Jak zaimportować wiele.pliki csv na raz?
Załóżmy, że mamy folder zawierający wiele danych.pliki csv, każdy zawierający tę samą liczbę zmiennych, ale każdy z różnych czasów. Czy istnieje sposób w R, aby importować je wszystkie jednocześnie, zamiast importować je wszystkie pojedynczo?
Mój problem polega na tym, że mam około 2000 plików danych do zaimportowania i muszę importować je pojedynczo za pomocą kodu:
read.delim(file="filename", header=TRUE, sep="\t")
13 answers
Coś takiego powinno skutkować każdą ramką danych jako oddzielnym elementem na jednej liście:
temp = list.files(pattern="*.csv")
myfiles = lapply(temp, read.delim)
Zakłada to, że masz te pliki CSV w jednym katalogu -- bieżącym katalogu roboczym -- i że wszystkie z nich mają małe litery rozszerzenia .csv.
Jeśli chcesz połączyć te ramki danych w jedną ramkę danych, zobacz rozwiązania w innych odpowiedziach za pomocą takich rzeczy, jak do.call(rbind,...), dplyr::bind_rows() lub data.table::rbindlist().
Jeśli naprawdę chcesz, aby każda ramka danych w oddzielny obiekt, mimo że często jest to niewskazane, możesz wykonać następujące czynności za pomocą assign:
temp = list.files(pattern="*.csv")
for (i in 1:length(temp)) assign(temp[i], read.csv(temp[i]))
Lub, bez assign, i aby zademonstrować (1) Jak można wyczyścić nazwę pliku i (2) Jak używać list2env, Możesz spróbować:
temp = list.files(pattern="*.csv")
list2env(
lapply(setNames(temp, make.names(gsub("*.csv$", "", temp))),
read.csv), envir = .GlobalEnv)
Ale często lepiej zostawić je na jednej liście.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-08-03 19:32:41
Szybkie i zwięzłe tidyverse rozwiązanie:
(ponad dwa razy szybciej niż Baza R ' S read.csv)
tbl <-
list.files(pattern = "*.csv") %>%
map_df(~read_csv(.))
I dane.tabela ' s fread() może nawet skrócić czas ładowania o połowę. (dla 1/4 bazy R razy)
library(data.table)
tbl_fread <-
list.files(pattern = "*.csv") %>%
map_df(~fread(.))
The stringsAsFactors = FALSE argument zachowuje wolny współczynnik ramki danych (i jak wskazuje marbel, jest domyślnym ustawieniem dla fread)
Jeśli typecasting jest bezczelny, możesz wymusić wszystkie kolumny jako znaki z argumentem col_types.
tbl <-
list.files(pattern = "*.csv") %>%
map_df(~read_csv(., col_types = cols(.default = "c")))
Jeśli chcesz zanurzyć się w podkatalogach, aby utworzyć listę plików, aby ostatecznie powiązać, pamiętaj, aby podać nazwę ścieżki, a także zarejestrować pliki z ich pełnymi nazwami na liście. Pozwoli to na kontynuowanie pracy wiązania poza bieżącym katalogiem. (Myślenie o pełnych nazwach ścieżek jako działających jak paszporty, aby umożliwić przemieszczanie się z powrotem przez "granice" katalogu.)
tbl <-
list.files(path = "./subdirectory/",
pattern = "*.csv",
full.names = T) %>%
map_df(~read_csv(., col_types = cols(.default = "c")))
Jak opisuje Hadley tutaj
map_df(x, f)jest tym samym codo.call("rbind", lapply(x, f))....
Bonus Feature - dodawanie nazw plików do rekordów na żądanie funkcji Niks w komentarzach poniżej:
* Dodaj Oryginalny filename do każdego rekordu.
Kod wyjaśniony: Utwórz funkcję do dołączania nazwy pliku do każdego rekordu podczas wstępnego czytania tabel. Następnie użyj tej funkcji zamiast prostej read_csv().
read_plus <- function(flnm) {
read_csv(flnm) %>%
mutate(filename = flnm)
}
tbl_with_sources <-
list.files(pattern = "*.csv",
full.names = T) %>%
map_df(~read_plus(.))
