Jak iterować wiersze w ramce danych w pandach
Mam DataFrame od Pandy:
import pandas as pd
inp = [{'c1':10, 'c2':100}, {'c1':11,'c2':110}, {'c1':12,'c2':120}]
df = pd.DataFrame(inp)
print df
Wyjście:
c1 c2
0 10 100
1 11 110
2 12 120
Teraz chcę iterować po rzędach tej ramki. Dla każdego wiersza chcę mieć dostęp do jego elementów (wartości w komórkach) po nazwie kolumn. Na przykład:
for row in df.rows:
print row['c1'], row['c2']
Znalazłem to podobne pytanie. Ale to nie daje mi odpowiedzi, której potrzebuję. Na przykład, sugeruje się tam, aby użycie:
for date, row in df.T.iteritems():
Lub
for row in df.iterrows():
Ale nie rozumiem, czym jest obiekt row i jak mogę z nim pracować.
25 answers
DataFrame.iterrows jest generatorem, który daje zarówno indeks, jak i wiersz (jako szereg):
import pandas as pd
df = pd.DataFrame({'c1': [10, 11, 12], 'c2': [100, 110, 120]})
for index, row in df.iterrows():
print(row['c1'], row['c2'])
10 100
11 110
12 120
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-12-11 08:38:28
Jak iterować wiersze w ramce danych w pandach?
Odpowiedź: Nie*!
Iteracja w pandach jest anty-wzorcem i jest czymś, co powinieneś robić tylko wtedy, gdy wyczerpałeś wszystkie inne opcje. Nie powinieneś używać żadnej funkcji z "iter " w nazwie dla więcej niż kilku tysięcy wierszy, albo będziesz musiał przyzwyczaić się do lot oczekiwania.
DataFrame.to_string().
Czy chcesz coś obliczyć? W takim przypadku wyszukaj metody w tej kolejności (lista zmodyfikowana z tutaj):
- wektoryzacja
- Cython procedury
- list Comprehensions (vanilla
forloop) -
DataFrame.apply(): i) redukcje, które mogą być wykonywane w Cythonie, II) iteracja w przestrzeni Pythona -
DataFrame.itertuples()oraziteritems() DataFrame.iterrows()
iterrows i itertuples (obie otrzymujące wiele głosów w odpowiedziach na to pytanie) powinny być używane w bardzo rzadkich okolicznościach, takich jak generowanie obiektów wiersza / nazw dla przetwarzania sekwencyjnego, co jest naprawdę jedyną rzeczą, do której te funkcje są przydatne.
Odwołanie do organu
Strona dokumentacji na iteracji ma ogromne czerwone pole ostrzegawcze, które says:
Iteracja przez obiekty pandy jest na ogół powolna. W wielu przypadkach iteracja ręczna nad wierszami nie jest potrzebna [...].
* to trochę bardziej skomplikowane niż "nie". df.iterrows() to poprawna odpowiedź na to pytanie, ale" wektoryzuj swoje operacje " jest lepsza. Przyznam, że istnieją okoliczności, w których nie można uniknąć iteracji(na przykład niektóre operacje, w których wynik zależy od wartości obliczonej dla poprzedniego wiersza). Jednak potrzeba pewnej znajomości biblioteki, aby wiedzieć, kiedy. Jeśli nie jesteś pewien, czy potrzebujesz iteracyjnego rozwiązania, prawdopodobnie nie. PS: aby dowiedzieć się więcej o moich przesłankach do napisania tej odpowiedzi, Przejdź na sam dół.
Szybciej niż zapętlenie: wektoryzacja, Cython
Wiele podstawowych operacji i obliczeń jest "wektoryzowanych" przez pandy (albo przez NumPy, albo przez Cythonized functions). Obejmuje to arytmetykę, porównania, (większość) redukcje, przekształcanie (takie jak pivoting), łączy, i operacje grupowe. Przejrzyj dokumentację Essential Basic Functionality , aby znaleźć odpowiednią metodę wektoryzowaną dla Twojego problemu.Jeśli żaden nie istnieje, możesz napisać własne za pomocą niestandardowych rozszerzeń Cython .
