Jaki jest najbardziej efektywny sposób znajdowania wszystkich czynników liczby w Pythonie?
Czy ktoś może mi wyjaśnić skuteczny sposób znajdowania wszystkich czynników liczby w Pythonie (2.7)?
Mogę tworzyć algorytmy do tego zadania, ale myślę, że jest to źle zakodowane i zajmuje zbyt dużo czasu, aby wykonać wynik dla dużych liczb.
19 answers
from functools import reduce
def factors(n):
return set(reduce(list.__add__,
([i, n//i] for i in range(1, int(n**0.5) + 1) if n % i == 0)))
To zwróci wszystkie czynniki, bardzo szybko, liczby n.
Dlaczego pierwiastek kwadratowy jako górna granica?
sqrt(x) * sqrt(x) = x. Więc jeśli te dwa czynniki są takie same, to oba są pierwiastkiem kwadratowym. Jeśli jeden czynnik będzie większy, drugi będzie mniejszy. Oznacza to, że jeden z tych dwóch czynników zawsze będzie mniejszy lub równy sqrt(x), więc musisz tylko szukać do tego momentu, aby znaleźć jeden z dwóch dopasowanych czynników. Następnie możesz użyć x / fac1, Aby uzyskać fac2.
reduce(list.__add__, ...) zbiera małe listy [fac1, fac2] i łączy je w jedną długą listę.
[i, n/i] for i in range(1, int(sqrt(n)) + 1) if n % i == 0 zwraca parę czynników, jeśli reszta po podzieleniu n przez mniejszy jest równa zeru (nie trzeba sprawdzać również większego; po prostu otrzymuje to dzieląc n przez mniejszy.)
set(...) Na zewnątrz jest pozbycie się duplikatów, co zdarza się tylko dla doskonałych kwadratów. Dla n = 4, to zwróci 2 dwa razy, więc set pozbędzie się jednego z nich.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-08-12 05:02:49
Rozwiązanie przedstawione przez @ agf jest świetne, ale można osiągnąć ~50% szybszy czas uruchamiania dla dowolnej liczby nieparzystej, sprawdzając parzystość. Ponieważ czynniki liczby nieparzystej zawsze są nieparzyste same w sobie, nie jest konieczne ich sprawdzanie w przypadku liczb nieparzystych.
Właśnie zacząłem rozwiązywać zagadki projektu Euler. W niektórych problemach sprawdzanie dzielnika jest wywoływane wewnątrz dwóch zagnieżdżonych pętlifor, a wydajność tej funkcji jest zatem niezbędne.
Łącząc ten fakt z doskonałym rozwiązaniem agf, skończyłem z tą funkcją:
from math import sqrt
def factors(n):
step = 2 if n%2 else 1
return set(reduce(list.__add__,
([i, n//i] for i in range(1, int(sqrt(n))+1, step) if n % i == 0)))
Jednak na małych liczbach (~
Przeprowadziłem kilka testów, żeby sprawdzić prędkość. Poniżej znajduje się użyty kod. Aby stworzyć różne wątki, zmieniłem odpowiednio X = range(1,100,1).