(typowanie metody obsługi podkatalogów mogą być również obsługiwane wewnątrz funkcji read_plus() w taki sam sposób, jak pokazano w drugim i trzecim wariancie zaproponowanym powyżej.)
### Benchmark Code & Results
library(tidyverse)
library(data.table)
library(microbenchmark)
### Base R Approaches
#### Instead of a dataframe, this approach creates a list of lists
#### removed from analysis as this alone doubled analysis time reqd
# lapply_read.delim <- function(path, pattern = "*.csv") {
# temp = list.files(path, pattern, full.names = TRUE)
# myfiles = lapply(temp, read.delim)
# }
#### `read.csv()`
do.call_rbind_read.csv <- function(path, pattern = "*.csv") {
files = list.files(path, pattern, full.names = TRUE)
do.call(rbind, lapply(files, function(x) read.csv(x, stringsAsFactors = FALSE)))
}
map_df_read.csv <- function(path, pattern = "*.csv") {
list.files(path, pattern, full.names = TRUE) %>%
map_df(~read.csv(., stringsAsFactors = FALSE))
}
### *dplyr()*
#### `read_csv()`
lapply_read_csv_bind_rows <- function(path, pattern = "*.csv") {
files = list.files(path, pattern, full.names = TRUE)
lapply(files, read_csv) %>% bind_rows()
}
map_df_read_csv <- function(path, pattern = "*.csv") {
list.files(path, pattern, full.names = TRUE) %>%
map_df(~read_csv(., col_types = cols(.default = "c")))
}
### *data.table* / *purrr* hybrid
map_df_fread <- function(path, pattern = "*.csv") {
list.files(path, pattern, full.names = TRUE) %>%
map_df(~fread(.))
}
### *data.table*
rbindlist_fread <- function(path, pattern = "*.csv") {
files = list.files(path, pattern, full.names = TRUE)
rbindlist(lapply(files, function(x) fread(x)))
}
do.call_rbind_fread <- function(path, pattern = "*.csv") {
files = list.files(path, pattern, full.names = TRUE)
do.call(rbind, lapply(files, function(x) fread(x, stringsAsFactors = FALSE)))
}
read_results <- function(dir_size){
microbenchmark(
# lapply_read.delim = lapply_read.delim(dir_size), # too slow to include in benchmarks
do.call_rbind_read.csv = do.call_rbind_read.csv(dir_size),
map_df_read.csv = map_df_read.csv(dir_size),
lapply_read_csv_bind_rows = lapply_read_csv_bind_rows(dir_size),
map_df_read_csv = map_df_read_csv(dir_size),
rbindlist_fread = rbindlist_fread(dir_size),
do.call_rbind_fread = do.call_rbind_fread(dir_size),
map_df_fread = map_df_fread(dir_size),
times = 10L)
}
read_results_lrg_mid_mid <- read_results('./testFolder/500MB_12.5MB_40files')
print(read_results_lrg_mid_mid, digits = 3)
read_results_sml_mic_mny <- read_results('./testFolder/5MB_5KB_1000files/')
read_results_sml_tny_mod <- read_results('./testFolder/5MB_50KB_100files/')
read_results_sml_sml_few <- read_results('./testFolder/5MB_500KB_10files/')
read_results_med_sml_mny <- read_results('./testFolder/50MB_5OKB_1000files')
read_results_med_sml_mod <- read_results('./testFolder/50MB_5OOKB_100files')
read_results_med_med_few <- read_results('./testFolder/50MB_5MB_10files')
read_results_lrg_sml_mny <- read_results('./testFolder/500MB_500KB_1000files')
