W jaki sposób Python dict może mieć wiele kluczy z tym samym skrótem?
Próbuję zrozumieć funkcję hash Pythona pod maską. Utworzyłem klasę niestandardową, w której wszystkie instancje zwracają tę samą wartość skrótu.
class C(object):
def __hash__(self):
return 42
Założyłem, że tylko jedna instancja powyższej klasy może znajdować się w zbiorze w dowolnym momencie, ale w rzeczywistości zbiór może mieć wiele elementów z tym samym Hashem.
c, d = C(), C()
x = {c: 'c', d: 'd'}
print x
# {<__main__.C object at 0x83e98cc>:'c', <__main__.C object at 0x83e98ec>:'d'}
# note that the dict has 2 elements
Eksperymentowałem trochę więcej i stwierdziłem, że jeśli nadpisuję metodę __eq__ tak, że wszystkie instancje klasy są równe, to zestaw pozwala tylko na jedną przykład.
class D(C):
def __eq__(self, other):
return hash(self) == hash(other)
p, q = D(), D()
y = {p:'p', q:'q'}
print y
# {<__main__.D object at 0x8817acc>]: 'q'}
# note that the dict has only 1 element
Więc jestem ciekaw, jak dict może mieć wiele elementów z tym samym hash. Dzięki!
Uwaga: edytowałem pytanie, aby podać przykład dict (zamiast set), ponieważ cała dyskusja w odpowiedziach dotyczy dict. To samo dotyczy zestawów; zestawy mogą również zawierać wiele elementów o tej samej wartości skrótu.
5 answers
Szczegółowy opis działania hashowania w Pythonie znajduje się w mojej odpowiedzi na Dlaczego early return jest wolniejszy niż inne?
W zasadzie używa hasha do wybrania miejsca w tabeli. Jeśli w gnieździe znajduje się wartość i hash jest zgodny, porównuje elementy, aby sprawdzić, czy są równe.
Jeśli hash nie pasuje lub elementy nie są równe, to próbuje innego slotu. Jest wzór na wybranie tego (który opisuję w odpowiedzi) i stopniowo ściąga nieużywany części wartości hash; ale gdy zużyje je wszystkie, w końcu przejdzie przez wszystkie sloty w tabeli hash. To gwarantuje, że w końcu znajdziemy pasujący element lub puste miejsce. Gdy wyszukiwanie znajdzie puste miejsce, wstawia wartość lub rezygnuje (w zależności od tego, czy dodajemy lub otrzymujemy wartość).
Ważne jest, aby pamiętać, że nie ma list lub wiadra: istnieje tylko tabela hash z określoną liczbą slotów, a każdy hash jest używany do generowanie sekwencji slotów kandydatów.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-23 10:31:11
Tutaj jest wszystko o pythonowych dictach, które udało mi się złożyć (prawdopodobnie więcej niż ktokolwiek chciałby wiedzieć; ale odpowiedź jest wyczerpująca). Okrzyk dla Duncana za zwrócenie uwagi na to, że Python dicks używają slotów i prowadzą mnie w dół tej króliczej nory.
- słowniki Pythona są zaimplementowane jako tabele hashowe.
- tabele Hash muszą pozwalać na kolizje hash tzn. nawet jeśli dwa klucze mają taką samą wartość hash, implementacja tabela musi mieć strategię wstawiania i pobierania par klucz i wartość jednoznacznie.
- Python dict używa open addressing do rozwiązywania kolizji hashowych (wyjaśnione poniżej) (zobacz dictobject.c: 296-297 ).
- tabela hash w Pythonie jest tylko kontuualnym blokiem pamięci(coś w rodzaju tablicy, więc możesz wyszukać
O(1)według indeksu). - każde miejsce w tabeli może przechowywać jeden i tylko jeden wpis. to jest ważne
- każdy wpis w tabeli faktycznie kombinacja trzech wartości - . Jest to zaimplementowane jako struktura C (zobacz dictobject.h:51-56)
-
Poniższy rysunek przedstawia logiczną reprezentację tabeli hashowej Pythona. Na rysunku poniżej, 0, 1, ...,,,,,.. po lewej stronie znajdują się indeksy slotów w tabeli hash (są one tylko w celach poglądowych i oczywiście nie są przechowywane razem z tabelą!).