Następna Najlepsza Rzecz: Lista*
Lista powinna być następnym portem wywołania, Jeśli 1) nie ma dostępne wektoryzowane rozwiązanie, 2) wydajność jest ważna, ale nie na tyle ważna, aby przejść przez problemy z cytonizacją kodu i 3) próbujesz wykonać transformację elementwise na swoim kodzie. Istnieje wiele dowodów , które sugerują, że składanie list jest wystarczająco szybkie (a nawet czasami szybsze) dla wielu typowych zadań Pandy.
Wzór jest prosty,
# Iterating over one column - `f` is some function that processes your data
result = [f(x) for x in df['col']]
# Iterating over two columns, use `zip`
result = [f(x, y) for x, y in zip(df['col1'], df['col2'])]
# Iterating over multiple columns - same data type
result = [f(row[0], ..., row[n]) for row in df[['col1', ...,'coln']].to_numpy()]
# Iterating over multiple columns - differing data type
result = [f(row[0], ..., row[n]) for row in zip(df['col1'], ..., df['coln'])]
Jeśli możesz zamknąć swoją logikę biznesową w funkcję, możesz użyć lista Planetoid Możesz sprawić, że dowolnie złożone rzeczy będą działać dzięki prostocie i szybkości surowego kodu Pythona.
Caveats
Zestawienia List zakładają, że Twoje dane są łatwe w obsłudze - oznacza to, że Twoje typy danych są spójne i nie masz Nan, ale nie zawsze można tego zagwarantować.
-
Pierwszy z nich jest bardziej oczywisty, ale kiedy mamy do czynienia z Nanami, preferuj wbudowane metody pand, jeśli istnieją (ponieważ mają znacznie lepsza logika obsługi przypadków narożnych), lub upewnij się, że twoja logika biznesowa zawiera odpowiednią logikę obsługi NaN.
- gdy mamy do czynienia z mieszanymi typami danych, należy iterację nad
zip(df['A'], df['B'], ...)zamiastdf[['A', 'B']].to_numpy(), ponieważ ten ostatni domyślnie przenosi dane do najczęściej używanego typu. Na przykład, jeśli A jest liczbowe, A B jest ciągiem znaków,to_numpy()rzuci całą tablicę na ciąg znaków, co może nie być tym, czego chcesz. Na szczęściezipping kolumny razem jest najprostszym obejściem dla to.
*przebieg może się różnić z powodów opisanych w sekcji zastrzeżenia powyżej.
Oczywisty Przykład
Zademonstrujmy różnicę prostym przykładem dodania dwóch kolumn pandy A + B. Jest to operat wektorowy, więc łatwo będzie skontrastować wydajność metod omówionych powyżej.

Kod porównawczy, w celach informacyjnych . Linia na dole mierzy funkcję napisane w numpandas, styl Pandy, który mocno miesza się z NumPy, aby wycisnąć maksymalną wydajność. Należy unikać pisania kodu numpandas, chyba że wiesz, co robisz. Trzymaj się API tam, gdzie możesz (tj. preferuj vec nad vec_numpy).
Czytaj Dalej
-
10 Minutes to pandas , and Essential Basic Functionality - Przydatne linki, które wprowadzą cię do pandy i jej biblioteki wektoryzowanych funkcji * / cythonized.
-
Enhancing Performance - podkład z Dokumentacji na temat ulepszania standardowych operacji pand
-
czy for-loops w pandach są naprawdę złe? Kiedy powinno mnie to obchodzić? - a szczegółowe writeup przeze mnie o składaniu list i ich przydatności do różnych operacji (głównie tych obejmujących dane nieliczbowe)
-
Kiedy powinienem (nie) chcieć używać pandy apply () w moim kodzie? -
applyjest powolny (ale nie tak powolny jak rodzinaiter*. Istnieją jednak sytuacje, w których można (Lub należy) rozważyćapplyjako poważną alternatywę, szczególnie w niektórych operacjachGroupBy).
* metody łańcuchowe pandy to "wektoryzowane" w tym sensie, że są określone na szeregu, ale działają na każdym elemencie. Podstawowe mechanizmy są nadal iteracyjne, ponieważ operacje łańcuchowe są z natury trudne do wektoryzacji.
