Jak upuścić kolumny według nazwy w ramce danych
Mam duży zestaw danych i chciałbym przeczytać konkretne kolumny lub rzucić wszystkie inne.
data <- read.dta("file.dta")
Wybieram kolumny, które mnie nie interesują:
var.out <- names(data)[!names(data) %in% c("iden", "name", "x_serv", "m_serv")]
I wtedy chciałbym zrobić coś takiego:
for(i in 1:length(var.out)) {
paste("data$", var.out[i], sep="") <- NULL
}
Aby zrzucić wszystkie niechciane kolumny. Czy to optymalne rozwiązanie?
10 answers
Powinieneś użyć indeksowania lub funkcji subset. Na przykład:
R> df <- data.frame(x=1:5, y=2:6, z=3:7, u=4:8)
R> df
x y z u
1 1 2 3 4
2 2 3 4 5
3 3 4 5 6
4 4 5 6 7
5 5 6 7 8
Następnie możesz użyć funkcji which oraz operatora - w indeksacji kolumny:
R> df[ , -which(names(df) %in% c("z","u"))]
x y
1 1 2
2 2 3
3 3 4
4 4 5
5 5 6
Lub, znacznie prościej, użyj argumentu select funkcji subset: Możesz następnie użyć operatora - bezpośrednio na wektorze nazw kolumn ,a nawet możesz pominąć cudzysłowy wokół nazw!
R> subset(df, select=-c(z,u))
x y
1 1 2
2 2 3
3 3 4
4 4 5
5 5 6
Zauważ, że możesz również wybrać kolumny, które chcesz, zamiast upuszczać Pozostałe :
R> df[ , c("x","y")]
x y
1 1 2
2 2 3
3 3 4
4 4 5
5 5 6
R> subset(df, select=c(x,y))
x y
1 1 2
2 2 3
3 3 4
4 4 5
5 5 6
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-03-08 15:03:39
Nie używaj -which() do tego jest bardzo niebezpieczne. Consider:
dat <- data.frame(x=1:5, y=2:6, z=3:7, u=4:8)
dat[ , -which(names(dat) %in% c("z","u"))] ## works as expected
dat[ , -which(names(dat) %in% c("foo","bar"))] ## deletes all columns! Probably not what you wanted...
Zamiast tego użyj podzbioru lub funkcji !:
dat[ , !names(dat) %in% c("z","u")] ## works as expected
dat[ , !names(dat) %in% c("foo","bar")] ## returns the un-altered data.frame. Probably what you want
which()!Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-03-08 18:12:23
pierwszy, możesz użyć indeksowania bezpośredniego (z wektorami logicznymi) zamiast ponownego dostępu do nazw kolumn, jeśli pracujesz z tą samą ramką danych; będzie to bezpieczniejsze, jak wskazuje Ista, i szybsze do zapisu i wykonania. Więc wystarczy:
var.out.bool <- !names(data) %in% c("iden", "name", "x_serv", "m_serv")
A następnie po prostu zmień dane:
data <- data[,var.out.bool] # or...
data <- data[,var.out.bool, drop = FALSE] # You will need this option to avoid the conversion to an atomic vector if there is only one column left
drugi, szybciej pisać, możesz bezpośrednio przypisać NULL do kolumn, które chcesz usunąć:
data[c("iden", "name", "x_serv", "m_serv")] <- list(NULL) # You need list() to respect the target structure.
