Jak znaleźć tryb statystyczny?
W R, mean() i median() są standardowymi funkcjami, które wykonują to, czego można się spodziewać. mode() mówi o wewnętrznym trybie przechowywania obiektu, a nie o wartości, która występuje najczęściej w jego argumencie. Ale czy istnieje standardowa funkcja biblioteczna, która implementuje tryb statystyczny dla wektora (lub listy)?
30 answers
Jeszcze jedno rozwiązanie, które działa zarówno dla danych liczbowych , jak i znaków / współczynników:
Mode <- function(x) {
ux <- unique(x)
ux[which.max(tabulate(match(x, ux)))]
}
Na mojej małej maszynie dinky, która może wygenerować i znaleźć tryb 10M-wektora całkowitego w około pół sekundy.
Jeśli zestaw danych może mieć wiele trybów, powyższe rozwiązanie przyjmuje takie samo podejście jak which.max i zwraca po raz pierwszy pojawiającą się wartość zestawu trybów. Aby zwrócić wszystkie tryby , użyj tego wariantu (od @ digEmAll w komentarzach):
Modes <- function(x) {
ux <- unique(x)
tab <- tabulate(match(x, ux))
ux[tab == max(tab)]
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-09-14 15:19:37
Istnieje Pakiet modeest, który dostarcza estymatorów trybu jednostkowych danych unimodalnych (a czasem multimodalnych) i wartości trybów zwykłych rozkładów prawdopodobieństwa.
mySamples <- c(19, 4, 5, 7, 29, 19, 29, 13, 25, 19)
library(modeest)
mlv(mySamples, method = "mfv")
Mode (most likely value): 19
Bickel's modal skewness: -0.1
Call: mlv.default(x = mySamples, method = "mfv")
Aby uzyskać więcej informacji zobacz ta strona
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-03-30 19:05:46
Znalazłem to na liście dyskusyjnej r, mam nadzieję, że to pomoże. I tak też o tym myślałem. Będziesz chciał tabelę () danych, posortować, a następnie wybrać imię. To hakerskie, ale powinno zadziałać.
names(sort(-table(x)))[1]
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-03-30 18:19:29
Uznałem post Kena Williamsa za świetny, dodałem kilka linii, aby uwzględnić wartości NA i zrobiłem z niego funkcję dla ułatwienia.
Mode <- function(x, na.rm = FALSE) {
if(na.rm){
x = x[!is.na(x)]
}
ux <- unique(x)
return(ux[which.max(tabulate(match(x, ux)))])
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-03-08 20:24:38
Szybki i brudny sposób szacowania trybu wektora liczb, który według Ciebie pochodzi z ciągłego rozkładu jednowymiarowego (np. rozkładu normalnego), definiuje i używa następującej funkcji:
estimate_mode <- function(x) {
d <- density(x)
d$x[which.max(d$y)]
}
Następnie, aby uzyskać oszacowanie trybu:
x <- c(5.8, 5.6, 6.2, 4.1, 4.9, 2.4, 3.9, 1.8, 5.7, 3.2)
estimate_mode(x)
## 5.439788
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-12-14 08:00:22
Następująca funkcja występuje w trzech formach:
Method = " mode "[default]: oblicza tryb dla wektora unimodalnego, w przeciwnym wypadku zwraca NA
method = "nmodes": oblicza liczbę trybów w wektorze
method = "modes": wyświetla wszystkie tryby dla wektora unimodalnego lub polimodalnego
modeav <- function (x, method = "mode", na.rm = FALSE)
{
x <- unlist(x)
if (na.rm)
x <- x[!is.na(x)]
u <- unique(x)
n <- length(u)
#get frequencies of each of the unique values in the vector
frequencies <- rep(0, n)
for (i in seq_len(n)) {
if (is.na(u[i])) {
frequencies[i] <- sum(is.na(x))
}
else {
frequencies[i] <- sum(x == u[i], na.rm = TRUE)
}
}
#mode if a unimodal vector, else NA
if (method == "mode" | is.na(method) | method == "")
{return(ifelse(length(frequencies[frequencies==max(frequencies)])>1,NA,u[which.max(frequencies)]))}
#number of modes
if(method == "nmode" | method == "nmodes")
{return(length(frequencies[frequencies==max(frequencies)]))}
#list of all modes
if (method == "modes" | method == "modevalues")
{return(u[which(frequencies==max(frequencies), arr.ind = FALSE, useNames = FALSE)])}
#error trap the method
warning("Warning: method not recognised. Valid methods are 'mode' [default], 'nmodes' and 'modes'")
return()
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-03-11 14:31:31
Tutaj inne rozwiązanie:
freq <- tapply(mySamples,mySamples,length)
#or freq <- table(mySamples)
as.numeric(names(freq)[which.max(freq)])
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-03-31 06:45:06
Nie mogę jeszcze głosować, ale odpowiedź Rasmusa Bååtha jest tym, czego szukałem. Chciałbym jednak nieco zmodyfikować, pozwalając na kontrastowanie rozkładu np. wartości fro tylko pomiędzy 0 a 1.