Dlaczego napisałem tę odpowiedź
Częstym trendem, który zauważam od nowych użytkowników, jest zadawanie pytań formularza " Jak mogę iterować nad moim df, aby zrobić X?". Wyświetlanie kodu wywołującego iterrows() podczas robienia czegoś wewnątrz for pętli. Oto dlaczego. Nowego Użytkownika do biblioteki, który nie zostały wprowadzone do koncepcji wektoryzacji prawdopodobnie wyobrażają sobie kod, który rozwiązuje ich problem, jak iteracja nad ich danymi, aby coś zrobić. Nie wiedząc, jak iterować przez ramkę danych, pierwszą rzeczą, którą robią, jest Wygooglowanie go i wylądowanie tutaj, na tym pytaniu. Następnie widzą zaakceptowaną odpowiedź mówiącą im, jak to zrobić, a oni zamykają oczy i uruchamiają ten kod bez uprzedniego pytania, czy iteracja nie jest właściwą rzeczą do zrobienia.
Celem tej odpowiedzi jest pomoc nowym użytkownikom zrozumcie, że iteracja niekoniecznie jest rozwiązaniem każdego problemu, że mogą istnieć lepsze, szybsze i bardziej idiomatyczne rozwiązania i że warto zainwestować czas w ich zbadanie. Nie próbuję rozpoczynać wojny iteracji z wektoryzacją, ale chcę, aby nowi użytkownicy byli informowani przy opracowywaniu rozwiązań ich problemów z tą biblioteką.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-12-26 12:35:12
Najpierw zastanów się, czy naprawdę potrzebujesziteracji nad wierszami w ramce danych. Zobacz ta odpowiedź dla alternatyw.
Jeśli nadal potrzebujesz iteracji nad wierszami, możesz użyć metod poniżej. Zwróć uwagę na niektóre Ważne zastrzeżenia , które nie zostały wymienione w żadnej z pozostałych odpowiedzi.
-
for index, row in df.iterrows(): print(row["c1"], row["c2"]) -
for row in df.itertuples(index=True, name='Pandas'): print(row.c1, row.c2)
itertuples() ma być szybciej than iterrows()
Ale należy pamiętać, zgodnie z docs (pandy 0.24.2 w tej chwili):
-
Iterrows:
dtypemoże nie pasować od wiersza do wierszaPonieważ iterrows zwraca serię dla każdego wiersza, to nie zachowuje typów dtypów w wierszach (dtypy są zachowywane w kolumnach dla ramek danych). Aby zachować dtypes podczas iteracji nad wierszami, lepiej jest użyć metody itertuples (), która zwraca namedtuples wartości i która jest ogólnie dużo faster than iterrows ()
-
Iterrows: nie modyfikuj wierszy
Powinieneś nigdy nie modyfikować czegoś, nad czym pracujesz. Nie gwarantuje to działania we wszystkich przypadkach. W zależności od typów danych iterator zwraca kopię, a nie Widok, a zapis do niego nie będzie miał żadnego efektu.
Użyj Ramki Danych .apply () zamiast:
new_df = df.apply(lambda x: x * 2) -
Itertuples:
Nazwy kolumn zostaną zmienione na nazwy pozycyjne, jeśli są nieprawidłowymi identyfikatorami Pythona, powtarzane lub rozpoczynają się podkreśleniem. Przy dużej liczbie kolumn (>255) zwracane są zwykłe krotki.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-04-23 19:41:52
Powinieneś użyć df.iterrows(). Iteracja wierszy po wierszu nie jest szczególnie efektywna, ponieważ obiekty Series muszą być tworzone.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-12-11 18:42:58
Chociaż iterrows() jest dobrym rozwiązaniem, czasami itertuples() może być znacznie szybsze:
df = pd.DataFrame({'a': randn(1000), 'b': randn(1000),'N': randint(100, 1000, (1000)), 'x': 'x'})
%timeit [row.a * 2 for idx, row in df.iterrows()]
# => 10 loops, best of 3: 50.3 ms per loop
%timeit [row[1] * 2 for row in df.itertuples()]
# => 1000 loops, best of 3: 541 µs per loop
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-06-01 09:00:01
Możesz również użyć df.apply() do iteracji wierszy i dostępu do wielu kolumn dla funkcji.
