Architektura perceptron wielowarstwowy (MLP): kryteria wyboru liczby ukrytych warstw i ich wielkości? [zamknięte]
chcesz poprawić to pytanie? Zaktualizuj pytanie, aby mogło być odpowiedź z faktami i cytatami przez edytując ten post .
Zamknięte 2 dni temu .
Popraw to pytanieJeśli mamy 10 wektorów, to możemy mieć 10 węzłów neuronowych w warstwie wejściowej.Jeśli mamy 5 klas wyjściowych, to możemy mieć 5 węzłów w warstwie wyjściowej.Ale jakie są kryteria wyboru liczba ukrytych warstw w MLP i ile węzłów neuronowych w jednej ukrytej warstwie?
4 answers
Ile ukrytych warstw?
Model z zeroukrytych warstw rozwiąże liniowo rozdzielalne Dane. Więc jeśli już wiesz, że Twoje dane nie są liniowo rozdzielne, nie zaszkodzi to zweryfikować -- po co używać bardziej złożonego modelu niż wymaga tego zadanie? Jeśli jest rozdzielna liniowo, to zadziała prostsza technika, ale Perceptron również to zrobi.
Zakładając, że Twoje dane wymagają rozdzielenia techniką nieliniową, to zawsze zaczynaj od jednej ukrytej warstwy. Prawie na pewno to wszystko, czego potrzebujesz. Jeśli dane można rozdzielić za pomocą MLP, to ten MLP prawdopodobnie potrzebuje tylko jednej ukrytej warstwy. Istnieje teoretyczne uzasadnienie tego, ale mój powód jest czysto empiryczny: wiele trudnych problemów klasyfikacji / regresji rozwiązuje się za pomocą MlP z jedną ukrytą warstwą, ale nie przypominam sobie, aby napotkać jakiekolwiek MlP z wieloma ukrytymi warstwami używane do skutecznego modelowania danych-czy na tablicach ogłoszeń ML, ML Podręczniki, prace naukowe itp. Istnieją, oczywiście, ale okoliczności, które uzasadniają ich użycie, są empirycznie dość rzadkie.
ile węzłów w warstwie ukrytej?
Z literatury akademickiej MLP. własne doświadczenia itp., Zebrałem i często opierałem się na kilku zasadach (RoT ), a które również uznałem za wiarygodne Przewodniki (tj., wskazówki były dokładne, a nawet gdy nie było, zazwyczaj było jasne, co robić następny):
RoT na podstawie poprawy zbieżności:
Po rozpoczęciu budowy modelu, po stronie więcej węzłów w ukrytej warstwie.
Dlaczego? Po pierwsze, kilka dodatkowych węzłów w ukrytej warstwie prawdopodobnie nie zaszkodzi-Twój MLP nadal będzie się zbierał. Z drugiej strony zbyt mała liczba węzłów w warstwie ukrytej może zapobiec konwergencji. Pomyśl o tym w ten sposób, dodatkowe węzły zapewniają pewną nadwyżkę pojemności-dodatkowe wagi do przechowywania/uwalniania sygnał do sieci podczas iteracji (szkolenia lub budowania modelu). Po drugie, jeśli zaczniesz z dodatkowymi węzłami w ukrytej warstwie, łatwo będzie je później przyciąć(w trakcie iteracji). Jest to powszechne i istnieją techniki diagnostyczne, które pomogą Ci (np. diagram Hintona, który jest tylko wizualnym przedstawieniem matryc wagowych, "mapa ciepła" wartości wagowych).
RoTs na podstawie wielkości warstwy wejściowej i wielkości warstwy wyjściowej:
zasada kciuka jest dla wielkości tej [ukrytej] warstwy, aby gdzieś pomiędzy rozmiarem warstwy wejściowej ... i rozmiar warstwy wyjściowej....
aby obliczyć liczbę ukrytych węzłów stosujemy ogólną zasadę: (Ilość wejść + wyjść) x 2/3
RoT na podstawie głównych składników:
zazwyczaj określamy tyle ukrytych węzłów co wymiary [główne komponenty] potrzebne do przechwytywania 70-90% wariancji danych wejściowych set .
A jednak NN FAQ autor nazywa te zasady "nonsensem" (dosłownie), ponieważ: ignorują liczbę instancji treningowych, hałas w celach (wartości zmiennych odpowiedzi) i złożoność przestrzeni funkcji.
Jego zdaniem (i zawsze wydawało mi się, że wie, o czym mówi), Wybierz liczbę neuronów w ukrytej warstwie w oparciu o to, czy twój MLP zawiera jakąś formę regularyzacji, czy wczesne zatrzymanie .
jedyna słuszna technika optymalizacji liczby neuronów w warstwie ukrytej:
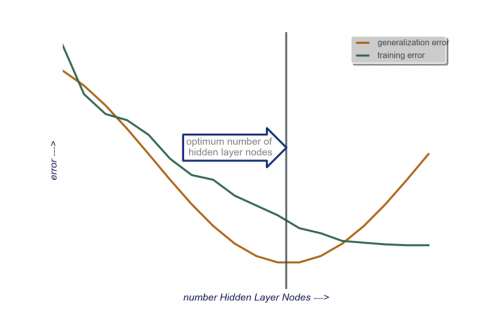
Podczas budowania modelu, testuj obsesyjnie; testy ujawnią sygnatury "nieprawidłowej" architektury sieci. Na przykład, jeśli zaczynasz od MLP z ukrytą warstwą złożoną z niewielkiej liczby węzłów (które stopniowo zwiększasz w razie potrzeby, na podstawie wyników testów), twój błąd w treningu i uogólnieniu będzie wysoki spowodowane przez stronniczość i niedopasowanie.