estimate_mode <- function(x,from=min(x), to=max(x)) {
d <- density(x, from=from, to=to)
d$x[which.max(d$y)]
}
Zdajemy sobie sprawę, że możesz nie chcieć ograniczać w ogóle swojej dystrybucji, następnie Ustaw od= - "duża liczba", do="duża liczba"
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-09-12 11:50:04
Mała modyfikacja odpowiedzi Kena Williamsa, dodanie opcjonalnych param na.rm i return_multiple.
W przeciwieństwie do odpowiedzi opartych na names(), Ta odpowiedź utrzymuje typ danych x w zwracanej wartości.
stat_mode <- function(x, return_multiple = TRUE, na.rm = FALSE) {
if(na.rm){
x <- na.omit(x)
}
ux <- unique(x)
freq <- tabulate(match(x, ux))
mode_loc <- if(return_multiple) which(freq==max(freq)) else which.max(freq)
return(ux[mode_loc])
}
Aby pokazać, że działa z opcjonalnymi params i utrzymuje typ danych:
foo <- c(2L, 2L, 3L, 4L, 4L, 5L, NA, NA)
bar <- c('mouse','mouse','dog','cat','cat','bird',NA,NA)
str(stat_mode(foo)) # int [1:3] 2 4 NA
str(stat_mode(bar)) # chr [1:3] "mouse" "cat" NA
str(stat_mode(bar, na.rm=T)) # chr [1:2] "mouse" "cat"
str(stat_mode(bar, return_mult=F, na.rm=T)) # chr "mouse"
Podziękowania dla @ Frank za uproszczenie.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-07-20 17:23:26
Napisałem następujący kod w celu wygenerowania trybu.
MODE <- function(dataframe){
DF <- as.data.frame(dataframe)
MODE2 <- function(x){
if (is.numeric(x) == FALSE){
df <- as.data.frame(table(x))
df <- df[order(df$Freq), ]
m <- max(df$Freq)
MODE1 <- as.vector(as.character(subset(df, Freq == m)[, 1]))
if (sum(df$Freq)/length(df$Freq)==1){
warning("No Mode: Frequency of all values is 1", call. = FALSE)
}else{
return(MODE1)
}
}else{
df <- as.data.frame(table(x))
df <- df[order(df$Freq), ]
m <- max(df$Freq)
MODE1 <- as.vector(as.numeric(as.character(subset(df, Freq == m)[, 1])))
if (sum(df$Freq)/length(df$Freq)==1){
warning("No Mode: Frequency of all values is 1", call. = FALSE)
}else{
return(MODE1)
}
}
}
return(as.vector(lapply(DF, MODE2)))
}
Spróbujmy:
MODE(mtcars)
MODE(CO2)
MODE(ToothGrowth)
MODE(InsectSprays)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-06-23 21:22:15
Na podstawie funkcji @ Chris do obliczania trybu lub powiązanych metryk, jednak przy użyciu metody Kena Williamsa do obliczania częstotliwości. Ten zapewnia poprawkę w przypadku braku trybów w ogóle (wszystkie elementy są jednakowo częste), oraz kilka bardziej czytelnych nazw method.