def valuation_formula(x, y):
return x * y * 0.5
df['price'] = df.apply(lambda row: valuation_formula(row['x'], row['y']), axis=1)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-06-01 06:24:44
Możesz użyć df.funkcja iloc w następujący sposób:
for i in range(0, len(df)):
print df.iloc[i]['c1'], df.iloc[i]['c2']
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-11-07 09:09:10
Jak skutecznie iterować
Jeśli naprawdę musisz iterować ramkę danych Pandy, prawdopodobnie będziesz chciał unikać używania iterrows () . Istnieją różne metody i zwykłe iterrows() jest dalekie od bycia najlepszym. itertuples () może być 100 razy szybszy.
W skrócie:
- jako ogólną zasadę należy stosować
df.itertuples(name=None). W szczególności, gdy masz stałą liczbę kolumn i mniej niż 255 kolumn. zobacz punkt (3) - w przeciwnym razie użyj
df.itertuples(), chyba że kolumny mają znaki specjalne, takie jak spacje lub '-'. patrz punkt (2) - możliwe jest użycie
itertuples()nawet jeśli ramka danych ma dziwne kolumny, używając ostatniego przykładu. patrz punkt (4) - używać tylko
iterrows()Jeśli nie można zastosować poprzednich rozwiązań. patrz punkt (1)
Wygeneruj losowy dataframe z milion wierszy i 4 kolumny:
df = pd.DataFrame(np.random.randint(0, 100, size=(1000000, 4)), columns=list('ABCD'))
print(df)
1) zwykłe {[6] } jest wygodne, ale cholernie powolne:
start_time = time.clock()
result = 0
for _, row in df.iterrows():
result += max(row['B'], row['C'])
total_elapsed_time = round(time.clock() - start_time, 2)
print("1. Iterrows done in {} seconds, result = {}".format(total_elapsed_time, result))
2) domyślna itertuples() jest już znacznie szybsza, ale nie działa z nazwami kolumn, takimi jak My Col-Name is very Strange (należy unikać tej metody, jeśli kolumny są powtarzane lub jeśli nazwa kolumny nie może być po prostu przekonwertowana na nazwę zmiennej Pythona).:
start_time = time.clock()
result = 0
for row in df.itertuples(index=False):
result += max(row.B, row.C)
total_elapsed_time = round(time.clock() - start_time, 2)
print("2. Named Itertuples done in {} seconds, result = {}".format(total_elapsed_time, result))
3) domyślne itertuples() użycie name = None jest jeszcze szybsze, ale niezbyt wygodne, ponieważ trzeba zdefiniować zmienną na kolumna.
start_time = time.clock()
result = 0
for(_, col1, col2, col3, col4) in df.itertuples(name=None):
result += max(col2, col3)
total_elapsed_time = round(time.clock() - start_time, 2)
print("3. Itertuples done in {} seconds, result = {}".format(total_elapsed_time, result))
4) Wreszcie, nazwa {[9] } jest wolniejsza od poprzedniego punktu, ale nie musisz definiować zmiennej dla kolumny i działa z nazwami kolumn, takimi jak My Col-Name is very Strange.
start_time = time.clock()
result = 0
for row in df.itertuples(index=False):
result += max(row[df.columns.get_loc('B')], row[df.columns.get_loc('C')])
total_elapsed_time = round(time.clock() - start_time, 2)
print("4. Polyvalent Itertuples working even with special characters in the column name done in {} seconds, result = {}".format(total_elapsed_time, result))
Wyjście:
A B C D
0 41 63 42 23
1 54 9 24 65
2 15 34 10 9
3 39 94 82 97
4 4 88 79 54
... .. .. .. ..
