią marcj:
/^[A-Z]{1,2}[0-9][0-9A-Z]? ?[0-9][A-Z]{2}$/
Jedyną różnicą między tym a specyfikacją jest to, że ostatnie 2 znaki nie mogą być w [CIKMOV] zgodnie ze specyfikacją.
Edytuj: Oto kolejna wersja, która testuje ograniczenia znaków końcowych.
/^[A-Z]{1,2}[0-9][0-9A-Z]? ?[0-9][A-BD-HJLNP-UW-Z]{2}$/
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-07-30 12:33:43
Niektóre z powyższych wyrażeń regularnych są nieco restrykcyjne. Zwróć uwagę na oryginalny kod Pocztowy: "W1K 7AA" zawiedzie, biorąc pod uwagę regułę "Pozycja 3-AEHMNPRTVXY używana tylko" powyżej jako " K " zostanie wykluczona.
Regex:
^(GIR 0AA|[A-PR-UWYZ]([0-9]{1,2}|([A-HK-Y][0-9]|[A-HK-Y][0-9]([0-9]|[ABEHMNPRV-Y]))|[0-9][A-HJKPS-UW])[0-9][ABD-HJLNP-UW-Z]{2})$
Wydaje się być trochę dokładniejsze, patrz artykuł Wikipedia zatytułowany "kody pocztowe w Wielkiej Brytanii" .
Zauważ, że to wyrażenie regularne wymaga tylko wielkich znaków.
Większe pytanie brzmi, czy ograniczasz dane wejściowe użytkownika, aby zezwalać tylko kody pocztowe, które faktycznie istnieją lub czy po prostu starasz się uniemożliwić użytkownikom wprowadzanie kompletnych śmieci do pól formularza. Poprawne dopasowanie każdego możliwego kodu pocztowego i jego przyszłościowe poprawienie jest trudniejszą zagadką i prawdopodobnie nie warto, chyba że jesteś w błędzie.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-07-01 14:53:13
Oto jak radzimy sobie z problemem kodów pocztowych w Wielkiej Brytanii:
^([A-Za-z]{1,2}[0-9]{1,2}[A-Za-z]?[ ]?)([0-9]{1}[A-Za-z]{2})$
Explanation:
- spodziewaj się 1 lub 2 znaków a-z, górnej lub dolnej grzywny
- spodziewaj się 1 lub 2 liczb
- oczekiwać 0 LUB 1 A-z char, górnej lub dolnej grzywny
- opcjonalna przestrzeń dozwolona
- spodziewaj się 1 liczby
- spodziewaj się 2 a-z, górnej lub dolnej grzywny
To dostaje większość formatów, następnie używamy db, aby sprawdzić, czy kod pocztowy jest rzeczywiście prawdziwy, dane te są napędzane przez openpoint https://www.ordnancesurvey.co.uk/opendatadownload/products.html
Hope this helps
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-12-24 10:35:39
Podstawowe zasady:
^[A-Z]{1,2}[0-9R][0-9A-Z]? [0-9][ABD-HJLNP-UW-Z]{2}$
Pełne Zasady:
Jeśli potrzebujesz wyrażenia regularnego, które zaznacza wszystkie pola dla reguł kodu pocztowego w koszt czytelności, proszę bardzo:
^(?:(?:[A-PR-UWYZ][0-9]{1,2}|[A-PR-UWYZ][A-HK-Y][0-9]{1,2}|[A-PR-UWYZ][0-9][A-HJKSTUW]|[A-PR-UWYZ][A-HK-Y][0-9][ABEHMNPRV-Y]) [0-9][ABD-HJLNP-UW-Z]{2}|GIR 0AA)$
Przetestowane na bazie naszych klientów i wydaje się idealnie dokładne.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-01-26 18:13:46
Używam następujących regex, które przetestowałem na wszystkich ważnych kodów pocztowych w Wielkiej Brytanii. Jest on oparty na zalecanych regułach, ale skondensowany na tyle, na ile jest rozsądny i nie używa żadnych specjalnych reguł regex specyficznych dla języka.
([A-PR-UWYZ]([A-HK-Y][0-9]([0-9]|[ABEHMNPRV-Y])?|[0-9]([0-9]|[A-HJKPSTUW])?) ?[0-9][ABD-HJLNP-UW-Z]{2})
Zakłada, że kod pocztowy został przekonwertowany na wielkie litery i nie ma znaków początkowych ani końcowych, ale akceptuje opcjonalną spację między kodem wyjściowym i kodem incode.