import timeit
from math import sqrt
from matplotlib.pyplot import plot, legend, show
def factors_1(n):
step = 2 if n%2 else 1
return set(reduce(list.__add__,
([i, n//i] for i in range(1, int(sqrt(n))+1, step) if n % i == 0)))
def factors_2(n):
return set(reduce(list.__add__,
([i, n//i] for i in range(1, int(sqrt(n)) + 1) if n % i == 0)))
X = range(1,100000,1000)
Y = []
for i in X:
f_1 = timeit.timeit('factors_1({})'.format(i), setup='from __main__ import factors_1', number=10000)
f_2 = timeit.timeit('factors_2({})'.format(i), setup='from __main__ import factors_2', number=10000)
Y.append(f_1/f_2)
plot(X,Y, label='Running time with/without parity check')
legend()
show()
X = range (1,100,1)
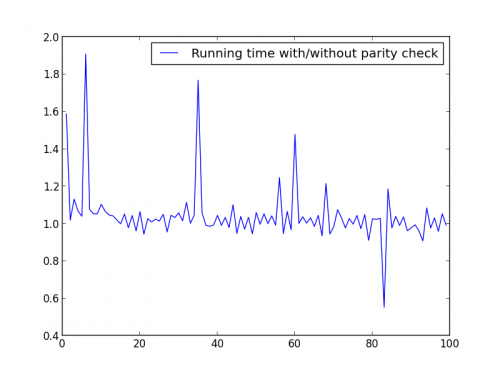
Nie ma tu znaczącej różnicy, ale z większe liczby, zaleta jest oczywista:
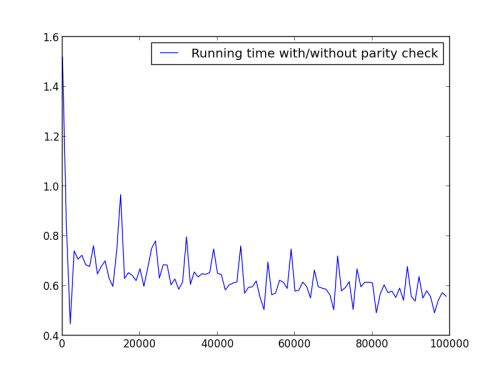
X = range(1,100000,1000) (tylko liczby nieparzyste)
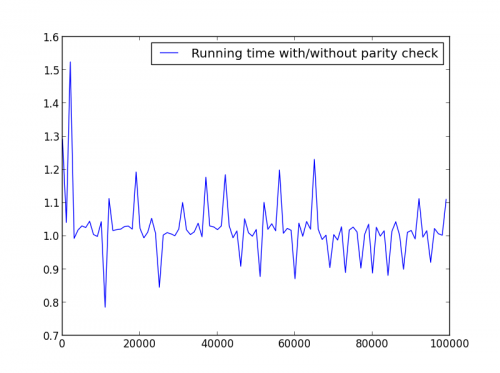
X = range(2,100000,100) (tylko liczby parzyste)
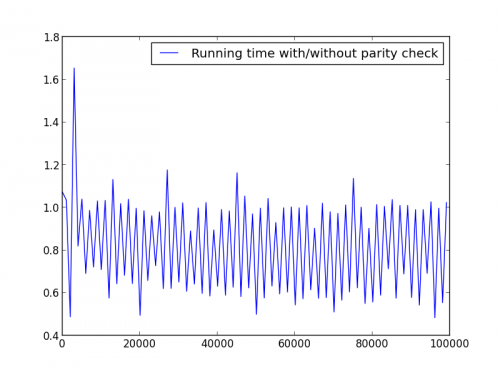
X = range(1,100000,1001) (przemienny parzystość)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-09-30 20:58:11
Odpowiedź Agf jest naprawdę całkiem fajna. Chciałem zobaczyć, czy mogę go przepisać, aby uniknąć używania reduce(). Oto co wymyśliłem:
import itertools
flatten_iter = itertools.chain.from_iterable
def factors(n):
return set(flatten_iter((i, n//i)
for i in range(1, int(n**0.5)+1) if n % i == 0))
Wypróbowałem również wersję, która wykorzystuje trudne funkcje generatora:
def factors(n):
return set(x for tup in ([i, n//i]
for i in range(1, int(n**0.5)+1) if n % i == 0) for x in tup)
Udało mi się to obliczyć:
start = 10000000
end = start + 40000
for n in range(start, end):
factors(n)
Uruchomiłem go raz, aby pozwolić Pythonowi skompilować go, a następnie uruchomiłem go pod komendą time(1) trzy razy i zachowałem najlepszy czas.
- reduce version: 11.58 seconds
- wersja itertools: 11.49 seconds
- tricky version: 11.12 seconds
Zauważ, że wersja itertools buduje krotkę i przekazuje ją do flatten_iter (). Jeśli zmienię kod, aby zbudować listę, zwolni to nieco:
- iterools (lista) wersja: 11.62 sekund
Uważam, że wersja tricky generator functions jest najszybsza z możliwych w Pythonie. Ale nie jest tak naprawdę dużo szybszy niż wersja reduce, około 4% szybciej na podstawie moich pomiarów.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-06-20 07:49:14
Alternatywne podejście do odpowiedzi agf:
def factors(n):
result = set()
for i in range(1, int(n ** 0.5) + 1):
div, mod = divmod(n, i)
if mod == 0:
result |= {i, div}
return result
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-07-23 13:10:10
[[1]}dalsze ulepszenie rozwiązania afg & eryksun. Poniższy fragment kodu zwraca posortowaną listę wszystkich czynników bez zmiany asymptotycznej złożoności czasu wykonania:
def factors(n):
l1, l2 = [], []
for i in range(1, int(n ** 0.5) + 1):
q,r = n//i, n%i # Alter: divmod() fn can be used.
