Jak przypisać kolory do zmiennych kategorycznych w ggplot2, które mają stabilne mapowanie?
Byłem na bieżąco z R w ostatnim miesiącu.
Oto moje pytanie:
Jaki jest dobry sposób na przypisanie kolorów do zmiennych kategorycznych w ggplot2, które mają stabilne mapowanie? Potrzebuję spójnych kolorów w zestawie wykresów, które mają różne podzbiory i różną liczbę zmiennych kategorycznych.
Na przykład,
plot1 <- ggplot(data, aes(xData, yData,color=categoricaldData)) + geom_line()
Gdzie categoricalData ma 5 poziomów.
A następnie
plot2 <- ggplot(data.subset, aes(xData.subset, yData.subset,
color=categoricaldData.subset)) + geom_line()
Gdzie categoricalData.subset ma 3 poziomy.
Jednakże, szczególny poziom, który znajduje się w obu zestawach, zakończy się innym kolorem, co utrudnia czytanie wykresów razem.
Czy muszę tworzyć wektor kolorów w ramce danych? A może istnieje inny sposób przypisania określonych kolorów do kategorii?
5 answers
W prostych sytuacjach, takich jak dokładny przykład w OP, zgadzam się, że odpowiedź Thierry ' ego jest najlepsza. Jednak myślę, że warto zwrócić uwagę na inne podejście, które staje się łatwiejsze, gdy próbujesz utrzymać spójne schematy kolorów w wielu klatkach danych, które są , a nie wszystkie uzyskane przez podzbiór jednej dużej ramki danych. Zarządzanie poziomami czynników w wielu klatkach danych może stać się żmudne, jeśli są one pobierane z oddzielnych plików i nie wszystkie poziomy czynników pojawiają się w każdy plik.
Jednym ze sposobów rozwiązania tego problemu jest utworzenie niestandardowej ręcznej skali kolorów w następujący sposób:
#Some test data
dat <- data.frame(x=runif(10),y=runif(10),
grp = rep(LETTERS[1:5],each = 2),stringsAsFactors = TRUE)
#Create a custom color scale
library(RColorBrewer)
myColors <- brewer.pal(5,"Set1")
names(myColors) <- levels(dat$grp)
colScale <- scale_colour_manual(name = "grp",values = myColors)
A następnie dodaj skalę kolorów na wykresie w razie potrzeby:
#One plot with all the data
p <- ggplot(dat,aes(x,y,colour = grp)) + geom_point()
p1 <- p + colScale
#A second plot with only four of the levels
p2 <- p %+% droplevels(subset(dat[4:10,])) + colScale
Pierwsza fabuła wygląda tak:
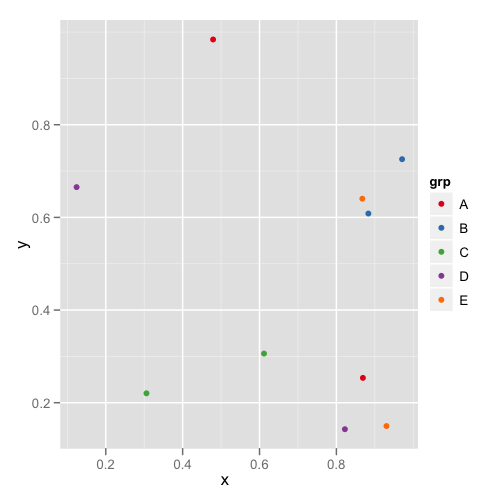
A druga fabuła wygląda tak:
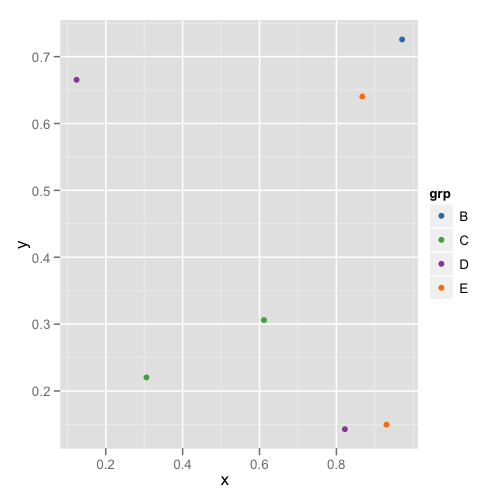
W ten sposób nie musisz pamiętać ani sprawdzać każdej ramki danych, aby sprawdzić, czy mają odpowiednie poziomy.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-04-03 16:20:40
Jestem w tej samej sytuacji co malcook w jego komentarz : niestety odpowiedź przez Thierry nie działa z ggplot2 w wersji 0.9.3.1.
