Porównanie Wyszukiwarki pełnotekstowej-Lucene, Sphinx, Postgresql, MySQL?
Buduję stronę Django i szukam Wyszukiwarki.
Kilku kandydatów:
-
Lucene / Lucene z kompasem / Solr
-
Sfinks
-
Postgresql wbudowane wyszukiwanie pełnotekstowe
-
Wbudowane wyszukiwanie pełnotekstowe MySQl
Kryteria wyboru:
- znaczenie wyników i ranking
- szybkość wyszukiwania i indeksowania
- łatwość użycia i łatwość integracji z Django
- zasób wymagania-strona będzie hostowana na VPS, więc idealnie wyszukiwarka nie wymagałaby dużo pamięci RAM i procesora
- skalowalność
- Dodatkowe funkcje, takie jak " Czy miałeś na myśli?", Podobne wyszukiwania itp
Każdy, kto miał doświadczenie z powyższymi wyszukiwarkami lub innymi silnikami nie znajdującymi się na liście-chętnie wysłucham Waszych opinii.
EDIT: jeśli chodzi o potrzeby indeksowania, ponieważ użytkownicy wciąż wprowadzają dane do witryny, dane te muszą być indeksowane ciągle. Nie musi to być czas rzeczywisty, ale najlepiej, aby nowe dane pojawiały się w indeksie z opóźnieniem nie większym niż 15 - 30 minut
8 answers
Dobrze widzieć, że ktoś mówi o Lucene - bo nie mam o tym pojęcia.
Sfinks, z drugiej strony, wiem dość dobrze, więc zobaczmy, czy mogę w czymś pomóc.
- ranking trafności wyników jest domyślny. Możesz skonfigurować własne sortowanie, jeśli chcesz, i nadać określonym Polom wyższe wagi.
- szybkość indeksowania jest superszybka, ponieważ komunikuje się bezpośrednio z bazą danych. Każda powolność będzie wynikać ze złożonych zapytań SQL i nieindeksowanych kluczy obcych i inne tego typu problemy. Ja też nigdy nie zauważyłem żadnej powolności w poszukiwaniach.
- jestem facetem od Railsów, więc nie mam pojęcia jak łatwo jest zaimplementować z Django. Istnieje API Pythona, które jest dostarczane ze źródłem Sphinx.
- DAEMON usługi wyszukiwania (searchd) jest dość niski w użyciu pamięci - i można ustawić limity na ile pamięci proces indeksowania również używa.
- skalowalność jest tam, gdzie moja wiedza jest bardziej szkicowa - ale łatwo jest skopiować pliki indeksu do wielu Maszyny i uruchomić kilka demonów searchd. Ogólne wrażenie, jakie mam od innych, jest jednak takie, że jest cholernie dobry pod dużym obciążeniem, więc skalowanie go na wiele maszyn nie jest czymś, z czym trzeba sobie radzić.
- nie ma wsparcia dla 'did-you-mean', etc-chociaż można to zrobić za pomocą innych narzędzi wystarczająco łatwo. Sphinx wykonuje słowa macierzyste za pomocą słowników, więc "jazda" i "jazda" (na przykład) byłyby uważane za to samo w wyszukiwaniach.
- Sfinks nie Zezwalaj na częściowe aktualizacje indeksu dla danych pól. Powszechnym podejściem jest utrzymanie wskaźnika delta ze wszystkimi ostatnimi zmianami i ponowne indeksowanie go po każdej zmianie (a te nowe wyniki pojawiają się w ciągu sekundy lub dwóch). Ze względu na niewielką ilość danych może to potrwać kilka sekund. Nadal będziesz musiał regularnie indeksować główny zbiór danych (chociaż jak regularnie zależy od zmienności Twoich danych-każdego dnia? co godzinę?). Szybkie prędkości indeksowania utrzymują to wszystko ale bezbolesne.
Nie mam pojęcia, jak bardzo pasuje to do twojej sytuacji, ale Evan Weaver porównał kilka opcji wyszukiwania common rails (Sphinx, Ferret (port Lucene dla Ruby) i Solr), uruchamiając kilka benchmarków. Może się przydać.
