Jak wygenerować AST zbudowany za pomocą ANTLR?
Robię analizator statyczny dla C. Zrobiłem lexer i parser za pomocą ANTLR, w którym generuje kod Java.
Czy ANTLR buduje dla nas AST automatycznie przezoptions {output=AST;}? Czy muszę sama zrobić choinkę? Jeśli tak, to jak wypluć węzły na AST?
Obecnie myślę, że węzły na tym AST zostaną wykorzystane do stworzenia SSA, a następnie analizy przepływu danych w celu stworzenia analizatora statycznego. Czy jestem na dobrej drodze?
1 answers
Rafał napisał (a):
Czy antlr buduje dla nas AST automatycznie za pomocą opcji{output=AST;}? Czy muszę sama zrobić choinkę? Jeśli tak, to jak wypluć węzły na AST?
Nie, parser nie wie, co chcesz jako korzeń i jako liście dla każdej reguły parsera, więc będziesz musiał zrobić trochę więcej niż tylko umieścić options { output=AST; } w gramatyce.
Na przykład podczas parsowania Źródła "true && (false || true && (true || false))" za pomocą parsera wygenerowanego z gramatyka:
grammar ASTDemo;
options {
output=AST;
}
parse
: orExp
;
orExp
: andExp ('||' andExp)*
;
andExp
: atom ('&&' atom)*
;
atom
: 'true'
| 'false'
| '(' orExp ')'
;
// ignore white space characters
Space
: (' ' | '\t' | '\r' | '\n') {$channel=HIDDEN;}
;
Generowane jest następujące drzewo parsowania:

(tj. tylko płaska, 1-wymiarowa lista tokenów)
Będziesz chciał powiedzieć ANTLR, które tokeny w Twojej gramatyce stają się korzeniami, liśćmi lub po prostu pozostawionymi poza drzewem.
Tworzenie AST można wykonać na dwa sposoby:
- Użyj reguł przepisywania, które wyglądają tak:
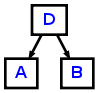
foo : A B C D -> ^(D A B);, Gdziefoojest regułą parsera, która pasuje do tokenówA B C D. Więc wszystko po {[8] } jest rzeczywistym przepisaniem zasada. Jak widać, tokenCnie jest używany w regule rewrite, co oznacza, że jest pomijany w AST. Token umieszczony bezpośrednio po^(stanie się korzeniem drzewa; - użyj operatorów drzewa
^i!po token wewnątrz reguł parsera, gdzie {[11] } uczyni token korzeniem, a!usunie token z drzewa. Odpowiednikiem dlafoo : A B C D -> ^(D A B);byłobyfoo : A B C! D^;
Zarówno foo : A B C D -> ^(D A B); jak i foo : A B C! D^; będą produkować po AST:
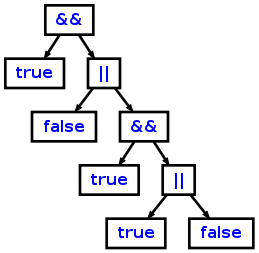
Teraz możesz przepisać gramatykę w następujący sposób:
grammar ASTDemo;
options {
output=AST;
}
parse
: orExp
;
orExp
: andExp ('||'^ andExp)* // Make `||` root
;
andExp
: atom ('&&'^ atom)* // Make `&&` root
;
atom
: 'true'
| 'false'
| '(' orExp ')' -> orExp // Just a single token, no need to do `^(...)`,
// we're removing the parenthesis. Note that
// `'('! orExp ')'!` will do exactly the same.
;
// ignore white space characters
Space
: (' ' | '\t' | '\r' | '\n') {$channel=HIDDEN;}
;
, który utworzy następujący AST ze źródła "true && (false || true && (true || false))":
Powiązane linki antlr wiki:
Rafał napisał (a):
Obecnie myślę, że węzły na tym AST będą używane do dokonywanie SSA, a następnie analiza przepływu danych w celu wykonania analizatora statycznego. Czy jestem na dobrej drodze?
Nigdy czegoś takiego nie robiłem, ale IMO pierwszą rzeczą, której byś chciał, to AST od źródła, więc tak, myślę, że jesteś na dobrej drodze! :)
EDIT
Oto jak możesz użyć wygenerowanego lexera i parsera:
import org.antlr.runtime.*;
import org.antlr.runtime.tree.*;
import org.antlr.stringtemplate.*;
public class Main {
public static void main(String[] args) throws Exception {
String src = "true && (false || true && (true || false))";
ASTDemoLexer lexer = new ASTDemoLexer(new ANTLRStringStream(src));
ASTDemoParser parser = new ASTDemoParser(new CommonTokenStream(lexer));
CommonTree tree = (CommonTree)parser.parse().getTree();
DOTTreeGenerator gen = new DOTTreeGenerator();
StringTemplate st = gen.toDOT(tree);
System.out.println(st);
}
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-09-01 20:51:07