Uzyskiwanie najbliższego dopasowania strun
Potrzebuję sposobu na porównanie wielu łańcuchów z testowym łańcuchem i zwrócenie łańcucha, który jest bardzo podobny do niego:
TEST STRING: THE BROWN FOX JUMPED OVER THE RED COW
CHOICE A : THE RED COW JUMPED OVER THE GREEN CHICKEN
CHOICE B : THE RED COW JUMPED OVER THE RED COW
CHOICE C : THE RED FOX JUMPED OVER THE BROWN COW
(jeśli zrobiłem to poprawnie) najbliższy ciąg do "test STRING" powinien być "CHOICE C". Jak najłatwiej to zrobić?
Planuję zaimplementować to w wielu językach, w tym VB.net, Lua i JavaScript. W tym momencie pseudo kod jest akceptowalny. Jeśli możesz podać przykład dla konkretnego języka, to również jest to doceniane!
10 answers
Problem ten pojawił się jakiś rok temu, gdy chodziło o wyszukanie w bazie danych różnych informacji wprowadzonych przez użytkownika informacji o platformie wiertniczej. Celem było wykonanie pewnego rodzaju rozmytego wyszukiwania ciągów, które mogłoby zidentyfikować wpis bazy danych z najczęstszymi elementami.
Część badań dotyczyła implementacji algorytmu Levenshtein distance , który określa, ile zmian należy wprowadzić do Ciągu lub frazy, aby przekształcić go w inny ciąg lub fraza.
Implementacja, którą wymyśliłem, była stosunkowo prosta i obejmowała ważone porównanie długości dwóch fraz, liczby zmian między każdą frazą i tego, czy każde słowo można znaleźć w docelowym wpisie.
Artykuł znajduje się na prywatnej stronie, więc Dołożę wszelkich starań, aby dołączyć odpowiednią treść tutaj:
Fuzzy String Matching jest procesem wykonywania ludzkiej oceny podobieństwa dwóch słów lub fraz. W wielu przypadkach, polega na identyfikacji słów lub zwrotów, które są do siebie najbardziej podobne. W tym artykule opisano wewnętrzne rozwiązanie problemu fuzzy string matching i jego przydatność w rozwiązywaniu różnych problemów, które mogą pozwolić nam zautomatyzować zadania, które wcześniej wymagały żmudnego zaangażowania użytkownika.
Wprowadzenie
Potrzeba wykonania fuzzy string matching pierwotnie powstała podczas opracowywania narzędzia walidatora Zatoki Meksykańskiej. Istniała baza znanych platformy i platformy w Zatoce Meksykańskiej, a ludzie kupujący ubezpieczenia daliby nam źle wpisane informacje o ich aktywach i musieliśmy dopasować je do bazy znanych platform. Kiedy było bardzo mało informacji podanych, najlepsze, co mogliśmy zrobić, to polegać na ubezpieczycielu, aby "rozpoznać" tego, do którego się odnosili i wywołać odpowiednie informacje. Tutaj właśnie przydaje się to zautomatyzowane rozwiązanie.
Spędziłem dzień badając metody fuzzy string matching, i w końcu natknąłem się na bardzo przydatny algorytm odległości Levenshteina na Wikipedii.
