Najszybszy sposób sprawdzenia, czy wartość istnieje na liście
Jaki jest najszybszy sposób, aby dowiedzieć się, czy wartość istnieje na liście (Lista z milionami wartości w niej) i jaki jest jej indeks?
Wiem, że wszystkie wartości na liście są unikalne, jak w tym przykładzie.
Pierwsza metoda, którą próbuję to (3.8 SEK w moim prawdziwym kodzie):
a = [4,2,3,1,5,6]
if a.count(7) == 1:
b=a.index(7)
"Do something with variable b"
Druga metoda jest (2x szybsza: 1.9 SEK dla mojego prawdziwego kodu):
a = [4,2,3,1,5,6]
try:
b=a.index(7)
except ValueError:
"Do nothing"
else:
"Do something with variable b"
Proponowane metody od użytkownika Stack Overflow (2.74 sec for my real kod):
a = [4,2,3,1,5,6]
if 7 in a:
a.index(7)
W moim prawdziwym kodzie pierwsza metoda zajmuje 3,81 SEK, a druga 1,88 sek. To dobra poprawa, ale:
Jestem początkujący w Pythonie / skryptach, i czy istnieje szybszy sposób, aby zrobić te same rzeczy i zaoszczędzić więcej czasu przetwarzania?
Bardziej szczegółowe wyjaśnienie mojego wniosku:
W API blendera mogę uzyskać dostęp do listy cząstek:
particles = [1, 2, 3, 4, etc.]
Stamtąd mogę uzyskać dostęp do lokalizacji cząstki:
particles[x].location = [x,y,z]
I dla każdego cząstka testuję, czy istnieje sąsiad, przeszukując każdą lokalizację cząstek w taki sposób:
if [x+1,y,z] in particles.location
"Find the identity of this neighbour particle in x:the particle's index
in the array"
particles.index([x+1,y,z])
12 answers
7 in a
Najczystszy i najszybszy sposób, aby to zrobić.
Możesz również rozważyć użycie set, ale zbudowanie tego zestawu z twojej listy może zająć więcej czasu niż szybsze testy członkostwa zaoszczędzą. Jedynym sposobem, aby być pewnym, jest dobre porównanie. (zależy to również od tego, jakich operacji potrzebujesz)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-09-27 15:57:30
Jak stwierdzili inni, in może być bardzo wolny dla dużych list. Oto kilka porównań występów dla in, set i bisect. Uwaga czas (w sekundach) jest w skali dziennika.
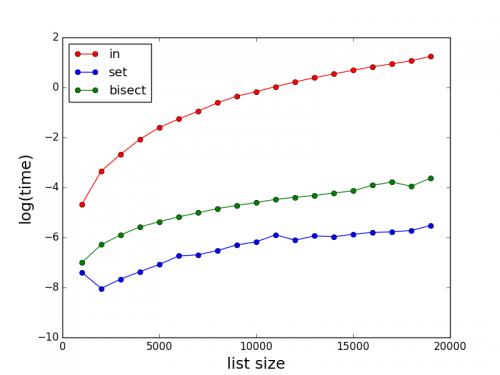
Kod do testów:
import random
import bisect
import matplotlib.pyplot as plt
import math
import time
def method_in(a, b, c):
start_time = time.time()
for i, x in enumerate(a):
if x in b:
c[i] = 1
return time.time() - start_time
def method_set_in(a, b, c):
start_time = time.time()
s = set(b)
for i, x in enumerate(a):
if x in s:
c[i] = 1
return time.time() - start_time
def method_bisect(a, b, c):
start_time = time.time()
b.sort()
for i, x in enumerate(a):
index = bisect.bisect_left(b, x)
if index < len(a):
if x == b[index]:
c[i] = 1
return time.time() - start_time
def profile():
time_method_in = []
time_method_set_in = []
time_method_bisect = []
# adjust range down if runtime is to great or up if there are to many zero entries in any of the time_method lists
Nls = [x for x in range(10000, 30000, 1000)]
for N in Nls:
a = [x for x in range(0, N)]
random.shuffle(a)
b = [x for x in range(0, N)]
random.shuffle(b)
c = [0 for x in range(0, N)]
time_method_in.append(method_in(a, b, c))
time_method_set_in.append(method_set_in(a, b, c))
time_method_bisect.append(method_bisect(a, b, c))
plt.plot(Nls, time_method_in, marker='o', color='r', linestyle='-', label='in')
plt.plot(Nls, time_method_set_in, marker='o', color='b', linestyle='-', label='set')
plt.plot(Nls, time_method_bisect, marker='o', color='g', linestyle='-', label='bisect')
plt.xlabel('list size', fontsize=18)
plt.ylabel('log(time)', fontsize=18)
plt.legend(loc='upper left')
plt.yscale('log')
plt.show()
profile()
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-07-23 18:41:06
Możesz umieścić swoje przedmioty w set. Ustawienia są bardzo wydajne.
