Python nie ma pamięci na dużym pliku CSV (numpy)
Mam plik CSV o pojemności 3GB, który próbuję odczytać Pythonem.
from numpy import *
def data():
return genfromtxt('All.csv',delimiter=',')
data = data() # This is where it fails already.
med = zeros(len(data[0]))
data = data.T
for i in xrange(len(data)):
m = median(data[i])
med[i] = 1.0/float(m)
print med
Błąd, który dostaję jest taki:
Python(1545) malloc: *** mmap(size=16777216) failed (error code=12)
*** error: can't allocate region
*** set a breakpoint in malloc_error_break to debug
Traceback (most recent call last):
File "Normalize.py", line 40, in <module>
data = data()
File "Normalize.py", line 39, in data
return genfromtxt('All.csv',delimiter=',')
File "/Library/Frameworks/Python.framework/Versions/2.6/lib/python2.6/site-
packages/numpy/lib/npyio.py", line 1495, in genfromtxt
for (i, line) in enumerate(itertools.chain([first_line, ], fhd)):
MemoryError
Dzięki
EDIT: próbowałem z tym, ale bez powodzenia...
genfromtxt('All.csv',delimiter=',', dtype=float16)
3 answers
Jak już inni ludzie wspominali, dla naprawdę dużego pliku, lepiej iterację.
Jednak z różnych powodów chcesz, aby cała rzecz została zapamiętana.
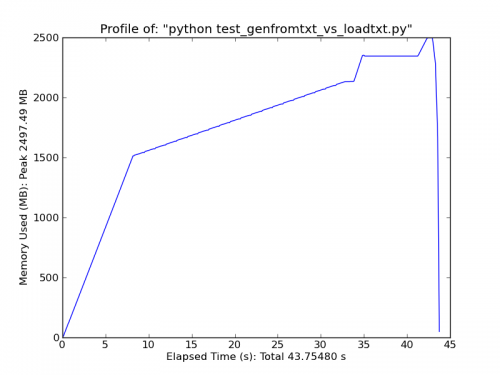
genfromtxt jest znacznie mniej wydajny niż loadtxt (chociaż obsługuje brakujące dane, podczas gdy loadtxt jest bardziej "szczupły i średni", dlatego obie funkcje współistnieją).
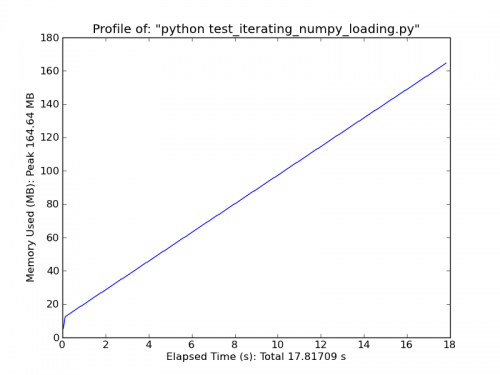
Jeśli Twoje dane są bardzo regularne (np. proste rozdzielane wiersze tego samego typu), Możesz również poprawić je za pomocą numpy.fromiter.
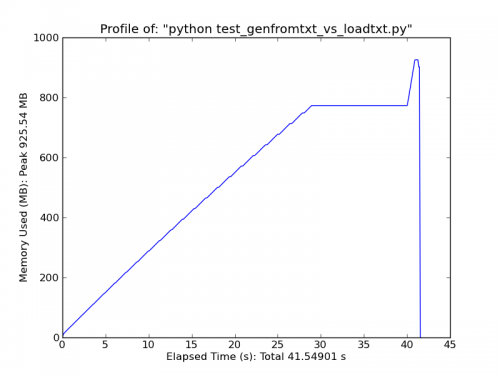
Jeśli masz wystarczającą ilość pamięci ram, rozważ użycie np.loadtxt('yourfile.txt', delimiter=',') (może być również konieczne podanie skiprows Jeśli masz nagłówek w pliku.)
Jako szybkie porównanie, Ładowanie ~500MB pliku tekstowego z loadtxt wykorzystuje ~900MB pamięci ram przy szczytowym zużyciu, podczas gdy ładowanie tego samego pliku z genfromtxt używa ~2,5 GB.
Loadtxt
Genfromtxt
Na przemian, rozważ coś takiego jak poniżej. Będzie działać tylko dla bardzo prostych, regularne dane, ale są dość szybkie. (loadtxt i genfromtxt robią wiele zgadywania i sprawdzania błędów. Jeśli Twoje dane są bardzo proste i regularne, możesz je znacznie poprawić.)
import numpy as np
def generate_text_file(length=1e6, ncols=20):
data = np.random.random((length, ncols))
np.savetxt('large_text_file.csv', data, delimiter=',')
def iter_loadtxt(filename, delimiter=',', skiprows=0, dtype=float):
def iter_func():
with open(filename, 'r') as infile:
for _ in range(skiprows):
next(infile)
for line in infile:
line = line.rstrip().split(delimiter)
for item in line:
yield dtype(item)
iter_loadtxt.rowlength = len(line)
data = np.fromiter(iter_func(), dtype=dtype)
data = data.reshape((-1, iter_loadtxt.rowlength))
return data
#generate_text_file()
data = iter_loadtxt('large_text_file.csv')
Fromiter
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-01-22 21:16:17
Problem z użyciem genfromtxt polega na tym, że próbuje ona załadować cały plik do pamięci, tzn. do tablicy numpy. Jest to świetne dla małych plików, ale złe dla wejść 3GB, takich jak twoje. Ponieważ tylko obliczasz mediany kolumn, nie ma potrzeby odczytywania całego pliku. Prostym, ale nie najskuteczniejszym sposobem, by to zrobić, byłoby wielokrotne odczytywanie całego pliku linia po linii i powtarzanie nad kolumnami.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-01-21 21:33:12
Dlaczego nie używasz modułu python csv?
>> import csv
>> reader = csv.reader(open('All.csv'))
>>> for row in reader:
... print row
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-01-21 21:40:04