Segmentacja obrazu z wykorzystaniem przesunięcia średniego
Czy ktoś mógłby mi pomóc zrozumieć, jak naprawdę działa segmentacja Mean Shift?
Oto matryca 8x8, którą właśnie wymyśliłem
103 103 103 103 103 103 106 104
103 147 147 153 147 156 153 104
107 153 153 153 153 153 153 107
103 153 147 96 98 153 153 104
107 156 153 97 96 147 153 107
103 153 153 147 156 153 153 101
103 156 153 147 147 153 153 104
103 103 107 104 103 106 103 107
Używając powyższej macierzy, czy jest możliwe wyjaśnienie, w jaki sposób segmentacja przesunięć średnich rozdzieliłaby 3 różne poziomy liczb?
2 answers
podstawy najpierw:
Średnia segmentacja przesunięć jest lokalną techniką homogenizacji, która jest bardzo przydatna do tłumienia cieniowania lub różnic tonalnych w zlokalizowanych obiektach. Przykład jest lepszy niż wiele słów:
Akcja: zastępuje każdy piksel średnią pikseli w okolicy range-r, której wartość znajduje się w odległości d.
Średnie przesunięcie zajmuje zwykle 3 wejścia:
- funkcja odległości dla pomiar odległości między pikselami. Zwykle odległość euklidesowa, ale każda inna dobrze zdefiniowana funkcja odległości może być użyta. Manhattan Odległość jest czasem innym przydatnym wyborem.
- promień. Wszystkie piksele w tym promieniu (mierzone zgodnie z powyższą odległością) zostaną uwzględnione w obliczeniach.
- różnica wartości. Ze wszystkich pikseli wewnątrz promienia r, do obliczenia średniej weźmiemy tylko te, których wartości mieszczą się w tej różnicy
Należy pamiętać, że algorytm nie jest dobrze zdefiniowany na granicach, więc różne implementacje dadzą różne wyniki.
Nie będę tutaj omawiać krwawych matematycznych szczegółów, ponieważ są one niemożliwe do pokazania bez odpowiedniej notacji matematycznej, niedostępnej w StackOverflow, a także dlatego, że można je znaleźć z dobrych źródeł gdzie indziej .
Spójrzmy na środek Twojej macierzy:
153 153 153 153
147 96 98 153
153 97 96 147
153 153 147 156
Z rozsądnym wyborem dla Promień i odległość, cztery środkowe piksele otrzymają wartość 97 (ich średnia) i będą różniły się od sąsiednich pikseli.
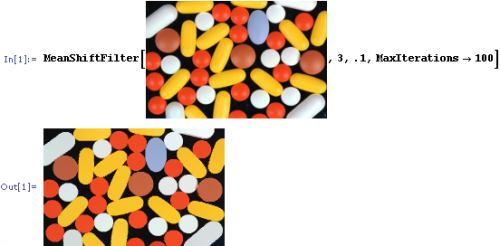
Obliczmy to w Mathematica . Zamiast pokazywać rzeczywiste liczby, wyświetlamy kodowanie kolorami, dzięki czemu łatwiej jest zrozumieć, co się dzieje: {]}
Kodowanie kolorów dla Twojej matrycy to:

Następnie przyjmujemy rozsądną średnią zmianę:
MeanShiftFilter[a, 3, 3]
I otrzymujemy:

Gdzie wszystkie elementy środkowe są równe (do 97, BTW).
Możesz powtarzać kilka razy ze średnią przesunięciem, starając się uzyskać bardziej jednorodne zabarwienie. Po kilku iteracjach dochodzi do stabilnej konfiguracji nie-izotropowej:

W tej chwili powinno być jasne, że nie możesz wybrać, ile" kolorów " otrzymasz po zastosowaniu Mean Shift. Pokażmy więc, jak to zrobić, bo to druga część twojego pytanie.
Aby móc z góry ustawić liczbę klastrów wyjściowych, musisz coś w rodzaju klastrów Kmeans.
Działa w ten sposób dla Twojej macierzy:
b = ClusteringComponents[a, 3]
{{1, 1, 1, 1, 1, 1, 1, 1},
{1, 2, 2, 3, 2, 3, 3, 1},
{1, 3, 3, 3, 3, 3, 3, 1},
{1, 3, 2, 1, 1, 3, 3, 1},
{1, 3, 3, 1, 1, 2, 3, 1},
{1, 3, 3, 2, 3, 3, 3, 1},
{1, 3, 3, 2, 2, 3, 3, 1},
{1, 1, 1, 1, 1, 1, 1, 1}}
Lub:

Który jest bardzo podobny do naszego poprzedniego wyniku, ale jak widać, teraz mamy tylko trzy poziomy wyjściowe.
HTH!Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-02-23 11:49:03
Segmentacja Mean-Shift działa mniej więcej tak:
Dane obrazu są konwertowane do przestrzeni funkcji
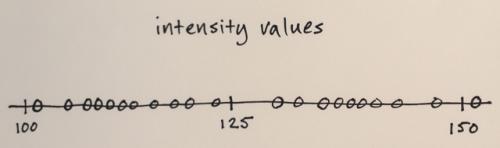
W Twoim przypadku wszystko, co masz, to wartości intensywności, więc przestrzeń funkcji będzie tylko jednowymiarowa. (Możesz na przykład obliczyć niektóre cechy tekstury, a następnie przestrzeń funkcji będzie dwuwymiarowa – i będziesz segmentować na podstawie intensywności i tekstury)
Okna wyszukiwania są rozmieszczone na funkcji przestrzeń
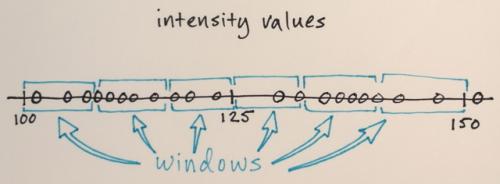
Liczba okien, rozmiar okna i początkowe lokalizacje są dowolne dla tego przykładu-coś, co może być dostrojone w zależności od konkretnych aplikacji
iteracje Mean-Shift:
1.) Środki próbek danych w każdym oknie są obliczane
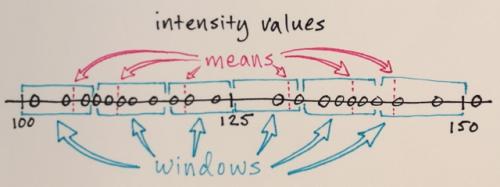
2.) Okna są przesunięte w miejsca równe ich wcześniej obliczonym środkom
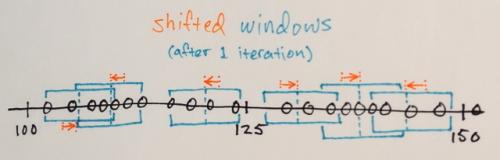
Kroki 1.) i 2.) są powtarzane aż zbieżność, tzn. wszystkie okna zostały osadzone na ostatecznych miejscach
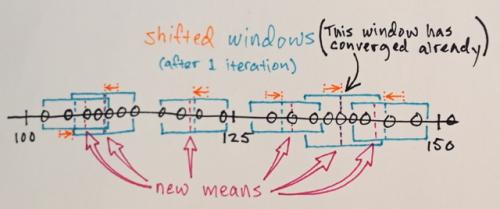
Okna, które kończą się w tych samych lokalizacjach, są scalane
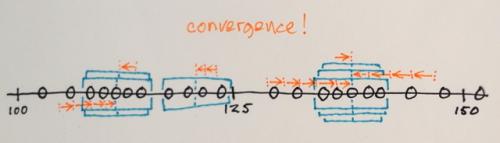
Dane są klastrowane zgodnie z window traversals
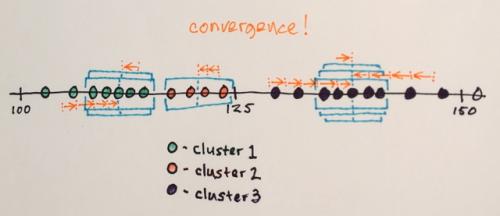
... na przykład wszystkie dane, które zostały przetransportowane przez okna, które wylądowały w, powiedzmy, lokalizacji "2", utworzą klaster powiązany z tą lokalizacją.
Tak więc ta segmentacja (przypadkowo) wytworzy trzy grupy. Przeglądając te grupy w oryginalny format obrazu może wyglądać jak [50]} ostatnie zdjęcie w odpowiedzi belisariusa. Wybór różnych rozmiarów okien i początkowych lokalizacji może przynieść różne wyniki.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-07-28 20:40:21