Nie podniosłem głębokości wyszukiwania pełnotekstowego MySQL, ale wiem, że nie konkuruje z szybkością ani funkcją Sphinx, Lucene czy Solr.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2009-04-10 15:08:56
Nie wiem, ale co do Lucene vs bazy danych Wyszukiwanie pełnotekstowe, myślę, że wydajność Lucene jest niezrównana. Powinieneś być w stanie wykonać prawie dowolne wyszukiwanie w czasie krótszym niż 10 ms, bez względu na to, ile rekordów musisz przeszukać, pod warunkiem, że poprawnie skonfigurowałeś indeks Lucene.
Nadchodzi jednak największa przeszkoda: osobiście uważam, że integracja Lucene w Twoim projekcie nie jest łatwa . Oczywiście, nie jest to zbyt trudne do skonfigurowania, więc można zrobić kilka podstawowych Szukaj, ale jeśli chcesz uzyskać jak najwięcej z niego, z optymalną wydajnością, to zdecydowanie potrzebujesz dobrej książki o Lucene.
Jeśli chodzi o wymagania procesora i pamięci RAM, wykonywanie wyszukiwania w Lucene nie wymaga zbyt wiele CPU, chociaż indeksowanie danych jest, chociaż nie robisz tego zbyt często (może raz lub dwa razy dziennie), więc nie jest to duża przeszkoda.
Nie odpowiada na wszystkie Twoje pytania, ale krótko mówiąc, jeśli masz dużo danych do przeszukiwania i chcesz świetnej wydajności, to Myślę, że Lucene to zdecydowanie najlepsza droga. Jeśli nie będziesz miał tyle danych do przeszukiwania, równie dobrze możesz przejść do wyszukiwania pełnotekstowego bazy danych. Skonfigurowanie wyszukiwania pełnotekstowego MySQL jest zdecydowanie łatwiejsze w mojej książce.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2009-04-29 18:23:36
Dziwię się, że nie ma więcej informacji o Solr. Solr jest dość podobny do Sphinx, ale ma bardziej zaawansowane funkcje (AFAIK, ponieważ nie używałem Sphinx - tylko o tym czytałem).
Odpowiedź pod poniższym linkiem opisuje kilka rzeczy na temat Sfinksa, które dotyczą również Solr. Porównanie Wyszukiwarki pełnotekstowej-Lucene, Sphinx, Postgresql, MySQL?
Solr zapewnia również następujące dodatkowe Funkcje:
- podpory replikacja
- wiele rdzeni (traktuj je jako oddzielne bazy danych z własną konfiguracją i własnymi indeksami)
- Wyszukiwanie logiczne
- podświetlanie słów kluczowych (dość łatwe do zrobienia w kodzie aplikacji, Jeśli masz regex-fu; jednak dlaczego nie pozwolić wyspecjalizowanemu narzędziu zrobić lepszą pracę dla Ciebie)
- zaktualizuj indeks za pomocą XML lub rozdzielonego pliku
- komunikować się z serwerem wyszukiwania poprzez HTTP (może nawet zwracać JSON, natywne PHP/Ruby/Python)
- PDF, Dokument Word indeksowanie
- dynamiczne pola
- Fasety
- pola zbiorcze
- Stop słowa, synonimy, itp. Więcej takich...
- indeks bezpośrednio z bazy danych z niestandardowymi zapytaniami
- Auto-suggest
- Cache Autowarming
- szybkie indeksowanie (porównaj z czasem indeksowania wyszukiwania pełnotekstowego MySQL) -- Lucene używa binarnego odwróconego formatu indeksu.
- Boosting (niestandardowe zasady zwiększania trafności danego słowa kluczowego lub frazy, itd.) Jeśli użytkownik zna pole, które chce przeszukać, zawęża wyszukiwanie wpisując pole, następnie wartość i tylko to pole jest wyszukiwane, a nie wszystko-znacznie lepsze wrażenia użytkownika]}
BTW, jest mnóstwo więcej funkcji; jednak wymieniłem tylko funkcje, które faktycznie wykorzystałem w produkcji. BTW, po wyjęciu z pudełka, MySQL obsługuje #1, #3 i #11 (limited) na powyższej liście. Dla funkcji, których szukasz, relacyjna baza danych tego nie przetnie. Wyeliminowałbym je od razu.
