Dlaczego pojedynczy proces gwintowany jest wykonywany na kilku procesorach/rdzeniach?
Powiedzmy, że uruchamiam prosty proces jednowątkowy, taki jak ten poniżej:
public class SirCountALot {
public static void main(String[] args) {
int count = 0;
while (true) {
count++;
}
}
}
(to jest Java, bo to jest to, co znam, ale podejrzewam, że to nie ma znaczenia)
Mam procesor i7 (4 rdzenie lub 8 zliczanie hyperthreading), i jestem uruchomiony Windows 7 64-bit, więc odpaliłem Sysinternals Process Explorer, aby spojrzeć na wykorzystanie PROCESORA, i zgodnie z oczekiwaniami widzę, że używa około 20% wszystkich dostępnych procesorów.
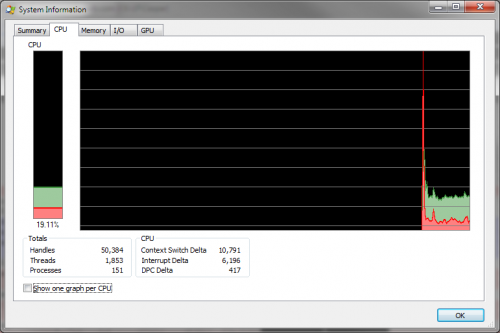
Ale kiedy włączam opcja wyświetlania 1 wykresu na procesor, widzę, że zamiast 1 z 4 używanych "rdzeni", użycie procesora jest rozłożone na wszystkie rdzenie:
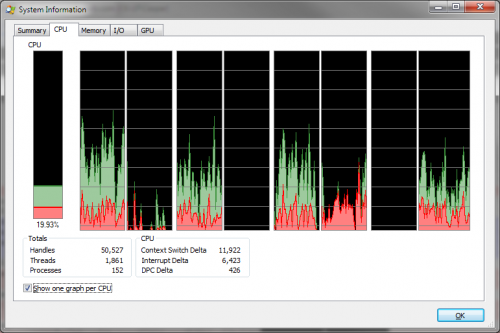
Zamiast tego spodziewałbym się 1 rdzenia maksymalnie, ale dzieje się tak tylko wtedy, gdy ustawiłem powinowactwo do procesu na pojedynczy rdzeń.
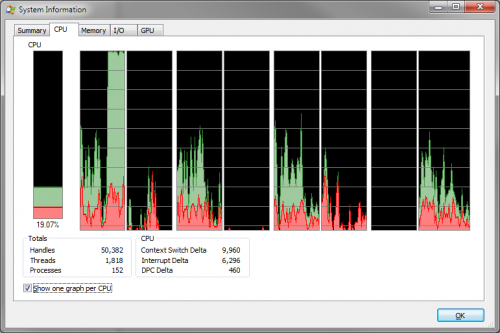
Dlaczego obciążenie jest podzielone na oddzielne rdzenie? Czy podział obciążenia na kilka rdzeni nie zakłóci buforowania lub nie pociągnie za sobą innych kar wydajnościowych?
Czy to dla prosty powód zapobiegania przegrzaniu jednego rdzenia? A może jest jakiś głębszy powód?
Edit: wiem, że system operacyjny jest odpowiedzialny za planowanie, ale chcę wiedzieć, dlaczego to "przeszkadza". Z pewnością z naiwnego punktu widzenia, przyklejenie (głównie*) jednowątkowego procesu do 1 rdzenia jest prostszym i bardziej wydajnym sposobem?
*mówię głównie jedno-gwintowe, ponieważ jest tu wiele wątków, ale tylko 2 z nich robią anything:
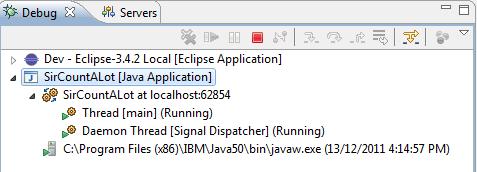
2 answers
System Operacyjny jest odpowiedzialny za planowanie. Można zatrzymać wątek i uruchomić go ponownie na innym procesorze. Zrobi to, nawet jeśli maszyna nie robi nic innego.
Proces jest przenoszony wokół procesorów, ponieważ system operacyjny nie zakłada, że istnieje jakikolwiek powód, aby kontynuować uruchamianie wątku na tym samym procesorze za każdym razem.
Z tego powodu napisałem bibliotekę do blokowania wątków do procesora, aby nie poruszał się i nie był przerywany przez inne wątki. Zmniejsza to opóźnienie i poprawić przepustowość, ale męczy procesor dla tego wątku. To działa na Linuksa, być może można dostosować go do systemu Windows. https://github.com/peter-lawrey/Java-Thread-Affinity/wiki/Getting-started
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-12-13 08:21:27
Spodziewałbym się również, że może to być zrobione celowo przez procesor i system operacyjny, aby spróbować rozłożyć obciążenie termiczne na matrycy procesora...
Aby obrócić (unikalny/pojedynczy) wątek od rdzenia do rdzenia.
I to może być wprawdzie argumentem przeciwko próbom walki z tym zbyt mocno (zwłaszcza, że w praktyce często można zobaczyć lepsze ulepszenia, po prostu dostrajając / ulepszając samą aplikację)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-04-02 07:58:37