if r == 0:
l1.append(i)
l2.append(q) # q's obtained are decreasing.
if l1[-1] == l2[-1]: # To avoid duplication of the possible factor sqrt(n)
l1.pop()
l2.reverse()
return l1 + l2
Idea: zamiast używać listy.funkcja sort (), aby uzyskać posortowaną listę, która daje NLog (n) złożoność; jest znacznie szybsze użycie listy.reverse() na l2, który przyjmuje złożoność O (n). (Tak powstaje python.) Po l2.reverse (), l2 może być dołączone do l1, aby uzyskać posortowaną listę czynników.
Zawiadomienie, l1 zawiera i - s, które się zwiększają. l2 zawiera q - s, które zmniejszają się. To jest powód wykorzystania powyższej idei.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-04-27 17:21:29
Wypróbowałem większość z tych wspaniałych odpowiedzi z czasem, aby porównać ich wydajność z moją prostą funkcją, A jednak ciągle widzę, że moja przewyższa te wymienione tutaj. Pomyślałem, że się tym podzielę i zobaczę, co myślicie.
def factors(n):
results = set()
for i in xrange(1, int(math.sqrt(n)) + 1):
if n % i == 0:
results.add(i)
results.add(int(n/i))
return results
Tak jak jest napisane musisz zaimportować matmę do testu, ale zastąpić matmę.sqrt (n) Z n**.5 powinno działać równie dobrze. Nie tracę czasu na sprawdzanie duplikatów, ponieważ duplikaty nie mogą istnieć w zestawie niezależnie od tego.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-03-30 21:56:13
Oto alternatywa dla rozwiązania @agf, które implementuje ten sam algorytm w bardziej pythonicznym stylu:
def factors(n):
return set(
factor for i in range(1, int(n**0.5) + 1) if n % i == 0
for factor in (i, n//i)
)
To rozwiązanie działa zarówno w Pythonie 2 jak i Pythonie 3 bez importu i jest znacznie bardziej czytelne. Nie testowałem wydajności tego podejścia, ale asymptotycznie powinno być tak samo, a jeśli wydajność jest poważnym problemem, żadne rozwiązanie nie jest optymalne.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-09-30 21:01:12
Istnieje algorytm siły przemysłu w SymPy o nazwie factorint :
>>> from sympy import factorint
>>> factorint(2**70 + 3**80)
{5: 2,
41: 1,
101: 1,
181: 1,
821: 1,
1597: 1,
5393: 1,
27188665321L: 1,
41030818561L: 1}
Zauważ, że nawet jeśli zaakceptowana odpowiedź mogła trwać wystarczająco długo (tj. wieczność), aby uwzględnić powyższą liczbę, dla niektórych dużych liczb nie powiedzie się, taki poniższy przykład. Jest to spowodowane do niechlujnych int(n**0.5). Na przykład, gdy n = 10000000000000079**2, mamy
>>> int(n**0.5)
10000000000000078L
Ponieważ10000000000000079 jest liczbą pierwszą , algorytm zaakceptowanej odpowiedzi nigdy nie znajdzie tego czynnika. Zauważ, że nie jest to tylko off-by-one; dla większych liczb będzie off o więcej. Z tego powodu lepiej unikać liczb zmiennoprzecinkowych w tego typu algorytmach.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-17 06:14:39
Oto kolejna alternatywa bez redukcji, która działa dobrze z dużymi liczbami. Używa sum do spłaszczenia listy.
def factors(n):
return set(sum([[i, n//i] for i in xrange(1, int(n**0.5)+1) if not n%i], []))
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-01-08 21:54:50
Pamiętaj, aby pobrać liczbę większą niż sqrt(number_to_factor) dla liczb nietypowych, takich jak 99, która ma 3*3*11 i floor sqrt(99)+1 == 10.
