Duża działka: ~20 milionów próbek, gigabajty danych
Mam problem (z moim Ramem): nie jest w stanie pomieścić danych, które chcę wykreślić. Mam wystarczająco dużo miejsca na HD. Czy jest jakieś rozwiązanie, aby uniknąć tego "cieniowania" mojego zestawu danych?
Konkretnie zajmuję się cyfrowym przetwarzaniem sygnału i muszę używać wysokiej częstotliwości próbkowania. My Framework (GNU Radio) zapisuje wartości (aby uniknąć zużywania zbyt dużej ilości miejsca na dysku) w formacie binarnym. Rozpakowuję go. Potem muszę spiskować. Chcę, żeby fabuła była zoomowalna i interaktywna. I to jest problem.Czy istnieje jakiś potencjał optymalizacji tego lub innego oprogramowania / języka programowania (takiego jak R lub Tak), który może obsługiwać większe zbiory danych? Właściwie to chcę dużo więcej danych w moich działkach. Ale nie mam doświadczenia z innym oprogramowaniem. GNUplot zawodzi, z podobnym podejściem do poniższego. Nie wiem R (jet).
import matplotlib.pyplot as plt
import matplotlib.cbook as cbook
import struct
"""
plots a cfile
cfile - IEEE single-precision (4-byte) floats, IQ pairs, binary
txt - index,in-phase,quadrature in plaintext
note: directly plotting with numpy results into shadowed functions
"""
# unpacking the cfile dataset
def unpack_set(input_filename, output_filename):
index = 0 # index of the samples
output_filename = open(output_filename, 'wb')
with open(input_filename, "rb") as f:
byte = f.read(4) # read 1. column of the vector
while byte != "":
# stored Bit Values
floati = struct.unpack('f', byte) # write value of 1. column to a variable
byte = f.read(4) # read 2. column of the vector
floatq = struct.unpack('f', byte) # write value of 2. column to a variable
byte = f.read(4) # next row of the vector and read 1. column
# delimeter format for matplotlib
lines = ["%d," % index, format(floati), ",", format(floatq), "\n"]
output_filename.writelines(lines)
index = index + 1
output_filename.close
return output_filename.name
# reformats output (precision configuration here)
def format(value):
return "%.8f" % value
# start
def main():
# specify path
unpacked_file = unpack_set("test01.cfile", "test01.txt")
# pass file reference to matplotlib
fname = str(unpacked_file)
plt.plotfile(fname, cols=(0,1)) # index vs. in-phase
# optional
# plt.axes([0, 0.5, 0, 100000]) # for 100k samples
plt.grid(True)
plt.title("Signal-Diagram")
plt.xlabel("Sample")
plt.ylabel("In-Phase")
plt.show();
if __name__ == "__main__":
main()
Coś jak plt.swap_on_disk () może buforować rzeczy na moim SSD;)
5 answers
Więc Twoje dane nie są tak duże, a fakt, że masz problemy z ich wykreśleniem, wskazuje na problemy z narzędziami. Matplotlib.... czy to nie jest dobre. Ma wiele opcji i wyjście jest w porządku, ale to ogromna wieprz pamięci i zasadniczo zakłada, że Twoje dane są małe. Ale są inne opcje.
Więc jako przykład wygenerowałem 20m plik punktu danych 'bigdata.bin ' używając następującego:
#!/usr/bin/env python
import numpy
import scipy.io.numpyio
npts=20000000
filename='bigdata.bin'
def main():
data = (numpy.random.uniform(0,1,(npts,3))).astype(numpy.float32)
data[:,2] = 0.1*data[:,2]+numpy.exp(-((data[:,1]-0.5)**2.)/(0.25**2))
fd = open(filename,'wb')
scipy.io.numpyio.fwrite(fd,data.size,data)
fd.close()
if __name__ == "__main__":
main()
Generuje to plik o rozmiarze ~229mb, który nie jest aż tak duży; ale wyraziłeś, że chcesz przejść do jeszcze większych plików, więc w końcu osiągniesz limity pamięci.
