Dlaczego dodatki elementwise są znacznie szybsze w oddzielnych pętlach niż w pętli łączonej?
Przypuśćmy a1, b1, c1, i d1 wskaż pamięć sterty, a mój kod numeryczny ma następującą pętlę rdzenia.
const int n = 100000;
for (int j = 0; j < n; j++) {
a1[j] += b1[j];
c1[j] += d1[j];
}
Pętla ta jest wykonywana 10 000 razy przez inną zewnętrzną pętlę for. Aby go przyspieszyć, zmieniłem kod na:
for (int j = 0; j < n; j++) {
a1[j] += b1[j];
}
for (int j = 0; j < n; j++) {
c1[j] += d1[j];
}
Skompilowany na MS Visual C++ 10.0 z pełną optymalizacją i SSE2 włączony dla 32-bitowego na Intel Core 2 Duo (x64), pierwszy przykład zajmuje 5,5 sekundy, a przykład z podwójną pętlą zajmuje tylko 1,9 sekundy. Moje pytanie brzmi: (proszę odnieść się do mojego przeformułowanego pytania na dole)
PS: nie jestem pewien, czy to pomoże:
Demontaż dla pierwszej pętli zasadniczo wygląda tak (blok ten powtarza się około pięć razy w pełnym programie):
movsd xmm0,mmword ptr [edx+18h]
addsd xmm0,mmword ptr [ecx+20h]
movsd mmword ptr [ecx+20h],xmm0
movsd xmm0,mmword ptr [esi+10h]
addsd xmm0,mmword ptr [eax+30h]
movsd mmword ptr [eax+30h],xmm0
movsd xmm0,mmword ptr [edx+20h]
addsd xmm0,mmword ptr [ecx+28h]
movsd mmword ptr [ecx+28h],xmm0
movsd xmm0,mmword ptr [esi+18h]
addsd xmm0,mmword ptr [eax+38h]
Każda pętla przykładu double loop tworzy ten kod (następujący blok powtarza się około trzy razy):
addsd xmm0,mmword ptr [eax+28h]
movsd mmword ptr [eax+28h],xmm0
movsd xmm0,mmword ptr [ecx+20h]
addsd xmm0,mmword ptr [eax+30h]
movsd mmword ptr [eax+30h],xmm0
movsd xmm0,mmword ptr [ecx+28h]
addsd xmm0,mmword ptr [eax+38h]
movsd mmword ptr [eax+38h],xmm0
movsd xmm0,mmword ptr [ecx+30h]
addsd xmm0,mmword ptr [eax+40h]
movsd mmword ptr [eax+40h],xmm0
Pytanie okazało się bez znaczenia, ponieważ zachowanie poważnie zależy od wielkości tablic (n) i pamięci podręcznej procesora. Więc jeśli jest dalsze zainteresowanie, przeformułowuję pytanie:
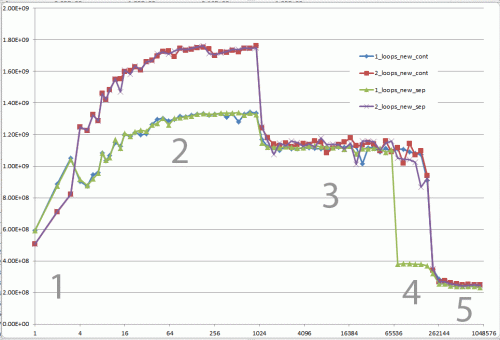
Czy mógłbyś zapewnić solidny wgląd w szczegóły, które prowadzą do różnych zachowań pamięci podręcznej, jak zilustrowane przez pięć regionów na poniższym wykresie?
Interesujące może być również zwrócenie uwagi na różnice między architekturami CPU/cache, poprzez dostarczenie podobnego wykresu dla tych procesorów.
PPS: oto Pełny kod. Wykorzystuje TBB Tick_Count dla wyższych rozdzielczości czas, który można wyłączyć, nie definiując makra TBB_TIMING:
#include <iostream>
#include <iomanip>
#include <cmath>
#include <string>
//#define TBB_TIMING
#ifdef TBB_TIMING
#include <tbb/tick_count.h>
using tbb::tick_count;
#else
#include <time.h>
#endif
using namespace std;
//#define preallocate_memory new_cont
enum { new_cont, new_sep };
double *a1, *b1, *c1, *d1;
void allo(int cont, int n)
{
switch(cont) {
case new_cont:
a1 = new double[n*4];
b1 = a1 + n;
c1 = b1 + n;
d1 = c1 + n;
break;
case new_sep:
a1 = new double[n];
b1 = new double[n];
c1 = new double[n];
d1 = new double[n];
break;
}
for (int i = 0; i < n; i++) {
a1[i] = 1.0;
d1[i] = 1.0;
c1[i] = 1.0;
b1[i] = 1.0;
}
}
void ff(int cont)
{
switch(cont){
case new_sep:
delete[] b1;
delete[] c1;
delete[] d1;
case new_cont:
delete[] a1;
}
}
double plain(int n, int m, int cont, int loops)
{
#ifndef preallocate_memory
allo(cont,n);
#endif
#ifdef TBB_TIMING
tick_count t0 = tick_count::now();
#else
clock_t start = clock();
#endif
if (loops == 1) {
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++){
a1[j] += b1[j];
c1[j] += d1[j];
}
}
} else {
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
a1[j] += b1[j];
}
for (int j = 0; j < n; j++) {
c1[j] += d1[j];
}
}
}
double ret;
#ifdef TBB_TIMING
tick_count t1 = tick_count::now();
ret = 2.0*double(n)*double(m)/(t1-t0).seconds();
#else
clock_t end = clock();
ret = 2.0*double(n)*double(m)/(double)(end - start) *double(CLOCKS_PER_SEC);
#endif
#ifndef preallocate_memory
ff(cont);
#endif
return ret;
}
void main()
{
freopen("C:\\test.csv", "w", stdout);
char *s = " ";
string na[2] ={"new_cont", "new_sep"};
cout << "n";
for (int j = 0; j < 2; j++)
for (int i = 1; i <= 2; i++)
#ifdef preallocate_memory
cout << s << i << "_loops_" << na[preallocate_memory];
#else
cout << s << i << "_loops_" << na[j];
#endif
cout << endl;
long long nmax = 1000000;
#ifdef preallocate_memory
allo(preallocate_memory, nmax);
#endif
for (long long n = 1L; n < nmax; n = max(n+1, long long(n*1.2)))
{
const long long m = 10000000/n;
cout << n;
for (int j = 0; j < 2; j++)
for (int i = 1; i <= 2; i++)
cout << s << plain(n, m, j, i);
cout << endl;
}
}
(pokazuje FLOP/S dla różnych wartości n.)
