Jak mogę poprawić wydajność mojego niestandardowego generowania tekstur głębi OpenGL ES 2.0?
Mam aplikację open source na iOS, która używa niestandardowych shaderów OpenGL ES 2.0 do wyświetlania trójwymiarowych reprezentacji struktur molekularnych. Robi to za pomocą proceduralnie generowanych sfer i cylindrów narysowanych na prostokątach, zamiast tych samych kształtów zbudowanych przy użyciu wielu wierzchołków. Minusem tego podejścia jest to, że wartości głębokości dla każdego fragmentu tych obiektów impostor muszą być obliczone w cieniowaniu fragmentów, aby były używane, gdy obiekty nakładają się.
Niestety, OpenGL ES 2.0 nie pozwala pisać do gl_FragDepth , więc musiałem wypisać te wartości do niestandardowej tekstury głębi. Przechodzę nad moją sceną za pomocą obiektu bufora ramki (FBO), renderując tylko kolor odpowiadający wartości głębi, a wyniki są przechowywane w teksturze. Tekstura ta jest następnie ładowana do drugiej połowy mojego procesu renderowania, gdzie generowany jest rzeczywisty obraz ekranu. Jeśli fragment na tym etapie znajduje się na głębokości poziom zapisany w teksturze głębi dla tego punktu na ekranie, jest wyświetlany. Jeśli nie, jest wyrzucony. Więcej o tym procesie, w tym diagramy, można znaleźć w moim poście tutaj .
Generowanie tej tekstury głębi jest wąskim gardłem w moim procesie renderowania i szukam sposobu, aby to przyspieszyć. Wydaje się wolniejsze niż powinno być, ale nie wiem dlaczego. W celu uzyskania właściwego generowania tej tekstury głębi, {[3] } jest wyłączona, GL_BLEND jest włączona za pomocą glBlendFunc(GL_ONE, GL_ONE), a glBlendEquation() jest ustawione na GL_MIN_EXT. Wiem, że wyjście sceny w ten sposób nie jest najszybszy na kafelkowym odroczonym rendererze jak seria PowerVR w urządzeniach z iOS, ale nie mogę wymyślić lepszego sposobu, aby to zrobić.
Mój Shader fragmentów głębi dla sfer (najczęstszy element wyświetlania) wydaje się być sercem tego wąskiego gardła (wykorzystanie Rendererów w instrumentach jest związane z 99%, co wskazuje, że jestem ograniczony przetwarzaniem fragmentów). Obecnie wygląda jak po:
precision mediump float;
varying mediump vec2 impostorSpaceCoordinate;
varying mediump float normalizedDepth;
varying mediump float adjustedSphereRadius;
const vec3 stepValues = vec3(2.0, 1.0, 0.0);
const float scaleDownFactor = 1.0 / 255.0;
void main()
{
float distanceFromCenter = length(impostorSpaceCoordinate);
if (distanceFromCenter > 1.0)
{
gl_FragColor = vec4(1.0);
}
else
{
float calculatedDepth = sqrt(1.0 - distanceFromCenter * distanceFromCenter);
mediump float currentDepthValue = normalizedDepth - adjustedSphereRadius * calculatedDepth;
// Inlined color encoding for the depth values
float ceiledValue = ceil(currentDepthValue * 765.0);
vec3 intDepthValue = (vec3(ceiledValue) * scaleDownFactor) - stepValues;
gl_FragColor = vec4(intDepthValue, 1.0);
}
}
Kiedy uproszczę to do
precision mediump float;
varying mediump vec2 impostorSpaceCoordinate;
varying mediump float normalizedDepth;
varying mediump float adjustedSphereRadius;
void main()
{
gl_FragColor = vec4(adjustedSphereRadius * normalizedDepth * (impostorSpaceCoordinate + 1.0) / 2.0, normalizedDepth, 1.0);
}
It zajmuje 18-35 ms na iPadzie 1, ale tylko 1,7-2,4 ms na iPhone 4. Szacowana liczba cykli GPU dla tego shadera wynosi 8 cykli. Zmiana czasu renderowania na podstawie liczby cykli nie wydaje się liniowa.