Następnie zwiększ liczbę węzłów w warstwie ukrytej, jeden po drugim, aż błąd uogólnienia zacznie wzrastać, tym razem z powodu nadmiernego dopasowania i wysokiej wariancji.
W praktyce robię to w ten sposób:
Warstwa wejściowa : rozmiar mojego vactora danych (liczba funkcji w moim modelu) + 1 dla węzła bias i oczywiście nie wliczając zmiennej odpowiedzi
Warstwa wyjściowa :: regresja (jeden węzeł) a klasyfikacja (Liczba węzłów równa liczbie klas, przy założeniu softmax)
Ukryta warstwa: na początek, jedna ukryta warstwa z liczbą węzłów równą wielkości warstwy wejściowej. "Idealny" rozmiar jest raczej mniejszy (tzn. pewna liczba węzłów między liczbą w warstwie wejściowej a liczbą w warstwie wyjściowej) niż większy-znowu, jest to tylko obserwacja empiryczna, a większość z tego obserwacja to moje własne doświadczenie. Jeśli projekt uzasadniał dodatkowy wymagany czas, zaczynam od pojedynczej ukrytej warstwy złożonej z niewielkiej liczby węzłów, a następnie (jak wyjaśniłem powyżej) dodaję węzły do ukrytej warstwy, jeden po drugim, obliczając błąd uogólnienia, błąd szkolenia, stronniczość i wariancję. Kiedy błąd uogólnienia zmalał i tuż przed tym, jak zacznie ponownie rosnąć, liczba węzłów w tym momencie jest moim wyborem. Zobacz rysunek poniżej.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-12-05 10:18:44
Bardzo trudno jest wybrać liczbę neuronów w ukrytej warstwie i wybrać liczbę ukrytych warstw w sieci neuronowej.
Zazwyczaj w większości zastosowań wystarczy jedna ukryta warstwa. Ponadto liczba neuronów w tej ukrytej warstwie powinna mieścić się między liczbą wejść (10 w twoim przykładzie) a liczbą wyjść (5 w twoim przykładzie).
Ale najlepszym sposobem wyboru liczby neuronów i ukrytych warstw jest eksperymentowanie. Trenuj kilka neuronów sieci o różnej liczbie ukrytych warstw i ukrytych neuronów oraz mierzą wydajność tych sieci za pomocą walidacji krzyżowej . Możesz trzymać się numeru, który daje najlepszą wydajność sieci.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-05-12 17:31:25
Aby zautomatyzować wybór najlepszej liczby warstw i najlepszej liczby neuronów dla każdej z warstw, możesz użyć optymalizacja genetyczna.
Kluczowe elementy to:
- chromosom : wektor, który określa ile jednostek w każdej ukrytej warstwie (np. [20,5,1,0,0] czyli 20 jednostek w pierwszej ukrytej warstwie, 5 w drugiej,... , przy braku warstw 4 i 5). Możesz ustawić limit maksymalnej liczby warstw do wypróbowania i maksymalnej liczby jednostki w każdej warstwie. Należy również wprowadzić ograniczenia dotyczące sposobu generowania chromosomów. Np. [10, 0, 3,... ] nie powinny być generowane, ponieważ wszelkie jednostki po brakującej warstwie ('3,...") byłoby nieistotne i zmarnowałoby cykle oceny.
- Funkcja Fitness : funkcja, która Zwraca odwrotność najniższego błędu treningowego w zbiorze krzyżowym sieci zdefiniowanej przez dany chromosom. Możesz również podać liczbę jednostek całkowitych lub obliczyć czas, jeśli chcesz znaleźć "najmniejszą / najszybszą, a jednocześnie najdokładniejszą sieć".
Możesz również rozważyć:
- przycinanie : Zacznij od dużej sieci, a następnie zmniejsz warstwy i ukryte jednostki, zachowując wydajność zestawu weryfikacji krzyżowej.
- rosnąca : Zacznij od bardzo małej sieci, następnie Dodaj Jednostki i warstwy i ponownie śledź wydajność zestawu CV.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-02-03 18:57:47
Ostatnio są prace teoretyczne na ten temat https://arxiv.org/abs/1809.09953 . zakładając, że używasz Relu MLP, wszystkie ukryte warstwy mają taką samą liczbę węzłów, a twoja funkcja straty i funkcja true, które przybliżasz siecią neuronową, są zgodne z niektórymi właściwościami technicznymi( w artykule), możesz wybrać głębokość, która ma być rzędu $\log(n)$ i szerokość ukrytych warstw, która ma być rzędu $n^{D/(2(\beta+D))}\log^2(n)$. Tutaj $n$ to twój rozmiar próbki, $d$ to wymiar twojego wektor wejściowy, a $ \ beta$ jest parametrem gładkości dla twojej prawdziwej funkcji. Ponieważ $ \ beta $ nie jest znana, prawdopodobnie będziesz chciał traktować ją jako hiperparametr.
Robi to można zagwarantować, że z prawdopodobieństwem, które zbiegają się do $1$ jako funkcja wielkości próbki błąd przybliżenia zbiega się do $0$ jako funkcja wielkości próbki. Dają stawkę. Zauważ, że nie jest to gwarantowana "Najlepsza" architektura, ale może przynajmniej dać ci dobre miejsce na początek. Dalej, mój własne doświadczenie sugeruje, że takie rzeczy jak porzucenie może nadal pomóc w praktyce.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-04-09 00:29:46