UTF-8, UTF-16 i UTF-32
Jakie są różnice między UTF-8, UTF-16 i UTF-32?
Rozumiem, że wszystkie będą przechowywać Unicode i że każdy z nich używa innej liczby bajtów do reprezentowania znaku. Czy jest jakaś przewaga w wyborze jednego nad drugim?
12 answers
UTF-8 ma przewagę w przypadku, gdy znaki ASCII reprezentują większość znaków w bloku tekstu, ponieważ UTF-8 koduje wszystkie znaki na 8 bitów (jak ASCII). Jest to również korzystne w tym, że plik UTF-8 zawierający tylko znaki ASCII ma takie samo kodowanie jak plik ASCII.
UTF-16 jest lepszy tam, gdzie nie dominuje ASCII, ponieważ używa głównie 2 bajtów na znak. UTF - 8 zacznie używać 3 lub więcej bajtów dla znaków wyższego rzędu, gdzie UTF-16 pozostaje tylko 2 bajty dla większości znaków.
UTF-32 obejmie wszystkie możliwe znaki w 4 bajtach. To sprawia, że jest całkiem nadęty. Nie mogę wymyślić żadnej korzyści z jej używania.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-02-26 20:04:10
W skrócie:
- UTF-8: kodowanie o zmiennej szerokości, kompatybilne wstecz z ASCII. Znaki ASCII (U+0000 do U+007F) zajmują 1 bajt, Punkty kodowe U + 0080 do U+07FF zajmują 2 bajty, Punkty kodowe U + 0800 do U + FFFF zajmują 3 bajty, Punkty kodowe U+10000 do U+10FFFF zajmują 4 bajty. Dobre dla tekstu angielskiego, nie tak dobre dla tekstu azjatyckiego.
UTF-16: kodowanie o zmiennej szerokości. Punkty kodowe U + 0000 do U+FFFF zajmują 2 bajty, Punkty kodowe U + 10000 do U+10FFFF zajmują 4 bajty. Złe dla tekstu angielskiego, dobre dla Azjatycki SMS.
UTF-32: kodowanie o stałej szerokości. Wszystkie punkty kodu zajmują cztery bajty. Ogromna pamięć, ale szybka w obsłudze. Rzadko używany.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-01-11 15:55:02
UTF-8 jest zmienną od 1 do 4 bajtów.
UTF-16 jest zmienną 2 lub 4 bajtów.
UTF-32 jest naprawiony 4 bajtów.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-01-04 18:27:51
Unicode definiuje pojedynczy ogromny zestaw znaków, przypisując jedną unikalną wartość całkowitą do każdego symbolu graficznego(co jest dużym uproszczeniem i nie jest prawdą, ale jest wystarczająco blisko dla celów tego pytania). UTF-8/16/32 to po prostu różne sposoby kodowania.
W skrócie, UTF-32 używa 32-bitowych wartości dla każdego znaku. To pozwala im używać kodu o stałej szerokości dla każdego znaku.
UTF-16 domyślnie używa 16-bitów, ale daje to tylko 65K znaków, co nie wystarcza do pełnego zestawu Unicode. Tak więc niektóre znaki używają par 16-bitowych wartości.
I UTF-8 domyślnie używają wartości 8-bitowych, co oznacza, że 127 pierwszych wartości jest jednobajtowymi znakami o stałej szerokości (najbardziej znaczący bit jest używany do oznaczenia, że jest to początek sekwencji wielobajtowej, pozostawiając 7 bitów dla rzeczywistej wartości znaku). Wszystkie pozostałe znaki są kodowane jako sekwencje do 4 bajtów (o ile pamięć służy).
I to prowadzi nas do zalety. Każdy znak ASCII jest bezpośrednio kompatybilny z UTF-8, więc w przypadku aktualizacji starszych aplikacji UTF-8 jest powszechnym i oczywistym wyborem. W prawie wszystkich przypadkach będzie również zużywać najmniej pamięci. Z drugiej strony nie można zagwarantować szerokości znaku. Może mieć szerokość 1, 2, 3 lub 4 znaków, co utrudnia manipulację ciągiem znaków.
UTF-32 jest odwrotnie, zużywa najwięcej pamięci( każdy znak ma stałą szerokość 4 bajtów), ale z drugiej strony wiedz że każdy znak ma taką dokładną długość, więc manipulacja łańcuchem staje się znacznie prostsza. Liczbę znaków w łańcuchu można obliczyć po prostu na podstawie długości łańcucha w bajtach. Nie możesz tego zrobić z UTF-8.