Kolejną zaletą jest to, że Solr (właściwie Lucene) jest bazą danych dokumentów (np. NoSQL), więc wiele zalet każdej innej bazy danych dokumentów można zrealizować za pomocą Solr. Innymi słowy, możesz użyć go nie tylko do wyszukiwania (tj. wydajności). Bądź kreatywny:)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-23 12:26:17
Apache Solr
Oprócz odpowiedzi na pytania OP, pozwolę sobie rzucić kilka spostrzeżeń na Apache Solr od prostego wprowadzenia do szczegółowej instalacji i implementacji .
Proste Wprowadzenie
każdy, kto miał doświadczenie z powyższymi wyszukiwarkami lub innymi silników nie ma na liście - chętnie posłucham twojego opinie.
Solr nie powinien być używany do rozwiązywania problemów w czasie rzeczywistym. Dla wyszukiwarek, Solr jest w zasadzie grą i działa bezbłędnie .
Solr działa dobrze na aplikacjach internetowych o dużym natężeniu ruchu (czytałem gdzieś, że nie nadaje się do tego, ale kopię zapasową tego stwierdzenia). Wykorzystuje pamięć RAM, a nie PROCESOR.
- znaczenie wyników i ranking
The boost pomaga w rankingu wyników pokazać się na szczycie. Powiedzmy, że próbujesz wyszukać nazwę john w polach firstname i lastname i chcesz nadać odpowiedniość polu firstname, następnie musisz zwiększyć w górę pola firstname, Jak pokazano.
http://localhost:8983/solr/collection1/select?q=firstname:john^2&lastname:john
Jak widzisz, firstname pole jest wzmocnione z wynikiem 2.
Więcej na SolrRelevancy
Prędkość jest niewiarygodnie szybka i bez kompromisów. Powód, dla którego przeniosłem się do Solr .
- szybkość wyszukiwania i indeksowania
Jeśli chodzi o szybkość indeksowania, Solr może również obsługiwać połączenia z tabel bazy danych. Wyższy i złożony JOIN wpływa na szybkość indeksowania. Jednak ogromna konfiguracja RAM z łatwością poradzi sobie z tą sytuacją.
The im wyższa PAMIĘĆ RAM, tym szybsza jest szybkość indeksowania Solr.
- łatwość użycia i łatwość integracji z Django
Nigdy nie próbowano zintegrować Solr i Django , jednak można to osiągnąć za pomocą stogu siana. Znalazłem ciekawy Artykułna ten sam temat i oto github.
- wymagania dotyczące zasobów-strona będzie hostowana na VPS, więc najlepiej wyszukiwarka nie wymagałaby dużo pamięci RAM i procesora
Solr rodzi się na PAMIĘCI RAM, więc jeśli RAM jest wysoki, nie musisz się martwić o Solr.
Użycie pamięci RAM Solr rośnie przy pełnej indeksacji jeśli masz jakieś miliardy rekordów, możesz mądrze wykorzystać Import Delta do rozwiązania tej sytuacji. Jak wyjaśniono, Solr jest tylko rozwiązaniem prawie w czasie rzeczywistym .
- skalowalność
Solr {[33] } jest wysoce skalowalny. Zobacz na SolrCloud . Niektóre kluczowe jego cechy.
- Shards (lub sharding to pojęcie dystrybucji indeksu wśród wielu maszyn, powiedzmy, jeśli indeks urósł za duży)]}
Solrj jest używany z chmurą Solr, która automatycznie zajmuje się równoważeniem obciążenia za pomocą mechanizmu Round-Robin.]}
- Wyszukiwanie Rozproszone
- wysoki Dostępność
- dodatkowe funkcje, takie jak " Czy miałeś na myśli?", Podobne wyszukiwania itp
W powyższym scenariuszu możesz użyć SpellCheckComponent , który jest spakowany Solr . Istnieje wiele innych funkcji, SnowballPorterFilterFactory pomaga odzyskać rekordy mówią, jeśli wpisałeś, książki zamiast książki , zostaną przedstawione wyniki związane z Księga .
Ta odpowiedź skupia się głównie na Apache Solr & MySQL . Django jest poza zasięgiem.
Zakładając, że jesteś w środowisku LINUX, możesz przejść do tego artykułu dalej. Ubuntu 14.04)
Szczegółowa Instalacja
Pierwsze Kroki
Pobierz Apache Solr z tutaj . Czyli wersja jest 4.8.1. Możesz pobrać nowy wersje, znalazłem ten stabilny.
