kolejkowanie żądań jednorożca
Właśnie przeprowadziliśmy migrację z passenger do unicorn, aby hostować kilka aplikacji rails. Wszystko działa świetnie, ale zauważamy poprzez New Relic, że prośba jest w kolejce między 100 a 300ms.
Oto wykres:
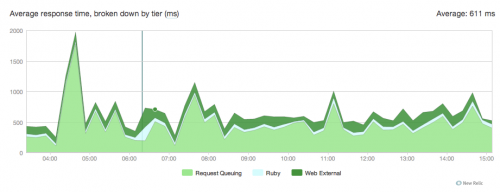
Nie mam pojęcia skąd to się bierze oto nasz jednorożec conf:
current_path = '/data/actor/current'
shared_path = '/data/actor/shared'
shared_bundler_gems_path = "/data/actor/shared/bundled_gems"
working_directory '/data/actor/current/'
worker_processes 6
listen '/var/run/engineyard/unicorn_actor.sock', :backlog => 1024
timeout 60
pid "/var/run/engineyard/unicorn_actor.pid"
logger Logger.new("log/unicorn.log")
stderr_path "log/unicorn.stderr.log"
stdout_path "log/unicorn.stdout.log"
preload_app true
if GC.respond_to?(:copy_on_write_friendly=)
GC.copy_on_write_friendly = true
end
before_fork do |server, worker|
if defined?(ActiveRecord::Base)
ActiveRecord::Base.connection.disconnect!
end
old_pid = "#{server.config[:pid]}.oldbin"
if File.exists?(old_pid) && server.pid != old_pid
begin
sig = (worker.nr + 1) >= server.worker_processes ? :TERM : :TTOU
Process.kill(sig, File.read(old_pid).to_i)
rescue Errno::ENOENT, Errno::ESRCH
# someone else did our job for us
end
end
sleep 1
end
if defined?(Bundler.settings)
before_exec do |server|
paths = (ENV["PATH"] || "").split(File::PATH_SEPARATOR)
paths.unshift "#{shared_bundler_gems_path}/bin"
ENV["PATH"] = paths.uniq.join(File::PATH_SEPARATOR)
ENV['GEM_HOME'] = ENV['GEM_PATH'] = shared_bundler_gems_path
ENV['BUNDLE_GEMFILE'] = "#{current_path}/Gemfile"
end
end
after_fork do |server, worker|
worker_pid = File.join(File.dirname(server.config[:pid]), "unicorn_worker_actor_#{worker.nr$
File.open(worker_pid, "w") { |f| f.puts Process.pid }
if defined?(ActiveRecord::Base)
ActiveRecord::Base.establish_connection
end
end
user deploy deploy;
worker_processes 6;
worker_rlimit_nofile 10240;
pid /var/run/nginx.pid;
events {
worker_connections 8192;
use epoll;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
sendfile on;
tcp_nopush on;
server_names_hash_bucket_size 128;
if_modified_since before;
gzip on;
gzip_http_version 1.0;
gzip_comp_level 2;
gzip_proxied any;
gzip_buffers 16 8k;
gzip_types application/json text/plain text/html text/css application/x-javascript t$
# gzip_disable "MSIE [1-6]\.(?!.*SV1)";
# Allow custom settings to be added to the http block
include /etc/nginx/http-custom.conf;
include /etc/nginx/stack.conf;
include /etc/nginx/servers/*.conf;
}
upstream upstream_actor_ssl {
server unix:/var/run/engineyard/unicorn_actor.sock fail_timeout=0;
}
server {
listen 443;
server_name letitcast.com;
ssl on;
ssl_certificate /etc/nginx/ssl/letitcast.crt;
ssl_certificate_key /etc/nginx/ssl/letitcast.key;
ssl_session_cache shared:SSL:10m;
client_max_body_size 100M;
root /data/actor/current/public;
access_log /var/log/engineyard/nginx/actor.access.log main;
error_log /var/log/engineyard/nginx/actor.error.log notice;
location @app_actor {
include /etc/nginx/common/proxy.conf;
proxy_pass http://upstream_actor_ssl;
}
include /etc/nginx/servers/actor/custom.conf;
include /etc/nginx/servers/actor/custom.ssl.conf;
if ($request_filename ~* \.(css|jpg|gif|png)$) {
break;
}
location ~ ^/(images|javascripts|stylesheets)/ {
expires 10y;
}
error_page 404 /404.html;
error_page 500 502 504 /500.html;
error_page 503 /system/maintenance.html;
location = /system/maintenance.html { }
location / {
if (-f $document_root/system/maintenance.html) { return 503; }
try_files $uri $uri/index.html $uri.html @app_actor;
}
include /etc/nginx/servers/actor/custom.locations.conf;
}
Nie jesteśmy pod dużym obciążeniem, więc nie rozumiem, dlaczego prośby utknęły w kolejce. Jako określone w konf jednorożca, mamy 6 pracowników jednorożca.
Wiesz, skąd to się wzięło ?Cheers
EDIT:
Średnia liczba zapytań na minutę: około 15 przez większość czasu, ponad 300 wglądów, ale nie doświadczyliśmy żadnego od czasu migracji.
Średnie obciążenie procesora: 0.2-0.3
Użyłem również kropli deszczu aby zobaczyć, co się stało robotnikom jednorożców za.
Oto skrypt ruby:
#!/usr/bin/ruby
# this is used to show or watch the number of active and queued
# connections on any listener socket from the command line
require 'raindrops'
require 'optparse'
require 'ipaddr'
usage = "Usage: #$0 [-d delay] ADDR..."