png("figure_%d.png")
set.seed(2014)
library(ggplot2)
dataset <- data.frame(category = rep(LETTERS[1:5], 100),
x = rnorm(500, mean = rep(1:5, 100)),
y = rnorm(500, mean = rep(1:5, 100)))
dataset$fCategory <- factor(dataset$category)
subdata <- subset(dataset, category %in% c("A", "D", "E"))
ggplot(dataset, aes(x = x, y = y, colour = fCategory)) + geom_point()
ggplot(subdata, aes(x = x, y = y, colour = fCategory)) + geom_point()
Oto pierwsza cyfra:
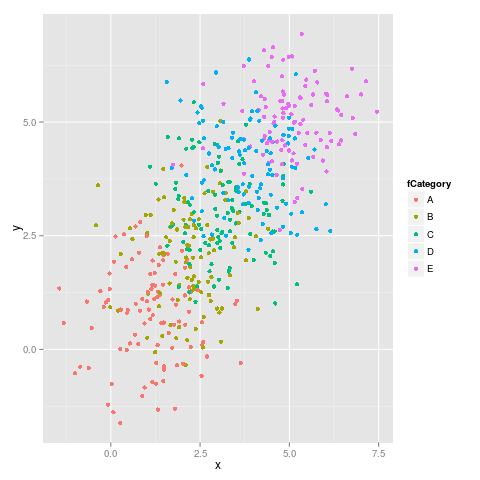
I druga cyfra:
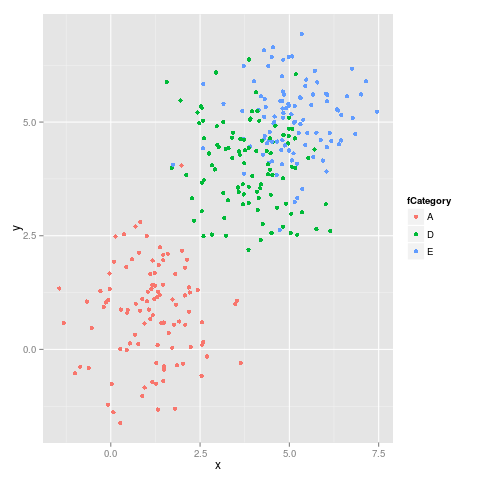
Jak widać kolory nie pozostają stałe, na przykład E przełącza się z magenta na blu.
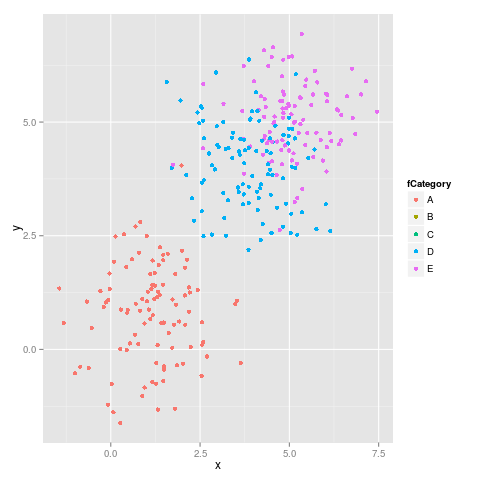
Zgodnie z sugestią malcook w jego komentarz i przez hadley w jego komentarz kod, który używa limits działa poprawnie:
ggplot(subdata, aes(x = x, y = y, colour = fCategory)) +
geom_point() +
scale_colour_discrete(drop=TRUE,
limits = levels(dataset$fCategory))
Daje następującą liczbę, która jest poprawna:
To jest wyjście z sessionInfo():
R version 3.0.2 (2013-09-25)
Platform: x86_64-pc-linux-gnu (64-bit)
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] methods stats graphics grDevices utils datasets base
other attached packages:
[1] ggplot2_0.9.3.1
loaded via a namespace (and not attached):
[1] colorspace_1.2-4 dichromat_2.0-0 digest_0.6.4 grid_3.0.2
[5] gtable_0.1.2 labeling_0.2 MASS_7.3-29 munsell_0.4.2
[9] plyr_1.8 proto_0.3-10 RColorBrewer_1.0-5 reshape2_1.2.2
[13] scales_0.2.3 stringr_0.6.2
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-23 12:18:24
Najprostszym rozwiązaniem jest konwersja zmiennej kategorycznej na czynnik przed podzbiorem. Dolna linia polega na tym, że potrzebna jest zmienna czynnikowa o dokładnie tych samych poziomach we wszystkich podzbiorach.
library(ggplot2)
dataset <- data.frame(category = rep(LETTERS[1:5], 100),
x = rnorm(500, mean = rep(1:5, 100)), y = rnorm(500, mean = rep(1:5, 100)))
dataset$fCategory <- factor(dataset$category)
subdata <- subset(dataset, category %in% c("A", "D", "E"))
Ze zmienną znakową
ggplot(dataset, aes(x = x, y = y, colour = category)) + geom_point()
ggplot(subdata, aes(x = x, y = y, colour = category)) + geom_point()
Ze zmienną czynnikową
ggplot(dataset, aes(x = x, y = y, colour = fCategory)) + geom_point()
ggplot(subdata, aes(x = x, y = y, colour = fCategory)) + geom_point()
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-06-21 05:04:25
Na podstawie bardzo pomocnej odpowiedzi jorana udało mi się wymyślić To rozwiązanie dla stabilnej skali kolorów dla czynnika boolean(TRUE, FALSE).
boolColors <- as.character(c("TRUE"="#5aae61", "FALSE"="#7b3294"))
boolScale <- scale_colour_manual(name="myboolean", values=boolColors)
ggplot(myDataFrame, aes(date, duration)) +
geom_point(aes(colour = myboolean)) +
boolScale
Ponieważ ColorBrewer nie jest zbyt pomocny w binarnych skalach kolorów, dwa potrzebne kolory są definiowane ręcznie.
Tutaj myboolean jest nazwa kolumny w myDataFrame trzymającej współczynnik PRAWDA / FAŁSZ. date i duration to nazwy kolumn, które mają być odwzorowane na osi x i y wykresu w tym przykładzie.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-04-02 21:11:25
To jest stary post, ale szukałem odpowiedzi na to samo pytanie,
Dlaczego nie spróbować czegoś takiego:
scale_color_manual(values = c("foo" = "#999999", "bar" = "#E69F00"))
Jeśli masz wartości kategoryczne, nie widzę powodu, dla którego to nie powinno działać.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-04-08 15:19:54