read_results_lrg_med_mod <- read_results('./testFolder/500MB_5MB_100files')
read_results_lrg_lrg_few <- read_results('./testFolder/500MB_50MB_10files')
read_results_xlg_lrg_mod <- read_results('./testFolder/5000MB_50MB_100files')
print(read_results_sml_mic_mny, digits = 3)
print(read_results_sml_tny_mod, digits = 3)
print(read_results_sml_sml_few, digits = 3)
print(read_results_med_sml_mny, digits = 3)
print(read_results_med_sml_mod, digits = 3)
print(read_results_med_med_few, digits = 3)
print(read_results_lrg_sml_mny, digits = 3)
print(read_results_lrg_med_mod, digits = 3)
print(read_results_lrg_lrg_few, digits = 3)
print(read_results_xlg_lrg_mod, digits = 3)
# display boxplot of my typical use case results & basic machine max load
par(oma = c(0,0,0,0)) # remove overall margins if present
par(mfcol = c(1,1)) # remove grid if present
par(mar = c(12,5,1,1) + 0.1) # to display just a single boxplot with its complete labels
boxplot(read_results_lrg_mid_mid, las = 2, xlab = "", ylab = "Duration (seconds)", main = "40 files @ 12.5MB (500MB)")
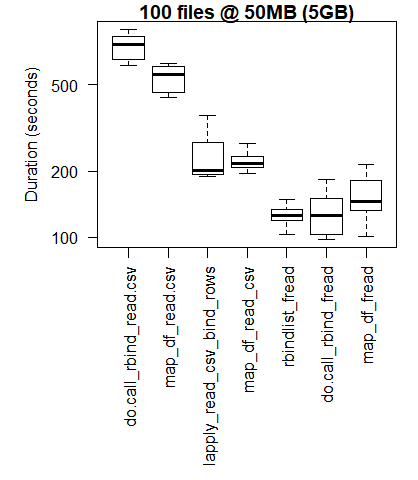
boxplot(read_results_xlg_lrg_mod, las = 2, xlab = "", ylab = "Duration (seconds)", main = "100 files @ 50MB (5GB)")
# generate 3x3 grid boxplots
par(oma = c(12,1,1,1)) # margins for the whole 3 x 3 grid plot
par(mfcol = c(3,3)) # create grid (filling down each column)
par(mar = c(1,4,2,1)) # margins for the individual plots in 3 x 3 grid
boxplot(read_results_sml_mic_mny, las = 2, xlab = "", ylab = "Duration (seconds)", main = "1000 files @ 5KB (5MB)", xaxt = 'n')
boxplot(read_results_sml_tny_mod, las = 2, xlab = "", ylab = "Duration (milliseconds)", main = "100 files @ 50KB (5MB)", xaxt = 'n')
boxplot(read_results_sml_sml_few, las = 2, xlab = "", ylab = "Duration (milliseconds)", main = "10 files @ 500KB (5MB)",)
boxplot(read_results_med_sml_mny, las = 2, xlab = "", ylab = "Duration (microseconds) ", main = "1000 files @ 50KB (50MB)", xaxt = 'n')
boxplot(read_results_med_sml_mod, las = 2, xlab = "", ylab = "Duration (microseconds)", main = "100 files @ 500KB (50MB)", xaxt = 'n')
boxplot(read_results_med_med_few, las = 2, xlab = "", ylab = "Duration (seconds)", main = "10 files @ 5MB (50MB)")
boxplot(read_results_lrg_sml_mny, las = 2, xlab = "", ylab = "Duration (seconds)", main = "1000 files @ 500KB (500MB)", xaxt = 'n')
boxplot(read_results_lrg_med_mod, las = 2, xlab = "", ylab = "Duration (seconds)", main = "100 files @ 5MB (500MB)", xaxt = 'n')
boxplot(read_results_lrg_lrg_few, las = 2, xlab = "", ylab = "Duration (seconds)", main = "10 files @ 50MB (500MB)")
Middling Use Case

Większy Przypadek Użycia
Różnorodność przypadków użycia
Wiersze: liczba plików(1000, 100, 10)
Kolumny: ostateczny rozmiar ramki danych (5MB, 50MB, 500MB)
(kliknij na obrazek, aby zobaczyć oryginał rozmiar)

Podstawowe wyniki R są lepsze dla najmniejszych przypadków użycia, w których obciążenie bibliotek C purrr i dplyr przewyższa wzrost wydajności, który jest obserwowany podczas wykonywania zadań przetwarzania na większą skalę.