ARGV.size > 0 or abort usage
delay = false
# "normal" exits when driven on the command-line
trap(:INT) { exit 130 }
trap(:PIPE) { exit 0 }
opts = OptionParser.new('', 24, ' ') do |opts|
opts.banner = usage
opts.on('-d', '--delay=delay') { |nr| delay = nr.to_i }
opts.parse! ARGV
end
socks = []
ARGV.each do |f|
if !File.exists?(f)
puts "#{f} not found"
next
end
if !File.socket?(f)
puts "#{f} ain't a socket"
next
end
socks << f
end
fmt = "% -50s % 10u % 10u\n"
printf fmt.tr('u','s'), *%w(address active queued)
begin
stats = Raindrops::Linux.unix_listener_stats(socks)
stats.each do |addr,stats|
if stats.queued.to_i > 0
printf fmt, addr, stats.active, stats.queued
end
end
end while delay && sleep(delay)
Jak go uruchomiłem:
./linux-tcp-listener-stats.rb -d 0.1 /var/run/engineyard/unicorn_actor.sock
Więc zasadniczo sprawdza co 1 / 10s, czy w kolejce są żądania i jeśli są to wyjścia:
Gniazdo | liczba przetwarzanych wniosków | liczba żądań w kolejce
Oto streszczenie wyniku:
Https://gist.github.com/f9c9e5209fbbfc611cb1
EDIT2:
Próbowałem zmniejsz liczbę pracowników nginx do jednego wczoraj, ale to niczego nie zmieniło.
Dla informacji jesteśmy hostowani na Engine Yard i mamy średnią instancję high-CPU 1.7 GB pamięci, 5 jednostek obliczeniowych EC2 (2 Wirtualne rdzenie po 2.5 jednostek obliczeniowych EC2 każdy)
Obsługujemy 4 Aplikacje rails, ta ma 6 pracowników, mamy jedną z 4, jedną z 2, a drugą z jedną. Wszyscy doświadczają kolejek żądań od czasu migracji do unicorn. Nie wiem czy pasażer oszukiwał ale New Relic nie zapisywał żadnego żądania w kolejce, kiedy go używaliśmy. Mamy też węzeł.aplikacja js obsługująca przesyłanie plików, bazę danych mysql i 2 redis.
Edytuj 3:
Używamy ruby 1.9. 2p290, nginx 1.0.10, unicorn 4.2.1 i newrelic_rpm 3.3.3. Spróbuję bez newrelic jutro i dam znać wyniki tutaj, ale dla informacji używaliśmy pasażera z new relic, ta sama wersja ruby i nginx i nie miał żadnego problemu.
Edytuj 4:
Próbowałem zwiększyć client_body_buffer_size i proxy_buffers z
client_body_buffer_size 256k;
proxy_buffers 8 256k;
Ale to nie zadziałało.
Edytuj 5:
W końcu to rozgryzliśmy ... Werble ... Zwycięzcą został nasz Cypher SSL. Kiedy zmieniliśmy go na RC4, zauważyliśmy, że kolejka żądań spada z 100 - 300ms do 30-100ms.
3 answers
Właśnie zdiagnozowałem podobny wygląd nowego wykresu relic jako całkowicie winę SSL. Spróbuj to wyłączyć. Widzimy czas kolejkowania żądania 400ms, który spada do 20ms bez SSL.
Kilka ciekawych punktów na temat tego, dlaczego niektórzy dostawcy SSL mogą być powolni: http://blog.cloudflare.com/how-cloudflare-is-making-ssl-fast
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-03-21 22:21:54
Jakiej wersji ruby, unicorn, nginx (nie powinno mieć znaczenia, ale warto wspomnieć) i newrelic_rpm używasz?
Ponadto, spróbowałbym uruchomić podstawowy test perf bez newrelic. NewRelic parsuje odpowiedź i są przypadki, w których może to być powolne z powodu problemu z 'rindex' w ruby pre-1.9.3. Jest to zwykle zauważalne tylko wtedy, gdy odpowiedź jest bardzo duża i nie zawiera znaczników "body" (np. AJAX, JSON, itp.). Widziałem przykład tego, gdzie odpowiedź AJAX 1MB była analiza NewRelic trwa 30 sekund.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-04-05 02:50:43
Czy jesteś pewien, że buforujesz żądania od klientów w nginx, a następnie buforujesz odpowiedzi od jednorożców przed wysłaniem ich z powrotem do klientów. Z twojej konfiguracji wydaje się, że tak (ponieważ jest to domyślnie), ale sugeruję, abyś to dokładnie sprawdził.
Konfiguracja do obejrzenia to:
Http://wiki.nginx.org/HttpProxyModule#proxy_buffering
To jest do buforowania odpowiedzi od jednorożców. Zdecydowanie potrzebujesz go, ponieważ nie chcesz, aby jednorożce były zajęte wysyłaniem danych do powolnego klienta.
Dla buforowania prośby klienta myślę, że należy spojrzeć na:
Http://wiki.nginx.org/HttpCoreModule#client_body_buffer_size
Myślę, że to wszystko nie może wyjaśnić opóźnienia 100ms, ale nie jestem zaznajomiony z całą konfiguracją systemu, więc warto spojrzeć na ten kierunek. Wygląda na to, że kolejkowanie nie jest spowodowane przez Spór CPU, ale przez jakiś rodzaj IO blokuję.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-11-14 23:57:56