Realizacja
Po przeczytaniu o teorii stojącej za tym, wdrożyłem i znalazłem sposoby, aby go zoptymalizować. Tak wygląda mój kod w VBA:
'Calculate the Levenshtein Distance between two strings (the number of insertions,
'deletions, and substitutions needed to transform the first string into the second)
Public Function LevenshteinDistance(ByRef S1 As String, ByVal S2 As String) As Long
Dim L1 As Long, L2 As Long, D() As Long 'Length of input strings and distance matrix
Dim i As Long, j As Long, cost As Long 'loop counters and cost of substitution for current letter
Dim cI As Long, cD As Long, cS As Long 'cost of next Insertion, Deletion and Substitution
L1 = Len(S1): L2 = Len(S2)
ReDim D(0 To L1, 0 To L2)
For i = 0 To L1: D(i, 0) = i: Next i
For j = 0 To L2: D(0, j) = j: Next j
For j = 1 To L2
For i = 1 To L1
cost = Abs(StrComp(Mid$(S1, i, 1), Mid$(S2, j, 1), vbTextCompare))
cI = D(i - 1, j) + 1
cD = D(i, j - 1) + 1
cS = D(i - 1, j - 1) + cost
If cI <= cD Then 'Insertion or Substitution
If cI <= cS Then D(i, j) = cI Else D(i, j) = cS
Else 'Deletion or Substitution
If cD <= cS Then D(i, j) = cD Else D(i, j) = cS
End If
Next i
Next j
LevenshteinDistance = D(L1, L2)
End Function
Prosty, szybki i bardzo przydatny metryk. Korzystając z tego, stworzyłem dwie osobne metryki do oceny podobieństwa dwóch łańcuchów. Jeden nazywam "valuePhrase" i jeden nazywam "valueWords". valuePhrase to tylko Odległość Levenshteina między tymi dwoma frazami i wartościami dzieli ciąg znaków na poszczególne słowa, na podstawie ograniczników, takich jak spacje, myślniki i cokolwiek innego, i porównuje każde słowo ze sobą, podsumowując najkrótszą odległość Levenshteina łączącą dowolne dwa słowa. Zasadniczo mierzy, czy informacje zawarte w jednym "zdaniu" są rzeczywiście zawarte w innym, tak jak permutacja słowna. Spędziłem kilka dni jako projekt poboczny wymyślając najbardziej efektywny sposób możliwe rozdzielenie ciągu znaków na podstawie ograniczników.
ValueWords, valuePhrase i funkcja Split:
Public Function valuePhrase#(ByRef S1$, ByRef S2$)
valuePhrase = LevenshteinDistance(S1, S2)
End Function
Public Function valueWords#(ByRef S1$, ByRef S2$)
Dim wordsS1$(), wordsS2$()
wordsS1 = SplitMultiDelims(S1, " _-")
wordsS2 = SplitMultiDelims(S2, " _-")
Dim word1%, word2%, thisD#, wordbest#
Dim wordsTotal#
For word1 = LBound(wordsS1) To UBound(wordsS1)
wordbest = Len(S2)
For word2 = LBound(wordsS2) To UBound(wordsS2)
thisD = LevenshteinDistance(wordsS1(word1), wordsS2(word2))
If thisD < wordbest Then wordbest = thisD
If thisD = 0 Then GoTo foundbest
Next word2
foundbest:
wordsTotal = wordsTotal + wordbest
Next word1
valueWords = wordsTotal
End Function
''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''
' SplitMultiDelims
' This function splits Text into an array of substrings, each substring
' delimited by any character in DelimChars. Only a single character
' may be a delimiter between two substrings, but DelimChars may
' contain any number of delimiter characters. It returns a single element
' array containing all of text if DelimChars is empty, or a 1 or greater
' element array if the Text is successfully split into substrings.
' If IgnoreConsecutiveDelimiters is true, empty array elements will not occur.
' If Limit greater than 0, the function will only split Text into 'Limit'
' array elements or less. The last element will contain the rest of Text.
