Jak rozumieć wrażliwe hashowanie?
Zauważyłem, że LSH wydaje się dobrym sposobem na znalezienie podobnych przedmiotów o właściwościach o wysokim wymiarze.
Po przeczytaniu gazety http://www.slaney.org/malcolm/yahoo/Slaney2008-LSHTutorial.pdf , nadal jestem mylony z tymi formułami.
Czy ktoś zna blog lub artykuł, który wyjaśnia to w łatwy sposób?
5 answers
Najlepszy tutorial jaki widziałem dla LSH jest w książce: Mining of Massive Datasets. Sprawdź Rozdział 3-Znajdowanie Podobnych Pozycji http://infolab.stanford.edu/ ~ ullman / mmds / ch3a. pdf
Również polecam poniższy slajd: http://www.cs.jhu.edu/%7Evandurme/papers/VanDurmeLallACL10-slides.pdf . Przykład w slajdzie bardzo mi pomaga w zrozumieniu hashowania na cosinus podobieństwa.
Pożyczam dwa slajdy z Benjamin Van Durme & Ashwin Lall, ACL2010 i spróbuj trochę wyjaśnić intuicje rodzin LSH Dla odległości cosinusa.
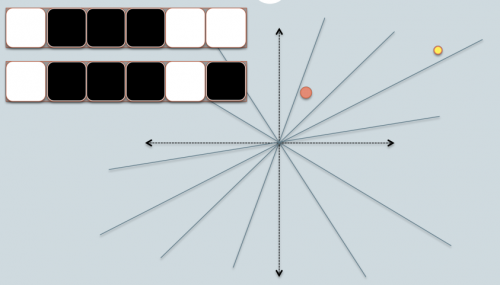
- na rysunku znajdują się dwa okręgi w/ czerwone i żółte kolorowe, reprezentujące dwa dwuwymiarowe punkty danych. Staramy się znaleźć ich cosinusowe podobieństwo używając LSH.
- szare linie są jednokrotnie losowo wybranymi płaszczyznami.
- w zależności od tego, czy punkt danych znajduje się powyżej Czy poniżej szarej linii, oznaczamy tę relację jako 0/1.
- w lewym górnym rogu znajdują się dwa rzędy białych / czarnych kwadratów, reprezentujących odpowiednio sygnaturę dwóch punktów danych. Każdy kwadrat odpowiada bitowi 0(biały) lub 1(czarny).
- więc gdy masz pulę samolotów, możesz zakodować punkty danych z ich lokalizacją odpowiadającą samolotom. Wyobraź sobie, że gdy mamy więcej płaszczyzn w Puli, różnica kątowa zakodowana w sygnaturze jest bliższa rzeczywistej różnicy. Bo tylko samoloty, które rezydują między dwoma punktami da dwie dane różnej wartości bitowej.
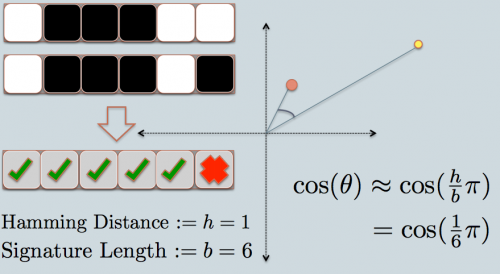
- teraz przyjrzymy się podpisowi dwóch punktów danych. Tak jak w przykładzie, używamy tylko 6 bitów(kwadratów) do reprezentowania każdej z danych. Jest to hash LSH dla oryginalnych danych, które posiadamy.
- odległość Hamminga między dwoma hashowanymi wartościami wynosi 1, ponieważ ich sygnatury różnią się tylko o 1 bit.
- biorąc pod uwagę długość podpisu, możemy obliczyć ich podobieństwo kątowe jak pokazano na wykresie.
Mam przykładowy kod (tylko 50 linii) w Pythonie, który używa cosinusowego podobieństwa. https://gist.github.com/94a3d425009be0f94751
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-10-21 07:19:58
Tweety w przestrzeni wektorowej mogą być doskonałym przykładem danych o wysokich wymiarach.
Sprawdź mój wpis na blogu na temat stosowania lokalnego wrażliwego hashowania do tweetów, aby znaleźć podobne.
Http://micvog.com/2013/09/08/storm-first-story-detection/
A ponieważ jedno zdjęcie to tysiąc słów sprawdź zdjęcie poniżej:
Http://micvog.files.wordpress.com/2013/08/lsh1.png
{kind=link}
Mam nadzieję, że to pomoże. @ mvogiatzis
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-03-24 09:24:19
Oto prezentacja ze Stanford, która to wyjaśnia. To dla mnie wielka różnica. Część druga jest bardziej o LSH, ale część pierwsza obejmuje to również.