wreszcie, można użyć metody subset (), ale tak naprawdę nie można jej użyć w kodzie (nawet plik pomocy ostrzega o tym). W szczególności, problem jest dla mnie, że jeśli chcesz bezpośrednio użyć funkcji drop susbset (), musisz napisać bez cudzysłowów wyrażenie odpowiadające nazwom kolumn:
subset( data, select = -c("iden", "name", "x_serv", "m_serv") ) # WILL NOT WORK
subset( data, select = -c(iden, name, x_serv, m_serv) ) # WILL
jako bonus, Oto mały benchmark różnych opcji, który wyraźnie pokazuje, że podzbiór jest wolniejszy, i że po pierwsze, zmiana metody jest szybsza:
re_assign(dtest, drop_vec) 46.719 52.5655 54.6460 59.0400 1347.331
null_assign(dtest, drop_vec) 74.593 83.0585 86.2025 94.0035 1476.150
subset(dtest, select = !names(dtest) %in% drop_vec) 106.280 115.4810 120.3435 131.4665 65133.780
subset(dtest, select = names(dtest)[!names(dtest) %in% drop_vec]) 108.611 119.4830 124.0865 135.4270 1599.577
subset(dtest, select = -c(x, y)) 102.026 111.2680 115.7035 126.2320 1484.174
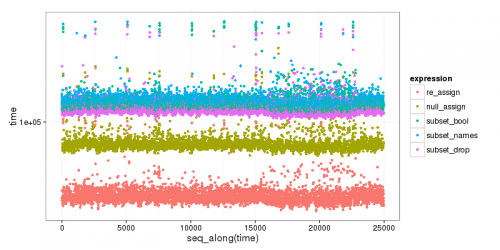
kod jest poniżej:
dtest <- data.frame(x=1:5, y=2:6, z = 3:7)
drop_vec <- c("x", "y")
null_assign <- function(df, names) {
df[names] <- list(NULL)
df
}
re_assign <- function(df, drop) {
df <- df [, ! names(df) %in% drop, drop = FALSE]
df
}
res <- microbenchmark(
re_assign(dtest,drop_vec),
null_assign(dtest,drop_vec),
subset(dtest, select = ! names(dtest) %in% drop_vec),
subset(dtest, select = names(dtest)[! names(dtest) %in% drop_vec]),
subset(dtest, select = -c(x, y) ),
times=5000)
plt <- ggplot2::qplot(y=time, data=res[res$time < 1000000,], colour=expr)
plt <- plt + ggplot2::scale_y_log10() +
ggplot2::labs(colour = "expression") +
ggplot2::scale_color_discrete(labels = c("re_assign", "null_assign", "subset_bool", "subset_names", "subset_drop")) +
ggplot2::theme_bw(base_size=16)
print(plt)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-07-22 20:37:17
Możesz również wypróbować pakiet dplyr:
R> df <- data.frame(x=1:5, y=2:6, z=3:7, u=4:8)
R> df
x y z u
1 1 2 3 4
2 2 3 4 5
3 3 4 5 6
4 4 5 6 7
5 5 6 7 8
R> library(dplyr)
R> dplyr::select(df2, -c(x, y)) # remove columns x and y
z u
1 3 4
2 4 5
3 5 6
4 6 7
5 7 8
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-06-12 18:15:06
Oto szybkie rozwiązanie. Powiedzmy, że masz ramkę danych X z trzema kolumnami A, B i C:
> X<-data.frame(A=c(1,2),B=c(3,4),C=c(5,6))
> X
A B C
1 1 3 5
2 2 4 6
Jeśli chcę usunąć kolumnę, powiedzmy B, po prostu użyj grepa na nazwach colnames, aby uzyskać indeks kolumny, którego możesz użyć, aby pominąć kolumnę.
> X<-X[,-grep("B",colnames(X))]
Nowa ramka danych X wyglądałaby następująco (tym razem bez kolumny B):
> X
A C
1 1 5
2 2 6
Piękno grepa polega na tym, że można określić wiele kolumn pasujących do wyrażenia regularnego. Gdybym miał X z pięcioma kolumnami (A,B,C,D, E):
> X<-data.frame(A=c(1,2),B=c(3,4),C=c(5,6),D=c(7,8),E=c(9,10))
> X
A B C D E
1 1 3 5 7 9
2 2 4 6 8 10
Usuń kolumny B i D:
> X<-X[,-grep("B|D",colnames(X))]
> X
A C E
1 1 5 9
2 2 6 10
EDIT: biorąc pod uwagę sugestię Grepla Mateusza Lundberga w komentarzach poniżej:
> X<-data.frame(A=c(1,2),B=c(3,4),C=c(5,6),D=c(7,8),E=c(9,10))
> X
A B C D E
1 1 3 5 7 9
2 2 4 6 8 10
> X<-X[,!grepl("B|D",colnames(X))]
> X
A C E
1 1 5 9
2 2 6 10
Jeśli spróbuję upuścić kolumnę,która nie istnieje, nic się nie powinno zdarzyć:
> X<-X[,!grepl("G",colnames(X))]
> X
A C E
1 1 5 9
2 2 6 10
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-12-25 11:50:39
Próbowałem usunąć kolumnę podczas korzystania z pakietu data.table i otrzymałem nieoczekiwany wynik. Myślę, że warto opublikować następujące informacje. Mała przestroga.