''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''
Function SplitMultiDelims(ByRef Text As String, ByRef DelimChars As String, _
Optional ByVal IgnoreConsecutiveDelimiters As Boolean = False, _
Optional ByVal Limit As Long = -1) As String()
Dim ElemStart As Long, N As Long, M As Long, Elements As Long
Dim lDelims As Long, lText As Long
Dim Arr() As String
lText = Len(Text)
lDelims = Len(DelimChars)
If lDelims = 0 Or lText = 0 Or Limit = 1 Then
ReDim Arr(0 To 0)
Arr(0) = Text
SplitMultiDelims = Arr
Exit Function
End If
ReDim Arr(0 To IIf(Limit = -1, lText - 1, Limit))
Elements = 0: ElemStart = 1
For N = 1 To lText
If InStr(DelimChars, Mid(Text, N, 1)) Then
Arr(Elements) = Mid(Text, ElemStart, N - ElemStart)
If IgnoreConsecutiveDelimiters Then
If Len(Arr(Elements)) > 0 Then Elements = Elements + 1
Else
Elements = Elements + 1
End If
ElemStart = N + 1
If Elements + 1 = Limit Then Exit For
End If
Next N
'Get the last token terminated by the end of the string into the array
If ElemStart <= lText Then Arr(Elements) = Mid(Text, ElemStart)
'Since the end of string counts as the terminating delimiter, if the last character
'was also a delimiter, we treat the two as consecutive, and so ignore the last elemnent
If IgnoreConsecutiveDelimiters Then If Len(Arr(Elements)) = 0 Then Elements = Elements - 1
ReDim Preserve Arr(0 To Elements) 'Chop off unused array elements
SplitMultiDelims = Arr
End Function
Miary podobieństwa
Używając tych dwóch metryk i trzeciej, która po prostu oblicza odległość między dwoma ciągami, mam szereg zmiennych, które mogę uruchomić algorytm optymalizacji, aby osiągnąć największą liczbę dopasowań. Fuzzy string matching jest samo w sobie nauką rozmytą, a więc tworząc liniowo niezależne metryki do pomiaru ciągu podobieństwo i mając znany zestaw ciągów, które chcemy dopasować do siebie, możemy znaleźć parametry, które dla naszych konkretnych stylów ciągów dają najlepsze wyniki dopasowania rozmytego.
Początkowo celem metryki była niska wartość wyszukiwania dla dokładnego dopasowania i zwiększenie wartości wyszukiwania dla coraz bardziej permutowanych miar. W niepraktycznym przypadku było to dość łatwe do zdefiniowania za pomocą zbioru dobrze zdefiniowanych permutacji i skonstruowania ostatecznej formuły tak, że miały zwiększanie wyników wyszukiwania według potrzeb.
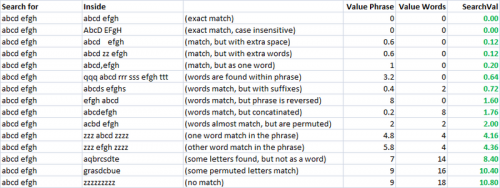
Na powyższym zrzucie ekranu poprawiłem swoją heurystykę, aby wymyślić coś, co czułem, że jest ładnie skalowane do mojej postrzeganej różnicy między wyszukiwanym terminem a wynikiem. Heurystyka, której użyłem dla Value Phrase w powyższym arkuszu kalkulacyjnym, to =valuePhrase(A2,B2)-0.8*ABS(LEN(B2)-LEN(A2)). Skutecznie zmniejszyłem karę odległości Levensteina o 80% różnicy długości dwóch "fraz". W ten sposób "Zwroty" o tej samej długości cierpią w pełni kary, ale "frazy", które zawierają "dodatkowe informacje" (dłuższe), ale poza tym nadal w większości mają te same znaki, podlegają obniżonej karze. Użyłem funkcji Value Words tak jak jest, a następnie moja końcowa heurystyka SearchVal została zdefiniowana jako =MIN(D2,E2)*0.8+MAX(D2,E2)*0.2 - średnia ważona. Każdy z dwóch punktów był niższy ważony 80%, a 20% wyższy wynik. To była tylko heurystyka, która pasowała do mojego przypadku użycia, Aby uzyskać dobry wskaźnik dopasowania. Te wagi są coś, co można następnie dostosować, aby uzyskać najlepsze dopasuj szybkość z ich danymi testowymi.