Spróbuj:
s = set(a)
if 7 in s:
# do stuff
Edit w komentarzu mówisz, że chcesz uzyskać indeks elementu. Niestety, zestawy nie mają pojęcia o pozycji elementu. Alternatywą jest wstępne posortowanie listy, a następnie użycie wyszukiwania binarnego za każdym razem, gdy musisz znaleźć element.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-23 12:02:48
def check_availability(element, collection: iter):
return element in collection
Użycie
check_availability('a', [1,2,3,4,'a','b','c'])
Uważam, że jest to najszybszy sposób, aby dowiedzieć się, czy wybrana wartość znajduje się w tablicy.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-08-11 12:52:39
Pierwotne pytanie brzmiało:
Jaki jest najszybszy sposób, aby dowiedzieć się, czy wartość istnieje na liście (Lista z milionami wartości) i jaki jest jego indeks?
Tak więc są dwie rzeczy do znalezienia:
- jest pozycją na liście i
- jaki jest indeks (jeśli jest na liście).
W tym celu zmodyfikowałem kod @xslittlegrass, aby obliczać indeksy we wszystkich przypadkach, i dodałem dodatkowe metoda.
Wyniki

Metody to:
- in -- basically if x in b: return b. index (x)
- try--try / catch na B. index (x) (pomija konieczność sprawdzenia czy x w b)
- set -- zasadniczo jeśli x W set (b): return b. index (x)
- bisect--sortowanie b z jego indeksem, binarne wyszukiwanie x w sortowaniu (b). Uwaga mod od @xslittlegrass który zwraca indeks w posortowanym b, zamiast oryginalnego b)
- reverse--form a reverse lookup dictionary D for b; then d [x] dostarcza indeks x.
Wyniki pokazują, że metoda 5 jest najszybsza.
Co ciekawe, metody try i metody set są równoważne w czasie.
Kod Badania
import random
import bisect
import matplotlib.pyplot as plt
import math
import timeit
import itertools
def wrapper(func, *args, **kwargs):
" Use to produced 0 argument function for call it"
# Reference https://www.pythoncentral.io/time-a-python-function/
def wrapped():
return func(*args, **kwargs)
return wrapped
def method_in(a,b,c):
for i,x in enumerate(a):
if x in b:
c[i] = b.index(x)
else:
c[i] = -1
return c
def method_try(a,b,c):
for i, x in enumerate(a):
try:
c[i] = b.index(x)
except ValueError:
c[i] = -1
def method_set_in(a,b,c):
s = set(b)
for i,x in enumerate(a):
if x in s:
c[i] = b.index(x)
else:
c[i] = -1
return c
def method_bisect(a,b,c):
" Finds indexes using bisection "
# Create a sorted b with its index
bsorted = sorted([(x, i) for i, x in enumerate(b)], key = lambda t: t[0])
for i,x in enumerate(a):
index = bisect.bisect_left(bsorted,(x, ))
c[i] = -1
if index < len(a):
if x == bsorted[index][0]:
c[i] = bsorted[index][1] # index in the b array
return c
def method_reverse_lookup(a, b, c):
reverse_lookup = {x:i for i, x in enumerate(b)}
for i, x in enumerate(a):
c[i] = reverse_lookup.get(x, -1)
return c
def profile():
Nls = [x for x in range(1000,20000,1000)]
number_iterations = 10
methods = [method_in, method_try, method_set_in, method_bisect, method_reverse_lookup]
time_methods = [[] for _ in range(len(methods))]
for N in Nls:
a = [x for x in range(0,N)]
random.shuffle(a)
b = [x for x in range(0,N)]
random.shuffle(b)
c = [0 for x in range(0,N)]
for i, func in enumerate(methods):
wrapped = wrapper(func, a, b, c)
time_methods[i].append(math.log(timeit.timeit(wrapped, number=number_iterations)))
markers = itertools.cycle(('o', '+', '.', '>', '2'))
colors = itertools.cycle(('r', 'b', 'g', 'y', 'c'))
labels = itertools.cycle(('in', 'try', 'set', 'bisect', 'reverse'))
for i in range(len(time_methods)):
plt.plot(Nls,time_methods[i],marker = next(markers),color=next(colors),linestyle='-',label=next(labels))
plt.xlabel('list size', fontsize=18)
plt.ylabel('log(time)', fontsize=18)
plt.legend(loc = 'upper left')
plt.show()
profile()
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-02-15 19:51:28
a = [4,2,3,1,5,6]
index = dict((y,x) for x,y in enumerate(a))
try:
a_index = index[7]
except KeyError:
print "Not found"
else:
print "found"
Będzie to dobry pomysł tylko wtedy, gdy a się nie zmieni i dlatego możemy wykonać część dict() raz, a następnie użyć jej wielokrotnie. Jeśli a się zmieni, proszę podać więcej szczegółów na temat tego, co robisz.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-09-27 16:26:35
Wygląda na to, że Twoja aplikacja może zyskać przewagę dzięki wykorzystaniu struktury danych filtru Bloom.