999995 48 27 4 25
999996 16 51 34 28
999997 1 39 61 14
999998 66 51 27 70
999999 51 53 47 99
[1000000 rows x 4 columns]
1. Iterrows done in 104.96 seconds, result = 66151519
2. Named Itertuples done in 1.26 seconds, result = 66151519
3. Itertuples done in 0.94 seconds, result = 66151519
4. Polyvalent Itertuples working even with special characters in the column name done in 2.94 seconds, result = 66151519
Ten artykuł jest bardzo interesującym porównaniem między iterrows i itertuples
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-06-11 13:43:59
Szukałem Jak iterować na wierszach oraz kolumny i kończyły się tutaj tak:
for i, row in df.iterrows():
for j, column in row.iteritems():
print(column)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-06-11 13:37:53
Możesz napisać swój własny iterator, który implementuje namedtuple
from collections import namedtuple
def myiter(d, cols=None):
if cols is None:
v = d.values.tolist()
cols = d.columns.values.tolist()
else:
j = [d.columns.get_loc(c) for c in cols]
v = d.values[:, j].tolist()
n = namedtuple('MyTuple', cols)
for line in iter(v):
yield n(*line)
Jest to bezpośrednio porównywalne z pd.DataFrame.itertuples. Staram się wykonywać to samo zadanie z większą wydajnością.
Dla podanego dataframe z moją funkcją:
list(myiter(df))
[MyTuple(c1=10, c2=100), MyTuple(c1=11, c2=110), MyTuple(c1=12, c2=120)]
Lub z pd.DataFrame.itertuples:
list(df.itertuples(index=False))
[Pandas(c1=10, c2=100), Pandas(c1=11, c2=110), Pandas(c1=12, c2=120)]
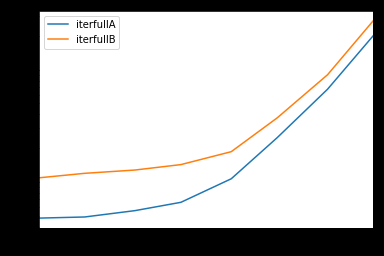
Kompleksowy test
Testujemy udostępnianie wszystkich kolumn i ich podzbiory.
def iterfullA(d):
return list(myiter(d))
def iterfullB(d):
return list(d.itertuples(index=False))
def itersubA(d):
return list(myiter(d, ['col3', 'col4', 'col5', 'col6', 'col7']))
def itersubB(d):
return list(d[['col3', 'col4', 'col5', 'col6', 'col7']].itertuples(index=False))
res = pd.DataFrame(
index=[10, 30, 100, 300, 1000, 3000, 10000, 30000],
columns='iterfullA iterfullB itersubA itersubB'.split(),
dtype=float
)
for i in res.index:
d = pd.DataFrame(np.random.randint(10, size=(i, 10))).add_prefix('col')
for j in res.columns:
stmt = '{}(d)'.format(j)
setp = 'from __main__ import d, {}'.format(j)
res.at[i, j] = timeit(stmt, setp, number=100)
res.groupby(res.columns.str[4:-1], axis=1).plot(loglog=True);

Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-11-07 04:29:57
for ind in df.index:
print df['c1'][ind], df['c2'][ind]
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-05-07 06:37:44
Aby zapętlić wszystkie wiersze w dataframe możesz użyć:
for x in range(len(date_example.index)):
print date_example['Date'].iloc[x]
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-04-04 20:46:53
Czasem użytecznym wzorem jest:
# Borrowing @KutalmisB df example
df = pd.DataFrame({'col1': [1, 2], 'col2': [0.1, 0.2]}, index=['a', 'b'])
# The to_dict call results in a list of dicts
# where each row_dict is a dictionary with k:v pairs of columns:value for that row
for row_dict in df.to_dict(orient='records'):
print(row_dict)
Co daje:
{'col1':1.0, 'col2':0.1}
{'col1':2.0, 'col2':0.2}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-04-13 23:06:06
Aby zapętlić wszystkie wiersze w dataframe i użyj wartości każdego wiersza wygodnie, namedtuples można przekonwertować na ndarray s. na przykład:
df = pd.DataFrame({'col1': [1, 2], 'col2': [0.1, 0.2]}, index=['a', 'b'])
Iteracja nad wierszami:
for row in df.itertuples(index=False, name='Pandas'):
print np.asarray(row)
Wyniki w:
[ 1. 0.1]
[ 2. 0.2]
Należy pamiętać, że jeśli index=True, indeks jest dodawany jako pierwszy element krotki , co może być niepożądane dla niektórych aplikacji.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-04-24 08:48:05
Do przeglądania i modyfikowania wartości użyłbym iterrows(). W pętli for i za pomocą rozpakowywania krotki (patrz przykład: i, row), używam row Tylko do wyświetlania wartości i używam i z metodą loc, Gdy chcę zmodyfikować wartości. Jak wspomniano w poprzednich odpowiedziach, tutaj nie należy modyfikować czegoś, co jest iteracją.