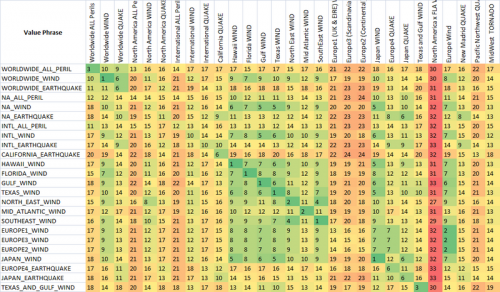
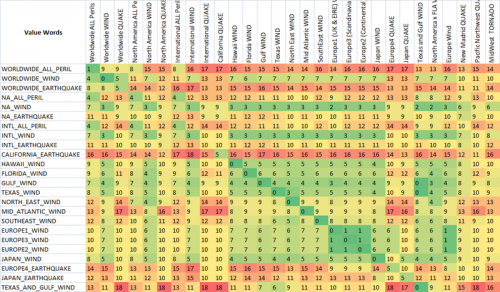
Jak widać, dwie ostatnie metryki, które są fuzzy string matching metrics, mają już naturalną tendencję do dawania niskich wyników ciągom, które są przeznaczone do dopasowania (po przekątnej). To jest bardzo dobre.
Zastosowanie Aby umożliwić optymalizację dopasowania rozmytego, ważę każdą metrykę. W związku z tym każda aplikacja fuzzy string match może ważyć parametry inaczej. Wzór, który określa wynik końcowy jest po prostu kombinacją metryk i ich wagi:
value = Min(phraseWeight*phraseValue, wordsWeight*wordsValue)*minWeight
+ Max(phraseWeight*phraseValue, wordsWeight*wordsValue)*maxWeight
+ lengthWeight*lengthValue
Używając algorytmu optymalizacji (sieć neuronowa jest tutaj najlepsza, ponieważ jest to dyskretny, wielowymiarowy problem), celem jest teraz zmaksymalizowanie liczby meczów. Stworzyłem funkcję, która wykrywa liczbę poprawnych dopasowań każdego zestawu do siebie, co widać na tym ostatnim zrzucie ekranu. Kolumna lub wiersz otrzymuje punkt, jeśli najniższy wynik jest przypisany ciąg, który miał być dopasowane, a częściowe punkty są przyznawane, jeśli jest remis za najniższy wynik, a prawidłowy mecz jest wśród remisów dopasowanych ciągów. Następnie go zoptymalizowałem. Widać, że zielona komórka jest kolumną, która najlepiej pasuje do bieżącego wiersza, a niebieski kwadrat wokół komórki jest wierszem, który najlepiej pasuje do bieżącej kolumny. Wynik w dolnym rogu to mniej więcej liczba udanych meczów i to właśnie mówimy naszemu problemowi optymalizacji, aby zmaksymalizować.
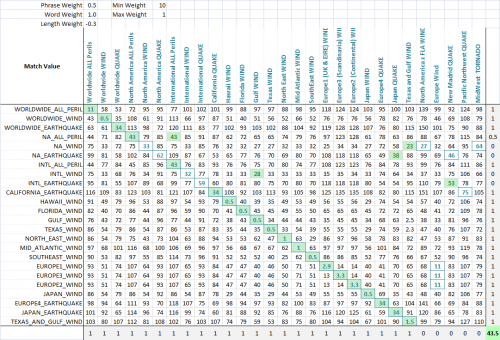
The algorytm okazał się wspaniałym sukcesem, a parametry rozwiązania mówią wiele o tego typu problemie. Zauważysz, że zoptymalizowany wynik wynosił 44, a najlepszy możliwy wynik to 48. 5 kolumn na końcu są wabikami i nie mają żadnego dopasowania do wartości wiersza. Im więcej wabików, tym trudniej będzie znaleźć najlepsze dopasowanie.