W skrócie, filtr bloom look-up może powiedzieć bardzo szybko, jeśli wartość jest zdecydowanie nie obecny w zestawie. W przeciwnym razie możesz wykonać wolniejsze wyszukiwanie, aby uzyskać indeks wartości, która może znajdować się na liście. Więc jeśli aplikacja ma tendencję do uzyskania" Nie znaleziono "wynik znacznie częściej niż" znaleziono " wynik, można zobaczyć przyspieszenie przez dodanie filtra Bloom.
Dla szczegóły, Wikipedia zapewnia dobry przegląd tego, jak działają filtry Bloom, A wyszukiwanie w Internecie "python bloom filter library" zapewni co najmniej kilka przydatnych implementacji.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-01-27 22:46:39
Należy pamiętać, że operatorin testuje nie tylko równość (==), ale także tożsamość (is), logika in dla list s jest w przybliżeniu równoważna następującym (w rzeczywistości jest napisany w C, a nie Pythonie, przynajmniej w CPython):
for element in s: if element is target: # fast check for identity implies equality return True if element == target: # slower check for actual equality return True return False
W większości okoliczności ten szczegół jest nieistotny, ale w niektórych okolicznościach może pozostawić początkującego Pythona zaskoczonego, na przykład numpy.NAN ma niezwykłą właściwość bycia nie równym :
>>> import numpy
>>> numpy.NAN == numpy.NAN
False
>>> numpy.NAN is numpy.NAN
True
>>> numpy.NAN in [numpy.NAN]
True
Aby odróżnić te nietypowe przypadki można użyć any() Jak:
>>> lst = [numpy.NAN, 1 , 2]
>>> any(element == numpy.NAN for element in lst)
False
>>> any(element is numpy.NAN for element in lst)
True
Zwróć uwagę, że in Logika dla list S z any() będzie:
any(element is target or element == target for element in lst)
Należy jednak podkreślić, że jest to przypadek edge, a w zdecydowanej większości przypadków operator in jest wysoce zoptymalizowany i dokładnie to, co chcesz oczywiście(albo z list lub z set).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-02-19 14:05:41
Lub __contains__:
sequence.__contains__(value)
Demo:
>>> l=[1,2,3]
>>> l.__contains__(3)
True
>>>
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-10-19 02:49:02
To nie jest kod, ale algorytm bardzo szybkiego wyszukiwania.
Jeśli Twoja lista i wartość, której szukasz, są liczbami, jest to dość proste. If strings: look at the bottom:
- -niech" n " będzie długością Twojej listy
- -opcjonalny krok: jeśli potrzebujesz indeksu elementu: Dodaj drugą kolumnę do listy z bieżącym indeksem elementów (0 do N-1) - patrz później
- zamów swoją listę lub jej kopię (.sort ())
- pętla przez:
- porównaj swoją liczbę z N / 2 elementem listy
- jeśli jest większy, pętla ponownie między indeksami n/2-N
- jeśli jest mniejszy, pętla ponownie między indeksami 0-N / 2
- If the same: you found it
- porównaj swoją liczbę z N / 2 elementem listy
- zawężaj listę, aż ją znajdziesz lub masz tylko 2 liczby (poniżej i powyżej tej, której szukasz)
- to znajdzie dowolny element w co najwyżej 19 kroków dla listy 1.000.000 (log(2)N być precyzyjne)
Jeśli potrzebujesz również oryginalnej pozycji numeru, poszukaj go w drugiej kolumnie indeksu.
Jeśli Twoja lista nie składa się z liczb, metoda nadal działa i będzie najszybsza, ale może być konieczne zdefiniowanie funkcji, która może porównywać/porządkować ciągi.
Oczywiście wymaga to Inwestycji w metodę sorted (), ale jeśli nadal używasz tej samej listy do sprawdzania, może być warto.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-05-11 01:50:13
Ponieważ pytanie nie zawsze powinno być rozumiane jako najszybszy sposób techniczny - zawsze sugeruję najprostszy najszybszy sposób rozumienia/pisania: rozumienie listy, jednolinijkowe
[i for i in list_from_which_to_search if i in list_to_search_in]
Miałem list_to_search_in ze wszystkimi przedmiotami i chciałem zwrócić indeksy przedmiotów w list_from_which_to_search.
To zwraca indeksy w ładnej liście.
Istnieją inne sposoby na sprawdzenie tego problemu - jednak składanie list jest wystarczająco szybkie, dodając do fakt napisania go wystarczająco szybko, aby rozwiązać problem.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-05-18 12:14:11
Kod sprawdzający, czy w tablicy istnieją dwa elementy, których iloczyn jest równy k:
n = len(arr1)
for i in arr1:
if k%i==0:
print(i)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-05-11 01:51:30