Jeśli chcesz uruchomić własne testy, ten skrypt bash może okazać się pomocny.
for ((i=1; i<=$2; i++)); do
cp "$1" "${1:0:8}_${i}.csv";
done
bash what_you_name_this_script.sh "fileName_you_want_copied" 100 utworzy 100 kopii pliku kolejno ponumerowanych (po pierwszych 8 znakach nazwy pliku i podkreślenie).
Uznanie i uznanie
Ze szczególnymi podziękowaniami dla:
- Tyler Rinker i Akrun do demonstracji microbenchmark.
- Jake Kaupp za wprowadzenie mnie do
map_df()tutaj . - David McLaughlin za pomocną informację zwrotną na temat poprawy wizualizacji i omówienia / potwierdzenia inwersji wydajności zaobserwowanych w małym pliku, wynikach analizy małych ramek danych.
- marbel dla wskazując domyślne zachowanie dla
fread(). (Muszę się uczyć nadata.table.)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-07-03 17:42:20
Oto kilka opcji do konwersji .pliki csv w jedno dane.ramka wykorzystująca bazę R i niektóre z dostępnych pakietów do odczytu plików w R.
Jest to wolniejsze niż poniższe opcje.
# Get the files names
files = list.files(pattern="*.csv")
# First apply read.csv, then rbind
myfiles = do.call(rbind, lapply(files, function(x) read.csv(x, stringsAsFactors = FALSE)))
Edit: - Kilka dodatkowych opcji za pomocą data.table i readr
A fread() wersja, która jest funkcją pakietu data.table. jest to zdecydowanie najszybsza opcja w R .
library(data.table)
DT = do.call(rbind, lapply(files, fread))
# The same using `rbindlist`
DT = rbindlist(lapply(files, fread))
Using readr , czyli kolejny pakiet do odczytu plików csv. Jest wolniejszy od fread, szybszy od bazy R, ale ma inne funkcjonalności.
library(readr)
library(dplyr)
tbl = lapply(files, read_csv) %>% bind_rows()
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-11-23 00:31:07
Jak również za pomocą lapply lub innego looping construct w R możesz połączyć swoje pliki CSV w jeden plik.
W Unixie, jeśli pliki nie miały nagłówków, to jest tak proste jak:
cat *.csv > all.csv
Lub jeśli są nagłówki i możesz znaleźć ciąg pasujący do nagłówków i tylko nagłówki (tj. przypuśćmy, że wszystkie linie nagłówków zaczynają się od "wieku"), wykonasz:
cat *.csv | grep -v ^Age > all.csv
Myślę, że w Windows można to zrobić z COPY i SEARCH (lub FIND lub coś) z pola poleceń DOS, ale dlaczego nie zainstalować cygwin i uzyskać moc powłoki poleceń Uniksa?
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-07-11 13:28:30
Jest to kod, który opracowałem, aby odczytać wszystkie pliki csv do R. utworzy ramkę danych dla każdego pliku csv indywidualnie i tytuł, który ramka danych oryginalnej nazwy pliku (usuwanie spacji i .csv) mam nadzieję, że okaże się to przydatne!
path <- "C:/Users/cfees/My Box Files/Fitness/"
files <- list.files(path=path, pattern="*.csv")
for(file in files)
{
perpos <- which(strsplit(file, "")[[1]]==".")
assign(
gsub(" ","",substr(file, 1, perpos-1)),
read.csv(paste(path,file,sep="")))
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-02-05 21:44:09
Trzy pierwsze odpowiedzi autorstwa @a5c1d2h2i1m1n2o1r2t1, @leerssej i @marbel są zasadniczo takie same: zastosuj fread do każdego pliku, a następnie rbind/rbindlist wynikowe dane.stoły. Zazwyczaj używam formularza rbindlist(lapply(list.files("*.csv"),fread)).