import math
def factor(x):
if x == 0 or x == 1:
return None
res = []
for i in range(2,int(math.floor(math.sqrt(x)+1))):
while x % i == 0:
x /= i
res.append(i)
if x != 1: # Unusual numbers
res.append(x)
return res
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-09-30 20:54:27
Dla n do 10* * 16 (może nawet trochę więcej), oto szybkie rozwiązanie pure Python 3.6,
from itertools import compress
def primes(n):
""" Returns a list of primes < n for n > 2 """
sieve = bytearray([True]) * (n//2)
for i in range(3,int(n**0.5)+1,2):
if sieve[i//2]:
sieve[i*i//2::i] = bytearray((n-i*i-1)//(2*i)+1)
return [2,*compress(range(3,n,2), sieve[1:])]
def factorization(n):
""" Returns a list of the prime factorization of n """
pf = []
for p in primeslist:
if p*p > n : break
count = 0
while not n % p:
n //= p
count += 1
if count > 0: pf.append((p, count))
if n > 1: pf.append((n, 1))
return pf
def divisors(n):
""" Returns an unsorted list of the divisors of n """
divs = [1]
for p, e in factorization(n):
divs += [x*p**k for k in range(1,e+1) for x in divs]
return divs
n = 600851475143
primeslist = primes(int(n**0.5)+1)
print(divisors(n))
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-10-09 00:33:28
Oto przykład, jeśli chcesz użyć liczby primes, aby przejść o wiele szybciej. Listy te są łatwe do znalezienia w Internecie. Dodałem komentarze w kodzie.
# http://primes.utm.edu/lists/small/10000.txt
# First 10000 primes
_PRIMES = (2, 3, 5, 7, 11, 13, 17, 19, 23, 29,
31, 37, 41, 43, 47, 53, 59, 61, 67, 71,
73, 79, 83, 89, 97, 101, 103, 107, 109, 113,
127, 131, 137, 139, 149, 151, 157, 163, 167, 173,
179, 181, 191, 193, 197, 199, 211, 223, 227, 229,
233, 239, 241, 251, 257, 263, 269, 271, 277, 281,
283, 293, 307, 311, 313, 317, 331, 337, 347, 349,
353, 359, 367, 373, 379, 383, 389, 397, 401, 409,
419, 421, 431, 433, 439, 443, 449, 457, 461, 463,
467, 479, 487, 491, 499, 503, 509, 521, 523, 541,
547, 557, 563, 569, 571, 577, 587, 593, 599, 601,
607, 613, 617, 619, 631, 641, 643, 647, 653, 659,
661, 673, 677, 683, 691, 701, 709, 719, 727, 733,
739, 743, 751, 757, 761, 769, 773, 787, 797, 809,
811, 821, 823, 827, 829, 839, 853, 857, 859, 863,
877, 881, 883, 887, 907, 911, 919, 929, 937, 941,
947, 953, 967, 971, 977, 983, 991, 997, 1009, 1013,
# Mising a lot of primes for the purpose of the example
)
from bisect import bisect_left as _bisect_left
from math import sqrt as _sqrt
def get_factors(n):
assert isinstance(n, int), "n must be an integer."
assert n > 0, "n must be greather than zero."
limit = pow(_PRIMES[-1], 2)
assert n <= limit, "n is greather then the limit of {0}".format(limit)
result = set((1, n))
root = int(_sqrt(n))
primes = [t for t in get_primes_smaller_than(root + 1) if not n % t]
result.update(primes) # Add all the primes factors less or equal to root square
for t in primes:
result.update(get_factors(n/t)) # Add all the factors associted for the primes by using the same process
return sorted(result)
def get_primes_smaller_than(n):
return _PRIMES[:_bisect_left(_PRIMES, n)]
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-02-20 06:22:18
Użycie {[1] } powoduje, że kod jest nieco wolniejszy i jest niezbędny tylko wtedy, gdy sprawdzasz pierwiastek kwadratowy. Oto moja wersja:
def factors(num):
if (num == 1 or num == 0):
return []
f = [1]
sq = int(math.sqrt(num))
for i in range(2, sq):
if num % i == 0:
f.append(i)
f.append(num/i)
if sq > 1 and num % sq == 0:
f.append(sq)
if sq*sq != num:
f.append(num/sq)
return f
Warunek if sq*sq != num: jest konieczny dla liczb takich jak 12, gdzie pierwiastek kwadratowy nie jest liczbą całkowitą, ale podłoga pierwiastka kwadratowego jest czynnikiem.