W tym konkretnym przypadku, długość łańcuchów jest nieistotna, ponieważ oczekujemy skrótów, które reprezentują dłuższe słowa, więc optymalna waga dla długości wynosi -0,3, co oznacza, że nie karamy strun, które różnią się długością. Zmniejszamy wynik w oczekiwaniu na te skróty, dając więcej miejsca na częściowe dopasowania słów, aby zastąpić dopasowania nie-słowne, które po prostu wymagają mniej podstawień, ponieważ ciąg jest krótszy.
Waga słowa wynosi 1,0, podczas gdy waga frazy wynosi tylko 0,5, co oznacza, że karamy całe słowa brakujące w jednym ciągu i cenimy bardziej całe wyrażenie jest nienaruszone. Jest to przydatne, ponieważ wiele z tych ciągów ma jedno słowo wspólne (the peril), gdzie naprawdę ważne jest to, czy kombinacja (region i peril) są utrzymywane.
Wreszcie, minimalna waga jest zoptymalizowana przy 10, a maksymalna waga przy 1. Oznacza to, że jeśli najlepszy z dwóch wyników (fraza wartości i słowa wartości) nie jest bardzo dobry, mecz jest znacznie karane, ale nie znacznie karane najgorsze z dwóch wyników. Zasadniczo kładzie to nacisk na konieczność albo valueWord lub valuePhrase, aby mieć dobry wynik, ale nie oba. Coś w rodzaju mentalności "weź to, co możemy dostać".
To naprawdę fascynujące, co zoptymalizowana wartość tych 5 wag mówi o rodzaju dopasowania rozmytego ciągu. Dla zupełnie różnych praktycznych przypadków dopasowania rozmytego ciągu parametry te są bardzo różne. Używałem go do 3 oddzielnych aplikacji do tej pory.
Podczas gdy nieużywany w ostatecznej optymalizacji, arkusz porównawczy był ustalono, który dopasowuje kolumny do siebie, aby uzyskać wszystkie doskonałe wyniki po przekątnej, i pozwala użytkownikowi zmieniać parametry, aby kontrolować szybkość, z jaką wyniki różnią się od 0, i zauważyć wrodzone podobieństwa między frazami wyszukiwania (które teoretycznie mogą być używane do kompensowania fałszywych alarmów w wynikach) {]}

Dalsze Aplikacje
To rozwiązanie może być stosowane wszędzie tam, gdzie użytkownik chce mieć system komputerowy identyfikujący ciąg znaków w zestaw strun, w których nie ma idealnego dopasowania. (Jak przybliżony vlookup dopasowania dla ciągów).
Więc co powinieneś z tego wyciągnąć, to to, że prawdopodobnie chcesz użyć kombinacji heurystyki wysokiego poziomu (znajdowanie słów z jednej frazy w drugiej frazie, długość obu fraz itp.) wraz z implementacją algorytmu odległości Levenshteina. Ponieważ decyzja, która jest "najlepsza" jest heurystyczną (rozmytą) determinacją - będziesz musiał wymyślić zestaw wag dla wszelkich metryk, które wymyślisz, aby określić podobieństwo.
Z odpowiednim zestawem heurystyki i wag, będziesz miał swój program porównawczy szybko podejmując decyzje, które byś podjął.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-04-12 13:38:20
Ten problem pojawia się cały czas w bioinformatyce. Przyjęta powyżej odpowiedź (która była świetna przy okazji) jest znana w bioinformatyce jako algorytmy Needleman-Wunsch (Porównaj dwa ciągi) i Smith-Waterman (znajdź przybliżony podłańcuch w dłuższym ciągu). Pracują świetnie i są końmi pociągowymi od dziesięcioleci.