10 answers
Po dalszej analizie tego, uważam, że jest to (przynajmniej częściowo) spowodowane wyrównaniem danych czterech wskaźników. Spowoduje to pewien poziom konfliktów banku pamięci podręcznej/drogi.
Jeśli dobrze zgadłem, jak przydzielasz swoje tablice, to mogą być wyrównane do linii strony.
Oznacza to, że wszystkie dostępy w każdej pętli spadną na ten sam sposób pamięci podręcznej. Jednak procesory Intela od jakiegoś czasu mają 8-drożną pamięć podręczną L1. Ale w rzeczywistość, spektakl nie jest do końca jednolity. Dostęp do 4-ways jest nadal wolniejszy niż powiedzmy 2-ways.
EDIT: faktycznie wygląda na to, że przydzielasz wszystkie tablice osobno. Zwykle, gdy wymagane są tak duże alokacje, alokator zażąda świeżych stron z systemu operacyjnego. Dlatego istnieje duża szansa, że duże przydziały pojawią się w tym samym offsecie od granicy strony.
Oto kod testu:
int main(){
const int n = 100000;
#ifdef ALLOCATE_SEPERATE
double *a1 = (double*)malloc(n * sizeof(double));
double *b1 = (double*)malloc(n * sizeof(double));
double *c1 = (double*)malloc(n * sizeof(double));
double *d1 = (double*)malloc(n * sizeof(double));
#else
double *a1 = (double*)malloc(n * sizeof(double) * 4);
double *b1 = a1 + n;
double *c1 = b1 + n;
double *d1 = c1 + n;
#endif
// Zero the data to prevent any chance of denormals.
memset(a1,0,n * sizeof(double));
memset(b1,0,n * sizeof(double));
memset(c1,0,n * sizeof(double));
memset(d1,0,n * sizeof(double));
// Print the addresses
cout << a1 << endl;
cout << b1 << endl;
cout << c1 << endl;
cout << d1 << endl;
clock_t start = clock();
int c = 0;
while (c++ < 10000){
#if ONE_LOOP
for(int j=0;j<n;j++){
a1[j] += b1[j];
c1[j] += d1[j];
}
#else
for(int j=0;j<n;j++){
a1[j] += b1[j];
}
for(int j=0;j<n;j++){
c1[j] += d1[j];
}
#endif
}
clock_t end = clock();
cout << "seconds = " << (double)(end - start) / CLOCKS_PER_SEC << endl;
system("pause");
return 0;
}
Benchmark Wyniki:
EDIT: Results on an actual Core 2 architecture machine:
2 x Intel Xeon X5482 Harpertown @ 3.2 GHz:
#define ALLOCATE_SEPERATE
#define ONE_LOOP
00600020
006D0020
007A0020
00870020
seconds = 6.206
#define ALLOCATE_SEPERATE
//#define ONE_LOOP
005E0020
006B0020
00780020
00850020
seconds = 2.116
//#define ALLOCATE_SEPERATE
#define ONE_LOOP
00570020
00633520
006F6A20
007B9F20
seconds = 1.894
//#define ALLOCATE_SEPERATE
//#define ONE_LOOP
008C0020
00983520
00A46A20
00B09F20
seconds = 1.993
Uwagi:
6.206 sekund {[8] } z jedną pętlą i 2.116 sekund z dwiema pętlami. To dokładnie odtwarza wyniki operacji.
W pierwszych dwóch testach tablice są przydzielane oddzielnie. zauważysz, że wszystkie mają takie samo wyrównanie względem strona.
W dwóch kolejnych testach tablice są pakowane razem, aby przełamać to wyrównanie. tutaj zauważysz, że obie pętle są szybsze. Co więcej, druga (podwójna) pętla jest teraz wolniejsza, jak normalnie można się spodziewać.
Jak podkreśla @ Stephen Cannon w komentarzach, istnieje bardzo prawdopodobne prawdopodobieństwo, że to wyrównanie powoduje fałszywe aliasing w jednostkach load/store lub cache. Wyszukałem to w Googlach i znalazłem, że Intel faktycznie ma licznik sprzętowy dla częściowe aliasowanie adresów boksy:
5 Regionów-Objaśnienia
Region 1:
To proste. Zbiór danych jest tak mały, że wydajność jest zdominowana przez napowietrzne, takie jak zapętlanie i rozgałęzianie.Region 2:
tutaj, wraz ze wzrostem rozmiarów danych, Ilość względnego obciążenia spada, a wydajność "nasyca się". Tutaj dwie pętle są wolniejsze, ponieważ mają dwa razy więcej pętli i rozgałęzień nad głową.
Region 3:
W tym momencie DANE nie mieszczą się już w pamięci podręcznej L1. Tak więc wydajność jest ograniczona przepustowością pamięci podręcznej L1 L2.
Region 4:
Spadek wydajności w pojedynczej pętli jest tym, co obserwujemy. I jak wspomniano, wynika to z wyrównania, które (najprawdopodobniej) powoduje fałszywe aliasing stragany w jednostkach obciążenia procesora/magazynu.
Jednak, aby doszło do fałszywego aliasingu, musi być wystarczająco duży krok między zbiory danych. Dlatego nie widzisz tego w regionie 3.