[Edited by Mateusz ... ]
DF = read.table(text = "
fruit state grade y1980 y1990 y2000
apples Ohio aa 500 100 55
apples Ohio bb 0 0 44
apples Ohio cc 700 0 33
apples Ohio dd 300 50 66
", sep = "", header = TRUE, stringsAsFactors = FALSE)
DF[ , !names(DF) %in% c("grade")] # all columns other than 'grade'
fruit state y1980 y1990 y2000
1 apples Ohio 500 100 55
2 apples Ohio 0 0 44
3 apples Ohio 700 0 33
4 apples Ohio 300 50 66
library('data.table')
DT = as.data.table(DF)
DT[ , !names(dat4) %in% c("grade")] # not expected !! not the same as DF !!
[1] TRUE TRUE FALSE TRUE TRUE TRUE
DT[ , !names(DT) %in% c("grade"), with=FALSE] # that's better
fruit state y1980 y1990 y2000
1: apples Ohio 500 100 55
2: apples Ohio 0 0 44
3: apples Ohio 700 0 33
4: apples Ohio 300 50 66
Zasadniczo składnia data.table nie jest dokładnie taka sama jak data.frame. W rzeczywistości istnieje wiele różnic, zobacz FAQ 1.1 i FAQ 2.17. Zostałeś ostrzeżony!
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-01-04 08:24:51
Oto inne rozwiązanie, które może być pomocne dla innych. Poniższy kod wybiera niewielką liczbę wierszy i kolumn z dużego zestawu danych. Kolumny są zaznaczone tak jak w jednej z odpowiedzi z tym wyjątkiem, że używam funkcji Wklej, aby wybrać zestaw kolumn o nazwach ponumerowanych kolejno:
df = read.table(text = "
state county city region mmatrix X1 X2 X3 A1 A2 A3 B1 B2 B3 C1 C2 C3
1 1 1 1 111010 1 0 0 2 20 200 4 8 12 NA NA NA
1 2 1 1 111010 1 0 0 4 NA 400 5 9 NA NA NA NA
1 1 2 1 111010 1 0 0 6 60 NA NA 10 14 NA NA NA
1 2 2 1 111010 1 0 0 NA 80 800 7 11 15 NA NA NA
1 1 3 2 111010 0 1 0 1 2 1 2 2 2 10 20 30
1 2 3 2 111010 0 1 0 2 NA 1 2 2 NA 40 50 NA
1 1 4 2 111010 0 1 0 1 1 NA NA 2 2 70 80 90
1 2 4 2 111010 0 1 0 NA 2 1 2 2 10 100 110 120
1 1 1 3 010010 0 0 1 10 20 10 200 200 200 1 2 3
1 2 1 3 001000 0 0 1 20 NA 10 200 200 200 4 5 9
1 1 2 3 101000 0 0 1 10 10 NA 200 200 200 7 8 NA
1 2 2 3 011010 0 0 1 NA 20 10 200 200 200 10 11 12
", sep = "", header = TRUE, stringsAsFactors = FALSE)
df
df2 <- df[df$region == 2, names(df) %in% c(paste("C", seq_along(1:3), sep=''))]
df2
# C1 C2 C3
# 5 10 20 30
# 6 40 50 NA
# 7 70 80 90
# 8 100 110 120
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-02-12 23:50:52
df2 <- df[!names(df) %in% c("c1", "c2")]
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-12-03 05:59:36
Zmieniłem kod na:
# read data
dat<-read.dta("file.dta")
# vars to delete
var.in<-c("iden", "name", "x_serv", "m_serv")
# what I'm keeping
var.out<-setdiff(names(dat),var.in)
# keep only the ones I want
dat <- dat[var.out]
W każdym razie, odpowiedź Juby jest najlepszym rozwiązaniem mojego problemu!
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-06-08 22:01:39
Nie mogę odpowiedzieć na twoje pytanie w komentarzach ze względu na niski wynik reputacji.
Następny kod spowoduje błąd, ponieważ funkcja wklej zwróci ciąg znaków
for(i in 1:length(var.out)) {
paste("data$", var.out[i], sep="") <- NULL
}
Oto możliwe rozwiązanie:
for(i in 1:length(var.out)) {
text_to_source <- paste0 ("data$", var.out[i], "<- NULL") # Write a line of your
# code like a character string
eval (parse (text=text_to_source)) # Source a text that contains a code
}
Lub po prostu zrób:
for(i in 1:length(var.out)) {
data[var.out[i]] <- NULL
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-07-25 13:05:54