UTF-16 to kompromis. Pozwala większość znaków zmieścić się w 16-bitowej wartości o stałej szerokości. Tak długo, jak nie masz chińskich symboli, nut lub innych, można założyć, że każdy znak ma 16 bitów szerokości. Zużywa mniej pamięci niż UTF-32. Ale w pewnym sensie jest to "najgorszy z obu światów". Prawie zawsze zużywa więcej pamięci niż UTF-8 i nadal nie unika problemu, który plaga UTF-8 (znaki o zmiennej długości).
Wreszcie, często pomocne jest po prostu iść z tym, co platforma obsługuje. Windows używa UTF-16 wewnętrznie, więc w Windows jest to oczywisty wybór.
Linux różni się trochę, ale zazwyczaj używają UTF-8 do wszystkiego, co jest zgodne z Unicode.
Tak krótka odpowiedź: wszystkie trzy kodowania mogą kodować ten sam zestaw znaków, ale reprezentują każdy znak jako różne sekwencje bajtów.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-01-04 18:30:38
Unicode jest standardem i o UTF-x można myśleć jako implementacja techniczna dla niektórych praktycznych celów:
- UTF-8 - "Rozmiar zoptymalizowany ": najlepiej nadaje się do danych opartych na znakach łacińskich (lub ASCII), zajmuje tylko 1 bajt na znak, ale rozmiar rośnie odpowiednio różnorodność symboli (i w najgorszym przypadku może wzrosnąć do 6 bajtów na znak)
- UTF-16 - "balance ": zajmuje minimum 2 bajty na znak, co jest w przeciwieństwie do innych języków, w których istnieje wiele języków o stałym rozmiarze, w celu ułatwienia obsługi znaków (ale rozmiar jest wciąż zmienny i może wzrosnąć do 4 bajtów na znak)
- UTF-32 - "wydajność ": pozwala na użycie prostych algorytmów jako wyniku znaków o stałym rozmiarze (4 bajty), ale z wadą pamięci
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-07-09 21:38:16
Próbowałem dać proste wyjaśnienie w moim blogpost .
UTF-32
Wymaga 32 bitów (4 bajty) do zakodowania dowolnego znaku. Na przykład, aby reprezentować punkt kodu znaku" A " używając tego schematu, musisz zapisać 65 w 32-bitowej liczbie binarnej:
00000000 00000000 00000000 01000001 (Big Endian)
Jeśli przyjrzysz się bliżej, zauważysz, że siedem prawych bitów jest w rzeczywistości tymi samymi bitami podczas korzystania ze schematu ASCII. Ale ponieważ UTF-32 jest schematem stałej szerokości, my musi dołączyć trzy dodatkowe bajty. Oznacza to, że jeśli mamy dwa pliki, które zawierają tylko znak "A", jeden jest zakodowany w ASCII, a drugi jest zakodowany w UTF-32, ich rozmiar będzie odpowiednio 1 bajt i 4 bajty.
UTF-16
Wiele osób uważa, że UTF-32 używa stałej szerokości 32 bitów do reprezentowania punktu kodu, UTF-16 ma stałą szerokość 16 bitów. Źle!W UTF-16 punkt kodu może być reprezentowany w 16 bitach lub 32 bitach. Więc ten schemat jest kodowaniem o zmiennej długości system. Jaka jest przewaga nad UTF-32? Przynajmniej dla ASCII, rozmiar plików nie będzie 4 razy większy od oryginału (ale nadal dwa razy), więc nadal nie jesteśmy wstecznie zgodni z ASCII.
Ponieważ 7-bitów wystarcza do reprezentowania znaku "A", możemy teraz użyć 2 bajtów zamiast 4, Jak UTF-32. Będzie wyglądać tak:
00000000 01000001
UTF-8
Dobrze zgadłeś.. W UTF-8 punkt kodu może być reprezentowany za pomocą 32, 16, 24 lub 8 bitów, a jako system UTF-16, ten również jest system kodowania o zmiennej długości.Wreszcie możemy reprezentować "A"w ten sam sposób, w jaki reprezentujemy ją za pomocą systemu kodowania ASCII:
01001101
Rozważmy chińską literę " 語 " - jej kodowanie UTF-8 to:
11101000 10101010 10011110
Podczas gdy kodowanie UTF-16 jest krótsze:
10001010 10011110
Aby zrozumieć przedstawienie i jak jest interpretowane, odwiedź oryginalny post.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-02-03 16:16:07
UTF-8
- nie ma pojęcia o kolejności bajtów
- używa od 1 do 4 bajtów na znak
- ASCII jest zgodnym podzbiorem kodowania
- całkowita synchronizacja, np. upuszczony bajt z dowolnego miejsca w strumieniu spowoduje uszkodzenie co najwyżej pojedynczego znaku
- prawie wszystkie języki europejskie są kodowane w dwóch bajtach lub mniej na znak
UTF-16
- musi być parsowany ze znanym porządkiem bajtów lub odczytywany znak bajtów (BOM)
- używa 2 lub 4 bajtów na znak
UTF-32
- każdy znak ma 4 bajty
- musi być parsowany ze znanym porządkiem bajtów lub odczytem znaku bajtów (BOM)
UTF-8 będzie najbardziej efektywny przestrzennie, chyba że większość znaków pochodzi ze spacji CJK (chińskiej, japońskiej i koreańskiej).