Specjalny kod pocztowy "GIR0 0AA" jest wykluczony i nie będzie sprawdzany jako nie ma go na oficjalnej liście kodów pocztowych i z tego co mi wiadomo nie będzie używany jako zarejestrowany adres. Dodanie go powinno być trywialne jako szczególny przypadek, jeśli jest to wymagane.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-11-09 14:03:46
Chciałem prostego wyrażenia regularnego, gdzie można pozwolić na zbyt wiele, ale nie zaprzeczać poprawnemu kodowi pocztowemu. Poszedłem z tym (wejście jest rozebrany / przycięty ciąg):
/^([a-z0-9]\s*){5,8}$/i
Pozwala to na najkrótsze możliwe kody pocztowe, takie jak "L1 8JQ", jak również najdłuższe, takie jak "OL14 5ET".
Ponieważ pozwala na maksymalnie 8 znaków, pozwala również na niepoprawne 8-znakowe kody pocztowe, jeśli nie ma spacji: "OL145ETX". Ale znowu, jest to uproszczone Wyrażenie regularne, gdy jest to wystarczająco dobre.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-01-09 11:42:14
Pierwsza połowa poprawnych formatów kodu pocztowego
- [A-Z] [A-Z][0-9] [A-Z]
- [A-Z] [A-Z][0-9][0-9]
- [A-Z][0-9][0-9]
- [A-Z] [A-Z] [0-9]
- [A-Z][A-Z][A-Z]
- [A-Z] [0-9] [A-Z]
- [A-Z] [0-9]
Wyjątki
Pozycja 1-QVX nie używany
Pozycja 2-IJZ nie używany z wyjątkiem GIR 0AA
Pozycja 3-AEHMNPRTVXY używane tylko
Pozycja 4-ABEHMNPRVWXY
Druga połowa kodu pocztowego
- [0-9] [A-Z][A-Z]
Wyjątki
Pozycja 2+3-cikmov nie używany
Pamiętaj, że nie wszystkie możliwe kody są używane, więc ta lista jest koniecznym, ale nie wystarczającym warunkiem poprawnego kodu. Może łatwiej będzie dopasować się do listy wszystkich ważnych kodów?
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2008-10-02 23:13:30
Aby sprawdzić kod pocztowy jest w prawidłowym formacie zgodnie z Royal Mail 's programmer' s guide :
|----------------------------outward code------------------------------| |------inward code-----|
#special↓ α1 α2 AAN AANA AANN AN ANN ANA (α3) N AA
^(GIR 0AA|[A-PR-UWYZ]([A-HK-Y]([0-9][A-Z]?|[1-9][0-9])|[1-9]([0-9]|[A-HJKPSTUW])?) [0-9][ABD-HJLNP-UW-Z]{2})$
Wszystkie kody pocztowe na doogal.co.uk mecz, z wyjątkiem tych, które już nie są używane.
Dodanie ? po spacji i użycie dopasowania bez rozróżniania wielkości liter, aby odpowiedzieć na to pytanie:
'se50eg'.match(/^(GIR 0AA|[A-PR-UWYZ]([A-HK-Y]([0-9][A-Z]?|[1-9][0-9])|[1-9]([0-9]|[A-HJKPSTUW])?) ?[0-9][ABD-HJLNP-UW-Z]{2})$/ig);
Array [ "se50eg" ]
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-03-27 13:44:37
Ten pozwala na puste spacje i tabulatory z obu stron w przypadku, gdy nie chcesz zawieść walidacji, a następnie przyciąć ją po stronie.
^\s*(([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([A-Za-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z])))) {0,1}[0-9][A-Za-z]{2})\s*$)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-01-04 14:41:22
Aby dodać do tej listy bardziej praktyczny regex, którego używam, który pozwala użytkownikowi wprowadzić empty string to:
^$|^(([gG][iI][rR] {0,}0[aA]{2})|((([a-pr-uwyzA-PR-UWYZ][a-hk-yA-HK-Y]?[0-9][0-9]?)|(([a-pr-uwyzA-PR-UWYZ][0-9][a-hjkstuwA-HJKSTUW])|([a-pr-uwyzA-PR-UWYZ][a-hk-yA-HK-Y][0-9][abehmnprv-yABEHMNPRV-Y]))) {0,1}[0-9][abd-hjlnp-uw-zABD-HJLNP-UW-Z]{2}))$
Ten regex pozwala na duże i małe litery z opcjonalnym spacją pomiędzy
Z punktu widzenia programistów ten regex jest przydatny dla oprogramowania, w którym adres może być opcjonalny. Na przykład, jeśli użytkownik nie chce podać swoich danych adresowych
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-09-23 09:57:44
Spójrz na kod Pythona na tej stronie:
Http://www.brunningonline.net/simon/blog/archives/001292.html
Mam do zrobienia parsowanie kodu pocztowego. Wymaganie jest dość proste; muszę przetworzyć kod pocztowy w outcode i (opcjonalnie) incode. Dobrą nowością jest to, że nie muszę wykonywać żadnej walidacji - po prostu muszę posiekać to, co mi dostarczono w sposób niejasno inteligentny. Nie mogę zakładać zbyt wiele o moim imporcie pod względem formatowania, czyli case i osadzone spacje. Ale to nie jest zła wiadomość; zła wiadomość jest taka, że muszę to wszystko robić w RPG. :-(
Niemniej jednak, rzuciłem małą funkcję Pythona, aby wyjaśnić moje myślenie.