Region 5:
W tym momencie nic nie mieści się w pamięci podręcznej. Więc jesteś związany przepustowością pamięci.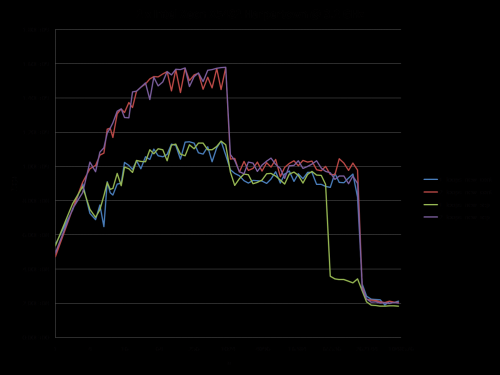
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-04-05 19:42:18
Ok, właściwa odpowiedź zdecydowanie musi coś zrobić z cache CPU. Ale użycie argumentu cache może być dość trudne, zwłaszcza bez danych.
Istnieje wiele odpowiedzi, które doprowadziły do wielu dyskusji, ale spójrzmy prawdzie w oczy: problemy z pamięcią podręczną mogą być bardzo złożone i nie są jednowymiarowe. Zależą one w dużej mierze od wielkości danych, więc moje pytanie było niesprawiedliwe: okazało się, że jest to bardzo interesujący punkt na wykresie pamięci podręcznej.
@Mysticial ' s answer przekonało wielu ludzi (w tym mnie), prawdopodobnie dlatego, że tylko on zdawał się opierać na faktach, ale był to tylko jeden "punkt danych" prawdy.
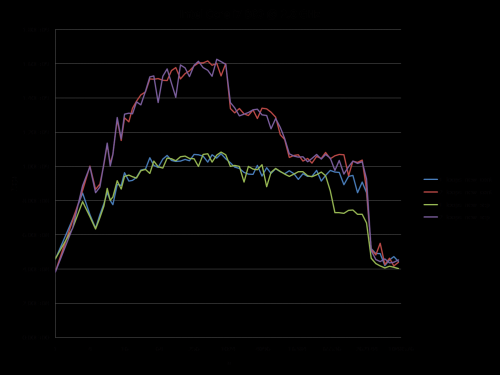
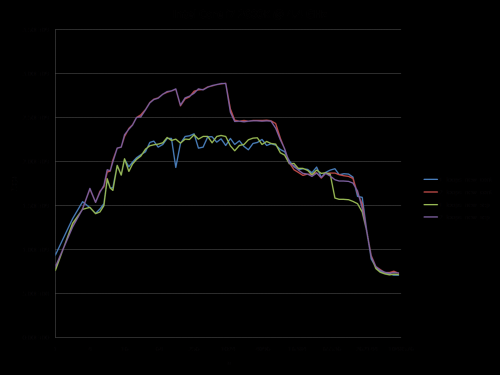
Dlatego połączyłem jego test (stosując ciągłą vs. oddzielną alokację) i Radę odpowiedzi @ James.
Poniższe wykresy pokazują, że większość odpowiedzi, a zwłaszcza większość komentarzy do pytania i odpowiedzi można uznać za całkowicie błędne lub prawdziwe w zależności od dokładnego scenariusza i parametrów użytych.
Zauważ, że moje pierwsze pytanie brzmiało: n = 100.000. Punkt ten (przez przypadek) wykazuje szczególne zachowanie:
-
Posiada największą rozbieżność między jedną i dwiema wersjami pętli (prawie współczynnik trzech)
Jest to jedyny punkt, w którym jedno-pętla (czyli z ciągłym alokacją) bije wersję dwu-pętlową. (Dzięki temu odpowiedź Mysticiala była w ogóle możliwa.)
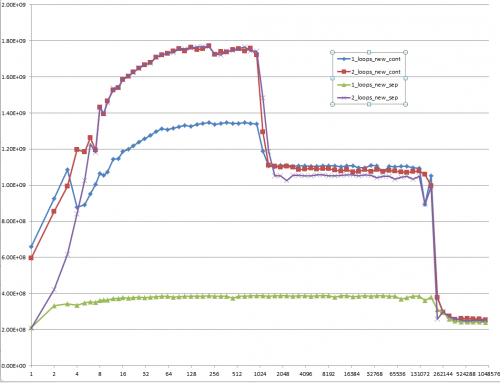
Wynik przy użyciu zainicjalizowanych danych:
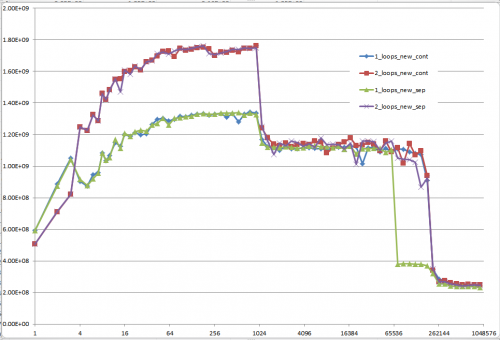
The wynik przy użyciu niezainicjalizowanych danych (to właśnie Mysticial testował):
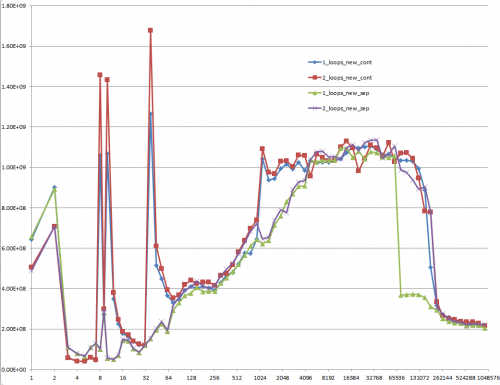
I jest to trudne do wyjaśnienia: dane inicjalizowane, które są przydzielane raz i ponownie używane dla każdego następnego przypadku testowego o różnej wielkości wektora:
Propozycja
Każde pytanie związane z wydajnością niskiego poziomu dotyczące przepełnienia stosu powinno być wymagane do dostarczenia informacji MFLOPS dla całego zakresu wielkości danych istotnych dla pamięci podręcznej! To strata czasu na myślenie odpowiedzi, a zwłaszcza omów je z innymi bez tych informacji.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-09-22 17:12:11
Druga pętla wiąże się z dużo mniejszą aktywnością pamięci podręcznej, więc łatwiej jest procesorowi nadążyć za wymaganiami dotyczącymi pamięci.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-12-17 20:47:55
Wyobraź sobie, że pracujesz na maszynie, na której n była odpowiednia wartość, aby możliwe było tylko trzymanie dwóch macierzy w pamięci jednocześnie, ale całkowita dostępna pamięć, poprzez buforowanie dysku, była nadal wystarczająca do przechowywania wszystkich czterech.
