Dlaczego inlining kompilatora generuje wolniejszy Kod niż inlining ręczny?
Tło
[10]}następująca pętla krytyczna kawałka oprogramowania numerycznego, napisanego w C++, zasadniczo porównuje dwa obiekty przez jednego z ich członków: [11]}for(int j=n;--j>0;)
asd[j%16]=a.e<b.e;
a i {[6] } należą do klasy ASD:
struct ASD {
float e;
...
};
Badałem efekt umieszczenia tego porównania w funkcji członu lekkiego:
bool test(const ASD& y)const {
return e<y.e;
}
I używanie go w ten sposób:
for(int j=n;--j>0;)
asd[j%16]=a.test(b);
Kompilator wprowadza tę funkcję, ale problem polega na tym, że kod złożenia będzie inny i powodują >10% nadmiarowości czasu pracy. Mam pytanie:
Pytania
Dlaczego kompilator prodrucinguje inny kod asemblera?
Dlaczego produkowany montaż jest wolniejszy?
EDIT: na drugie pytanie odpowiedziała sugestia @KamyarSouri (j%16). Kod złożenia wygląda teraz prawie identycznie (zobacz http://pastebin.com/diff.php?i=yqXedtPm ). jedyne różnice to linie 18, 33, 48:
000646F9 movzx edx,dl
Materiał
- kod testu: http://pastebin.com/03s3Kvry
- wyjście montażowe na MSVC10 z /Ox / Ob2 / Ot / arch:SSE2:
- kompilator w wersji: http://pastebin.com/yqXedtPm
- Wersja Manualna: http://pastebin.com/pYSXL77f
- różnica http://pastebin.com/diff.php?i=yqXedtPm
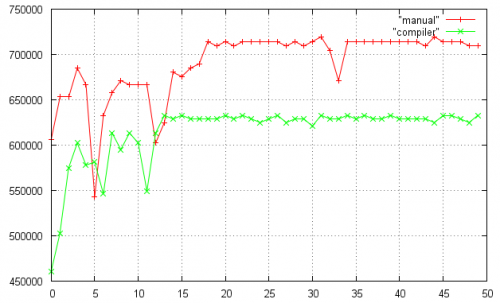
Skrypt gnuplot do generowania wykresu: http://pastebin.com/8amNqya7
Opcje Kompilatora:
/Zi /W3 /WX- /MP /Ox /Ob2 /Oi /Ot /Oy /gl /D "WIN32" /D "NDEBUG" /D "_CONSOLE" /D "_UNICODE" /D "UNICODE" /Gm- /EHsc /MT /GS- /Gy /arch:SSE2 /fp:precise /Zc:wchar_t /ZC:forScope /Gd /analyze-
Opcje Linkera: / INCREMENTAL: NO " kernel32.lib "" user32.lib "" gdi32.lib "" winspool.lib" "comdlg32lib "" advapi32.lib "" shell32.lib "" ole32.lib "" oleaut32.lib "" uuid.lib "" odbc32.lib "" odbccp32.w związku z tym, że nie jest to możliwe, nie jest to możliwe, ponieważ nie jest to możliwe, ponieważ nie jest to możliwe, ponieważ nie jest to możliwe, ponieważ nie jest to możliwe.]}
2 answers
Krótka Odpowiedź:
Twoja asd Tablica jest zadeklarowana jako:
int *asd=new int[16];
Dlatego użyj int jako typu zwracanego, a nie bool.
Alternatywnie Zmień typ tablicy na bool.
W każdym przypadku upewnij się, że typ zwracanej funkcji test odpowiada typowi tablicy.
Przejdź do dołu, aby uzyskać więcej szczegółów.
Długa Odpowiedź:
W wersji ręcznie inlined, "rdzeń" jednej iteracji wygląda jak to:
xor eax,eax
mov edx,ecx
and edx,0Fh
mov dword ptr [ebp+edx*4],eax
mov eax,dword ptr [esp+1Ch]
movss xmm0,dword ptr [eax]
movss xmm1,dword ptr [edi]
cvtps2pd xmm0,xmm0
cvtps2pd xmm1,xmm1
comisd xmm1,xmm0
Kompilator w wersji jest całkowicie identyczny z wyjątkiem pierwszej instrukcji.