cat może być znacznie szybsze, jak sugeruje @Spacedman w odpowiedzi na 4. miejsce. Dodam kilka szczegółów jak to zrobić z wewnątrz R:
x = fread(cmd='cat *.csv', header=F)
Co jednak, jeśli każdy plik csv ma nagłówek?
x = fread(cmd="awk 'NR==1||FNR!=1' *.csv", header=T)
A co jeśli masz tyle Plików, że powłoka glob zawiedzie?
x = fread(cmd='find . -name "*.csv" | xargs cat', header=F)
A co jeśli wszystkie pliki mają nagłówek i jest ich za dużo?
header = fread(cmd='find . -name "*.csv" | head -n1 | xargs head -n1', header=T)
x = fread(cmd='find . -name "*.csv" | xargs tail -q -n+2', header=F)
names(x) = names(header)
A co jeśli skonkatenowany plik csv jest za duży na pamięć systemową?
system('find . -name "*.csv" | xargs cat > combined.csv')
x = fread('combined.csv', header=F)
Z nagłówkami?
system('find . -name "*.csv" | head -n1 | xargs head -n1 > combined.csv')
system('find . -name "*.csv" | xargs tail -q -n+2 >> combined.csv')
x = fread('combined.csv', header=T)
fread(text=paste0(system("xargs cat|awk 'NR==1||$1!=\"<column one name>\"'",input=paths,intern=T),collapse="\n"),header=T,sep="\t")
A to jest mniej więcej taka sama prędkość jak zwykły fread xargs cat:)
Uwaga: dla danych.tabela pre-v1.11.6 (19 Sep 2018), pomiń cmd= z fread(cmd=.
Dodatek: Użycie biblioteki równoległej mclapply zamiast szeregowego lapply, np. rbindlist(lapply(list.files("*.csv"),fread)) jest również znacznie szybsze niż rbindlist lapply fread.
Czas odczytać 121401 CSV w jednym pliku danych.stolik. Każdy csv ma 3 kolumny, jedna wiersz nagłówka, a średnio 4.510 wierszy. Maszyna jest maszyną wirtualną GCP z 96 rdzeniami:
rbindlist lapply fread 234.172s 247.513s 256.349s
rbindlist mclapply fread 15.223s 9.558s 9.292s
fread xargs cat 4.761s 4.259s 5.095s
Podsumowując, jeśli interesuje Cię szybkość i masz wiele plików i wiele rdzeni, fread xargs cat jest około 50x szybszy niż najszybsze rozwiązanie w top 3 odpowiedzi.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-06-16 10:47:56
Moim zdaniem większość innych odpowiedzi jest przestarzała przez rio::import_list, która jest zwięzłą jednowierszową:
library(rio)
my_data <- import_list(dir("path_to_directory", pattern = ".csv", rbind = TRUE))
Wszelkie dodatkowe argumenty są przekazywane do rio::import. {[3] } może poradzić sobie z prawie każdym formatem pliku, który R może odczytać, i używa data.table'S fread, gdzie to możliwe, więc powinien być również szybki.
Użycie plyr::ldply powoduje około 50% zwiększenie prędkości poprzez włączenie opcji .parallel Podczas odczytu 400 plików csv o około 30-40 MB każdy. Przykład zawiera pasek postępu tekstu.
