Jak przekształcić dane z długiego do szerokiego formatu
Mam problem z przearanżowaniem poniższej ramki danych:
set.seed(45)
dat1 <- data.frame(
name = rep(c("firstName", "secondName"), each=4),
numbers = rep(1:4, 2),
value = rnorm(8)
)
dat1
name numbers value
1 firstName 1 0.3407997
2 firstName 2 -0.7033403
3 firstName 3 -0.3795377
4 firstName 4 -0.7460474
5 secondName 1 -0.8981073
6 secondName 2 -0.3347941
7 secondName 3 -0.5013782
8 secondName 4 -0.1745357
Chcę przekształcić ją tak, aby każda unikalna zmienna "name "była nazwą wiersza, z" wartościami "jako obserwacjami wzdłuż tego wiersza i" numbers " jako nazwami colnames. Coś w tym stylu:
name 1 2 3 4
1 firstName 0.3407997 -0.7033403 -0.3795377 -0.7460474
5 secondName -0.8981073 -0.3347941 -0.5013782 -0.1745357
melt i cast i kilka innych rzeczy, ale żadna nie sprawdziła się. 12 answers
Using reshape function:
reshape(dat1, idvar = "name", timevar = "numbers", direction = "wide")
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-05-04 23:20:03
Nowy (w 2014 roku) tidyr pakiet również robi to po prostu, z gather()/spread() być warunkami dla melt/cast.
Edit: teraz, w 2019 roku, tidyr v 1.0 uruchomił i ustawił spread i gather na ścieżce deprecacji, preferując zamiast pivot_wider i pivot_longer, które można znaleźć opisane w tej odpowiedzi. Czytaj dalej, jeśli chcesz rzucić okiem na krótkie życie spread/gather.
library(tidyr)
spread(dat1, key = numbers, value = value)
From github ,
tidyrjest przeróbkąreshape2przeznaczoną do dołącz do tidy data framework i współpracuj ramię w ramię zmagrittridplyr, aby zbudować solidny rurociąg do analizy danych.Tak jak
reshape2zrobił mniej niż przekształcił,tidyrzrobił mniej niżreshape2. Został zaprojektowany specjalnie do porządkowania danych, a nie ogólnego przekształcania, które robi {12]}, lub ogólnej agregacji, która przekształciła. W szczególności, wbudowane metody działają tylko dla ramek danych, atidyrnie zapewnia marginesów ani agregacji.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-06-20 09:12:55
Można to zrobić za pomocą funkcji reshape() lub za pomocą melt() / cast() funkcje w pakiecie przekształcania. Dla drugiej opcji przykładowy kod to
library(reshape)
cast(dat1, name ~ numbers)
Lub używając reshape2
library(reshape2)
dcast(dat1, name ~ numbers)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-05-26 14:52:24
Inną opcją, jeśli wydajność jest problemem, jest użycie rozszerzenia data.table reshape2's melt & dcast functions
(odniesienie: efektywne przekształcanie za pomocą danych.tabele )
library(data.table)
setDT(dat1)
dcast(dat1, name ~ numbers, value.var = "value")
# name 1 2 3 4
# 1: firstName 0.1836433 -0.8356286 1.5952808 0.3295078
# 2: secondName -0.8204684 0.4874291 0.7383247 0.5757814
I, od danych.tabela v1.9. 6 możemy odlewać na wielu kolumnach
## add an extra column
dat1[, value2 := value * 2]
## cast multiple value columns
dcast(dat1, name ~ numbers, value.var = c("value", "value2"))
# name value_1 value_2 value_3 value_4 value2_1 value2_2 value2_3 value2_4
# 1: firstName 0.1836433 -0.8356286 1.5952808 0.3295078 0.3672866 -1.6712572 3.190562 0.6590155
# 2: secondName -0.8204684 0.4874291 0.7383247 0.5757814 -1.6409368 0.9748581 1.476649 1.1515627
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-03-27 22:51:39
Używając Twojego przykładowego dataframe, możemy:
xtabs(value ~ name + numbers, data = dat1)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-09-02 07:37:07
W wersji devel tidyr ‘0.8.3.9000’, istnieje pivot_wider i pivot_longer, które są uogólnione do zmiany kształtu (odpowiednio long -> wide, wide -> long) od 1 do wielu kolumn. Korzystanie z danych OP
- pojedyncza kolumna długa - > szeroka
library(dplyr)
library(tidyr)
dat1 %>%
pivot_wider(names_from = numbers, values_from = value)
# A tibble: 2 x 5
# name `1` `2` `3` `4`
# <fct> <dbl> <dbl> <dbl> <dbl>
#1 firstName 0.341 -0.703 -0.380 -0.746
#2 secondName -0.898 -0.335 -0.501 -0.175
- > utworzono kolejną kolumnę do wyświetlania funkcjonalności
dat1 %>%
mutate(value2 = value * 2) %>%
pivot_wider(names_from = numbers, values_from = c("value", "value2"))
# A tibble: 2 x 9
# name value_1 value_2 value_3 value_4 value2_1 value2_2 value2_3 value2_4
# <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#1 firstName 0.341 -0.703 -0.380 -0.746 0.682 -1.41 -0.759 -1.49
#2 secondName -0.898 -0.335 -0.501 -0.175 -1.80 -0.670 -1.00 -0.349
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-07-12 20:14:34
Pozostałe dwie opcje:
Pakiet podstawowy:
df <- unstack(dat1, form = value ~ numbers)
rownames(df) <- unique(dat1$name)
df
sqldf opakowanie:
library(sqldf)
sqldf('SELECT name,