# Logical model of Python Hash table -+-----------------+ 0| <hash|key|value>| -+-----------------+ 1| ... | -+-----------------+ .| ... | -+-----------------+ i| ... | -+-----------------+ .| ... | -+-----------------+ n| ... | -+-----------------+ Po zainicjowaniu nowego dict zaczyna się od 8 slotów . (zobacz dictobject.h:49)
- podczas dodawania wpisów do tabeli zaczynamy od jakiegoś slotu,
i, który opiera się na hashie klucza. CPython używa inicjałui = hash(key) & mask. Gdziemask = PyDictMINSIZE - 1, ale to nie jest naprawdę ważne). Zauważ, że początkowy slot, i, który jest sprawdzany, zależy od hash klucza. - jeśli slot jest pusty, wpis jest dodawany do slot (przez wpis, mam na myśli
<hash|key|value>). Ale co, jeśli to miejsce jest zajęte!? Najbardziej prawdopodobnie dlatego, że inny wpis ma ten sam hash (hash collision!) - jeśli slot jest zajęty, CPython (a nawet PyPy) porównuje hash i klucz (przez porównanie mam na myśli
==Porównanie, a nieisporównanie) wpisu w slocie z kluczem bieżącego wpisu, który ma być wstawiony (dictobject.c:337,344-345). Jeśli oba pasują, to myśli, że wpis już istnieje, poddaje się i przechodzi do następnego wpisu, który ma zostać wstawiony. Jeśli albo hash albo klucz nie pasuje, zaczyna się sondowanie . - sondowanie oznacza, że przeszukuje szczeliny po szczelinie, aby znaleźć puste miejsce. Technicznie możemy iść jeden po drugim, i+1, i + 2, ... i użyć pierwszego dostępnego (czyli sondy liniowej). Ale z powodów wyjaśnionych pięknie w komentarzach (patrz dictobject.c:33-126), CPython wykorzystuje random sonding. W random probing, następny slot jest wybierany w pseudo losowej kolejności. Wpis jest dodawany do pierwszego pustego miejsca. Na ta dyskusja, rzeczywisty algorytm użyty do wybrania następnego slotu nie jest tak naprawdę ważny (zobacz dictobject.c: 33-126 dla algorytmu sondowania). Ważne jest to, że szczeliny są badane aż do znalezienia pierwszego pustego szczeliny.
- to samo dzieje się w przypadku wyszukiwania, po prostu zaczyna się od początkowego gniazda i (gdzie i zależy od hash klucza). Jeśli hash i klucz nie pasują do wpisu w gnieździe, zaczyna on sondować, dopóki nie znajdzie gniazda z dopasowaniem. Jeśli wszystkie sloty są wyczerpane, zgłasza awarię.
- BTW, dict zostanie zmieniony, jeśli będzie pełne dwie trzecie. Pozwala to uniknąć spowolnienia poszukiwań. (zobacz dictobject.h:64-65)
==) kluczy podczas wstawiania elementów. Podsumowując, jeśli istnieją dwa klucze, a i b i hash(a)==hash(b), Ale a!=b, to oba mogą istnieć harmonijnie w dict Pythona. Ale jeśli hash(a)==hash(b) i a==b, więc nie mogą być w tym samym dict.
Ponieważ musimy badać po każdej kolizji hash, jednym ze skutków ubocznych zbyt wielu kolizji hash jest to, że wyszukiwanie i wstawianie będzie bardzo powolne (jak wskazuje Duncan w komentarzu ).
Myślę, że krótka odpowiedź na moje pytanie brzmi: "ponieważ tak to jest zaimplementowane w kodzie źródłowym;)"
Chociaż to dobrze wiedzieć (dla geek points?), Nie jestem pewien, w jaki sposób można go wykorzystać w prawdziwym życiu. Bo jeśli nie próbujesz jednoznacznie złamać czegoś, dlaczego dwa obiekty, które nie są sobie równe, mają ten sam hash?
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-23 12:26:23
Edit : odpowiedź poniżej jest jednym z możliwych sposobów radzenia sobie z kolizjami hashów, jednak nie Jak to robi Python. Wiki Pythona, o której mowa poniżej, jest również Niepoprawna. Najlepszym źródłem podanym przez @ Duncan poniżej jest sama implementacja: http://svn.python.org/projects/python/trunk/Objects/dictobject.c przepraszam za zamieszanie.