for(int j=0;j<n;j++){
a[j] += b[j];
}
for(int j=0;j<n;j++){
c[j] += d[j];
}
Spowoduje, że a i b zostaną załadowane do pamięci RAM, a następnie będą pracować w całości w pamięci RAM. Po uruchomieniu drugiej pętli, c i d zostaną załadowane z dysk do pamięci RAM i działa na.
Druga pętla
for(int j=0;j<n;j++){
a[j] += b[j];
c[j] += d[j];
}
Wyświetli dwie tablice i stronę w dwóch pozostałych za każdym razem wokół pętli. Oczywiście byłoby to znacznie wolniejsze.
Prawdopodobnie nie widzisz buforowania dysku w swoich testach, ale prawdopodobnie widzisz skutki uboczne innej formy buforowania.
Wydaje się, że jest tu trochę zamieszania/nieporozumienia, więc postaram się rozwinąć trochę używając przykład.
Powiedzmy n = 2 i pracujemy z bajtami. W moim scenariuszu mamy więc tylko 4 bajty pamięci RAM, a reszta naszej pamięci jest znacznie wolniejsza (powiedzmy 100 razy dłuższy dostęp).
Zakładając dość głupią politykę buforowania jeśli bajt nie znajduje się w buforze, umieść go tam i uzyskaj następujący bajt, gdy jesteśmy przy nim otrzymasz scenariusz podobny do tego: {36]}
-
Z
for(int j=0;j<n;j++){ a[j] += b[j]; } for(int j=0;j<n;j++){ c[j] += d[j]; } Cache
a[0]oraza[1]następnieb[0]ib[1]i ustawa[0] = a[0] + b[0]w buforze - są teraz cztery bajty w buforze,a[0], a[1]ib[0], b[1]. Koszt = 100 + 100.- Ustaw
a[1] = a[1] + b[1]w pamięci podręcznej. Koszt = 1 + 1. - powtórz dla
cid. Koszt całkowity=
(100 + 100 + 1 + 1) * 2 = 404-
Z
for(int j=0;j<n;j++){ a[j] += b[j]; c[j] += d[j]; } Cache
a[0]ia[1]następnieb[0]ib[1]i ustawa[0] = a[0] + b[0]W cache - są teraz cztery bajty w cache,a[0], a[1]ib[0], b[1]. Koszt = 100 + 100.- wysuń
a[0], a[1], b[0], b[1]z cache i cachec[0]ic[1]następnied[0]id[1]i ustawc[0] = c[0] + d[0]W cache. Koszt = 100 + 100. - podejrzewam, że zaczynasz widzieć, dokąd zmierzam.
- całkowity koszt =
(100 + 100 + 100 + 100) * 2 = 800
To klasyczny scenariusz cache thrash.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-10-03 11:12:55
To nie z powodu innego kodu, ale z powodu buforowania: RAM jest wolniejszy niż rejestry procesora, a pamięć podręczna znajduje się wewnątrz procesora, aby uniknąć zapisywania pamięci RAM za każdym razem, gdy zmienna się zmienia. Ale pamięć podręczna nie jest duża jak pamięć RAM, dlatego mapuje tylko ułamek.
Pierwszy kod modyfikuje odległe adresy pamięci na przemian w każdej pętli, co wymaga ciągłego unieważniania pamięci podręcznej.
Drugi kod nie zmienia się: po prostu płynie po sąsiednich adresy dwa razy. Powoduje to, że całe zadanie ma zostać wykonane w pamięci podręcznej, unieważniając je dopiero po uruchomieniu drugiej pętli.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-12-17 20:49:03
Nie mogę replikować omawianych tutaj wyników.
Nie wiem, czy winny jest zły kod benchmarkowy, CZY Co, ale dwie metody są w 10% od siebie na mojej maszynie, używając poniższego kodu, a jedna pętla jest zwykle nieco szybsza niż dwie - jak można się spodziewać.
Rozmiary tablic wahały się od 2^16 do 2^24, używając ośmiu pętli. Byłem ostrożny, aby zainicjować tablice źródłowe, więc przypisanie += nie wymagało FPU , aby dodać śmieci pamięci interpretowane jako podwójne.
Bawiłem się różnymi schematami, np. stawiając Zadanie b[j], d[j] do InitToZero[j] wewnątrz pętli, a także z użyciem += b[j] = 1 i += d[j] = 1, i otrzymałem dość spójne wyniki.
Jak można się było spodziewać, inicjalizacja b i d wewnątrz pętli za pomocą InitToZero[j] dała połączonemu podejściu przewagę, ponieważ były one wykonywane back-to-back przed przypisaniami do a i c, ale nadal w granicach 10%. Pomyśl.
Sprzęt jest [[28]} Dell XPS 8500 z Generacją 3 Core i7 @ 3,4 GHz i 8 GB pamięci. Dla 2^16 do 2^24, przy użyciu ośmiu pętli, łączny czas wynosił odpowiednio 44,987 i 40,965. Visual C++ 2010, w pełni zoptymalizowany.