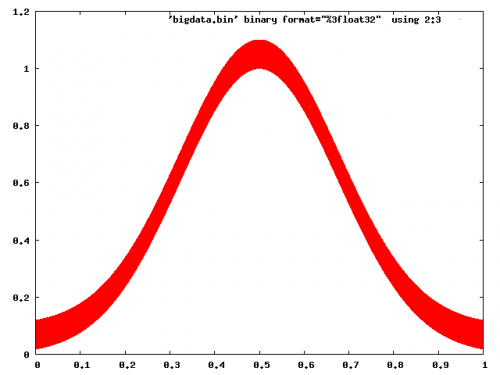
Skupmy się najpierw na nieinteraktywnych fabułach. Pierwszą rzeczą do zrealizowania jest to, że wykresy wektorowe z glifami w każdym punkcie będą katastrofą - dla każdego z punktów 20 M, z których większość i tak będzie nakładać się, próbując renderować małe krzyże lub okręgi lub coś będzie diaster, generowanie ogromnych plików i zajmuje mnóstwo czasu. Myślę, że to jest to, co domyślnie Tonący matplotlib.Gnuplot nie ma z tym problemu:
gnuplot> set term png
gnuplot> set output 'foo.png'
gnuplot> plot 'bigdata.bin' binary format="%3float32" using 2:3 with dots
#!/usr/bin/env python
import numpy
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
datatype=[('index',numpy.float32), ('floati',numpy.float32),
('floatq',numpy.float32)]
filename='bigdata.bin'
def main():
data = numpy.memmap(filename, datatype, 'r')
plt.plot(data['floati'],data['floatq'],'r,')
plt.grid(True)
plt.title("Signal-Diagram")
plt.xlabel("Sample")
plt.ylabel("In-Phase")
plt.savefig('foo2.png')
if __name__ == "__main__":
main()
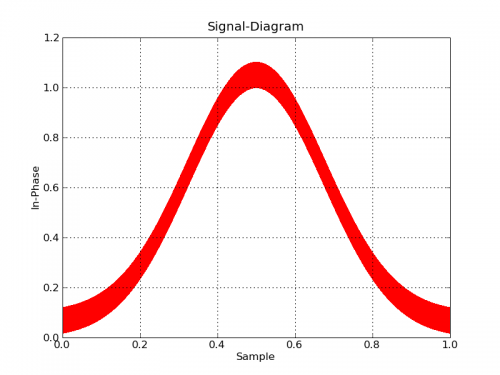
Z drugiej strony, plotowanie-big-data jest dość powszechnym zadaniem, a istnieją narzędzia, które są gotowe do pracy. Paraview jest moim ulubionym miejscem, a wizyta jest kolejną. Oba są głównie dla danych 3D, ale Paraview w szczególności robi 2d, jak również, i jest bardzo interaktywny (a nawet ma interfejs skryptowy Pythona). Jedyną sztuczką będzie zapisanie danych do formatu pliku, który Paraview może łatwo odczytać.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-10-23 09:39:21
Z pewnością możesz zoptymalizować odczyt swojego pliku: możesz bezpośrednio odczytać go do tablicy NumPy, tak aby wykorzystać szybkość NumPy. Masz kilka opcji. Jeśli pamięć RAM jest problemem, możesz użyć memmap, która przechowuje większość pliku na dysku (zamiast w pamięci RAM):
# Each data point is a sequence of three 32-bit floats:
data = np.memmap(filename, mode='r', dtype=[('index', 'float32'), ('floati','float32'), ('floatq', 'float32')])
Jeśli RAM NIE JEST PROBLEMEM, możesz umieścić całą tablicę w RAM za pomocą fromfile :
data = np.fromfile(filename, dtype=[('index', 'float32'), ('floati','float32'), ('floatq', 'float32')])
Wykreślanie można następnie wykonać za pomocą zwykłej funkcji plot(*data) Matplotlib, ewentualnie poprzez " zoom W " metoda zaproponowana w innym rozwiązaniu.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-01-10 01:04:53
Nowszy projekt ma duży potencjał dla dużych zbiorów danych: Bokeh , który został stworzony z dokładnie z myślą o tym.
W rzeczywistości tylko dane, które są istotne w skali wykresu, są wysyłane do zaplecza wyświetlacza. Podejście to jest znacznie szybsze niż podejście Matplotlib.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-03-15 03:51:39
Sugerowałbym coś nieco skomplikowanego, ale to powinno zadziałać: Zbuduj swój wykres w różnych rozdzielczościach, dla różnych zakresów.
Pomyśl na przykład o Google Earth. Jeśli rozpakujesz się na maksymalnym poziomie, aby pokryć całą planetę, rozdzielczość jest najniższa. Po powiększeniu Zdjęcia zmieniają się na bardziej szczegółowe, ale tylko na obszarze, który powiększasz.
Czyli zasadniczo dla Twojej fabuły (czy to 2D ? 3D ? Zakładam, że jest to 2D), proponuję zbudować jeden duży wykres, który obejmuje cały zakres [0, n] z niską rozdzielczością, 2 mniejsze wykresy pokrywające [0, n/2] i [N/2 + 1, n] z dwukrotnie większą rozdzielczością niż duży, 4 mniejsze wykresy pokrywające [0, n / 4] ... [3 * N / 4 + 1, n] Z dwukrotnie większą rozdzielczością niż 2 powyżej i tak dalej.
Nie jestem pewien, czy moje wyjaśnienie jest naprawdę jasne. Ponadto, Nie wiem, czy ten rodzaj grafu o wielu rozdzielczościach jest obsługiwany przez jakikolwiek istniejący program wykresu.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-05-02 07:54:25
Ciekawe czy da się wygrać przyspieszając pobieranie punktów? (Od jakiegoś czasu intrygują mnie drzewa R* (R star).)
Zastanawiam się, czy użycie czegoś takiego jak drzewo r* w tym przypadku może być dobrym rozwiązaniem. (w przypadku powiększenia, wyższe węzły w drzewie mogą zawierać informacje o grubszym, powiększonym renderowaniu, węzły dalej w kierunku liści zawierają pojedyncze próbki)
Może nawet odwzorować drzewo (lub jakąkolwiek strukturę używasz) na pamięć, aby utrzymać wydajność i niskie zużycie pamięci RAM. (odciążasz zadanie zarządzania pamięcią do jądra)
Mam nadzieję, że to ma sens.. trochę gadam. jest późno!
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-05-02 08:28:06