for i, row in df.iterrows():
df_column_A = df.loc[i, 'A']
if df_column_A == 'Old_Value':
df_column_A = 'New_value'
Tutaj row W pętli jest kopią tego wiersza, a nie jego widokiem. Dlatego nie należy pisać czegoś takiego jak row['A'] = 'New_Value', nie będzie zmodyfikuj ramkę danych. Możesz jednak użyć i i loc i określić ramkę danych do wykonania pracy.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-02-28 17:51:44
Istnieje sposób na iterację rzutów podczas otrzymywania ramki danych w zamian, a nie Serii. Nie widzę, żeby ktoś wspominał, że możesz przekazać indeks jako listę dla wiersza, który ma być zwrócony jako ramka Danych:
for i in range(len(df)):
row = df.iloc[[i]]
Zwróć uwagę na użycie podwójnych nawiasów. Zwraca ramkę danych z jednym wierszem.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-10-17 15:26:30
Cs95 pokazuje, że wektoryzacja pand znacznie przewyższa inne metody pand do przetwarzania danych za pomocą ramek danych.
Chciałem dodać, że jeśli najpierw przekonwertujesz ramkę danych do tablicy NumPy, a następnie użyjesz wektoryzacji, jest to jeszcze szybsze niż wektoryzacja ramki danych Pandy (i to obejmuje czas, aby przekształcić ją z powrotem w serię ramek danych).
Jeśli dodasz następujące funkcje do kodu wzorcowego cs95, stanie się to całkiem widoczne:
def np_vectorization(df):
np_arr = df.to_numpy()
return pd.Series(np_arr[:,0] + np_arr[:,1], index=df.index)
def just_np_vectorization(df):
np_arr = df.to_numpy()
return np_arr[:,0] + np_arr[:,1]

Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-06-11 12:39:21
Jest tak wiele sposobów na iterację wierszy w ramce danych Pandy. Jednym z bardzo prostych i intuicyjnych sposobów jest:
df = pd.DataFrame({'A':[1, 2, 3], 'B':[4, 5, 6], 'C':[7, 8, 9]})
print(df)
for i in range(df.shape[0]):
# For printing the second column
print(df.iloc[i, 1])
# For printing more than one columns
print(df.iloc[i, [0, 2]])
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-06-11 13:38:59
W skrócie
- Użyj wektoryzacji, jeśli to możliwe
- jeśli operacja nie może być wektoryzowana-użyj list comprehensions
- Jeśli potrzebujesz pojedynczego obiektu reprezentującego cały wiersz-użyj itertuples
- Jeśli powyższe jest zbyt wolne-spróbuj swifter.Zastosuj Jeśli nadal jest za wolno - wypróbuj rutynę Cython]}
Benchmark

Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-07-28 20:08:44
Najprostszym sposobem jest użycie funkcji apply
def print_row(row):
print row['c1'], row['c2']
df.apply(lambda row: print_row(row), axis=1)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-11-02 21:35:10
Możesz również zrobić indeksowanie NumPy dla jeszcze większych przyspieszeń. To nie jest naprawdę iteracja, ale działa znacznie lepiej niż iteracja dla niektórych aplikacji.
subset = row['c1'][0:5]
all = row['c1'][:]
Możesz też wrzucić go do tablicy. Te indeksy / selekcje mają już działać jak tablice NumPy, ale napotkałem problemy i musiałem rzucić
np.asarray(all)
imgs[:] = cv2.resize(imgs[:], (224,224) ) # Resize every image in an hdf5 file
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-06-11 13:37:16
Ten przykład wykorzystuje iloc do wyizolowania każdej cyfry w ramce danych.
import pandas as pd
a = [1, 2, 3, 4]
b = [5, 6, 7, 8]
mjr = pd.DataFrame({'a':a, 'b':b})
size = mjr.shape
for i in range(size[0]):
for j in range(size[1]):
print(mjr.iloc[i, j])
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-03-16 22:33:02
Niektóre biblioteki (np. Biblioteka Java interop, której używam) wymagają przekazywania wartości w wierszu na raz, na przykład podczas przesyłania strumieniowego danych. Aby odtworzyć naturę streamingu, "stream" moje wartości ramki danych jeden po drugim, napisałem poniżej, co przydaje się od czasu do czasu.