PS: zmieniłem pętle, aby odliczać do zera, a metoda łączona była nieznacznie szybsza. Drapanie się po głowie. Zwróć uwagę na nowy rozmiar tablicy i liczbę pętli.
// MemBufferMystery.cpp : Defines the entry point for the console application.
//
#include "stdafx.h"
#include <iostream>
#include <cmath>
#include <string>
#include <time.h>
#define dbl double
#define MAX_ARRAY_SZ 262145 //16777216 // AKA (2^24)
#define STEP_SZ 1024 // 65536 // AKA (2^16)
int _tmain(int argc, _TCHAR* argv[]) {
long i, j, ArraySz = 0, LoopKnt = 1024;
time_t start, Cumulative_Combined = 0, Cumulative_Separate = 0;
dbl *a = NULL, *b = NULL, *c = NULL, *d = NULL, *InitToOnes = NULL;
a = (dbl *)calloc( MAX_ARRAY_SZ, sizeof(dbl));
b = (dbl *)calloc( MAX_ARRAY_SZ, sizeof(dbl));
c = (dbl *)calloc( MAX_ARRAY_SZ, sizeof(dbl));
d = (dbl *)calloc( MAX_ARRAY_SZ, sizeof(dbl));
InitToOnes = (dbl *)calloc( MAX_ARRAY_SZ, sizeof(dbl));
// Initialize array to 1.0 second.
for(j = 0; j< MAX_ARRAY_SZ; j++) {
InitToOnes[j] = 1.0;
}
// Increase size of arrays and time
for(ArraySz = STEP_SZ; ArraySz<MAX_ARRAY_SZ; ArraySz += STEP_SZ) {
a = (dbl *)realloc(a, ArraySz * sizeof(dbl));
b = (dbl *)realloc(b, ArraySz * sizeof(dbl));
c = (dbl *)realloc(c, ArraySz * sizeof(dbl));
d = (dbl *)realloc(d, ArraySz * sizeof(dbl));
// Outside the timing loop, initialize
// b and d arrays to 1.0 sec for consistent += performance.
memcpy((void *)b, (void *)InitToOnes, ArraySz * sizeof(dbl));
memcpy((void *)d, (void *)InitToOnes, ArraySz * sizeof(dbl));
start = clock();
for(i = LoopKnt; i; i--) {
for(j = ArraySz; j; j--) {
a[j] += b[j];
c[j] += d[j];
}
}
Cumulative_Combined += (clock()-start);
printf("\n %6i miliseconds for combined array sizes %i and %i loops",
(int)(clock()-start), ArraySz, LoopKnt);
start = clock();
for(i = LoopKnt; i; i--) {
for(j = ArraySz; j; j--) {
a[j] += b[j];
}
for(j = ArraySz; j; j--) {
c[j] += d[j];
}
}
Cumulative_Separate += (clock()-start);
printf("\n %6i miliseconds for separate array sizes %i and %i loops \n",
(int)(clock()-start), ArraySz, LoopKnt);
}
printf("\n Cumulative combined array processing took %10.3f seconds",
(dbl)(Cumulative_Combined/(dbl)CLOCKS_PER_SEC));
printf("\n Cumulative seperate array processing took %10.3f seconds",
(dbl)(Cumulative_Separate/(dbl)CLOCKS_PER_SEC));
getchar();
free(a); free(b); free(c); free(d); free(InitToOnes);
return 0;
}
Nie jestem pewien, dlaczego zdecydowano, że MFLOPS jest odpowiednią metryką. Myślałem, że pomysł był aby skupić się na dostępie do pamięci, więc starałem się zminimalizować ilość czasu obliczeń zmiennoprzecinkowych. Wyszedłem w +=, ale nie jestem pewien dlaczego.
Proste przypisanie bez obliczeń byłoby czystszym testem czasu dostępu do pamięci i stworzyłoby test, który jest jednolity niezależnie od liczby pętli. Może coś przeoczyłem w rozmowie, ale warto pomyśleć dwa razy. Jeśli plus zostanie pominięty w przypisaniu, łączny czas jest prawie identyczny w 31 sekundach każdy.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-12-16 01:55:04
To dlatego, że procesor nie ma tak wielu braków pamięci podręcznej (gdzie musi czekać na dane tablicy pochodzą z układów pamięci RAM). Byłoby interesujące dla Ciebie Ustawianie rozmiaru tablic w sposób ciągły, aby przekraczać rozmiary bufora poziomu 1 (L1), a następnie bufora poziomu 2 (L2), Twojego procesora i wykreślić czas potrzebny na wykonanie kodu względem rozmiarów tablic. Wykres nie powinien być linią prostą, jak można się spodziewać.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-02-16 09:38:15
Pierwsza pętla zmienia zapis w każdej zmiennej. Drugi i trzeci wykonują tylko małe skoki wielkości elementu.
Spróbuj napisać dwie równoległe linie 20 krzyżyków długopisem i papierem oddzielone o 20 cm. Spróbuj raz zakończyć jedną, a następnie drugą linię i spróbuj innym razem, pisząc krzyż na przemian w każdej linii.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-02-16 09:47:53
Oryginalne Pytanie
Dlaczego jedna pętla jest o wiele wolniejsza niż dwie?
Ocena Problemu
KOD PO:
const int n=100000;
for(int j=0;j<n;j++){
a1[j] += b1[j];
c1[j] += d1[j];
}
I
for(int j=0;j<n;j++){
a1[j] += b1[j];
}
for(int j=0;j<n;j++){
c1[j] += d1[j];
}
Rozważanie
Biorąc pod uwagę oryginalne pytanie OP dotyczące 2 wariantów pętli for i jego zmienione pytanie dotyczące zachowania pamięci podręcznej wraz z wieloma innymi doskonałymi odpowiedziami i przydatne komentarze; chciałbym spróbować zrobić tutaj coś innego, przyjmując inne podejście do tej sytuacji i problemu.
