Jak radzić sobie z kolizjami?
Słyszałem na moich zajęciach, że HashTable umieści nowy wpis w "następnym dostępnym" wiadrze, jeśli nowy wpis klucza zderzy się z innym.
W jaki sposób HashTable nadal zwraca poprawną wartość, jeśli ta kolizja wystąpi, gdy wywołanie jednego z powrotem za pomocą klucza kolizji?
Zakładam, że Keys są typami String, a hashCode() zwraca domyślną wartość wygenerowaną przez say Java.
Jeśli zaimplementuję własną funkcję haszującą i wykorzystam ją jako część tabeli wyszukiwania (np. HashMap lub Dictionary), jakie istnieją strategie radzenia sobie z kolizjami?
10 answers
Tabele Hash radzą sobie z kolizjami na jeden z dwóch sposobów.
Opcja 1: przez to, że każde wiadro zawiera połączoną listę elementów, które są zahaszowane do tego wiadra. To dlatego zła funkcja hash może sprawić, że wyszukiwanie w tabelach hash będzie bardzo powolne.
Opcja 2: Jeśli wpisy w tabeli hash są pełne, tabela hash może zwiększyć liczbę wiadrów, które posiada, a następnie redystrybuować wszystkie elementy w tabeli. Funkcja hash Zwraca liczbę całkowitą i hash tabela musi wziąć wynik funkcji hash i zmodyfikować go względem wielkości tabeli, aby mieć pewność, że dotrze do bucket. Więc zwiększając rozmiar, będzie ponownie i uruchomić obliczenia modulo, które jeśli masz szczęście może wysłać obiekty do różnych wiadra.
Java używa zarówno opcji 1, jak i 2 w swoich implementacjach tabel hashowych.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-04-12 14:58:28
Kiedy mówiłeś o "tabela hashów umieści nowy wpis W' next available ' bucket, jeśli nowy wpis klucza zderzy się z innym.", mówisz o otwartej strategii adresowania rozwiązywania kolizji tabeli hash.
Istnieje kilka strategii dla tabeli hash w celu rozwiązania kolizji.
Pierwszy rodzaj metody big wymaga, aby klucze (lub wskaźniki do nich) były przechowywane w tabeli, wraz z powiązanymi wartościami, które dalej zawiera:
- oddzielny łańcuch
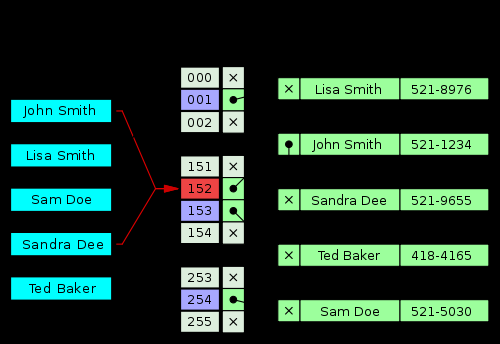
- adresowanie otwarte
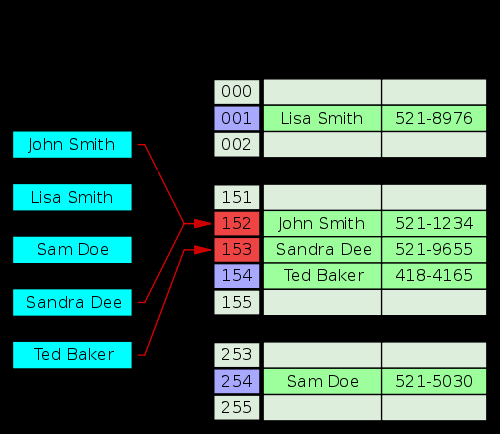
- Koalesced hashing
- haszowanie kukułek
- Robin Hood hashing
- 2-choice hashing
- Hopscotch hashing
Inną ważną metodą obsługi kolizji jest dynamiczna zmiana rozmiaru , która dodatkowo ma kilka sposoby:
- Zmiana rozmiaru poprzez skopiowanie wszystkich wpisów
- przyrostowa zmiana rozmiaru
- Klucze monotoniczne
EDIT : powyższe są zapożyczone z wiki_hash_table , gdzie powinieneś zajrzeć, aby uzyskać więcej informacji.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-12-19 11:18:37
Gorąco zachęcam do przeczytania tego wpisu na blogu, który pojawił się ostatnio na HackerNews: Jak działa HashMap w Javie
W skrócie, odpowiedź brzmi
Co się stanie, jeśli dwa różne Obiekty klucza HashMap mają takie same hashcode?