MAX(CASE WHEN numbers = 1 THEN value ELSE NULL END) x1,
MAX(CASE WHEN numbers = 2 THEN value ELSE NULL END) x2,
MAX(CASE WHEN numbers = 3 THEN value ELSE NULL END) x3,
MAX(CASE WHEN numbers = 4 THEN value ELSE NULL END) x4
FROM dat1
GROUP BY name')
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-07-14 17:44:08
Używając bazy R aggregate Funkcja:
aggregate(value ~ name, dat1, I)
# name value.1 value.2 value.3 value.4
#1 firstName 0.4145 -0.4747 0.0659 -0.5024
#2 secondName -0.8259 0.1669 -0.8962 0.1681
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-12-25 04:05:05
Jest bardzo potężny nowy pakiet genius data scientists w Win-Vector (ludzie, którzyvtreat, seplyr i replyr) o nazwie cdata. Implementuje ona zasady "skoordynowanych danych" opisane w niniejszym dokumencie , a także w niniejszym poście na blogu . Chodzi o to, że niezależnie od tego, w jaki sposób organizujesz swoje dane, powinno być możliwe zidentyfikowanie poszczególnych punktów danych za pomocą systemu "współrzędnych danych". Oto fragment ostatniego postu na blogu Johna Mount ' a:
Cały system opiera się na dwóch podstawowych lub operatorów cdata::moveValuesToRowsD() oraz cdata:: moveValuesToColumnsD(). Te operatorzy mają pivot, un-pivot, one-hot kodować, transponować, przenoszenie wiele wierszy i kolumn oraz wiele innych przekształceń jako proste specjalne sprawy.
Łatwo jest napisać wiele różnych operacji pod względem CDATA primitives. Operatory te mogą pracować-w pamięci lub na big data skalowanie (z bazami danych i Apache Spark; Do big data użyj cdata:: moveValuesToRowsN() and cdata:: moveValuesToColumnsN() warianty). Transformatory są sterowane przez stół sterujący, który sam jest diagramem (lub obrazem) transformacji.
Najpierw zbudujemy tabelę kontrolną (szczegóły w blogu ), a następnie wykonamy przenoszenie danych z wierszy do kolumn.
library(cdata)
# first build the control table
pivotControlTable <- buildPivotControlTableD(table = dat1, # reference to dataset
columnToTakeKeysFrom = 'numbers', # this will become column headers
columnToTakeValuesFrom = 'value', # this contains data
sep="_") # optional for making column names
# perform the move of data to columns
dat_wide <- moveValuesToColumnsD(tallTable = dat1, # reference to dataset
keyColumns = c('name'), # this(these) column(s) should stay untouched
controlTable = pivotControlTable# control table above
)
dat_wide
#> name numbers_1 numbers_2 numbers_3 numbers_4
#> 1 firstName 0.3407997 -0.7033403 -0.3795377 -0.7460474
#> 2 secondName -0.8981073 -0.3347941 -0.5013782 -0.1745357
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-12-23 23:01:37
Baza reshape funkcja działa doskonale:
df <- data.frame(
year = c(rep(2000, 12), rep(2001, 12)),
month = rep(1:12, 2),
values = rnorm(24)
)
df_wide <- reshape(df, idvar="year", timevar="month", v.names="values", direction="wide", sep="_")
df_wide
Gdzie
-
idvarjest kolumną klas, która oddziela wiersze -
timevarjest kolumną klas do rzucania szerokich -
v.namesjest kolumną zawierającą wartości liczbowe -
directionokreśla szeroki lub długi format - opcjonalny argument
sepjest separatorem używanym pomiędzytimevarnazwami klas Iv.namesw wyjściudata.frame.
Jeśli nie istnieje idvar, utwórz go przed korzystanie z funkcji reshape():
df$id <- c(rep("year1", 12), rep("year2", 12))
df_wide <- reshape(df, idvar="id", timevar="month", v.names="values", direction="wide", sep="_")
df_wide
Pamiętaj, że idvar jest wymagane! Część timevar i v.names jest łatwa. Wyjście tej funkcji jest bardziej przewidywalne niż niektóre z pozostałych, ponieważ wszystko jest wyraźnie zdefiniowane.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-08-29 03:00:45
O wiele łatwiejszy sposób!
devtools::install_github("yikeshu0611/onetree") #install onetree package
library(onetree)
widedata=reshape_toWide(data = dat1,id = "name",j = "numbers",value.var.prefix = "value")
widedata
name value1 value2 value3 value4
firstName 0.3407997 -0.7033403 -0.3795377 -0.7460474
secondName -0.8981073 -0.3347941 -0.5013782 -0.1745357
Jeśli chcesz wrócić z wide do long, Zmień tylko Wide na Long, bez zmian w obiektach.
reshape_toLong(data = widedata,id = "name",j = "numbers",value.var.prefix = "value")
name numbers value
firstName 1 0.3407997
secondName 1 -0.8981073
firstName 2 -0.7033403
secondName 2 -0.3347941
firstName 3 -0.3795377
secondName 3 -0.5013782
firstName 4 -0.7460474
secondName 4 -0.1745357
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-07-26 05:47:41
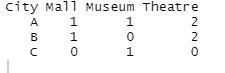
Możesz spróbować tego
Library (reshape2)
Dcast (DF, City ~ Facility, fill=0)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-10-19 22:35:09