Mode <- function(x, method = "one", na.rm = FALSE) {
x <- unlist(x)
if (na.rm) {
x <- x[!is.na(x)]
}
# Get unique values
ux <- unique(x)
n <- length(ux)
# Get frequencies of all unique values
frequencies <- tabulate(match(x, ux))
modes <- frequencies == max(frequencies)
# Determine number of modes
nmodes <- sum(modes)
nmodes <- ifelse(nmodes==n, 0L, nmodes)
if (method %in% c("one", "mode", "") | is.na(method)) {
# Return NA if not exactly one mode, else return the mode
if (nmodes != 1) {
return(NA)
} else {
return(ux[which(modes)])
}
} else if (method %in% c("n", "nmodes")) {
# Return the number of modes
return(nmodes)
} else if (method %in% c("all", "modes")) {
# Return NA if no modes exist, else return all modes
if (nmodes > 0) {
return(ux[which(modes)])
} else {
return(NA)
}
}
warning("Warning: method not recognised. Valid methods are 'one'/'mode' [default], 'n'/'nmodes' and 'all'/'modes'")
}
Ponieważ wykorzystuje metodę Kena do obliczania częstotliwości, wydajność jest również zoptymalizowana, korzystając z postu Akseli, porównałem niektóre z poprzednich odpowiedzi, aby pokazać, jak moja funkcja jest bliska wydajności Kena, z warunków dla różnych opcji ouput powodujących tylko niewielkie koszty:

Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-06-29 11:32:02
Ten hack powinien działać dobrze. Podaje wartość oraz liczbę mode:
Mode <- function(x){
a = table(x) # x is a vector
return(a[which.max(a)])
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-09-13 07:01:34
R ma tak wiele pakietów dodatkowych, że niektóre z nich mogą zapewnić tryb [statystyczny] numerycznej listy/serii/wektora.
Jednak biblioteka standardowa R sama w sobie nie wydaje się mieć takiej wbudowanej metody! Jednym ze sposobów obejścia tego problemu jest użycie jakiegoś konstruktu podobnego do poniższego (i przekształcenie go w funkcję, jeśli używasz go często...):
mySamples <- c(19, 4, 5, 7, 29, 19, 29, 13, 25, 19)
tabSmpl<-tabulate(mySamples)
SmplMode<-which(tabSmpl== max(tabSmpl))
if(sum(tabSmpl == max(tabSmpl))>1) SmplMode<-NA
> SmplMode
[1] 19
Dla większej listy przykładowej należy rozważyć użycie zmiennej tymczasowej dla wartości max (tabSmpl) (Nie wiem, czy R automatycznie Optymalizuj to)
Odniesienie: Patrz " a co z medianą i modem?"w tym KickStarting r lesson
To wydaje się potwierdzać, że (przynajmniej w momencie pisania tej lekcji) nie ma funkcji mode W R (dobrze... mode () jak się dowiedziałeś służy do sprawdzania typu zmiennych).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-03-30 19:04:30
To działa całkiem dobrze
> a<-c(1,1,2,2,3,3,4,4,5)
> names(table(a))[table(a)==max(table(a))]
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-02-07 04:31:35
Oto funkcja do znalezienia trybu:
mode <- function(x) {
unique_val <- unique(x)
counts <- vector()
for (i in 1:length(unique_val)) {
counts[i] <- length(which(x==unique_val[i]))
}
position <- c(which(counts==max(counts)))
if (mean(counts)==max(counts))
mode_x <- 'Mode does not exist'
else
mode_x <- unique_val[position]
return(mode_x)
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-09-06 09:09:18
Poniżej znajduje się kod, który można wykorzystać do znalezienia trybu zmiennej wektorowej w R.
a <- table([vector])
names(a[a==max(a)])
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-02-21 17:43:14
Istnieje wiele rozwiązań dla tego. Sprawdziłam pierwszą, a potem napisałam własną. Wrzuć tutaj, jeśli komuś to pomoże:
Mode <- function(x){
y <- data.frame(table(x))
y[y$Freq == max(y$Freq),1]
}
Lets test it with a few example. Biorę iris zestaw danych. Lets test with numeric data
> Mode(iris$Sepal.Length)
[1] 5
Które możesz zweryfikować jest poprawne.