Używałem go do przetwarzania kodów pocztowych dla mnie.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-06-20 09:12:55
Otrzymaliśmy spec:
UK postcodes must be in one of the following forms (with one exception, see below):
§ A9 9AA
§ A99 9AA
§ AA9 9AA
§ AA99 9AA
§ A9A 9AA
§ AA9A 9AA
where A represents an alphabetic character and 9 represents a numeric character.
Additional rules apply to alphabetic characters, as follows:
§ The character in position 1 may not be Q, V or X
§ The character in position 2 may not be I, J or Z
§ The character in position 3 may not be I, L, M, N, O, P, Q, R, V, X, Y or Z
§ The character in position 4 may not be C, D, F, G, I, J, K, L, O, Q, S, T, U or Z
§ The characters in the rightmost two positions may not be C, I, K, M, O or V
The one exception that does not follow these general rules is the postcode "GIR 0AA", which is a special valid postcode.
Wymyśliliśmy to:
/^([A-PR-UWYZ][A-HK-Y0-9](?:[A-HJKS-UW0-9][ABEHMNPRV-Y0-9]?)?\s*[0-9][ABD-HJLNP-UW-Z]{2}|GIR\s*0AA)$/i
Ale uwaga-pozwala to na dowolną liczbę spacji pomiędzy grupami.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-08-08 12:57:05
Mam regex do walidacji kodu pocztowego w Wielkiej Brytanii.
To działa dla wszystkich typów kodów pocztowych, zarówno wewnętrznych, jak i zewnętrznych
^((([A-PR-UWYZ][0-9])|([A-PR-UWYZ][0-9][0-9])|([A-PR-UWYZ][A-HK-Y][0-9])|([A-PR-UWYZ][A-HK-Y][0-9][0-9])|([A-PR-UWYZ][0-9][A-HJKSTUW])|([A-PR-UWYZ][A-HK-Y][0-9][ABEHMNPRVWXY]))) || ^((GIR)[ ]?(0AA))$|^(([A-PR-UWYZ][0-9])[ ]?([0-9][ABD-HJLNPQ-UW-Z]{0,2}))$|^(([A-PR-UWYZ][0-9][0-9])[ ]?([0-9][ABD-HJLNPQ-UW-Z]{0,2}))$|^(([A-PR-UWYZ][A-HK-Y0-9][0-9])[ ]?([0-9][ABD-HJLNPQ-UW-Z]{0,2}))$|^(([A-PR-UWYZ][A-HK-Y0-9][0-9][0-9])[ ]?([0-9][ABD-HJLNPQ-UW-Z]{0,2}))$|^(([A-PR-UWYZ][0-9][A-HJKS-UW0-9])[ ]?([0-9][ABD-HJLNPQ-UW-Z]{0,2}))$|^(([A-PR-UWYZ][A-HK-Y0-9][0-9][ABEHMNPRVWXY0-9])[ ]?([0-9][ABD-HJLNPQ-UW-Z]{0,2}))$
To działa dla wszystkich typów formatów.
Przykład:
AB10-------------------->TYLKO ZEWNĘTRZNY KOD POCZTOWY
A1 1AA------------------>połączenie (zewnętrznego i wewnętrznego) kodu pocztowego
WC2A-------------------->ZEWNĘTRZNE
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-10-20 01:59:11
Przyjęta odpowiedź odzwierciedla zasady podane przez Royal Mail, chociaż w regex jest literówka. Ta literówka chyba była tam na gov.uk strony jak również (tak jak znajduje się na stronie Archiwum XML).