Ale co, jeśli masz milion strun do porównania? to bilion porównań par, z których każde Jest O (n*m)! Nowoczesne sekwencery DNA łatwo Wygeneruj miliard krótkich sekwencji DNA, każda o długości około 200 "liter" DNA. Zazwyczaj chcemy znaleźć, dla każdego takiego ciągu, najlepsze dopasowanie do ludzkiego genomu (3 miliardy liter). Oczywiście algorytm Needleman-Wunsch i jego krewni nie zrobią tego.
Ten tak zwany "problem wyrównania" jest dziedziną aktywnych badań. Najpopularniejsze algorytmy są obecnie w stanie znaleźć niedokładne dopasowania między 1 miliard krótkich strun i ludzkiego genomu w ciągu kilku godzin na rozsądny sprzęt (powiedzmy, osiem rdzeni i 32 GB PAMIĘCI RAM).
Większość tych algorytmów działa poprzez szybkie znajdowanie krótkich dokładnych dopasowań (seeds), a następnie rozszerzanie ich do pełnego ciągu za pomocą wolniejszego algorytmu (na przykład Smith-Waterman). Powodem, dla którego to działa, jest to, że tak naprawdę jesteśmy zainteresowani tylko kilkoma bliskimi meczami, więc opłaca się pozbyć 99.9...% par, które nie mają ze sobą nic wspólnego.
Jak znaleźć dokładne dopasowania pomóc znaleźć inexact dopasowania? Dobrze., powiedzmy, że dopuszczamy tylko jedną różnicę między zapytaniem a celem. Łatwo zauważyć, że ta różnica musi wystąpić w prawej lub lewej połowie zapytania, a więc druga połowa musi dokładnie pasować. Idea ta może być rozszerzona na wiele niedopasowań i jest podstawą algorytmu ELAND powszechnie stosowanego w sekwencerach DNA Illumina.
Istnieje wiele bardzo dobrych algorytmów do dokładnego dopasowywania łańcuchów. Podany ciąg zapytania o długości 200, a docelowy ciąg długość 3 miliardów (ludzki genom), chcemy znaleźć dowolne miejsce w celu, w którym istnieje podłańcuch długości k, który dokładnie odpowiada podłańcuchowi zapytania. Proste podejście polega na indeksowaniu celu: pobieramy wszystkie podłańcuchy o długości k, umieszczamy je w tablicy i sortujemy. Następnie weź każdy podciąg zapytania o długości k i przeszukaj posortowany indeks. sortowanie i wyszukiwanie można wykonać w czasie O (log n).
Ale przechowywanie może być problemem. Indeks 3 mld docelowej litery musiałby posiadać 3 miliardy wskaźników i 3 miliardy słów o długości K. Wydaje się, że trudno zmieścić to w mniej niż kilkudziesięciu gigabajtach pamięci RAM. Ale o dziwo możemy znacznie skompresować indeks, używając transformaty Burrowsa-Wheelera , i nadal będzie ona efektywnie kwerendowalna. Indeks ludzkiego genomu może zmieścić się w mniej niż 4 GB PAMIĘCI RAM. Idea ta jest podstawą popularnych alignerów sekwencji, takich jak Bowtie i BWA.
Alternatywnie możemy użyć przyrostka tablica, która przechowuje tylko wskaźniki, ale reprezentuje jednocześnie indeks wszystkich sufiksów w ciągu docelowym (zasadniczo, jednoczesny indeks wszystkich możliwych wartości k; to samo dotyczy transformacji Burrowsa-Wheelera). Indeks tablicy sufiksów ludzkiego genomu zajmie 12 GB PAMIĘCI RAM, jeśli użyjemy wskaźników 32-bitowych.
Powyższe linki zawierają bogactwo informacji i linków do podstawowych prac badawczych. Link ELAND przechodzi do pliku PDF z przydatnymi danymi ilustrującymi pojęcia zaangażowany i pokazuje, jak radzić sobie z wstawianiem i usuwaniem.