Będą przechowywane w tym samym wiadrze, ale nie ma następnego węzła z połączoną listą. I klucze metoda equals () zostanie użyta do zidentyfikuj poprawną parę wartości klucza w HashMap.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-02-12 21:40:15
Istnieje wiele dostępnych technik radzenia sobie z kolizją. Wyjaśnię niektóre z nich
"Łańcuch": {]} W łańcuchowaniu używamy indeksów tablic do przechowywania wartości. Jeśli kod skrótu drugiej wartości również wskazuje na ten sam indeks, to zamieniamy tę wartość indeksu na listę połączoną i wszystkie wartości wskazujące na ten indeks są przechowywane w liście połączonej, A Indeks rzeczywistej tablicy wskazuje na nagłówek listy połączonej. Ale jeśli jest tylko jeden kod hash wskazujący na indeks tablicy, to wartość jest bezpośrednio zapisywana w tym indeksie. Ta sama logika jest stosowana podczas pobierania wartości. Jest to używane w Java HashMap/Hashtable, aby uniknąć kolizji.
Sonda liniowa: Ta technika jest używana, gdy mamy więcej indeksu w tabeli niż wartości, które mają być zapisane. Technika sondy liniowej działa na koncepcji keep incrementing, aż znajdziesz pustą szczelinę. Pseudo kod wygląda tak..
Index = h (k)
While (Val (index) jest zajęte)
Indeks = (index+1) mod N
Technika podwójnego mieszania: w tej technice używamy dwóch funkcji mieszających h1 (k) i h2 (k). Jeśli szczelina W h1 (k) jest zajęta, to druga funkcja haszująca h2(k) używana do zwiększenia indeksu. Pseudo-kod wygląda tak..
Index = h1 (k)
While (Val (index) jest zajęte)
Index = (index + h2 (k)) mod N
Techniki sondowania liniowego i podwójnego mieszania są częścią techniki adresowania otwartego i mogą być używane tylko wtedy, gdy dostępne Sloty to więcej niż liczba przedmiotów do dodania. Zajmuje mniej pamięci niż łączenie łańcuchowe, ponieważ nie ma tu dodatkowej struktury, ale jej powolne z powodu dużego ruchu zdarzają się, dopóki nie znajdziemy pustego gniazda. Również w technice otwartego adresowania, gdy element jest usuwany z gniazda, umieszczamy nagrobek, aby wskazać, że element jest usuwany stąd, dlatego jest pusty.
Wzięte z http://coder2design.com/hashing/
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-07-01 12:22:53
Słyszałem na studiach, że HashTable umieści nowy wpis w "następny dostępny" wiadro, jeśli nowy Wejście klucza zderza się z innym.W rzeczywistości nie jest to prawdą, przynajmniej w przypadku Oracle JDK (jest to to szczegóły implementacji, które mogą się różnić w zależności od implementacji API). Zamiast tego każdy kubełek zawiera połączoną listę wpisów.
Więc jak HashTable jeszcze zwróć poprawną wartość, jeśli to kolizja występuje przy wywołaniu jednego z kluczem do kolizji?
Używa equals(), aby znaleźć rzeczywiście pasujący wpis.
Jeśli zaimplementuję własną funkcję haszującą i użyj go jako części tabeli wyszukiwania (tj. HashMap lub Słownik), co istnieją strategie radzenia sobie z kolizje?
Istnieją różne strategie obsługi kolizji z różnymi zaletami i wadami. wpis Wikipedii na tablicach hashowych daje dobre przegląd.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-02-12 21:38:46
Update since Java 8: Java 8 używa samowystarczalnego drzewa do obsługi kolizji, poprawiając najgorszy przypadek z O(n) Do o (log n) dla wyszukiwania. W Javie 8 wprowadzono samo-zrównoważone drzewo jako ulepszenie nad łańcuchowaniem (używane do Javy 7), które używa linked-list i ma najgorszy przypadek O (n) dla lookup (ponieważ musi przechodzić przez listę)
Aby odpowiedzieć na drugą część pytania, wstawianie odbywa się poprzez mapowanie danego elementu do danego indeksu w jeśli jednak dojdzie do kolizji, wszystkie elementy muszą być nadal zachowane (przechowywane w drugorzędnej strukturze danych, a nie tylko zastępowane w tablicy bazowej). Zwykle odbywa się to poprzez uczynienie każdego komponentu tablicy (slotu) drugorzędną strukturą danych (aka bucket), a element jest dodawany do zasobnika znajdującego się na podanym indeksie tablicy (jeśli klucz nie istnieje jeszcze w zasobniku, w którym to przypadku jest zastępowany).
Podczas wyszukiwania klucz jest hashowany do jego odpowiedni indeks tablicy i wyszukiwanie jest wykonywane dla elementu pasującego do (dokładnego) klucza w podanym zasobniku. Ponieważ łyżka nie musi obsługiwać kolizji (porównuje klucze bezpośrednio), rozwiązuje to problem kolizji, ale robi to kosztem konieczności wstawiania i Wyszukiwania na drugorzędnej strukturze danych. Kluczem jest to, że w hashmapie zarówno klucz, jak i wartość są przechowywane, więc nawet jeśli hash się zderzy, klucze są porównywane bezpośrednio dla równości (w wiadrze) i w ten sposób można jednoznacznie zidentyfikować w wiadrze.