Teraz jedyne nieliczbowe pole w zbiorze danych iris (Species) nie ma trybu. Przetestujmy na naszym własnym przykładzie
> test <- c("red","red","green","blue","red")
> Mode(test)
[1] red
EDIT
Jak wspomniano w komentarze, użytkownik może chcieć zachować Typ wprowadzania. W takim przypadku funkcja mode może zostać zmieniona na:
Mode <- function(x){
y <- data.frame(table(x))
z <- y[y$Freq == max(y$Freq),1]
as(as.character(z),class(x))
}
Ostatni wiersz funkcji po prostu wymusza ostateczną wartość trybu do typu oryginalnego wejścia.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-04-25 00:46:15
Inną prostą opcją, która podaje wszystkie wartości uporządkowane według częstotliwości, jest użycie rle:
df = as.data.frame(unclass(rle(sort(mySamples))))
df = df[order(-df$lengths),]
head(df)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-12-04 14:29:14
Użyłbym funkcji density() do określenia wygładzonego maksimum (być może ciągłego) rozkładu:
function(x) density(x, 2)$x[density(x, 2)$y == max(density(x, 2)$y)]
Gdzie x jest zbiorem danych. Zwróć uwagę na dopasuj parmetr funkcji gęstości, która reguluje wygładzanie.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-05-02 14:57:26
Chociaż lubię prostą funkcję Kena Williamsa, chciałbym pobrać wiele trybów, jeśli istnieją. Mając to na uwadze, używam poniższej funkcji, która zwraca listę trybów, jeśli jest wiele lub pojedynczy.
rmode <- function(x) {
x <- sort(x)
u <- unique(x)
y <- lapply(u, function(y) length(x[x==y]))
u[which( unlist(y) == max(unlist(y)) )]
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-12-24 16:08:02
Przeglądałem wszystkie te opcje i zacząłem zastanawiać się nad ich względnymi funkcjami i wydajnością, więc zrobiłem kilka testów. W przypadku, gdyby ktoś jeszcze był ciekawy tego samego, dzielę się moimi wynikami tutaj.
Nie chcąc przejmować się wszystkimi funkcjami tutaj zamieszczonymi, postanowiłem skupić się na przykładzie opartym na kilku kryteriach: funkcja powinna pracować zarówno na wektorach znakowych, faktorowych, logicznych i numerycznych, powinna odpowiednio radzić sobie z NAs i innymi problematycznymi wartościami, a wyjście powinno być "sensowne", tzn. brak cyfr jako znaków lub innych takich głupstw.
Dodałem również własną funkcję, która jest oparta na tym samym pomyśle rle Co chrispy ' s, z tym, że dostosowana do bardziej ogólnego zastosowania:
library(magrittr)
Aksel <- function(x, freq=FALSE) {
z <- 2
if (freq) z <- 1:2
run <- x %>% as.vector %>% sort %>% rle %>% unclass %>% data.frame
colnames(run) <- c("freq", "value")
run[which(run$freq==max(run$freq)), z] %>% as.vector
}
set.seed(2)
F <- sample(c("yes", "no", "maybe", NA), 10, replace=TRUE) %>% factor
Aksel(F)
# [1] maybe yes
C <- sample(c("Steve", "Jane", "Jonas", "Petra"), 20, replace=TRUE)
Aksel(C, freq=TRUE)
# freq value
# 7 Steve
Skończyłem uruchamiając pięć funkcji, na dwóch zestawach danych testowych, przez microbenchmark. Nazwy funkcji odnoszą się do ich autorów:
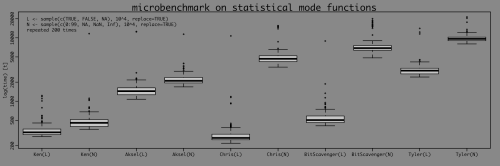
Funkcja Chrisa została domyślnie ustawiona na method="modes" i na.rm=TRUE, aby była bardziej porównywalna, ale inna niż że funkcje te zostały użyte w sposób przedstawiony tutaj przez ich autorów.
Tylko w kwestii prędkości Wersja Kens wygrywa zręcznie, ale jest również jedyną z nich, która zgłosi tylko jeden tryb, bez względu na to, ile ich naprawdę jest. Jak to często bywa, istnieje kompromis między szybkością a wszechstronnością. W method="mode", Wersja Chrisa zwróci wartość iff jest jeden tryb, w przeciwnym razie NA. Myślę, że to miły akcent.