Po pobraniu archiwum rozpakuj je do wybranego folderu.
Powiedz .. Albo cokolwiek.. Więc to będzie wyglądać Downloads/solr-4.8.1/
Na twój znak.. Nawigacja wewnątrz katalogu
shankar@shankar-lenovo: cd Downloads/solr-4.8.1
shankar@shankar-lenovo: ~/Downloads/solr-4.8.1$
Uruchom serwer aplikacji Jetty
Jetty jest dostępny w folderze examples katalogu solr-4.8.1, więc przejdź do niego i rozpocznij Jetty Application Server.
shankar@shankar-lenovo:~/Downloads/solr-4.8.1/example$ java -jar start.jar
( Wskazówka: Użyj i po starcie.jar, aby serwer Jetty działał w tło)
Aby sprawdzić, czy Apache Solr działa poprawnie, odwiedź ten adres URL w przeglądarce. http://localhost:8983/solr
Uruchamianie Jetty na niestandardowym porcie
Domyślnie działa na porcie 8983. Możesz zmienić port tutaj lub bezpośrednio w pliku jetty.xml.
java -Djetty.port=9091 -jar start.jar
Pobierz JConnector
Ten plik JAR działa jako most pomiędzy MySQL i JDBC, Pobierz niezależną od platformy wersję tutaj
Po pobraniu należy rozpakować folder i skopiować mysql-connector-java-5.1.31-bin.jar i wkleić go do katalogu lib .
shankar@shankar-lenovo:~/Downloads/solr-4.8.1/contrib/dataimporthandler/lib
Tworzenie tabeli MySQL do połączenia z Apache Solr
Aby umieścić Solr na użyj, musisz mieć jakieś tabele i dane do wyszukiwania. W tym celu użyjemy MySQL do tworzenia tabeli i przesuwania losowych nazw, a następnie możemy użyć Solr do połączenia się z MySQL i indeksowania tej tabeli i jej wpisów.
1.Struktura Tabeli
CREATE TABLE test_solr_mysql
(
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
name VARCHAR(45) NULL,
created TIMESTAMP NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (id)
);
2.Wypełnij powyższą tabelę
INSERT INTO `test_solr_mysql` (`name`) VALUES ('Jean');
INSERT INTO `test_solr_mysql` (`name`) VALUES ('Jack');
INSERT INTO `test_solr_mysql` (`name`) VALUES ('Jason');
INSERT INTO `test_solr_mysql` (`name`) VALUES ('Vego');
INSERT INTO `test_solr_mysql` (`name`) VALUES ('Grunt');
INSERT INTO `test_solr_mysql` (`name`) VALUES ('Jasper');
INSERT INTO `test_solr_mysql` (`name`) VALUES ('Fred');
INSERT INTO `test_solr_mysql` (`name`) VALUES ('Jenna');
INSERT INTO `test_solr_mysql` (`name`) VALUES ('Rebecca');
INSERT INTO `test_solr_mysql` (`name`) VALUES ('Roland');
Wejście do rdzenia i dodanie dyrektyw lib
1.Przejdź do
shankar@shankar-lenovo: ~/Downloads/solr-4.8.1/example/solr/collection1/conf
2.Modyfikowanie solrconfig.xml
Dodaj te dwie dyrektywy do tego pliku..
<lib dir="../../../contrib/dataimporthandler/lib/" regex=".*\.jar" />
<lib dir="../../../dist/" regex="solr-dataimporthandler-\d.*\.jar" />
Teraz dodaj DIH (Obsługa importu danych)
<requestHandler name="/dataimport"
class="org.apache.solr.handler.dataimport.DataImportHandler" >
<lst name="defaults">
<str name="config">db-data-config.xml</str>
</lst>
</requestHandler>
3.Utwórz db-data-config.plik xml
Jeśli plik istnieje, to ignoruj, dodaj te linie do tego pliku. Jak widać w pierwszej linii, musisz podać dane uwierzytelniające swojej bazy danych MySQL. Nazwa bazy danych, nazwa użytkownika i hasło.