W formacie A9A 9AA reguły dopuszczają znak P na trzeciej pozycji, podczas gdy regex uniemożliwia to. Poprawny regex to:
(GIR 0AA)|((([A-Z-[QVX]][0-9][0-9]?)|(([A-Z-[QVX]][A-Z-[IJZ]][0-9][0-9]?)|(([A-Z-[QVX]][0-9][A-HJKPSTUW])|([A-Z-[QVX]][A-Z-[IJZ]][0-9][ABEHMNPRVWXY])))) [0-9][A-Z-[CIKMOV]]{2})
Skrócenie tego powoduje następujące wyrażenia regularne (które używają składni Perl / Ruby):
(GIR 0AA)|([A-PR-UWYZ](([0-9]([0-9A-HJKPSTUW])?)|([A-HK-Y][0-9]([0-9ABEHMNPRVWXY])?))\s?[0-9][ABD-HJLNP-UW-Z]{2})
Zawiera również opcjonalny przestrzeń między pierwszym i drugim blokiem.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-03-31 08:00:40
To, co znalazłem w prawie wszystkich odmianach i regex z bulk transfer pdf i to, co jest na stronie Wikipedii jest to, specjalnie dla Wikipedii regex jest, musi być ^ po pierwszym / (pionowy pasek). Domyśliłem się tego testując AA9A 9AA, ponieważ w przeciwnym razie sprawdzanie formatu A9A 9AA potwierdzi to. Na przykład sprawdzanie EC1D 1BB, które powinno być nieprawidłowe, wraca poprawne, ponieważ C1D 1BB jest prawidłowym formatem.
Oto, co wymyśliłem dla dobry regex:
^([G][I][R] 0[A]{2})|^((([A-Z-[QVX]][0-9]{1,2})|([A-Z-[QVX]][A-HK-Y][0-9]{1,2})|([A-Z-[QVX]][0-9][ABCDEFGHJKPSTUW])|([A-Z-[QVX]][A-HK-Y][0-9][ABEHMNPRVWXY])) [0-9][A-Z-[CIKMOV]]{2})$
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-11-15 17:16:11
Poprzez empiryczne badania i obserwacje, a także potwierdzenie za pomocą https://en.wikipedia.org/wiki/Postcodes_in_the_United_Kingdom#Validation , Oto moja wersja wyrażenia regularnego Pythona, które poprawnie parsuje i waliduje kod pocztowy w Wielkiej Brytanii:
UK_POSTCODE_REGEX = r'(?P<postcode_area>[A-Z]{1,2})(?P<district>(?:[0-9]{1,2})|(?:[0-9][A-Z]))(?P<sector>[0-9])(?P<postcode>[A-Z]{2})'
Ten regex jest prosty i zawiera grupy przechwytywania. To Nie obejmuje wszystkie walidacje legalne Brytyjskie kody pocztowe, ale uwzględnia tylko litery vs pozycje liczbowe.
Oto jak ja użyje go w kodzie:
@dataclass
class UKPostcode:
postcode_area: str
district: str
sector: int
postcode: str
# https://en.wikipedia.org/wiki/Postcodes_in_the_United_Kingdom#Validation
# Original author of this regex: @jontsai
# NOTE TO FUTURE DEVELOPER:
# Verified through empirical testing and observation, as well as confirming with the Wiki article
# If this regex fails to capture all valid UK postcodes, then I apologize, for I am only human.
UK_POSTCODE_REGEX = r'(?P<postcode_area>[A-Z]{1,2})(?P<district>(?:[0-9]{1,2})|(?:[0-9][A-Z]))(?P<sector>[0-9])(?P<postcode>[A-Z]{2})'
@classmethod
def from_postcode(cls, postcode):
"""Parses a string into a UKPostcode
Returns a UKPostcode or None
"""
m = re.match(cls.UK_POSTCODE_REGEX, postcode.replace(' ', ''))
if m:
uk_postcode = UKPostcode(
postcode_area=m.group('postcode_area'),
district=m.group('district'),
sector=m.group('sector'),
postcode=m.group('postcode')
)
else:
uk_postcode = None
return uk_postcode
def parse_uk_postcode(postcode):
"""Wrapper for UKPostcode.from_postcode
"""
uk_postcode = UKPostcode.from_postcode(postcode)
return uk_postcode
Oto testy jednostkowe:
@pytest.mark.parametrize(
'postcode, expected', [
# https://en.wikipedia.org/wiki/Postcodes_in_the_United_Kingdom#Validation
(
'EC1A1BB',
UKPostcode(
postcode_area='EC',
district='1A',
sector='1',
postcode='BB'
),
),
(
'W1A0AX',
UKPostcode(
postcode_area='W',
district='1A',
sector='0',
postcode='AX'
),
),
(
'M11AE',
UKPostcode(
postcode_area='M',
district='1',
sector='1',
postcode='AE'
),
),
(
'B338TH',
UKPostcode(
postcode_area='B',
district='33',
sector='8',
postcode='TH'
)
),
(
'CR26XH',
UKPostcode(
postcode_area='CR',
district='2',
sector='6',
postcode='XH'
)
),
(
'DN551PT',
UKPostcode(
postcode_area='DN',
district='55',
sector='1',
postcode='PT'
)
)
]
)
def test_parse_uk_postcode(postcode, expected):
uk_postcode = parse_uk_postcode(postcode)
assert(uk_postcode == expected)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-04-25 18:03:11
Potrzebowałem wersji, która będzie działać w SAS z PRXMATCH i pokrewnymi funkcjami, więc wpadłem na to:
^[A-PR-UWYZ](([A-HK-Y]?\d\d?)|(\d[A-HJKPSTUW])|([A-HK-Y]\d[ABEHMNPRV-Y]))\s?\d[ABD-HJLNP-UW-Z]{2}$
Przypadki testowe i Uwagi:
/*
Notes
The letters QVX are not used in the 1st position.