library(plyr)
library(data.table)
library(doSNOW)
csv.list <- list.files(path="t:/data", pattern=".csv$", full.names=TRUE)
cl <- makeCluster(4)
registerDoSNOW(cl)
pb <- txtProgressBar(max=length(csv.list), style=3)
pbu <- function(i) setTxtProgressBar(pb, i)
dt <- setDT(ldply(csv.list, fread, .parallel=TRUE, .paropts=list(.options.snow=list(progress=pbu))))
stopCluster(cl)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-12-16 23:55:51
Oto mój konkretny przykład odczytu wielu plików i łączenia ich w jedną ramkę danych:
path<- file.path("C:/folder/subfolder")
files <- list.files(path=path, pattern="/*.csv",full.names = T)
library(data.table)
data = do.call(rbind, lapply(files, function(x) read.csv(x, stringsAsFactors = FALSE)))
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-01-18 02:15:37
Bazując na komentarzu dnlbrk, przypisywanie może być znacznie szybsze niż list2env dla dużych plików.
library(readr)
library(stringr)
List_of_file_paths <- list.files(path ="C:/Users/Anon/Documents/Folder_with_csv_files/", pattern = ".csv", all.files = TRUE, full.names = TRUE)
Ustawiając pełną.nazwa argumentu do true, otrzymasz pełną ścieżkę do każdego pliku jako osobny ciąg znaków na liście plików, np. List_of_file_paths[1] będzie coś w stylu "C:/Users/Anon/Documents/Folder_with_csv_files/file1.csv "
for(f in 1:length(List_of_filepaths)) {
file_name <- str_sub(string = List_of_filepaths[f], start = 46, end = -5)
file_df <- read_csv(List_of_filepaths[f])
assign( x = file_name, value = file_df, envir = .GlobalEnv)
}
for(f in 1:length(List_of_filepaths)) {
file_name <- str_sub(string = List_of_filepaths[f], start = 46, end = -5)
file_df <- read_csv(List_of_filepaths[f])
file_df <- file_df[,1:3] #if you only need the first three columns
assign( x = file_name, value = file_df, envir = .GlobalEnv)
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-09-24 10:23:08
Następujące kody powinny dać Ci najszybszą prędkość dla dużych danych, o ile masz wiele rdzeni na komputerze:
if (!require("pacman")) install.packages("pacman")
pacman::p_load(doParallel, data.table, stringr)
# get the file name
dir() %>% str_subset("\\.csv$") -> fn
# use parallel setting
(cl <- detectCores() %>%
makeCluster()) %>%
registerDoParallel()
# read and bind all files together
system.time({
big_df <- foreach(
i = fn,
.packages = "data.table"
) %dopar%
{
fread(i, colClasses = "character")
} %>%
rbindlist(fill = TRUE)
})
# end of parallel work
stopImplicitCluster(cl)
Zaktualizowano 2020/04/16: Ponieważ znajduję nowy pakiet dostępny do obliczeń równoległych, alternatywne rozwiązanie jest dostarczane za pomocą następujących kodów.
if (!require("pacman")) install.packages("pacman")
pacman::p_load(future.apply, data.table, stringr)
# get the file name
dir() %>% str_subset("\\.csv$") -> fn
plan(multiprocess)
future_lapply(fn,fread,colClasses = "character") %>%
rbindlist(fill = TRUE) -> res
# res is the merged data.table
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-04-16 01:45:01
Podoba mi się podejście wykorzystujące list.files(), lapply() i list2env() (lub fs::dir_ls(), purrr::map() i list2env()). To wydaje się proste i elastyczne.
Alternatywnie możesz wypróbować mały pakiet {tor} (to-R): domyślnie importuje pliki z katalogu roboczego do listy (warianty list_*()) lub do środowiska globalnego (wariantyload_*()).
