O dzieleniu plików Hadoop / HDFS
Chcę tylko potwierdzić na następujące. Sprawdź, czy jest to poprawne: 1. Zgodnie z moim zrozumieniem, kiedy kopiujemy plik do HDFS, jest to punkt, w którym plik (zakładając jego rozmiar > 64MB = rozmiar bloku HDFS) jest podzielony na wiele kawałków, a każdy kawałek jest przechowywany na różnych węzłach danych.
-
Zawartość pliku jest już dzielona na kawałki, gdy plik jest kopiowany do HDFS, a podział pliku nie następuje w czasie uruchamiania zadania map. Zadania na mapie są zaplanowane tylko w taki sposób że pracują na każdym kawałku Maxa. rozmiar 64 MB z lokalizacją danych (np. zadanie map działa na tym węźle, który zawiera dane/fragment)
Podział Plików ma miejsce również wtedy, gdy plik jest skompresowany (gzipped), ale MR zapewnia, że każdy plik jest przetwarzany przez tylko jednego mapera, tzn. MR zbierze wszystkie fragmenty pliku gzip leżące w innych węzłach danych i przekaże je pojedynczemu maperowi.
To samo co powyżej nastąpi jeśli zdefiniujemy issplatable () aby zwracało false, tzn. wszystkie fragmenty pliku będą przetwarzane przez jednego mapera działającego na jednym komputerze. MR odczyta wszystkie fragmenty pliku z różnych węzłów danych i udostępni je pojedynczemu maperowi.
3 answers
Twoje zrozumienie nie jest idealne.
Chciałbym zauważyć, że istnieją dwa, prawie niezależne procesy: dzielenie plików na bloki HDFS i dzielenie plików do przetwarzania przez różne mapery.
HDFS dzieli pliki na bloki na podstawie zdefiniowanego rozmiaru bloku.
każdy format wejściowy ma własną logikę, w jaki sposób pliki mogą być dzielone na części w celu niezależnego przetwarzania przez różnych maperów. Domyślną logiką formatu pliku jest dzielenie pliku przez bloki HDFS. Możesz zaimplementować dowolne inne logika
Kompresja, zwykle jest przeciwnikiem dzielenia, dlatego stosujemy technikę kompresji blokowej, aby umożliwić dzielenie skompresowanych danych. Oznacza to, że każda logiczna część pliku (bloku) jest skompresowana niezależnie.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-02-13 12:06:57
Odpowiedź Davida prawie trafia w sedno, właśnie nad nią pracuję.
Istnieją tutaj dwie różne koncepcje, każda z nich jest obsługiwana przez inny podmiot w ramach hadoop
Po Pierwsze --
1) dzielenie pliku na bloki -- gdy plik jest zapisywany do HDFS, HDFS dzieli plik na bloki i zajmuje się jego replikacją. Odbywa się to raz (w większości), a następnie jest dostępne dla wszystkich zadań MR uruchomionych w klastrze. To jest konfiguracją klastra
Po drugie --
2) dzielenie pliku na podziały wejściowe -- gdy ścieżka wejściowa jest przekazywana do zadania MR, zadanie MR używa ścieżki wraz z formatem wejściowym skonfigurowanym do dzielenia plików określonych w ścieżce wejściowej na podziały, każdy podział jest przetwarzany przez zadanie map. Obliczanie podziałów wejściowych odbywa się za pomocą formatu wejściowego przy każdym wykonaniu zadania
Teraz, gdy już mamy to za sobą, możemy zrozumieć, że jest to() metoda należy do drugiej kategorii.
Aby naprawdę to rozwikłać, przyjrzyj się przepływowi danych zapisu HDFS (koncepcja 1)
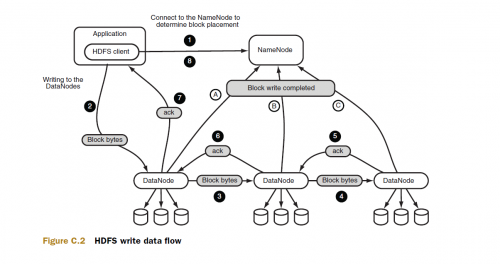
Drugi punkt na diagramie to prawdopodobnie miejsce, w którym następuje podział, zauważ, że nie ma to nic wspólnego z uruchomieniem zadania MR
Teraz spójrz na etapy wykonania MR job
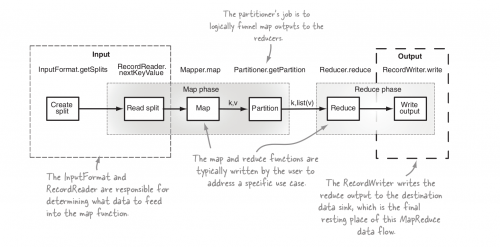
Tutaj pierwszym krokiem jest obliczenie podziałów wejściowych poprzez format wejścia skonfigurowany dla zadania.
Dużo Twoje zamieszanie wynika z faktu, że clubbing obu tych pojęć, mam nadzieję, że to czyni to trochę jaśniejsze.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-04-17 05:26:20
Tak, Zawartość pliku jest dzielona na kawałki, gdy plik jest kopiowany do HDFS. Rozmiar bloku jest konfigurowalny i jeśli jest to powiedzmy 128 MB, to całe 128 MB będzie jednym blokiem, a nie 2 bloki po 64 MB osobno.Nie jest również konieczne, aby każdy fragment pliku był przechowywany na osobnym datanodzie.Datanode może mieć więcej niż jeden fragment określonego pliku.A konkretny fragment może być obecny w więcej niż jednym datanodach na podstawie współczynnika replikacji.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-04-16 12:06:29