Myślę również, że to ciekawe, jak niektóre funkcje są wpływane przez zwiększone liczba unikalnych wartości, podczas gdy inne nie są prawie tak wiele. Nie przestudiowałem kodu szczegółowo, aby dowiedzieć się, dlaczego tak jest, oprócz wyeliminowania logicznego / numerycznego jako przyczyny.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-05-27 03:08:23
Tryb nie może być przydatny w każdej sytuacji. Więc funkcja powinna zająć się tą sytuacją. Wypróbuj następującą funkcję.
Mode <- function(v) {
# checking unique numbers in the input
uniqv <- unique(v)
# frquency of most occured value in the input data
m1 <- max(tabulate(match(v, uniqv)))
n <- length(tabulate(match(v, uniqv)))
# if all elements are same
same_val_check <- all(diff(v) == 0)
if(same_val_check == F){
# frquency of second most occured value in the input data
m2 <- sort(tabulate(match(v, uniqv)),partial=n-1)[n-1]
if (m1 != m2) {
# Returning the most repeated value
mode <- uniqv[which.max(tabulate(match(v, uniqv)))]
} else{
mode <- "Two or more values have same frequency. So mode can't be calculated."
}
} else {
# if all elements are same
mode <- unique(v)
}
return(mode)
}
Wyjście,
x1 <- c(1,2,3,3,3,4,5)
Mode(x1)
# [1] 3
x2 <- c(1,2,3,4,5)
Mode(x2)
# [1] "Two or more varibles have same frequency. So mode can't be calculated."
x3 <- c(1,1,2,3,3,4,5)
Mode(x3)
# [1] "Two or more values have same frequency. So mode can't be calculated."
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-09-20 05:47:11
To opiera się na odpowiedzi jprockbelly ' ego, dodając szybkość dla bardzo krótkich wektorów. Jest to przydatne przy stosowaniu trybu do danych.ramka lub datowalna z dużą ilością małych grup:
Mode <- function(x) {
if ( length(x) <= 2 ) return(x[1])
if ( anyNA(x) ) x = x[!is.na(x)]
ux <- unique(x)
ux[which.max(tabulate(match(x, ux)))]
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-11-13 23:33:58
Inne możliwe rozwiązanie:
Mode <- function(x) {
if (is.numeric(x)) {
x_table <- table(x)
return(as.numeric(names(x_table)[which.max(x_table)]))
}
}
Użycie:
set.seed(100)
v <- sample(x = 1:100, size = 1000000, replace = TRUE)
system.time(Mode(v))
Wyjście:
user system elapsed
0.32 0.00 0.31
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-12-16 02:45:39
Uważam, że Twoje obserwacje są klasami zliczb rzeczywistych i oczekujesz, że tryb będzie 2.5, gdy twoje obserwacje będą 2, 2, 3 i 3, wtedy możesz oszacować tryb za pomocą mode = l1 + i * (f1-f0) / (2f1 - f0 - f2) Gdzie l1 ..dolna granica najczęściej występującej klasy, f1 ..częstość występowania najczęściej występującej klasy, f0 ..częstotliwość klas przed najczęściej występującymi klasami, f2 ..częstotliwość zajęć po najczęstszych klasach i i ..Przedział klasowy podany np. w 1, 2, 3:
#Small Example
x <- c(2,2,3,3) #Observations
i <- 1 #Class interval
z <- hist(x, breaks = seq(min(x)-1.5*i, max(x)+1.5*i, i), plot=F) #Calculate frequency of classes
mf <- which.max(z$counts) #index of most frequent class
zc <- z$counts
z$breaks[mf] + i * (zc[mf] - zc[mf-1]) / (2*zc[mf] - zc[mf-1] - zc[mf+1]) #gives you the mode of 2.5
#Larger Example
set.seed(0)
i <- 5 #Class interval
x <- round(rnorm(100,mean=100,sd=10)/i)*i #Observations
z <- hist(x, breaks = seq(min(x)-1.5*i, max(x)+1.5*i, i), plot=F)
mf <- which.max(z$counts)
zc <- z$counts
z$breaks[mf] + i * (zc[mf] - zc[mf-1]) / (2*zc[mf] - zc[mf-1] - zc[mf+1]) #gives you the mode of 99.5
W przypadku, gdy chcesz najczÄ ™ Ĺ "ciej poziom i masz wiÄ ™ cej niĹź jeden najczÄ ™ Ĺ" ciej poziom moĹźesz uzyskaÄ ‡ wszystkie np. z:
x <- c(2,2,3,5,5)
names(which(max(table(x))==table(x)))
#"2" "5"
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-03-27 08:31:39
Funkcja generyczna fmode w pakiecie collapse jest teraz dostępna w CRAN implementuje tryb C++ oparty na hashowaniu indeksów. Jest znacznie szybszy niż którekolwiek z powyższych podejść. Zawiera metody wektorów, macierzy, danych.ramki i dplyr zgrupowane tibbles. Składnia:
fmode(x, g = NULL, w = NULL, ...)