Wreszcie, jeśli po prostu wypowiem Stały Kolor:
precision mediump float;
void main()
{
gl_FragColor = vec4(0.5, 0.5, 0.5, 1.0);
}
Nieliniowe skalowanie w czasie renderowania i nagła zmiana pomiędzy iPadem a iPhonem 4 na drugi shader sprawia, że myślę, że jest coś, co zaginęła. Pełny projekt źródłowy zawierający te trzy warianty shaderów (patrz w SphereDepth.plik fsh i skomentuj odpowiednie sekcje), a model testowy można pobrać z tutaj, jeśli chcesz wypróbować to samodzielnie.
Jeśli czytałeś tak daleko, moje pytanie brzmi: na podstawie tych informacji profilowania, Jak mogę poprawić wydajność renderowania mojego niestandardowego shadera głębi na urządzeniach z systemem iOS?
4 answers
Bazując na zaleceniach Tommy ' ego, Pivota i rotoglupa, zaimplementowałem kilka optymalizacji, które doprowadziły do podwojenia szybkości renderowania zarówno dla generowania tekstur głębi, jak i ogólnego potoku renderowania w aplikacji.
Najpierw ponownie włączyłem wstępnie obliczoną głębię sfery i teksturę oświetlenia, które wcześniej używałem z niewielkim skutkiem, tylko teraz używam odpowiednich wartości precyzji lowp podczas obsługi kolorów i innych wartości z tej tekstury. To połączenie, wraz z odpowiednim mipmappingiem dla tekstury, wydaje się dawać wzrost wydajności o ~10%.
Co ważniejsze, robię teraz przepustkę przed renderowaniem zarówno mojej tekstury głębi, jak i ostatecznego raytraced impostors, gdzie kładę pewną nieprzezroczystą geometrię, aby zablokować piksele, które nigdy nie zostaną renderowane. Aby to zrobić, włączam testowanie głębi, a następnie rysuję kwadraty składające się na obiekty w mojej scenie, skurczone przez sqrt(2) / 2, za pomocą prostego nieprzezroczystego shadera. W ten sposób powstaną kwadratowe wstawki obszar pokrywający znany jako nieprzezroczysty w reprezentowanej kuli.
Następnie wyłączam zapis głębokości za pomocą glDepthMask(GL_FALSE) i renderuję sferę kwadratową w miejscu bliżej użytkownika o jeden promień. Dzięki temu sprzęt do odroczonego renderowania oparty na kafelkach w urządzeniach z systemem iOS może skutecznie usuwać fragmenty, które nigdy nie pojawiłyby się na ekranie w żadnych warunkach, ale nadal zapewniają płynne przecięcia między widocznymi oszustami sfer w oparciu o wartości głębi na piksel. To jest przedstawione w mojej surowej ilustracja poniżej:

W tym przykładzie nieprzezroczyste kwadraty blokujące dla dwóch najwyższych oszustów nie uniemożliwiają renderowania fragmentów widocznych obiektów, ale blokują fragment fragmentów od najniższego oszusta. Przedni oszust może następnie korzystać z testów na piksel, aby wygenerować płynne przecięcie, podczas gdy wiele pikseli z tylnego oszusta nie marnuje cykli GPU przez renderowanie.
Nie myślałem, aby wyłączyć głębokość pisze, ale pozostawia na testach głębi podczas ostatniego etapu renderowania. Jest to klucz do uniemożliwienia oszustom po prostu układania się na sobie, a jednocześnie korzystania z niektórych optymalizacji sprzętowych w GPU PowerVR.
W moich benchmarkach, renderowanie modelu testowego, którego użyłem powyżej daje czasy 18 - 35 ms Na Klatkę, w porównaniu do 35-68 ms, które otrzymałem wcześniej, prawie podwojenie szybkości renderowania. Zastosowanie tej samej nieprzezroczystej geometrii do wstępnego renderowania raytracingu przepustka daje podwojenie ogólnej wydajności renderowania.
Co dziwne, kiedy próbowałem to jeszcze udoskonalić za pomocą wstawionych i ograniczonych ośmiokątów, które powinny obejmować ~17% mniej pikseli podczas rysowania i być bardziej wydajne z blokowaniem fragmentów, wydajność była w rzeczywistości gorsza niż przy użyciu prostych kwadratów do tego. Wykorzystanie kafelków było nadal mniejsze niż 60% w najgorszym przypadku, więc być może większa geometria powodowała więcej braków w pamięci podręcznej.