Podejście
Biorąc pod uwagę dwie pętle i całą dyskusję na temat cache i archiwizacji stron, chciałbym przyjąć inne podejście, aby spojrzeć na to z innej perspektywy. Takie, które nie obejmuje pamięci podręcznej i plików stron ani egzekucji przydzielania pamięci, w rzeczywistości to podejście nie dotyczy nawet faktyczny sprzęt lub oprogramowanie w ogóle.
Perspektywa
Po obejrzeniu kodu przez chwilę okazało się, na czym polega problem i co go generuje. Pozwala rozbić to na problem algorytmiczny i spojrzeć na to z perspektywy korzystania z notacji matematycznych następnie zastosować analogię do problemów matematycznych, jak również do algorytmów.
Co Wiemy
Wiemy, że jego pętla będzie działać 100,000 razy. Wiemy również, że a1, b1, c1 & d1 są wskaźnikami na architekturze 64-bitowej. W C++ na maszynie 32-bitowej wszystkie wskaźniki mają 4 bajty, a na maszynie 64-bitowej mają 8 bajtów, ponieważ wskaźniki mają stałą długość. Wiemy, że w obu przypadkach mamy 32 bajty do przydzielenia. Jedyną różnicą jest to, że przydzielamy 32 bajty lub 2 zestawy po 2-8bajtów na każdą iterację, gdzie w drugim przypadku przydzielamy 16 bajtów na każdą iterację dla obu niezależnych pętli. Więc obie pętle nadal są równe 32 bajty w całkowitej alokacji. Dzięki tej informacji pokażmy ogólną matematykę, algorytm i analogię. Wiemy, ile razy ten sam zestaw lub grupa operacji będzie musiała być wykonana w obu przypadkach. Znamy ilość pamięci, którą należy przydzielić w obu przypadkach. Możemy ocenić, że całkowite obciążenie pracą przydziałów między obydwoma przypadkami będzie wynosić około to samo.
Czego nie wiemy
Nie wiemy, jak długo to zajmie dla każdego przypadku, chyba że ustawimy licznik i przeprowadzimy test na stanowisku. Jednak znaki ławki zostały już uwzględnione z pierwotnego pytania i z niektórych odpowiedzi i komentarzy, jak również i możemy zobaczyć znaczącą różnicę między tymi dwoma i to jest całe rozumowanie tego pytania do tego problemu i do odpowiedzi na to, aby rozpocząć z.
Zbadajmy
Jest już oczywiste, że wielu już to zrobiło, patrząc na alokacje sterty, testy bench mark, patrząc na pamięć RAM, pamięć podręczną i pliki stron. Uwzględniono również konkretne punkty danych i konkretne indeksy iteracji, a różne rozmowy na temat tego konkretnego problemu sprawiły, że wiele osób zaczęło kwestionować inne powiązane rzeczy na ten temat. Jak więc zacząć patrzeć na ten problem używając matematycznych algorytmy i zastosowanie do nich analogii? Zaczynamy od kilku twierdzeń! Potem zbudujemy nasz algorytm.
Nasze Twierdzenia:
- niech nasza pętla i jej iteracje będą podsumowaniem, które zaczyna się od 1 i kończy się na 100000 zamiast zaczynać się od 0, ponieważ nie musimy martwić się o schemat indeksowania 0 adresowania pamięci, ponieważ jesteśmy po prostu zainteresowani samym algorytmem.
- w obu przypadki mamy 4 funkcje do pracy i 2 wywołania funkcji z 2 operacjami wykonywanymi na każdym wywołaniu funkcji. Więc ustawimy je jako funkcje i wywołania funkcji, aby były
F1(),F2(),f(a),f(b),f(c)if(d).
Algorytmy:
Pierwszy przypadek: - tylko jedno podsumowanie, ale dwa niezależne wywołania funkcji.
Sum n=1 : [1,100000] = F1(), F2();
F1() = { f(a) = f(a) + f(b); }
F2() = { f(c) = f(c) + f(d); }
2. przypadek: - dwa podsumowania, ale każda ma swoją funkcję sprawdzam.
Sum1 n=1 : [1,100000] = F1();
F1() = { f(a) = f(a) + f(b); }
Sum2 n=1 : [1,100000] = F1();
F1() = { f(c) = f(c) + f(d); }
Jeśli zauważyłeś F2() istnieje tylko w Sum gdzie zarówno Sum1, jak i Sum2 zawiera tylko F1(). Będzie to również widoczne później, jak również, gdy zaczniemy wnioskować, że istnieje rodzaj optymalizacji dzieje się z drugiego algorytmu.
Iteracje przez pierwszy przypadek Sum wywołują f(a), które dodają do siebie f(b), a następnie wywołują f(c), które zrobią to samo, ale dodają f(d) do siebie dla każdego 100000 iterations. W drugim przypadku mamy Sum1 i Sum2 i obie działają tak samo, jakby były tą samą funkcją wywoływaną dwa razy z rzędu.
W tym przypadku możemy traktować Sum1 i Sum2 jako zwykłe stare Sum gdzie Sum w tym przypadku wygląda tak: Sum n=1 : [1,100000] { f(a) = f(a) + f(b); } a teraz wygląda to jak optymalizacja, gdzie możemy po prostu uznać, że jest to ta sama funkcja.
Podsumowanie z analogią
Z tym, co widzieliśmy w drugim przypadku, wygląda to prawie tak, jakby była optymalizacja, ponieważ obie pętle for mają takie same dokładny podpis, ale to nie jest prawdziwy problem. Problemem nie jest praca wykonywana przez f(a),f(b),f(c)&f(d) w obu przypadkach i porównanie między nimi różnica w odległości, jaką suma musi pokonać w obu przypadkach daje różnicę w czasie wykonania.