UTF-32 jest najlepszy dla dostępu losowego poprzez przesunięcie znaków do tablicy bajtów.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-01-04 18:41:02
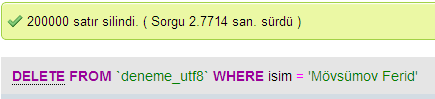
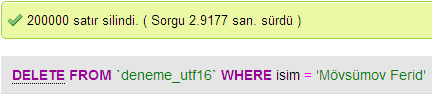
Zrobiłem kilka testów, aby porównać wydajność bazy danych pomiędzy UTF - 8 i UTF-16 W MySQL.
Prędkość Aktualizacji
UTF-8

UTF-16

Prędkość Wstawiania
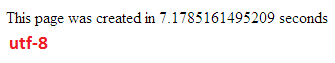
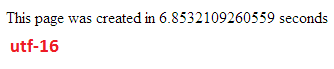
Usuń Prędkość
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-01-04 18:39:16
W UTF-32 wszystkie znaki są kodowane 32 bitami. Zaletą jest to, że można łatwo obliczyć długość ciągu. Wadą jest to, że dla każdego znaku ASCII marnuje się dodatkowe trzy bajty.
W UTF-8 znaki mają zmienną długość, znaki ASCII są kodowane w jednym bajcie( osiem bitów), większość zachodnich znaków specjalnych jest kodowana w dwóch lub trzech bajtach (na przykład € to trzy bajty), a bardziej egzotyczne znaki mogą zajmować do czterech bajtów. Wyczyść wadą jest to, że a priori nie można obliczyć długości łańcucha. Ale kodowanie tekstu alfabetu łacińskiego (angielskiego) zajmuje dużo mniej bajtów, w porównaniu do UTF-32.
UTF-16 jest również zmienną długością. Znaki są kodowane w dwóch lub czterech bajtach. Naprawdę nie widzę sensu. Jego wadą jest zmienna długość, ale nie ma tej zalety, że oszczędza tyle miejsca, co UTF-8.
Z tych trzech, najwyraźniej UTF-8 jest najbardziej rozpowszechniony.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-03-08 10:25:30
W zależności od środowiska programistycznego możesz nawet nie mieć wyboru, jakie kodowanie będzie używane wewnętrznie przez twój typ danych string.
Ale do przechowywania i wymiany danych zawsze używałbym UTF-8, Jeśli masz wybór. Jeśli masz głównie DANE ASCII, zapewni to najmniejszą ilość danych do przesłania, a jednocześnie będzie w stanie zakodować wszystko. Optymalizacja pod kątem najmniejszego wejścia/wyjścia to sposób na nowoczesne maszyny.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-01-04 18:34:35
Jak wspomniano, różnica polega przede wszystkim na wielkości podstawowych zmiennych, które w każdym przypadku stają się większe, aby umożliwić reprezentowanie większej liczby znaków.
Jednak czcionki, kodowanie i rzeczy są strasznie skomplikowane (niepotrzebnie?), więc potrzebny jest duży link, aby wypełnić bardziej szczegółowo:
Http://www.cs.tut.fi/~jkorpela / chars. html#ascii
Nie oczekuj, że zrozumiesz to wszystko, ale jeśli nie chcesz mieć później problemów, warto się uczyć tak samo jak ty możesz, jak najszybciej (lub po prostu namawiając kogoś innego, aby to za Ciebie uporządkował).
Paweł.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2009-01-30 17:17:07
W skrócie, jedynym powodem używania UTF-16 lub UTF-32 jest obsługa, odpowiednio, skryptów nieanglojęzycznych i starożytnych.
Zastanawiałem się, dlaczego ktoś zdecydował się na kodowanie bez UTF-8, skoro jest to oczywiście bardziej wydajne dla celów internetowych/programistycznych.
Powszechne błędne przekonanie - przyrostek liczby nie wskazuje na jego możliwości. Wszystkie obsługują kompletny Unicode, tylko że UTF-8 może obsługiwać ASCII z jednym bajtem, więc jest bardziej wydajny / mniej podatny na uszkodzenia procesora i przez internet.
Dobra lektura: http://www.personal.psu.edu/ejp10/blogs/gotunicode/2007/10/which_utf_do_i_use.html i http://utf8everywhere.org
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-05-21 15:12:32