Edytuj (5/31/2011):
Bazując na sugestii Pivota, stworzyłem ośmiokąty wpisane i ograniczone do użycia zamiast prostokątów, tylko zastosowałem się do zaleceń tutaj w celu optymalizacji trójkątów do rasteryzacji. W poprzednich testach ośmiokąty dawały gorsze wyniki niż kwadraty, pomimo usuwania wielu niepotrzebnych fragmentów i pozwalając na skuteczniejsze blokowanie zakrytych fragmentów. Poprzez dopasowanie rysunku trójkąta w następujący sposób:
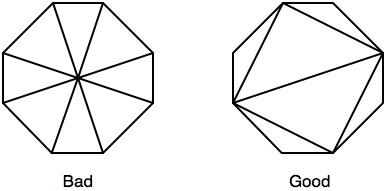
Byłem w stanie skróć ogólny czas renderowania średnio o 14% poza wyżej opisanymi optymalizacjami, przełączając się na ośmiokąty z kwadratów. Tekstura głębokości jest teraz generowana w 19 ms, z sporadycznymi spadkami do 2 ms i kolcami do 35 ms.
EDIT 2 (5/31/2011):
Ponownie przyjrzałem się pomysłowi Tommy ' ego o użyciu funkcji step, teraz, gdy mam mniej fragmentów do odrzucenia z powodu oktagonów. To, w połączeniu z teksturą wyszukiwania głębi dla sfery, prowadzi teraz do średniego czasu renderowania 2 ms na iPad 1 do generowania głębi tekstury dla mojego testowego modelu. Uważam, że jest to tak dobre, jak mogłem mieć nadzieję w tym przypadku renderowania, i gigantyczna poprawa od miejsca, w którym zacząłem. Dla potomności, oto Shader głębi, którego teraz używam:
precision mediump float;
varying mediump vec2 impostorSpaceCoordinate;
varying mediump float normalizedDepth;
varying mediump float adjustedSphereRadius;
varying mediump vec2 depthLookupCoordinate;
uniform lowp sampler2D sphereDepthMap;
const lowp vec3 stepValues = vec3(2.0, 1.0, 0.0);
void main()
{
lowp vec2 precalculatedDepthAndAlpha = texture2D(sphereDepthMap, depthLookupCoordinate).ra;
float inCircleMultiplier = step(0.5, precalculatedDepthAndAlpha.g);
float currentDepthValue = normalizedDepth + adjustedSphereRadius - adjustedSphereRadius * precalculatedDepthAndAlpha.r;
// Inlined color encoding for the depth values
currentDepthValue = currentDepthValue * 3.0;
lowp vec3 intDepthValue = vec3(currentDepthValue) - stepValues;
gl_FragColor = vec4(1.0 - inCircleMultiplier) + vec4(intDepthValue, inCircleMultiplier);
}
Zaktualizowałem próbkę testową tutaj , jeśli chcesz zobaczyć to nowe podejście w działaniu w porównaniu do tego, co robiłem na początku.
Wciąż jestem otwarty na inne sugestie, ale jest to ogromny krok naprzód w tej podanie.Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-05-31 20:33:26
Na pulpicie, było tak na wielu wczesnych programowalnych urządzeniach, że chociaż mogły przetwarzać 8 lub 16 lub jakiekolwiek fragmenty jednocześnie, faktycznie miały tylko jeden licznik programów dla ich partii (ponieważ oznacza to również tylko jedną jednostkę pobierania/dekodowania i jedną ze wszystkiego innego, o ile działają w jednostkach 8 lub 16 pikseli). Stąd początkowy zakaz warunkowości, a przez jakiś czas po nim sytuacja, w której gdyby warunkowe oceny dla Pikseli, które byłyby przetworzone razem zwracały różne wartości, piksele te były przetwarzane w mniejszych grupach w pewnym układzie.
Chociaż PowerVR nie są jednoznaczne, ich zalecenia dotyczące rozwoju aplikacji mają sekcję dotyczącą kontroli przepływu i zawierają wiele zaleceń dotyczących dynamicznych gałęzi, które zazwyczaj są dobrym pomysłem tylko tam, gdzie wynik jest rozsądnie przewidywalny, co sprawia, że myślę, że dostają się do tego samego rodzaju rzeczy. Sugerowałbym zatem, że dysproporcja prędkości może być bo zawarłeś warunek.
