Dlaczego pandy w Pythonie były szybsze od danych?tabela fuzji W R w 2012 roku?
Ostatnio natknąłem się na pandas bibliotekę dla Pythona, która zgodnie z Ten benchmark wykonuje bardzo szybkie scalanie w pamięci. Jest jeszcze szybszy niż Dane.Tabela pakiet w R(mój język wyboru do analizy).
Dlaczego pandas jest tak dużo szybszy niż data.table? Czy to z powodu nieodłącznej przewagi prędkości python nad R, czy jest jakiś kompromis, którego nie jestem świadomy? Czy istnieje sposób na wykonywanie połączeń wewnętrznych i zewnętrznych w data.table bez uciekania się do merge(X, Y, all=FALSE) i merge(X, Y, all=TRUE)?
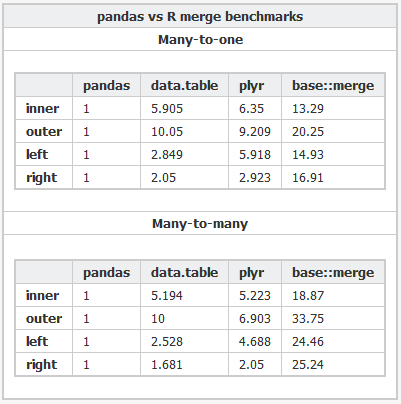
Oto kod R i Kod Pythona używany do porównywania różnych pakietów.
3 answers
Wygląda na to, że Wes mógł odkryć znany problem w data.table, gdy liczba unikalnych ciągów (poziomów) jest duża: 10 000.
Czy Rprof() ujawnia większość czasu spędzonego w wywołaniu sortedmatch(levels(i[[lc]]), levels(x[[rc]])? To nie jest tak naprawdę samo połączenie (algorytm), ale wstępny krok.
Ostatnio podjęto wysiłki, aby zezwolić na kolumny znaków w kluczach, co powinno rozwiązać ten problem poprzez ściślejszą integrację z własną globalną tabelą skrótów znaków R. Niektóre wyniki porównawcze to już zgłoszone przez test.data.table(), ale ten kod nie jest jeszcze podłączony, aby zastąpić poziomy do poziomów dopasowanych.
Czy pandy łączą się szybciej niż data.table dla zwykłych liczb całkowitych? To powinien być sposób na odizolowanie samego algorytmu od kwestii czynników.
Również data.table mA szeregi czasowe scalają w umyśle. Dwa aspekty tego: i) multi column ordered keys such as (id,datetime) ii) fast panujące join (roll=TRUE) vel last observation carried forward.
I ' ll need trochę czasu, aby potwierdzić, ponieważ jest to pierwszy widziałem porównanie do data.table Jak przedstawiono.
Aktualizacja z danych.tabela v1.8. 0 Wydany lipiec 2012
- wewnętrzna funkcja sortedmatch() usunięta i zastąpiona chmatch() przy dopasowywaniu poziomów i do poziomów x dla kolumn typu 'factor'. To wstępny krok powodował (znane) znaczne spowolnienie, gdy liczba z poziomów kolumny czynnika było duże (np. >10 000). Nasilone w testy łączenia czterech takich kolumn, jak wykazał Wes McKinney (autor pakietu Python). Dopasowanie 1 mln strun, w tym z czego 600 000 jest unikalnych jest teraz zmniejszona z 16s do 0,5 s, na przykład.
Również w tym wydaniu było:
Kolumny znaków są teraz dozwolone w klawiszach i są preferowane do factor. data.table () i setkey() nie zmuszają już znaków do factor. Czynniki są nadal wspierane. Wprowadza FR#1493, FR#1224 oraz (częściowo) FR#951.
Nowe funkcje chmatch () i % chin%, szybsze wersje match() i %w% dla wektorów znaków. Wewnętrzny bufor ciągów R jest wykorzystywane (nie jest zbudowana tabela hash). Są około 4 razy szybsze niż match () na przykładzie w ?chmatch.
Ale jak pisałem pierwotnie, wyżej:
data.tablemA szeregi czasowe scalają w umyśle. Dwa aspekty tego: i) multi column ordered keys such as (id, datetime) ii) fast join (roll=TRUE) vel last observation carried forward.
Zatem połączenie dwóch kolumn znakowych jest prawdopodobnie szybsze niż dane.stolik. Ponieważ brzmi to tak, jakby mieszał połączone dwie kolumny. data.table Nie hashuje klucza, ponieważ ma na myśli dominujące uporządkowane połączenia. "Klucz" w danych.tabela jest dosłownie tylko kolejność sortowania (podobna do klastrowego indeksu w SQL; tzn. w ten sposób dane są porządkowane w pamięci RAM). Na liście jest na przykład dodanie kluczy pomocniczych.
Podsumowując, rażąca różnica prędkości podkreślona przez ten konkretny test dwóch kolumn z ponad 10 000 unikalnych ciągów nie powinna być tak zła, ponieważ znany problem został naprawiony.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-09-26 09:46:45
Powodem, dla którego pandas jest szybszy jest to, że wymyśliłem lepszy algorytm, który jest zaimplementowany bardzo ostrożnie przy użyciuszybkiej implementacji tabeli hashowej - klib oraz w C/Cython , Aby uniknąć przeciążenia interpretera Pythona dla części nie-wektoryzowalnych. Algorytm ten opisany jest nieco szczegółowo w mojej prezentacji: a look inside pandy design and development.
Porównanie z data.table jest rzeczywiście trochę interesujące, ponieważ cały punkt R {[0] } jest to, że zawiera wstępnie obliczone indeksy dla różnych kolumn w celu przyspieszenia operacji, takich jak wybór danych i scalanie. W tym przypadku (łączenie baz danych) ramka danych pandy zawiera żadnych wstępnie obliczonych Informacji , które są używane do scalania, że tak powiem jest to" zimne " scalanie. Gdybym przechowywał faktorowane wersje kluczy join, join byłby znacznie szybszy - ponieważ Faktoryzacja jest największym wąskim gardłem dla tego algorytmu.
Dodam jeszcze, że wewnętrzna konstrukcja ramki danych pandy jest znacznie bardziej podatna na tego rodzaju operacje niż dane R.ramka (która jest tylko listą tablic wewnętrznie).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-03-24 11:30:10
Ten temat ma dwa lata, ale wydaje się prawdopodobnym miejscem dla ludzi do lądowania, gdy szukają porównań pand i danych.Tabela
Ponieważ oba z nich ewoluowały w czasie, chcę opublikować relatywnie nowsze porównanie (z 2014) tutaj dla zainteresowanych użytkowników: https://github.com/Rdatatable/data.table/wiki/Benchmarks-:-Grouping
Ciekawe byłoby, czy wes i/lub Matt (którzy, nawiasem mówiąc, są twórcami pand i danych.tabela i mają zarówno skomentowane powyżej) mają jakieś wiadomości do dodania tutaj, jak również.-- UPDATE --
Komentarz zamieszczony poniżej przez jangoreckiego zawiera link, który moim zdaniem jest bardzo przydatny: https://github.com/szilard/benchm-databases

Ten wykres przedstawia średnie czasy agregacji i łączenia operacji dla różnych technologii (lower = faster; Ostatnia aktualizacja porównania we wrześniu 2016 r.). To było dla mnie bardzo pouczające.
Going wracając do pytania, R DT key i R DT odnoszą się do klucza / unkeyed smaków danych R.table and happen to be faster in this benchmark than Python ' s Pandas (Py pandas).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-04-19 22:55:26