Na przykład tutaj przeczytałem wszystkie .pliki csv z mojego katalogu roboczego do listy za pomocą tor::list_csv():
library(tor)
dir()
#> [1] "_pkgdown.yml" "cran-comments.md" "csv1.csv"
#> [4] "csv2.csv" "datasets" "DESCRIPTION"
#> [7] "docs" "inst" "LICENSE.md"
#> [10] "man" "NAMESPACE" "NEWS.md"
#> [13] "R" "README.md" "README.Rmd"
#> [16] "tests" "tmp.R" "tor.Rproj"
list_csv()
#> $csv1
#> x
#> 1 1
#> 2 2
#>
#> $csv2
#> y
#> 1 a
#> 2 b
A teraz Ładuję te pliki do mojego globalnego środowiska z tor::load_csv():
# The working directory contains .csv files
dir()
#> [1] "_pkgdown.yml" "cran-comments.md" "CRAN-RELEASE"
#> [4] "csv1.csv" "csv2.csv" "datasets"
#> [7] "DESCRIPTION" "docs" "inst"
#> [10] "LICENSE.md" "man" "NAMESPACE"
#> [13] "NEWS.md" "R" "README.md"
#> [16] "README.Rmd" "tests" "tmp.R"
#> [19] "tor.Rproj"
load_csv()
# Each file is now available as a dataframe in the global environment
csv1
#> x
#> 1 1
#> 2 2
csv2
#> y
#> 1 a
#> 2 b
Jeśli chcesz odczytać określone pliki, możesz dopasować ich ścieżkę doregexp, ignore.case i invert.
Dla jeszcze większej elastyczności użytkowania list_any(). Pozwala na podanie funkcji czytnika za pomocą argumentu .f.
(path_csv <- tor_example("csv"))
#> [1] "C:/Users/LeporeM/Documents/R/R-3.5.2/library/tor/extdata/csv"
dir(path_csv)
#> [1] "file1.csv" "file2.csv"
list_any(path_csv, read.csv)
#> $file1
#> x
#> 1 1
#> 2 2
#>
#> $file2
#> y
#> 1 a
#> 2 b
Podaj dodatkowe argumenty poprzez ... lub wewnątrz funkcji lambda.
path_csv %>%
list_any(readr::read_csv, skip = 1)
#> Parsed with column specification:
#> cols(
#> `1` = col_double()
#> )
#> Parsed with column specification:
#> cols(
#> a = col_character()
#> )
#> $file1
#> # A tibble: 1 x 1
#> `1`
#> <dbl>
#> 1 2
#>
#> $file2
#> # A tibble: 1 x 1
#> a
#> <chr>
#> 1 b
path_csv %>%
list_any(~read.csv(., stringsAsFactors = FALSE)) %>%
map(as_tibble)
#> $file1
#> # A tibble: 2 x 1
#> x
#> <int>
#> 1 1
#> 2 2
#>
#> $file2
#> # A tibble: 2 x 1
#> y
#> <chr>
#> 1 a
#> 2 b
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-01-07 16:05:18
Poproszono mnie o dodanie tej funkcjonalności do pakietu stackoverflow R. Biorąc pod uwagę, że jest to pakiet tinyverse (i nie może zależeć od pakietów stron trzecich), oto co wymyśliłem: {]}
#' Bulk import data files
#'
#' Read in each file at a path and then unnest them. Defaults to csv format.
#'
#' @param path a character vector of full path names
#' @param pattern an optional \link[=regex]{regular expression}. Only file names which match the regular expression will be returned.
#' @param reader a function that can read data from a file name.
#' @param ... optional arguments to pass to the reader function (eg \code{stringsAsFactors}).
#' @param reducer a function to unnest the individual data files. Use I to retain the nested structure.
#' @param recursive logical. Should the listing recurse into directories?
#'
#' @author Neal Fultz
#' @references \url{https://stackoverflow.com/questions/11433432/how-to-import-multiple-csv-files-at-once}
#'
#' @importFrom utils read.csv
#' @export
read.directory <- function(path='.', pattern=NULL, reader=read.csv, ...,
reducer=function(dfs) do.call(rbind.data.frame, dfs), recursive=FALSE) {
files <- list.files(path, pattern, full.names = TRUE, recursive = recursive)
reducer(lapply(files, reader, ...))
}
Parametryzując funkcję czytnika i reduktora, ludzie mogą korzystać z danych.table lub dplyr, jeśli tak zdecydują, lub po prostu użyj podstawowych funkcji R, które są dobre dla mniejszych zestawów danych.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-04-07 22:33:52