<dataConfig>
<dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost/yourdbname" user="dbuser" password="dbpass"/>
<document>
<entity name="test_solr" query="select CONCAT('test_solr-',id) as rid,name from test_solr_mysql WHERE '${dataimporter.request.clean}' != 'false'
OR `created` > '${dataimporter.last_index_time}'" >
<field name="id" column="rid" />
<field name="solr_name" column="name" />
</entity>
</document>
</dataConfig>
( WSKAZÓWKA: Możesz mieć dowolną liczbę Bytów, ale uwaga na pole id, jeśli są takie same, indeksowanie zostanie pominięte. )
4.Zmodyfikuj schemat.plik xml
Dodaj to do swojego schematu .xml Jak pokazano..
<uniqueKey>id</uniqueKey>
<field name="solr_name" type="string" indexed="true" stored="true" />
Realizacja
Indeksowanie
Tutaj jest prawdziwa okazja. Aby skorzystać z zapytań Solr, musisz wykonać indeksowanie danych z MySQL do Solr.
Krok 1: Przejdź do panelu administracyjnego Solr
Hit the URL http://localhost:8983/solr w Twojej przeglądarce. Ekran otwiera się w ten sposób.
Jak wskazuje znacznik, przejdź do Logging inorder, aby sprawdzić, czy którakolwiek z powyższych konfiguracji nie doprowadziła do błędów.
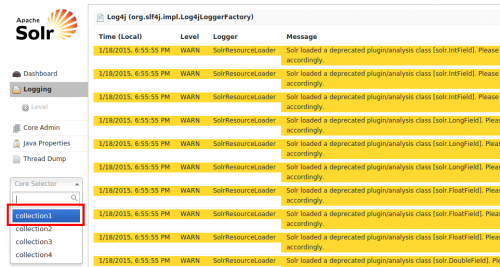
Krok 2: Sprawdź swoje dzienniki
Ok więc teraz jesteś tutaj, jak można Jest wiele żółtych wiadomości (ostrzeżenia). Upewnij się, że komunikaty o błędach nie są zaznaczone na Czerwono. Wcześniej w naszej konfiguracji dodaliśmy zapytanie select na naszym db-data-config.XML, powiedzmy, że gdyby były jakieś błędy w tym zapytaniu, pojawiłoby się tutaj.
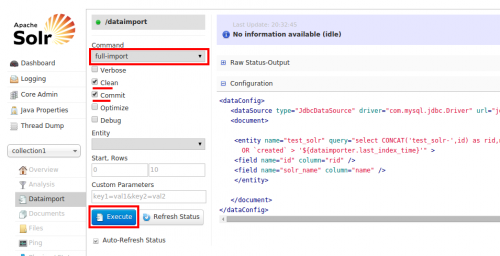
Używając DIH, połączysz się z MySQL z Solr poprzez plik konfiguracyjny db-data-config.xml z interfejs Solr i pobiera 10 rekordów z bazy danych, które są indeksowane do Solr.
Aby to zrobić, wybierz full-import i sprawdź opcje Clean i Commit. Teraz kliknij wykonaj Jak pokazano.
Alternatywnie, można użyć bezpośredniego full-import zapytanie jak to..
http://localhost:8983/solr/collection1/dataimport?command=full-import&commit=true
Po kliknięciu wykonaj, Solr zaczyna indeksować rekordy, gdyby były jakieś błędy, napisałoby indeksowanie nie powiodło się i musisz wrócić do sekcji Logowanie , aby zobaczyć, co poszło nie tak.
Zakładając, że nie ma błędów w tej konfiguracji i jeśli indeksowanie zostanie pomyślnie zakończone., dostaniesz to powiadomienie.

Krok 4: Uruchamianie Zapytań Solr
Wygląda na to, że wszystko poszło dobrze, teraz możesz użyć zapytań Solr do zapytania danych, które zostały zindeksowane. Kliknij Query po lewej stronie, a następnie naciśnij Execute na dole.
Zobaczysz indeksowane rekordy, jak pokazano.
