Sprawdzanie, czy dane są normalnie dystrybuowane w R
Czy ktoś może mi pomóc wypełnić następującą funkcję w R:
#data is a single vector of decimal values
normally.distributed <- function(data) {
if(data is normal)
return(TRUE)
else
return(NO)
}
8 answers
Testy normalności nie robią tego, co większość myśli. Test Shapiro, Anderson Darling i inni są testami hipotezy zerowej przeciwko założeniu normalności. Nie należy ich używać do określania, czy należy stosować zwykłe procedury statystyczne teorii. W rzeczywistości nie mają one praktycznie żadnej wartości dla analityka danych. Na jakich warunkach jesteśmy zainteresowani odrzuceniem hipotezy zerowej, że dane są normalnie dystrybuowane? Nigdy nie spotkałem się z sytuacją, w której normalny test jest słusznie. Gdy rozmiar próbki jest mały, nawet duże odstępstwa od normalności nie są wykrywane, a gdy rozmiar próbki jest duży, nawet najmniejsze odchylenie od normalności doprowadzi do odrzucenia null.
Na przykład:
> set.seed(100)
> x <- rbinom(15,5,.6)
> shapiro.test(x)
Shapiro-Wilk normality test
data: x
W = 0.8816, p-value = 0.0502
> x <- rlnorm(20,0,.4)
> shapiro.test(x)
Shapiro-Wilk normality test
data: x
W = 0.9405, p-value = 0.2453
Tak więc, w obu tych przypadkach (zmienność dwumianowa i lognormalna) wartość P wynosi > 0.05, co powoduje brak odrzucenia null (że dane są normalne). Czy to oznacza, że mamy stwierdzić, że dane są normalne? (podpowiedź: odpowiedź brzmi nie). Niepowodzenie odrzucenie to nie to samo, co akceptacja. To Test hipotezy 101.
Ale co z większymi rozmiarami próbek? Weźmy przypadek, w którym rozkład jest bardzo {[10] } prawie normalny.> library(nortest)
> x <- rt(500000,200)
> ad.test(x)
Anderson-Darling normality test
data: x
A = 1.1003, p-value = 0.006975
> qqnorm(x)
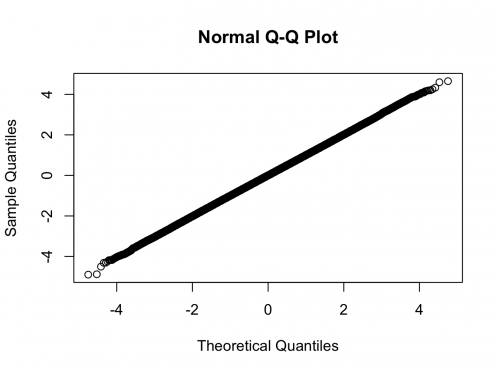
Tutaj używamy rozkładu t o 200 stopniach swobody. Wykres qq pokazuje, że rozkład jest bliższy normalności niż jakakolwiek dystrybucja, którą można zobaczyć w świecie rzeczywistym, ale test odrzuca normalność z bardzo wysokim stopniem pewność siebie.
Czy znaczący test na normalność oznacza, że nie powinniśmy używać w tym przypadku statystyki normalnej teorii? (kolejna podpowiedź: odpowiedź brzmi NIE:))
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-11-07 22:07:57
Gorąco polecam również SnowsPenultimateNormalityTest w pakiecie TeachingDemos. Dokumentacja funkcji jest dla Ciebie o wiele bardziej przydatna niż sam test. Przeczytaj go dokładnie przed użyciem testu.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-01-26 22:44:32
SnowsPenultimateNormalityTest z pewnością ma swoje zalety, ale możesz również chcieć spojrzeć na qqnorm.
X <- rlnorm(100)
qqnorm(X)
qqnorm(rnorm(100))
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-10-16 03:49:09
Rozważ użycie funkcji shapiro.test, który wykonuje test Shapiro-Wilksa na normalność. Byłem z tego zadowolony.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-10-16 01:45:06
Biblioteka (DnE)
X
Jest.norm (x,10,0.05)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-11-16 03:23:34
Test Andersona-Darlinga jest również przydatny.
library(nortest)
ad.test(data)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-10-16 19:07:58
Kiedy wykonujesz test, kiedykolwiek masz probabilty odrzucić hipotezę zerową, gdy jest to prawda.
Zobacz kod nextt R:
p=function(n){
x=rnorm(n,0,1)
s=shapiro.test(x)
s$p.value
}
rep1=replicate(1000,p(5))
rep2=replicate(1000,p(100))
plot(density(rep1))
lines(density(rep2),col="blue")
abline(v=0.05,lty=3)
Wykres pokazuje, że Czy masz wielkość próbki małe lub duże 5% razy masz szansę odrzucić hipotezę zerową, gdy to prawda (błąd typu I)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-10-11 03:32:48
Oprócz qqplots i testu Shapiro-Wilka przydatne mogą być następujące metody.
Jakościowy:
- histogram w porównaniu z normalnym
- cdf w porównaniu do normalnego
- opisy gg
- ggqqplot
Ilość:
Metody jakościowe można wytworzyć stosując w R:
library("ggpubr")
library("car")
h <- hist(data, breaks = 10, density = 10, col = "darkgray")
xfit <- seq(min(data), max(data), length = 40)
yfit <- dnorm(xfit, mean = mean(data), sd = sd(data))
yfit <- yfit * diff(h$mids[1:2]) * length(data)
lines(xfit, yfit, col = "black", lwd = 2)
plot(ecdf(data), main="CDF")
lines(ecdf(rnorm(10000)),col="red")
ggdensity(data)
ggqqplot(data)
A słowo ostrzeżenia - nie ślepo stosować testów. Posiadanie solidnego zrozumienia statystyk pomoże Ci zrozumieć, kiedy używać jakich testów i znaczenie założeń w testowaniu hipotez.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-03-13 23:13:18