class DataFrameReader:
def __init__(self, df):
self._df = df
self._row = None
self._columns = df.columns.tolist()
self.reset()
self.row_index = 0
def __getattr__(self, key):
return self.__getitem__(key)
def read(self) -> bool:
self._row = next(self._iterator, None)
self.row_index += 1
return self._row is not None
def columns(self):
return self._columns
def reset(self) -> None:
self._iterator = self._df.itertuples()
def get_index(self):
return self._row[0]
def index(self):
return self._row[0]
def to_dict(self, columns: List[str] = None):
return self.row(columns=columns)
def tolist(self, cols) -> List[object]:
return [self.__getitem__(c) for c in cols]
def row(self, columns: List[str] = None) -> Dict[str, object]:
cols = set(self._columns if columns is None else columns)
return {c : self.__getitem__(c) for c in self._columns if c in cols}
def __getitem__(self, key) -> object:
# the df index of the row is at index 0
try:
if type(key) is list:
ix = [self._columns.index(key) + 1 for k in key]
else:
ix = self._columns.index(key) + 1
return self._row[ix]
except BaseException as e:
return None
def __next__(self) -> 'DataFrameReader':
if self.read():
return self
else:
raise StopIteration
def __iter__(self) -> 'DataFrameReader':
return self
Które mogą być użyte:
for row in DataFrameReader(df):
print(row.my_column_name)
print(row.to_dict())
print(row['my_column_name'])
print(row.tolist())
I zachowuje mapowanie wartości/ nazw dla iterowanych wierszy. Oczywiście, jest o wiele wolniejsze niż stosowanie apply i Cython jak wskazano powyżej, ale jest konieczne w w pewnych okolicznościach.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-12-10 09:36:45
Wraz z wielkimi odpowiedziami w tym poście zamierzam zaproponowaćDivide and Conquer podejście, nie piszę tej odpowiedzi, aby znieść inne wielkie odpowiedzi, ale aby je wypełnić innym podejściem, które działało efektywnie dla mnie. Ma dwa etapy splitting i merging ramka danych pandy:
Zalety dzielenia i zdobywania:
- nie musisz używać wektoryzacji ani żadnych innych metod, aby wrzucić typ ramki danych do innego Typ
- nie musisz cytować kodu, który zwykle wymaga od Ciebie dodatkowego czasu
- oba
iterrows()iitertuples()w moim przypadku miały taką samą wydajność w całym dataframe - zależy od wyboru krojenia
index, będziesz w stanie wykładniczo przyspieszyć iterację. Im wyższyindex, tym szybszy proces iteracji.
Wady dzielenia i zdobywania:
- nie powinieneś mieć zależności nad procesem iteracji do ten sam dataframe i inny slice . Oznacza to, że jeśli chcesz czytać lub pisać z innych , może trudno to zrobić.
=================== podejście "dziel i rządź"=================
Krok 1: Dzielenie / Krojenie
W tym kroku podzielimy iterację na całą ramkę danych. Pomyśl, że będziesz czytać plik csv do pandas df, a następnie iterate nad nim. W maju mam 5.000.000 records i podzielę ją na 100,000 płyt.
Notatka: muszę powtórzyć jak inne analizy runtime wyjaśnione w innych rozwiązaniach na tej stronie, "Liczba rekordów" ma wykładniczy udział "runtime" w wyszukiwaniu na df. W oparciu o benchmark na moich danych oto wyniki:
Number of records | Iteration per second
========================================
100,000 | 500 it/s
500,000 | 200 it/s
1,000,000 | 50 it/s
5,000,000 | 20 it/s
Krok 2: Scalanie
To będzie prosty krok, po prostu połącz wszystkie zapisane pliki csv w jedną ramkę danych i zapisz je do większego pliku csv plik.