Wreszcie, podczas gdy te algorytmy w zasadzie rozwiązały problem (re)sekwencjonowania pojedynczych ludzkich genomów (miliard krótkich strun), technologia sekwencjonowania DNA poprawia się jeszcze szybciej niż Prawo Moore ' a, a my szybko zbliżamy się do bilionowych zbiorów danych. Na przykład, obecnie trwają projekty sekwencji genomów 10,000 gatunków kręgowców, każdy o długości około miliarda liter. Oczywiście, będziemy chcesz zrobić parowe dopasowanie inexact string Na danych...
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-05-04 09:20:44
Kwestionuję, że wybór B jest bliższy łańcuchowi testowemu, ponieważ jest to tylko 4 znaki(i 2 usuwa) z oryginalnego łańcucha. Podczas gdy widzisz C jako bliżej, ponieważ zawiera zarówno brązowy i czerwony. Miałby jednak większy dystans do edycji.
Istnieje algorytm o nazwie Levenshtein Distance , który mierzy odległość edycji między dwoma wejściami.
TUTAJ jest narzędziem dla tego algorytmu.
- wybór stawki A jako odległość 15.
- wybór stawki B jako odległość 6.
- Wybierz C jako odległość 9.
EDIT: Przepraszam, ciągle mieszam struny w narzędziu levenshtein. Aktualizacja poprawnych odpowiedzi.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-05-02 16:46:40
Implementacja Lua, dla potomności:
function levenshtein_distance(str1, str2)
local len1, len2 = #str1, #str2
local char1, char2, distance = {}, {}, {}
str1:gsub('.', function (c) table.insert(char1, c) end)
str2:gsub('.', function (c) table.insert(char2, c) end)
for i = 0, len1 do distance[i] = {} end
for i = 0, len1 do distance[i][0] = i end
for i = 0, len2 do distance[0][i] = i end
for i = 1, len1 do
for j = 1, len2 do
distance[i][j] = math.min(
distance[i-1][j ] + 1,
distance[i ][j-1] + 1,
distance[i-1][j-1] + (char1[i] == char2[j] and 0 or 1)
)
end
end
return distance[len1][len2]
end
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-04-27 19:32:03
Może Cię zainteresować ten wpis na blogu.
Http://seatgeek.com/blog/dev/fuzzywuzzy-fuzzy-string-matching-in-python
Fuzzywuzzy jest biblioteką Pythona, która zapewnia łatwe miary odległości, takie jak odległość Levenshteina do dopasowywania łańcuchów. Jest on zbudowany na bazie difflib w bibliotece standardowej i będzie korzystać z implementacji C Python-levenshtein, jeśli jest dostępna.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-05-04 03:32:50
Ta biblioteka może okazać się pomocna! http://code.google.com/p/google-diff-match-patch/
[[0]} jest obecnie dostępny w Java, JavaScript, Dart, C++, C#, Objective C, Lua i PythonTo działa całkiem dobrze. Używam go w kilku moich projektach Lua.
I nie sądzę, że byłoby zbyt trudne, aby przenieść go do innych języków!
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-05-21 13:21:23
Jeśli robisz to w kontekście wyszukiwarki lub nakładki na bazę danych, możesz rozważyć użycie narzędzia takiego jak Apache Solr , z wtyczką ComplexPhraseQueryParser . Ta kombinacja pozwala na wyszukiwanie w indeksie ciągów z wynikami posortowanymi według trafności, zgodnie z odległością Levenshteina.
Używamy go przeciwko dużej kolekcji artystów i tytułów piosenek, gdy przychodzące zapytanie może mieć jedną lub więcej literówek, a to działa całkiem dobrze(i niezwykle szybko biorąc pod uwagę, że kolekcje są w milionach ciągów).