Odpowiednie Solr Zapytanie o listę wszystkich rekordów to
http://localhost:8983/solr/collection1/select?q=*:*&wt=json&indent=true

solr_name, stąd Twoje zapytanie wygląda następująco to.
http://localhost:8983/solr/collection1/select?q=solr_name:Ja*&wt=json&indent=true

Tak się pisze zapytania Solr . Aby przeczytać więcej na ten temat, sprawdź ten piękny Artykuł.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-01-19 11:51:34
Patrzę właśnie na PostgreSQL Full-text search i ma wszystkie właściwe cechy nowoczesnej Wyszukiwarki, naprawdę dobry Rozszerzony charakter i wielojęzyczne wsparcie, Ładna ścisła integracja z polami tekstowymi w bazie danych.
Ale nie ma przyjaznych dla użytkownika operatorów wyszukiwania, takich jak + Lub AND (używa & | !) i nie jestem zachwycony, jak to działa na ich stronie dokumentacji. Chociaż ma pogrubienie terminów meczowych w fragmentach wyników, domyślny algorytm, dla którego mecz warunki nie są dobre. Ponadto, jeśli chcesz indeksować rtf, PDF, MS Office, musisz znaleźć i zintegrować konwerter formatów plików.
OTOH, to o wiele lepsze niż Wyszukiwanie tekstowe MySQL, które nawet nie indeksuje słów z trzech lub mniej liter. Jest to domyślne dla wyszukiwania MediaWiki i naprawdę uważam, że nie jest dobre dla użytkowników końcowych: http://www.searchtools.com/analysis/mediawiki-search/
We wszystkich przypadkach, które widziałem, Lucene / Solr i Sphinx są naprawdę świetne . Są solidny kod i ewoluowały ze znaczną poprawą użyteczności, więc narzędzia są po to, aby wyszukiwanie spełniało prawie wszystkich.
Dla SHAILI-SOLR zawiera bibliotekę kodów wyszukiwania Lucene i ma komponenty, aby być ładną samodzielną wyszukiwarką.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2009-09-17 22:57:50
Tylko moje dwa grosze do tego bardzo starego pytania. Bardzo polecam zajrzeć do ElasticSearch.
Elasticsearch jest serwerem wyszukiwania opartym na Lucene. Zapewnia rozproszoną, wielotenantową wyszukiwarkę pełnotekstową z RESTful Web interface i bez schematów dokumentów JSON. Elasticsearch jest rozwijany w Javie i jest wydany jako open source na warunkach licencji Apache.
Zalety w stosunku do innych FTS (wyszukiwanie pełnotekstowe) Silniki to:
- RESTful interface
- lepsza skalowalność
- duża społeczność
- zbudowany przez Lucene deweloperzy
- obszerna dokumentacja
- istnieje wiele bibliotek open source (w tym Django)
Korzystamy z tej wyszukiwarki w naszym projekcie i jesteśmy z niej bardzo zadowoleni.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-01-21 19:07:12
SearchTools-Avi powiedział " wyszukiwanie tekstu MySQL, który nie indeksuje nawet słów z trzech liter lub mniej."
FYIs, min. Długość pełnego tekstu MySQL jest regulowana od co najmniej MySQL 5.0. Google 'mysql fulltext min length' dla prostych instrukcji.
To powiedziawszy, MySQL fulltext ma ograniczenia: po pierwsze, robi się wolno aktualizować po osiągnięciu miliona rekordów lub tak, ...
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2009-09-28 00:51:39
Dodałbym mnoGoSearch do listy. Niezwykle wydajne i elastyczne rozwiązanie, które działa jak Google: indexer pobiera dane z wielu witryn, możesz użyć podstawowych kryteriów lub wymyślić własne Hooki, aby uzyskać maksymalną jakość wyszukiwania. Może również pobierać dane bezpośrednio z bazy danych.
Rozwiązanie nie jest dziś tak znane, ale zaspokaja maksymalne potrzeby. Można go skompilować i zainstalować lub na samodzielnym serwerze, a nawet na głównym serwerze, nie trzeba więc dużo ressources jak Solr, jak to jest napisane w C i działa doskonale nawet na małych serwerach.
Na początku musisz skompilować go samodzielnie, więc wymaga to trochę wiedzy. Zrobiłem mały skrypt dla Debiana, który może pomóc. Wszelkie poprawki są mile widziane.
Jak używasz frameworka Django, to możesz użyć w środku klienta PHP lub znaleźć rozwiązanie w Pythonie, widziałem jakieś Artykuły .
I oczywiście mnoGoSearch jest open source, GNU GPL.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-06-20 21:06:18