Pomyśl o {[38] } jako o Summations, który wykonuje iteracje jako o Boss, który wydaje rozkazy dwóm ludziom A & B i że ich praca jest do mięsa C & D odpowiednio i odebrać od nich jakąś paczkę i zwrócić ją. W tej analogii iteracje pętli for lub sumowania i Sprawdzanie warunków nie reprezentują Boss. To, co w rzeczywistości reprezentuje Boss, nie pochodzi bezpośrednio z rzeczywistych algorytmów matematycznych, ale z rzeczywistego pojęcia Scope i Code Block W ramach rutynowej lub podprogramu, metody, funkcji, jednostki translacji itp. Pierwszy algorytm ma 1 Zakres, gdzie drugi algorytm ma 2 kolejne lunety.
W pierwszym przypadku na każdym wywołaniu slip Boss przechodzi do A i wydaje rozkaz, a A przechodzi do fetch B's, a Boss przechodzi do C i wydaje rozkazy, aby zrobić to samo i otrzymać pakiet z D na każdej iteracji.
W drugim przypadku Boss działa bezpośrednio z A, aby przejść i pobrać B's pakiet, dopóki wszystkie pakiety nie zostaną odebrane. Następnie Boss Działa z C, aby zrobić to samo, aby uzyskać wszystkie D's paczki.
Ponieważ pracujemy ze wskaźnikiem 8 bajtów i zajmujemy się alokacją sterty, rozważmy ten problem tutaj. Powiedzmy, że Boss jest 100 stóp od A, A {[41] } jest 500 stóp od C. Nie musimy się martwić o to, jak daleko Boss jest początkowo od C ze względu na kolejność egzekucji. W obu przypadkach Boss początkowo podróżuje z A najpierw do B. Ta analogia nie oznacza, że odległość ta jest dokładna; jest to tylko przypadek testu użycia scenariusz pokazujący działanie algorytmów. W wielu przypadkach podczas alokacji sterty i pracy z plikami pamięci podręcznej i plikami stron odległości między lokalizacjami adresów mogą nie różnić się tak bardzo lub mogą być bardzo znaczące w zależności od charakteru typów danych i rozmiarów tablic.
Przypadki Testowe:
pierwsza sprawa: na pierwszej iteracji Boss musi początkowo przejść 100 stóp, aby dać poślizg zamówienia do A i A idzie i robi swoje, ale wtedy Boss musi przebyć 500 stóp do C, aby dać mu zamówienie. Następnie w następnej iteracji i każdej kolejnej iteracji po {[40] } musi iść tam iz powrotem 500 stóp między nimi.
druga sprawa: The Boss musi przejść 100 stóp na pierwszej iteracji do A, ale po tym jest już tam i czeka na A, aby wrócić, dopóki wszystkie poślizgi nie zostaną wypełnione. Wtedy Boss musi podróż 500 stóp na pierwszej iteracji do C ponieważ C jest 500 stóp od A ponieważ to {84]} jest wywoływane zaraz po pracy z A, a następnie czeka tak jak on z {41]} aż wszystkie {87]} zamówienia zostaną wykonane.
Różnica W Przebytych Odległościach
const n = 100000
distTraveledOfFirst = (100 + 500) + ((n-1)*(500 + 500);
// Simplify
distTraveledOfFirst = 600 + (99999*100);
distTraveledOfFirst = 600 + 9999900;
distTraveledOfFirst = 10000500;
// Distance Traveled On First Algorithm = 10,000,500ft
distTraveledOfSecond = 100 + 500 = 600;
// Distance Traveled On Second Algorithm = 600ft;
Porównanie dowolnych wartości
Możemy łatwo zobaczyć, że 600 to znacznie mniej niż 10 milionów. Teraz to nie jest dokładne, ponieważ my nie znam rzeczywistej różnicy w odległości między jaki adres pamięci RAM lub z jakiego pliku pamięci podręcznej lub strony każde wywołanie każdej iteracji będzie spowodowane wieloma innymi niewidzialnymi zmiennymi, ale jest to Tylko ocena sytuacji, której należy być świadomym i próbować spojrzeć na nią z najgorszego scenariusza.
Więc według tych liczb prawie wyglądałoby to tak, jakby algorytm pierwszy był 99% wolniejszy od algorytmu drugiego; jednak jest to tylko część lub odpowiedzialność algorytmów i to nie uwzględnia rzeczywistych pracowników A, B, C, & D i co muszą zrobić na każdej iteracji pętli. Tak więc praca szefów stanowi tylko około 15 - 40% całkowitej wykonanej pracy. W związku z tym większość pracy wykonywanej przez pracowników ma nieco większy wpływ na utrzymanie stosunku różnic prędkości do około 50-70% [135]}
Obserwacja: - różnice między tymi dwoma algorytmy
W tej sytuacji jest to struktura procesu wykonywanej pracy i pokazuje, że Przypadek 2 jest bardziej efektywny zarówno od częściowej optymalizacji posiadania podobnej deklaracji funkcji, jak i definicji, gdzie tylko zmienne różnią się nazwami. Widzimy również, że całkowita odległość przebyta w Przypadku 1 jest znacznie większa niż w przypadku 2 i możemy uznać tę odległość przebytą za naszą Współczynnik czasu pomiędzy dwoma algorytmami. Przypadek 1 ma znacznie więcej pracy niż Przypadek 2 . Było to również widoczne w dowodach ASM, które pokazano między obydwoma przypadkami. Nawet z tym, co zostało już powiedziane o tych sprawach, nie wyjaśnia to również faktu, że w sprawie 1 szef będzie musiał poczekać na oba A & C aby wrócić, zanim będzie mógł wrócić do A ponownie na następnej iteracji i to również nie uwzględnia fakt, że jeśli A lub B zajmuje bardzo dużo czasu, to zarówno Boss, jak i inni pracownicy również czekają bezczynnie. W przypadku 2 jedynym bezczynnym jest Boss dopóki pracownik nie wróci. Więc nawet to ma wpływ na algorytm.
Wniosek:
Przypadek 1 jest klasycznym problemem interpolacji, który okazuje się być nieefektywny. Myślę też, że był to jeden z głównych powodów, dla których wiele architektur maszyn i programistów skończyło na budowaniu i projektowaniu systemów wielordzeniowych z możliwością wykonywania aplikacji wielowątkowych, a także programowania równoległego.