DODATKOWO, dzięki Solr, możesz na żądanie wyszukiwać indeks za pomocą JSON, dzięki czemu nie będziesz musiał wymyślać rozwiązania między różnymi językami, na które patrzysz.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-05-04 18:21:03
Bardzo, bardzo dobrym zasobem dla tego typu algorytmów jest Simmetrics: http://sourceforge.net/projects/simmetrics/
Niestety nie ma zajebistej strony zawierającej sporo dokumentacji :( W przypadku, gdy pojawi się ponownie, jego poprzedni adres był taki: http://www.dcs.shef.ac.uk / ~sam/simmetrics.html
Voila (dzięki uprzejmości " Wayback Machine"): http://web.archive.org/web/20081230184321/http://www.dcs.shef.ac.uk/~sam/simmetrics.html
Możesz studiować źródło kodu, są dziesiątki algorytmów do tego rodzaju porównań, każdy z innym kompromisem. Implementacje są w Javie.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-05-04 14:48:59
Aby skutecznie odpytywać duży zbiór tekstu, możesz użyć pojęcia Edytuj odległość / prefiks Edytuj odległość.
Edytuj odległość ED (X, y): minimalna liczba transfromów, aby uzyskać z termu x do termu y
Ale obliczanie ED między każdym terminem i tekstem zapytania jest zasobooszczędne i czasochłonne. Dlatego zamiast obliczać ED dla każdego terminu najpierw możemy wyodrębnić możliwe pasujące terminy za pomocą techniki zwanej indeksem Qgram. a następnie zastosować obliczenia ED na tych wybrane terminy.
Zaletą techniki indeksowania Qgram jest obsługa wyszukiwania rozmytego.
Jednym z możliwych sposobów dostosowania indeksu QGram jest zbudowanie odwróconego indeksu za pomocą Qgramów. Tam przechowujemy wszystkie słowa, które składają się z konkretnego Qgram, pod tym Qgram.(Zamiast zapisywać pełny ciąg znaków możesz użyć unikalnego identyfikatora dla każdego łańcucha). W tym celu można użyć struktury danych mapy drzewa w języku Java. Poniżej znajduje się mały przykład na temat przechowywania terminów
Col : colmbia, colombo, Gancola, ta col ama
Następnie podczas zapytań obliczamy liczbę wspólnych Qgramów pomiędzy tekstem zapytania A dostępnymi terminami.
Example: x = HILLARY, y = HILARI(query term)
Qgrams
$$HILLARY$$ -> $$H, $HI, HIL, ILL, LLA, LAR, ARY, RY$, Y$$
$$HILARI$$ -> $$H, $HI, HIL, ILA, LAR, ARI, RI$, I$$
number of q-grams in common = 4
Liczba q-gramów wspólnych = 4.
Dla terminów z dużą liczbą wspólnych Qgramów, obliczamy ED / PED względem terminu zapytania, a następnie sugerujemy termin użytkownikowi końcowemu.
Implementację tej teorii znajdziesz w poniższym projekcie (Patrz "QGramIndex.java"). Nie krępuj się zadawać pytań. https://github.com/Bhashitha-Gamage/City_Search
Aby dowiedzieć się więcej o Edit Distance, Prefix Edit Distance qgram index obejrzyj poniższy film Prof. dr Hannah Bast https://www.youtube.com/embed/6pUg2wmGJRo (lekcja zaczyna się od 20: 06)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-04-03 06:30:02
Problem jest trudny do zaimplementowania, jeśli Dane wejściowe są zbyt duże (powiedzmy miliony ciągów). Użyłem elastic search, żeby to rozwiązać. Po prostu włóż wszystkie dane wejściowe do DB i możesz szybko wyszukać dowolny ciąg znaków na podstawie dowolnej odległości edycji. Oto fragment C#, który wyświetli listę wyników posortowanych według odległości edycji (mniejszej do wyższej)
var res = client.Search<ClassName>(s => s
.Query(q => q
.Match(m => m
.Field(f => f.VariableName)
.Query("SAMPLE QUERY")
.Fuzziness(Fuzziness.EditDistance(5))
)
));
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-12 14:13:13