Przechowuje listę (lub wiadro) elementów w hash, a następnie iteracji przez tę listę, aż znajdzie rzeczywiste klucz do tej listy. Obraz mówi więcej niż tysiąc słów:
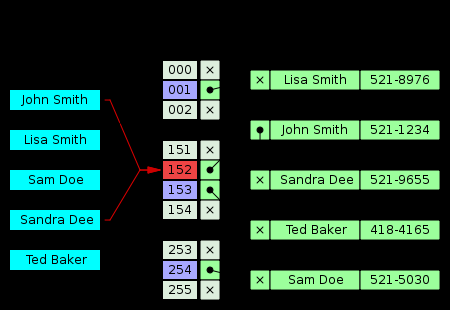
Tutaj widzisz John Smith i Sandra Dee oba skróty do 152. Wiadro 152 zawiera oba z nich. Podczas wyszukiwania Sandra Dee Najpierw znajduje listę w bucket 152, a następnie przecina ją, aż Sandra Dee zostanie znaleziona i zwróci 521-6955.
Poniższy błąd jest tu tylko dla kontekstu: na wiki Pythona możesz znaleźć (pseudo?) Kod jak Python wykonuje wyszukiwanie.
Jest w rzeczywistości kilka możliwych rozwiązań tego problemu, sprawdź artykuł w Wikipedii, aby uzyskać ładny przegląd: http://en.wikipedia.org/wiki/Hash_table#Collision_resolution
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-02-08 14:34:20
Tabele Hash, w ogóle muszą dopuszczać kolizje hash! Będziesz mieć pecha i dwie rzeczy w końcu hash do tego samego. Poniżej znajduje się zestaw obiektów na liście elementów, które mają ten sam klucz skrótu. Zazwyczaj jest tylko jedna rzecz na tej liście, ale w tym przypadku, będzie je układać w to samo. Jedynym sposobem, aby wiedzieć, że są różne, jest operator równości.
Kiedy to się stanie, Twoje wyniki z czasem ulegną degradacji, dlatego ty chcesz, aby funkcja hash była jak najbardziej "losowa".
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-01-25 21:04:39
W wątku nie widziałem, co dokładnie robi python z instancjami klas zdefiniowanych przez użytkownika, gdy umieszczamy je w słowniku jako klucze. Poczytajmy trochę dokumentacji: deklaruje ona, że tylko obiekty hashable mogą być używane jako klucze. Hashable są niezmiennymi klasami wbudowanymi i wszystkimi klasami zdefiniowanymi przez użytkownika.
Klasy zdefiniowane przez Użytkownika mają __cmp _ _ () i _metody_ hash_ _ () domyślnie; z nimi wszystkie obiekty porównywać nierówne (z wyjątkiem samych siebie) i x.__ hash _ _ () zwraca wynik uzyskany z id (x).
Więc jeśli masz stale _ _ hash_ _ w swojej klasie, ale nie podajesz żadnej metody __cmp__ lub __eq__, to wszystkie Twoje instancje są nierówne dla słownika. Z drugiej strony, jeśli podasz metodę _ _ cmp _ _ lub _ _ eq__, ale nie podasz _ _ hash__, Twoje instancje nadal są nierówne pod względem słownikowym.
class A(object):
def __hash__(self):
return 42
class B(object):
def __eq__(self, other):
return True
class C(A, B):
pass
dict_a = {A(): 1, A(): 2, A(): 3}
dict_b = {B(): 1, B(): 2, B(): 3}
dict_c = {C(): 1, C(): 2, C(): 3}
print(dict_a)
print(dict_b)
print(dict_c)
Wyjście
{<__main__.A object at 0x7f9672f04850>: 1, <__main__.A object at 0x7f9672f04910>: 3, <__main__.A object at 0x7f9672f048d0>: 2}
{<__main__.B object at 0x7f9672f04990>: 2, <__main__.B object at 0x7f9672f04950>: 1, <__main__.B object at 0x7f9672f049d0>: 3}
{<__main__.C object at 0x7f9672f04a10>: 3}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-08-23 10:15:11