Więc nawet patrząc na to z tego podejścia, nawet nie angażując w to, jak sprzęt, system operacyjny i kompilator współpracują ze sobą, aby zrobić alokację sterty, która obejmuje pracę z RAM, Cache, pliki stron, itp.; stojąca za nią matematyka pokazuje nam już, które z tych dwóch rozwiązań jest lepszym rozwiązaniem z zastosowania powyższej analogii gdzie Boss lub Summations są te For Loops, które musiały podróżować między pracownikami A & B. Możemy łatwo zauważyć, że Przypadek 2 jest co najmniej w 1/2 tak szybki, jeśli nie trochę więcej niż Przypadek 1 ze względu na różnicę w odległej podróży i czasie. I ta matematyka wyrównuje się prawie praktycznie i doskonale zarówno z czasów znakowania ławki, jak i ilości różnicy w ilości instrukcji montażu.
Na Ops zmienione pytania
EDIT: pytanie okazało się bez znaczenia, ponieważ zachowanie zależy od rozmiarów tablic (n) i pamięci podręcznej procesora. Tak więc, jeśli jest dalsze zainteresowanie, przeformułuję pytanie:
Czy mógłbyś zapewnić solidny wgląd w szczegóły, które prowadzą do różnych zachowań pamięci podręcznej, jak zilustrowane przez pięć regionów na następujących Wykres?
Interesujące może być również zwrócenie uwagi na różnice między architekturami CPU/cache, poprzez dostarczenie podobnego wykresu dla tych procesorów.
W Związku Z Tymi Pytaniami
Jak wykazałem bez wątpienia, istnieje podstawowy problem, nawet zanim sprzęt i oprogramowanie zostaną zaangażowane. Teraz co do zarządzania pamięcią i buforowaniem wraz z plikami stron itp. który działa razem w zintegrowanym zestawie systemów pomiędzy: The Architecture {Sprzęt, Firmware, niektóre wbudowane sterowniki, jądra i zestawy instrukcji ASM}, The OS {Systemy zarządzania plikami i pamięcią, sterowniki i rejestr}, The Compiler { jednostki tłumaczeniowe i optymalizacje kodu źródłowego}, a nawet Source Code z jego zestawem (- ami) charakterystycznych algorytmów; widzimy już, że jest wąskie gardło, które dzieje się w ramach pierwszego algorytmu, zanim nawet zastosujemy go do dowolnego komputera. z dowolnymi dowolnymi Architecture, OS, i Programmable Language w porównaniu do drugiego algorytmu. Tak więc istniał już problem przed włączeniem wewnętrznych cech współczesnego komputera.
Wyniki Końcowe
[132]}nie można jednak powiedzieć, że te nowe pytania nie są ważne, ponieważ same w sobie są i w końcu odgrywają pewną rolę. Mają one wpływ na procedury i ogólną wydajność, co jest widoczne w różnych wykresach i ocenach od wielu, którzy udzielili odpowiedzi lub komentarzy. Jeśli zwrócisz uwagę na analogięBoss i dwóch pracowników A & B który musiał iść i odebrać paczki z C & D odpowiednio i biorąc pod uwagę notacje matematyczne dwóch algorytmów, o których mowa, widać, że nawet bez udziału komputera Case 2 jest o około 60% szybszy niż Case 1 i kiedy spojrzysz na wykresy i wykresy po zastosowaniu tych algorytmów do źródła kod, skompilowany i zoptymalizowany i wykonany przez system operacyjny do wykonywania operacji na danym sprzęcie można nawet zobaczyć trochę więcej degradacji między różnicami w tych algorytmach.
Teraz, jeśli zbiór "danych" jest dość mały, może na początku nie wydawać się aż tak źle różnicą, ale ponieważ Case 1 jest o 60 - 70% wolniejszy niż Case 2, możemy spojrzeć na wzrost tej funkcji jako Na różnice w czasie wykonania:{[135]]}
DeltaTimeDifference approximately = Loop1(time) - Loop2(time)
//where
Loop1(time) = Loop2(time) + (Loop2(time)*[0.6,0.7]) // approximately
// So when we substitute this back into the difference equation we end up with
DeltaTimeDifference approximately = (Loop2(time) + (Loop2(time)*[0.6,0.7])) - Loop2(time)
// And finally we can simplify this to
DeltaTimeDifference approximately = [0.6,0.7]*(Loop2(time)
I to przybliżenie jest średnia różnica między tymi dwoma pętlami zarówno algorytmicznie, jak i operacji maszynowych obejmujących optymalizację oprogramowania i instrukcje maszynowe. Więc kiedy zbiór danych rośnie liniowo, tak samo różnica w czasie między nimi. Algorytm 1 ma więcej pobrań niż algorytm 2, co jest oczywiste, gdy {[40] } musiał podróżować tam iz powrotem maksymalną odległość między A & C dla każdej iteracji po pierwszej iteracji, podczas gdy {[40] } musiał przejść do A raz i następnie po wykonaniu A musiał przebyć maksymalną odległość tylko jeden raz, jadąc z A do C.
Więc próba skupienia się na robieniu dwóch podobnych rzeczy naraz i żonglowaniu nimi w tę i z powrotem zamiast skupiać się na podobnych kolejnych zadaniach sprawi, że będzie bardzo zły pod koniec dnia, ponieważ musiał podróżować i pracować dwa razy więcej. Dlatego nie trać zakresu sytuacji pozwalając swojemu szefowi wejść w interpolację wąskie gardło, bo małżonka i dzieci szefa nie doceniłyby tego.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-08-05 00:42:00
Mogą być stare C++ i optymalizacje. W moim komputerze uzyskałem prawie taką samą prędkość:
Jedna pętla: 1.577 ms dwie pętle: 1.507 ms
Uruchamiam VS2015 na procesorze E5-1620 3,5 Ghz z 16GB ram
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-07-11 07:00:53