Obsługa kolizji przynosi najgorszą wydajność wstawiania i Wyszukiwania Z O (1) w przypadku braku obsługi kolizji do O (N) dla łańcucha (lista powiązana jest używana jako drugorzędna struktura danych) i o(log n) dla drzewa samobalansującego.
Bibliografia:
W Javie 8 wprowadzono następujące ulepszenia / zmiany HashMap obiektów w przypadku dużych kolizji.
Alternatywny String hash funkcja dodana w Javie 7 została usunięta.
Wiadra zawierające dużą liczbę kolidujących kluczy będą przechowywać swoje wpisy w zrównoważonym drzewie zamiast listy połączonej po określony próg został osiągnięty.
Powyższe zmiany zapewniają wydajność o (log (n)) W najgorszych scenariuszach (https://www.nagarro.com/en/blog/post/24/performance-improvement-for-hashmap-in-java-8)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-08-01 00:14:12
Ponieważ istnieje pewne zamieszanie co do algorytmu, którego używa HashMap Java (w implementacji Sun / Oracle / OpenJDK), tutaj odpowiednie fragmenty kodu źródłowego (z OpenJDK, 1.6.0_20, na Ubuntu):
/**
* Returns the entry associated with the specified key in the
* HashMap. Returns null if the HashMap contains no mapping
* for the key.
*/
final Entry<K,V> getEntry(Object key) {
int hash = (key == null) ? 0 : hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
Ta metoda (cite jest z linii 355 do 371) jest wywoływana podczas wyszukiwania wpisu w tabeli, na przykład z get(), containsKey() i inni Pętla for przechodzi tutaj przez połączoną listę utworzoną przez obiekty entry.
Tutaj kod dla obiektów wejściowych (linie 691-705 + 759):
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
// (methods left away, they are straight-forward implementations of Map.Entry)
}
Zaraz po tym przychodzi metoda addEntry():
/**
* Adds a new entry with the specified key, value and hash code to
* the specified bucket. It is the responsibility of this
* method to resize the table if appropriate.
*
* Subclass overrides this to alter the behavior of put method.
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
Dodaje nowy wpis z przodu wiadra, z linkiem do starego pierwszego wpisu (lub null, jeśli takiego nie ma). Podobnie, metoda removeEntryForKey() przechodzi przez Listę i zajmuje się usuwaniem tylko jednego wpisu, pozwalając pozostałej części listy pozostać nienaruszonym.
Oto lista wpisów dla każdego wiadra i bardzo wątpię, aby to zmieniło się z _20 na _22, ponieważ było tak od 1.2 on
(kod ten jest (c) 1997-2007 Sun Microsystems, i jest dostępny na licencji GPL, ale do kopiowania lepiej używać oryginalnego pliku, zawartego w src.zip w każdym JDK z Sun/Oracle, a także w OpenJDK.)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-02-12 22:36:06
Użyje metody equals, aby sprawdzić, czy klucz jest obecny nawet, a zwłaszcza jeśli w tym samym wiadrze znajduje się więcej niż jeden element.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-02-12 21:33:58
Istnieją różne metody rozwiązywania kolizji.Niektóre z nich to oddzielne Łańcuchowanie, otwarte adresowanie,haszowanie Robin Hooda, haszowanie kukułek itp.
Java używa oddzielnych łańcuchów do rozwiązywania kolizji w tabelach Hashowych.Oto świetny link do tego, jak to się dzieje: http://javapapers.com/core-java/java-hashtable/
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-06-14 06:11:35
Oto bardzo prosta implementacja tabeli hash w Javie. tylko w implementacjach put() i get(), ale możesz łatwo dodać cokolwiek chcesz. opiera się na metodzie Javy hashCode(), która jest implementowana przez wszystkie obiekty. możesz łatwo stworzyć własny interfejs,
interface Hashable {
int getHash();
}
I wymusić implementację przez klucze, jeśli chcesz.
public class Hashtable<K, V> {
private static class Entry<K,V> {
private final K key;
private final V val;
Entry(K key, V val) {
this.key = key;
this.val = val;
}
}
private static int BUCKET_COUNT = 13;
@SuppressWarnings("unchecked")
private List<Entry>[] buckets = new List[BUCKET_COUNT];
public Hashtable() {
for (int i = 0, l = buckets.length; i < l; i++) {
buckets[i] = new ArrayList<Entry<K,V>>();
}
}
public V get(K key) {
int b = key.hashCode() % BUCKET_COUNT;
List<Entry> entries = buckets[b];
for (Entry e: entries) {
if (e.key.equals(key)) {
return e.val;
}
}
return null;
}
public void put(K key, V val) {
int b = key.hashCode() % BUCKET_COUNT;
List<Entry> entries = buckets[b];
entries.add(new Entry<K,V>(key, val));
}
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-03-01 20:34:17