The letters IJZ are not used in the second position.
The only letters to appear in the third position are ABCDEFGHJKPSTUW when the structure starts with A9A.
The only letters to appear in the fourth position are ABEHMNPRVWXY when the structure starts with AA9A.
The final two letters do not use the letters CIKMOV, so as not to resemble digits or each other when hand-written.
*/
/*
Bits and pieces
1st position (any): [A-PR-UWYZ]
2nd position (if letter): [A-HK-Y]
3rd position (A1A format): [A-HJKPSTUW]
4th position (AA1A format): [ABEHMNPRV-Y]
Last 2 positions: [ABD-HJLNP-UW-Z]
*/
data example;
infile cards truncover;
input valid 1. postcode &$10. Notes &$100.;
flag = prxmatch('/^[A-PR-UWYZ](([A-HK-Y]?\d\d?)|(\d[A-HJKPSTUW])|([A-HK-Y]\d[ABEHMNPRV-Y]))\s?\d[ABD-HJLNP-UW-Z]{2}$/',strip(postcode));
cards;
1 EC1A 1BB Special case 1
1 W1A 0AX Special case 2
1 M1 1AE Standard format
1 B33 8TH Standard format
1 CR2 6XH Standard format
1 DN55 1PT Standard format
0 QN55 1PT Bad letter in 1st position
0 DI55 1PT Bad letter in 2nd position
0 W1Z 0AX Bad letter in 3rd position
0 EC1Z 1BB Bad letter in 4th position
0 DN55 1CT Bad letter in 2nd group
0 A11A 1AA Invalid digits in 1st group
0 AA11A 1AA 1st group too long
0 AA11 1AAA 2nd group too long
0 AA11 1AAA 2nd group too long
0 AAA 1AA No digit in 1st group
0 AA 1AA No digit in 1st group
0 A 1AA No digit in 1st group
0 1A 1AA Missing letter in 1st group
0 1 1AA Missing letter in 1st group
0 11 1AA Missing letter in 1st group
0 AA1 1A Missing letter in 2nd group
0 AA1 1 Missing letter in 2nd group
;
run;
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-04 22:10:47
Poniżej metoda sprawdzi kod pocztowy i dostarczy pełne informacje
const valid_postcode = postcode => {
try {
postcode = postcode.replace(/\s/g, "");
const fromat = postcode
.toUpperCase()
.match(/^([A-Z]{1,2}\d{1,2}[A-Z]?)\s*(\d[A-Z]{2})$/);
const finalValue = `${fromat[1]} ${fromat[2]}`;
const regex = /^([Gg][Ii][Rr] 0[Aa]{2})|((([A-Za-z][0-9]{1,2})|(([A-Za-z][A-Ha-hJ-Yj-y][0-9]{1,2})|(([AZa-z][0-9][A-Za-z])|([A-Za-z][A-Ha-hJ-Yj-y][0-9]?[A-Za-z]))))[0-9][A-Za-z]{2})$/i;
return {
isValid: regex.test(postcode),
formatedPostCode: finalValue,
error: false,
info: 'It is a valid postcode'
};
} catch (error) {
return { error: true , info: 'Invalid post code has been entered!'};
}
};
valid_postcode('GU348RR')
result => {isValid: true, formatedPostCode: "GU34 8RR", error: false, info: "It is a valid postcode"}
valid_postcode('sdasd4746asd')
result => {error: true, info: "Invalid post code has been entered!"}
valid_postcode('787898523')
result => {error: true, info: "Invalid post code has been entered!"}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-03-09 23:30:00