Zdjęcie z przeglądu (jest o wiele więcej w slajdach):
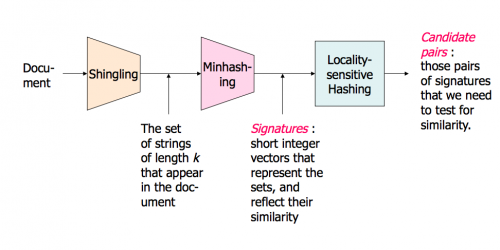
Near Neighbor Search in High Dimensional Data-Part1: http://www.stanford.edu/class/cs345a/slides/04-highdim.pdf
Near Neighbor Search in High Dimensional Data - Part2: http://www.stanford.edu/class/cs345a/slides/05-LSH.pdf
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-04-12 06:05:13
- LSH jest procedurą, która pobiera jako wejście zestaw dokumentów / obrazów / obiektów i wyprowadza rodzaj tabeli Hash.
- indeksy tej tabeli zawierają dokumenty takie, że dokumenty znajdujące się na tym samym indeksie są uważane za podobne, a te na różnych indeksach są "odmienne".
- Gdzie podobne zależy od systemu metrycznego, a także od podobieństwa progu s , który działa jak parametr globalny LSH.
- to zależy od musisz określić, jaki jest odpowiedni próg s dla Twojego problemu.

Ważne jest, aby podkreślić, że różne miary podobieństwa mają różne implementacje LSH.
Na moim blogu starałem się dokładnie wyjaśnić LSH dla przypadków minhashingu (miara podobieństwa jaccard) i simhashingu (miara odległości cosinusa). Mam nadzieję, że go znajdziesz. przydatne: https://aerodatablog.wordpress.com/2017/11/29/locality-sensitive-hashing-lsh/
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-02-06 20:53:09
Jestem osobą wizualną. Oto, co działa dla mnie jako intuicja.
Powiedz, że każda z rzeczy, których chcesz szukać, to przedmioty fizyczne, takie jak jabłko, kostka, krzesło.
Moja intuicja dla LSH jest taka, że jest podobna do brania cieni tych obiektów. Na przykład, jeśli weźmiesz Cień sześcianu 3D, otrzymasz kwadrat 2D-jak na kartce papieru, lub kula 3d da ci Cień podobny do okręgu na kartce papieru.
W końcu jest o wiele więcej niż trzy wymiary w problemie wyszukiwania (gdzie każde słowo w tekście może być jednym wymiarem), ale analogia shadow jest nadal bardzo przydatna.
Teraz możemy efektywnie porównywać ciągi bitów w oprogramowaniu. Ciąg bitowy o stałej długości jest rodzajem, mniej więcej, jak linia w jednym wymiarze.
Więc z LSH, projektuję cienie obiektów jako punkty (0 LUB 1) na pojedynczej linii/ciągu bitów o stałej długości.
Cała sztuczka polega na tym, aby wziąć cienie takie, że nadal mają sens w dolnym wymiarze, np. przypominają oryginalny obiekt w wystarczająco dobry sposób, który można rozpoznać.
Dwuwymiarowy rysunek sześcianu w perspektywie mówi mi, że jest to sześcian. Ale nie mogę łatwo odróżnić kwadratu 2D od cienia sześcianu 3D bez perspektywy: oba wyglądają jak kwadrat dla mnie.
To, jak zaprezentuję swój obiekt światłu, zadecyduje o tym, czy dostanę dobry, rozpoznawalny cień, czy nie. Więc myślę o "dobrym" LSH jako Tym, który zmieni moje obiekty przed światłem tak, że ich cień jest najlepiej rozpoznawalny jako reprezentujący mój obiekt.
Podsumowując: myślę o rzeczach do indeksowania za pomocą LSH jako obiekty fizyczne, takie jak sześcian, stół lub krzesło, a ich cienie wyświetlam w 2D, a ostatecznie wzdłuż linii (bit string). A " dobra "funkcja" LSH " polega na tym, jak prezentuję moje obiekty przed światłem, aby uzyskać w przybliżeniu rozpoznawalny kształt w 2D flatland, a później mój ciąg bitowy.
Wreszcie kiedy chcę szukać jeśli obiekt, który mam, jest podobny do niektórych obiektów, które zindeksowałem, biorę cienie tego obiektu" zapytania " za pomocą tego samego sposobu, aby przedstawić mój obiekt przed światłem(ostatecznie kończąc się z bitowym ciągiem też). A teraz mogę porównać, jak podobny jest ten ciąg bitowy ze wszystkimi innymi indeksowanymi ciągami bitowymi, który jest proxy do wyszukiwania całych moich obiektów, jeśli Znalazłem dobry i rozpoznawalny sposób prezentacji moich obiektów mojemu światłu.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-12-18 17:52:01