Gdzie zamiast:
xor eax,eax
Ma:
xor eax,eax
movzx edx,al
Ok, więc to jest jedna dodatkowa Instrukcja. Oboje robią to samo-zerują rejestr. To jedyna różnica, jaką widzę...
Instrukcja movzx ma jednokrotne opóźnienie i obiegową przepustowość cyklu 0.33 na wszystkich nowszych architekturach. Więc nie mogę sobie wyobrazić, jak to mogło zrób 10% różnicy.
W obu przypadkach wynik zerowania jest używany tylko 3 Instrukcje później. Więc jest bardzo możliwe, że to może być na krytycznej ścieżce egzekucji.
Chociaż nie jestem inżynierem Intela, oto moje przypuszczenie:
Większość nowoczesnych procesorów zajmuje się operacjami zerowania (takimi jak xor eax,eax) poprzezzmianę nazwy rejestru NA bank rejestrów zerowych. Całkowicie omija jednostki wykonawcze. Jest jednak możliwe, że to Specjalna obsługa może spowodować powstanie bańki rurociągu, gdy dostęp do (częściowego) rejestru jest możliwy poprzez movzx edi,al.
Ponadto istnieje również false zależność odeax w kompilatorze w wersji inlined:
movzx edx,al
mov eax,ecx // False dependency on "eax".
To, czyout-of-order execution jest w stanie rozwiązać ten problem, nie mam pojęcia.
OK, to w zasadzie zmienia się w kwestię inżynierii wstecznej kompilatora MSVC...
Tutaj wyjaśnię dlaczego to dodatkowe movzx jest generowane, jak również dlaczego pozostaje.
Kluczem jest tutaj wartość zwracana bool. Najwidoczniej, bool typy danych są prawdopodobnie zapisywane jako 8-bitowe wartości wewnątrz wewnętrznej reprezentacji MSVC.
Dlatego, gdy w domyśle przekształcisz z bool na int tutaj:
asd[j%16] = a.test(b);
^^^^^^^^^ ^^^^^^^^^
type int type bool
Istnieje promocja 8-bitowa -> 32-bitowa liczba całkowita. Z tego powodu MSVC generuje instrukcję movzx.
Gdy inlining jest wykonywany ręcznie, kompilator ma wystarczająco dużo informacji, aby zoptymalizuj tę konwersję i zachowaj wszystko jako 32-bitowy typ danych IR.
Jednakże, gdy kod jest umieszczony w jego własnej funkcji z wartością zwracaną bool, kompilator nie jest w stanie zoptymalizować 8-bitowego pośredniego typu danych. Dlatego movzx zostaje.
Gdy oba typy danych są takie same (int lub bool), konwersja nie jest potrzebna. W związku z tym problem jest całkowicie unikany.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-12-21 03:39:33
lea esp,[esp] zajmuje 7 bajtów i-cache i znajduje się wewnątrz pętli. Kilka innych wskazówek sprawia, że wygląda na to, że kompilator nie jest pewien, czy jest to kompilacja release czy debug.
Edit:
lea esp,[esp] nie jest w pętli. Pozycja wśród otaczających mnie instrukcji wprowadzała mnie w błąd. Teraz wygląda na to, że celowo zmarnował 7 bajtów, a następnie kolejne zmarnowane 2 bajty, aby rozpocząć rzeczywistą pętlę na granicy 16 bajtów. Co oznacza, że to faktycznie przyspiesza, jak widać Autor: Johennes Gerer
Kompilator nadal wydaje się być niepewny, czy jest to kompilacja debugowa czy release.
Kolejna edycja:
Pastebin diff różni się od Pastebin diff, które widziałem wcześniej. Ta odpowiedź może być teraz usunięta, ale ma już komentarze, więc ją zostawię.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-12-21 02:12:40