Oto przykładowy kod:
# Step 1 (Splitting/Slicing)
import pandas as pd
df_all = pd.read_csv('C:/KtV.csv')
df_index = 100000
df_len = len(df)
for i in range(df_len // df_index + 1):
lower_bound = i * df_index
higher_bound = min(lower_bound + df_index, df_len)
# splitting/slicing df (make sure to copy() otherwise it will be a view
df = df_all[lower_bound:higher_bound].copy()
'''
write your iteration over the sliced df here
using iterrows() or intertuples() or ...
'''
# writing into csv files
df.to_csv('C:/KtV_prep_'+str(i)+'.csv')
# Step 2 (Merging)
filename='C:/KtV_prep_'
df = (pd.read_csv(f) for f in [filename+str(i)+'.csv' for i in range(ktv_len // ktv_index + 1)])
df_prep_all = pd.concat(df)
df_prep_all.to_csv('C:/KtV_prep_all.csv')
Numer referencyjny:
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-10-31 13:57:20
Jak wiele odpowiedzi tutaj poprawnie i jasno wskazuje, nie powinieneś generalnie próbować zapętlić pandy, ale raczej powinieneś napisać wektorowy Kod. Pozostaje jednak pytanie, czy powinieneś kiedykolwiek pisać pętle w pandach, a jeśli tak, to najlepszy sposób na zapętlenie w takich sytuacjach.
Uważam, że jest przynajmniej jedna ogólna sytuacja, w której pętle są odpowiednie: kiedy trzeba obliczyć jakąś funkcję, która zależy od wartości w Inne wiersze w nieco skomplikowany sposób. W tym w przypadku kod zapętlający jest często prostszy, bardziej czytelny i mniej podatny na błędy niż kod wektorowy. kod zapętlający może być nawet szybszy.
Postaram się to pokazać na przykładzie. Załóżmy, że chcesz pobrać skumulowaną sumę kolumny, ale zresetuj ją, gdy inna kolumna równa się zero:import pandas as pd
import numpy as np
df = pd.DataFrame( { 'x':[1,2,3,4,5,6], 'y':[1,1,1,0,1,1] } )
# x y desired_result
#0 1 1 1
#1 2 1 3
#2 3 1 6
#3 4 0 4
#4 5 1 9
#5 6 1 15
Jest to dobry przykład, gdzie z pewnością można napisać jedną linijkę pand, aby to osiągnąć, chociaż nie jest to szczególnie czytelne, zwłaszcza jeśli nie jesteś uczciwy doświadczony z pand już:
df.groupby( (df.y==0).cumsum() )['x'].cumsum()
To będzie wystarczająco szybkie w większości sytuacji, chociaż możesz również napisać szybszy kod unikając groupby, ale prawdopodobnie będzie jeszcze mniej czytelny.
Alternatywnie, co jeśli zapiszemy to jako pętlę? Możesz zrobić coś takiego z numpy:
import numba as nb
@nb.jit(nopython=True) # optional
def custom_sum(x,y):
x_sum = x.copy()
for i in range(1,len(df)):
if y[i] > 0: x_sum[i] = x_sum[i-1] + x[i]
return x_sum
df['desired_result'] = custom_sum( df.x.to_numpy(), df.y.to_numpy() )
Trzeba przyznać, że do konwersji kolumn ramki danych na tablice numpy potrzeba trochę narzutu, ale rdzeń kodu to tylko jedna linijka kodu, którą można możesz przeczytać nawet jeśli nie wiesz nic o pandach lub numpy:
if y[i] > 0: x_sum[i] = x_sum[i-1] + x[i]
I ten kod jest w rzeczywistości szybszy niż wektoryzowany kod. W niektórych szybkich testach z 100 000 wierszy, powyższe jest około 10x szybsze niż podejście groupby. Zauważ, że jednym z kluczy do prędkości jest numba, czyli opcje. Bez " @ nb.JIT", kod zapętlający jest w rzeczywistości około 10x wolniejszy niż podejście groupby.
Oczywiście ten przykład jest na tyle prosty, że prawdopodobnie wolisz jedna linia pand do pisania pętli z towarzyszącym jej napowietrznym. Istnieją jednak bardziej złożone wersje tego problemu, dla których czytelność lub szybkość pętli numpy/numba prawdopodobnie ma sens.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-12-22 17:15:46