Gdzie x może być jednym z powyższych obiektów, g dostarcza opcjonalny wektor grupujący lub listę wektorów grupujących (dla obliczeń trybu grupowanego, wykonywanych również w C++), oraz w (opcjonalnie) dostarcza liczbowy wektor wagi. W metodzie Tibble nie ma argumentu g, można wykonać data %>% group_by(idvar) %>% fmode.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-03-19 21:45:11
Może wypróbować następującą funkcję:
- przekształć wartości liczbowe w współczynnik
- Użyj summary (), aby uzyskać tabelę częstotliwości
- return mode indeks, którego częstotliwość jest największa
- transform factor back to numeric nawet istnieje więcej niż 1 tryb, ta funkcja działa dobrze!
mode <- function(x){
y <- as.factor(x)
freq <- summary(y)
mode <- names(freq)[freq[names(freq)] == max(freq)]
as.numeric(mode)
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-10-12 12:33:46
Tryb obliczania jest najczęściej w przypadku zmiennej czynnika wtedy możemy użyć
labels(table(HouseVotes84$V1)[as.numeric(labels(max(table(HouseVotes84$V1))))])
HouseVotes84 to zbiór danych dostępny w pakiecie 'mlbench'.
Da maksymalną wartość etykiety. jest łatwiejszy w użyciu przez wbudowane funkcje bez funkcji zapisu.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-02-21 17:41:41
Wydaje mi się, że jeśli zbiór ma tryb, to jego elementy można odwzorować jeden do jednego z liczbami naturalnymi. Tak więc problem ze znalezieniem trybu sprowadza się do stworzenia takiego mapowania, znalezienia trybu mapowanych wartości, a następnie mapowania z powrotem do niektórych elementów w kolekcji. (Radzenie sobie z NA występuje w fazie mapowania).
Mam histogram funkcję, która działa na podobnej zasadzie. (Funkcje specjalne i operatory użyte w niniejszym kodzie powinny być zdefiniowane w i/lub . Fragmenty Shapiro i neatOveRse powielone w niniejszym dokumencie są powielane za zgodą; powielone fragmenty mogą być używane zgodnie z warunkami tej strony.) R pseudokod dla histogram jest
.histogram <- function (i)
if (i %|% is.empty) integer() else
vapply2(i %|% max %|% seqN, `==` %<=% i %O% sum)
histogram <- function(i) i %|% rmna %|% .histogram
(specjalne operatory binarne wykonują , currying , and composition) I have a maxloc function, which is similar to which.max, but returns all the absolute maxima wektora. R pseudokod dla maxloc jest
FUNloc <- function (FUN, x, na.rm=F)
which(x == list(identity, rmna)[[na.rm %|% index.b]](x) %|% FUN)
maxloc <- FUNloc %<=% max
minloc <- FUNloc %<=% min # I'M THROWING IN minloc TO EXPLAIN WHY I MADE FUNloc
Then
imode <- histogram %O% maxloc
I
x %|% map %|% imode %|% unmap
Obliczy tryb dowolnej kolekcji, pod warunkiem zdefiniowania odpowiednich funkcji map-ping i unmap-ping.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-10-30 23:47:06
Dodanie w raster::modal() jako opcji, chociaż zauważ, że raster jest sporym pakietem i może nie być warte zainstalowania, jeśli nie wykonujesz prac geoprzestrzennych.
Kod źródłowy można wyciągnąć z https://github.com/rspatial/raster/blob/master/src/modal.cpp i https://github.com/rspatial/raster/blob/master/R/modal.R do osobistego pakietu R, dla tych, którzy są szczególnie chętni.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-11-15 06:58:57