Jako pierwszy test, co się stanie, jeśli spróbujesz następujących?
void main()
{
float distanceFromCenter = length(impostorSpaceCoordinate);
// the step function doesn't count as a conditional
float inCircleMultiplier = step(distanceFromCenter, 1.0);
float calculatedDepth = sqrt(1.0 - distanceFromCenter * distanceFromCenter * inCircleMultiplier);
mediump float currentDepthValue = normalizedDepth - adjustedSphereRadius * calculatedDepth;
// Inlined color encoding for the depth values
float ceiledValue = ceil(currentDepthValue * 765.0) * inCircleMultiplier;
vec3 intDepthValue = (vec3(ceiledValue) * scaleDownFactor) - (stepValues * inCircleMultiplier);
// use the result of the step to combine results
gl_FragColor = vec4(1.0 - inCircleMultiplier) + vec4(intDepthValue, inCircleMultiplier);
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-05-18 23:07:00
Wiele z tych punktów zostało omówionych przez innych, którzy opublikowali odpowiedzi, ale nadrzędnym tematem jest to, że Twój rendering wykonuje dużo pracy, która zostanie odrzucona:
Sam shader wykonuje potencjalnie zbędną pracę. długość wektora może być obliczona jako
sqrt(dot(vector, vector)). Nie potrzebujesz sqrt, aby odrzucić fragmenty poza okręgiem, a i tak obliczasz długość, aby obliczyć głębokość. Dodatkowo, czy przyjrzałeś się, czy czy nie Jawna kwantyzacja wartości głębi jest rzeczywiście konieczna, czy może ujdzie ci to na sucho po prostu za pomocą sprzętowej konwersji z zmiennoprzecinkowego na liczbę całkowitą dla bufora ramki (potencjalnie z dodatkowym odchyleniem, aby upewnić się, że testy quasi-głębi pojawią się zaraz później)?Wiele fragmentów jest trywialnie poza kręgiem. tylko π / 4 powierzchni rysowanych quadów daje użyteczne wartości głębokości. W tym momencie wyobrażam sobie, że Twoja aplikacja jest mocno wypaczona w kierunku przetwarzanie fragmentów, więc warto rozważyć zwiększenie liczby rysowanych wierzchołków w zamian za zmniejszenie obszaru, który trzeba zacienić. Ponieważ rysujesz sfery za pomocą rzutowania ortograficznego, wystarczy dowolny regularny wielokąt, chociaż możesz potrzebować trochę dodatkowego rozmiaru w zależności od poziomu powiększenia, aby upewnić się, że rasteryzujesz wystarczającą ilość pikseli.
Wiele fragmentów jest trywialnie zamkniętych przez inne fragmenty. jak zauważyli inni, jesteś nie używając testu głębokości sprzętowej, a tym samym nie wykorzystując w pełni zdolności tbdr do zabijania cieniowania działa wcześnie. Jeśli już zaimplementowałeś coś dla 2), wszystko, co musisz zrobić, to narysować wpisany wielokąt regularny na maksymalnej głębokości, którą możesz wygenerować (płaszczyzna przez środek kuli), i narysować prawdziwy wielokąt na minimalnej głębokości (przód kuli). Zarówno stanowiska Tommy ' ego, jak i rotoglupa zawierają już specyfikę wektora stanu.
Zauważ, że 2) i 3) Zastosuj również shadery raytracing.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-05-28 16:44:06
W ogóle nie jestem ekspertem od platform mobilnych, ale myślę, że to, co cię gryzie, to to: {]}
- Twój Shader głębi jest dość drogi]}
[[9]}Doświadcz ogromnego przeciążenia w przejściu głębokości, gdy wyłączysz
GL_DEPTH test
Czy dodatkowa przepustka, narysowana przed testem głębokości nie byłaby pomocna ?
To przejście może wykonać GL_DEPTH prefill, na przykład rysując każdą sferę reprezentowaną jako czworokątna kamera (lub sześcian, który może być łatwiejszy do Ustawienia), a zawarty w powiązana kula. Ten pass może być rysowany bez maski kolorów lub shadera fragmentów, tylko z włączonymi GL_DEPTH_TEST i glDepthMask. Na platformach stacjonarnych tego rodzaju przejścia są rysowane szybciej niż przejścia kolor + głębia.
Następnie możesz włączyć GL_DEPTH_TEST i wyłączyć glDepthMask, w ten sposób twój shader nie będzie uruchamiany na pikselach ukrytych przez bliższą geometrię.
To rozwiązanie wymagałoby wydania innego zestawu wywołań losowania, więc może to nie być korzystne.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-05-20 17:41:49