Zauważ, że ta wersja nie zwraca samego numeru, ale jest to Łatwa poprawka, jeśli chcesz. Wyjście również nie jest posortowane.
I timed it running 10000 times on all numbers 1-200 and 100 razy na wszystkich numerach 1-5000. Przewyższa wszystkie inne wersje, które testowałem, w tym rozwiązania dansalmo, Jason Schorn, oxrock, agf, steveha i eryksun, choć oxrock jest zdecydowanie najbliższy.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-09-02 21:13:20
Użyj czegoś tak prostego, jak poniższa lista, zauważając, że nie musimy testować 1 i liczby, którą próbujemy znaleźć:
def factors(n):
return [x for x in range(2, n//2+1) if n%x == 0]
W odniesieniu do użycia pierwiastka kwadratowego, powiedzmy, że chcemy znaleźć czynniki 10. Część całkowita sqrt(10) = 4 Dlatego range(1, int(sqrt(10))) = [1, 2, 3, 4] i testowanie do 4 wyraźnie pomija 5.
Chyba, że coś mi umyka, sugerowałbym, jeśli musisz zrobić to w ten sposób, używając int(ceil(sqrt(x))). Oczywiście powoduje to wiele niepotrzebnych wywołań funkcji.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-09-30 20:56:00
Potencjalnie bardziej wydajny algorytm niż przedstawiony tutaj (zwłaszcza jeśli w n istnieją małe faktony pierwsze). sztuczka polega na tym, aby dostosować limit , do którego podziału próby jest potrzebny za każdym razem, gdy zostaną znalezione czynniki pierwsze:
def factors(n):
'''
return prime factors and multiplicity of n
n = p0^e0 * p1^e1 * ... * pk^ek encoded as
res = [(p0, e0), (p1, e1), ..., (pk, ek)]
'''
res = []
# get rid of all the factors of 2 using bit shifts
mult = 0
while not n & 1:
mult += 1
n >>= 1
if mult != 0:
res.append((2, mult))
limit = round(sqrt(n))
test_prime = 3
while test_prime <= limit:
mult = 0
while n % test_prime == 0:
mult += 1
n //= test_prime
if mult != 0:
res.append((test_prime, mult))
if n == 1: # only useful if ek >= 3 (ek: multiplicity
break # of the last prime)
limit = round(sqrt(n)) # adjust the limit
test_prime += 2 # will often not be prime...
if n != 1:
res.append((n, 1))
return res
To jest python3; podział // powinien be the only thing you need to adapt for python 2 (add from __future__ import division).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-17 05:33:51
Myślę, że dla czytelności i szybkości rozwiązanie @ oxrock jest najlepsze, więc tutaj jest przepisany kod dla Pythona 3+:
def num_factors(n):
results = set()
for i in range(1, int(n**0.5) + 1):
if n % i == 0: results.update([i,int(n/i)])
return results
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-03-12 17:19:34
Byłem dość zaskoczony, gdy zobaczyłem to pytanie, że nikt nie używał numpy, nawet jeśli numpy jest dużo szybszy niż pętle Pythona. Implementując rozwiązanie @agf z numpy i okazało się to średnio 8X szybsze . Wierzę, że jeśli zaimplementujesz niektóre z innych rozwiązań w numpy, możesz uzyskać niesamowite czasy.
Oto moja funkcja:
import numpy as np
def b(n):
r = np.arange(1, int(n ** 0.5) + 1)
x = r[np.mod(n, r) == 0]
return set(np.concatenate((x, n / x), axis=None))
Zauważ, że liczby osi x nie są wejściami do funkcji. Wejście do funkcji to 2 do Liczba na osi X minus 1. Więc gdzie dziesięć jest wejście będzie 2* * 10-1 = 1023

Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-08-21 10:47:30
Bez użycia reduce (), która nie jest wbudowaną funkcją w Python3:
def factors(n):
res = [f(x) for f in (lambda x: x, lambda x: n // x) for x in range(1, int(n**0.5) + 1) if not n % x]
return set(res) # returns a set to remove the duplicates from res
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-10-12 12:39:42
Myślę, że jest to najprostszy sposób, aby to zrobić:
x = 23
i = 1
while i <= x:
if x % i == 0:
print("factor: %s"% i)
i += 1
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-08-11 08:06:41