Oszacowanie liczby neuronów i liczby warstw sztucznej sieci neuronowej [zamkniętej]
Szukam metody, jak obliczyć liczbę warstw i liczbę neuronów na warstwę. Jako wejście mam tylko rozmiar wektora wejściowego, rozmiar wektora wyjściowego i rozmiar zestawu treningowego.
Zazwyczaj najlepsza sieć jest określana przez wypróbowanie różnych topologii sieci i wybranie tej z najmniejszym błędem. Niestety nie mogę tego zrobić.
3 answers
To naprawdę trudny problem.
Im bardziej wewnętrzna struktura ma sieć, tym lepiej, że sieć będzie reprezentować złożone rozwiązania. Z drugiej strony, zbyt duża struktura wewnętrzna jest wolniejsza, może powodować różnice w treningach lub prowadzić do nadmiernego dopasowania-co uniemożliwiłoby generalizację sieci na nowe dane.
Ludzie tradycyjnie podchodzili do tego problemu na kilka różnych sposobów:
Wypróbuj różne konfiguracje, zobacz co działa najlepiej. możesz podzielić swój zestaw treningowy na dwie części-jedną do treningu, drugą do oceny - a następnie trenować i oceniać różne podejścia. Niestety wygląda na to, że w Twoim przypadku to eksperymentalne podejście nie jest dostępne.
Użyj zasady. Wiele osób wymyślił wiele domysłów, co działa najlepiej. Jeśli chodzi o liczbę neuronów w warstwie ukrytej, ludzie spekulowali, że (na przykład) powinien (a) być pomiędzy rozmiar warstwy wejściowej i wyjściowej, (b) ustawiony na coś w pobliżu (wejścia+wyjścia) * 2/3, lub (C) nigdy nie większy niż dwa razy rozmiar warstwy wejściowej.
problem z regułami jest taki, że nie zawsze biorą pod uwagę istotne informacje, jak "trudny" jest problem, jaka jest wielkość zestawów treningowych i testowych itp. W związku z tym zasady te są często wykorzystywane jako punkt wyjścia dla "spróbujmy-kilku-rzeczy-i-zobacz-co-działa-najlepiej" podejście.Użyj algorytmu, który dynamicznie dostosowuje konfigurację sieci. algorytmy takie jak korelacja kaskadowa zaczynają się od minimalnej sieci, a następnie dodają Ukryte węzły podczas treningu. Może to sprawić, że Twoja konfiguracja eksperymentalna będzie nieco prostsza i (teoretycznie) może skutkować lepszą wydajnością (ponieważ nie użyjesz przypadkowo niewłaściwej liczby ukrytych węzłów).
Jest dużo badań na ten temat, więc jeśli jesteś naprawdę zainteresowany, jest wiele do przeczytania. Zobacz cytaty na tym podsumowaniu , w szczególności:
Lawrence, S., Giles, C. L. i Tsoi, A. C. (1996), "jaką wielkość sieci neuronowej daje optymalne uogólnienie? Własności zbieżności odwrotności " . raport techniczny UMIACS-tr-96-22 i CS-TR-3617, Institute for Advanced Computer Studies, University of Maryland, College Park.
Elisseeff, A., and Paugam-Moisy, H. (1997), "Rozmiar wielowarstwowych sieci do dokładnego uczenia się: podejście analityczne" . [19]}Advances in Neural Information Processing Systems 9, Cambridge, MA: the MIT Press, pp. 162-168.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2010-07-27 16:30:25
W praktyce nie jest to trudne(bazując na zakodowaniu i przeszkoleniu kilkudziesięciu MlP).
W sensie podręcznikowym, uzyskanie "właściwej" architektury jest trudne-tzn. dostrojenie architektury sieciowej tak, aby wydajność (rozdzielczość) nie mogła być poprawiona przez dalszą optymalizację architektury jest trudne, zgadzam się. Ale tylko w rzadkich przypadkach wymagany jest taki stopień optymalizacji.
W praktyce, aby spełnić lub przekroczyć dokładność predykcji z sieci neuronowej wymaganej przez spec, prawie nigdy nie trzeba spędzać dużo czasu z architekturą sieci-trzy powody, dla których jest to prawdą:
większość parametrów wymaganych do określenia architektury sieci są fixe d, gdy zdecydujesz się na swój model danych (liczba funkcje w wektorze wejściowym, czy żądana zmienna odpowiedzi jest liczbowa lub kategoryczna, a jeśli ta ostatnia, to ile unikalnych klas etykiety, które wybrałeś);
-
Nieliczni pozostali parametry architektury, które są w rzeczywistości przestrajalne, są prawie zawsze (100% czasu z mojego doświadczenia) mocno ograniczone przez te stałe architektury parametry--tzn. wartości tych parametrów są ściśle ograniczone przez wartość max i Min oraz
Optymalna Architektura nie musi być określona przed rozpoczyna się szkolenie, rzeczywiście, bardzo często kod sieci neuronowej do Dołącz mały moduł do programowego dostrajania sieci Architektura podczas treningu (poprzez usunięcie węzłów, których wartości wagowe zbliżają się do zera-zwykle nazywane " przycinanie .")
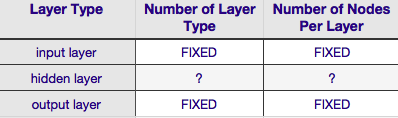
Zgodnie z powyższą tabelą architektura sieci neuronowej jest całkowicie określona przez sześć parametry (Sześć komórek w wewnętrznej siatce). Dwie z nich (liczba typów warstw dla warstwy wejściowej i wyjściowej) to zawsze jedna i jedna-sieci neuronowe mają pojedynczą warstwę wejściową i pojedynczą warstwę wyjściową. Twój NN musi mieć co najmniej jedną warstwę wejściową i jedną warstwę wyjściową-nie więcej, nie mniej. Po drugie, liczba węzłów składających się z każdej z tych dwóch warstw jest stała-warstwa wejściowa, przez rozmiar wektora wejściowego-tzn. Liczba węzłów w warstwie wejściowej jest równa długości wektora wejściowego(w rzeczywistości jeden więcej neuronów jest prawie zawsze dodawany do warstwy wejściowej jako węzeł bias {10]}).
Podobnie rozmiar warstwy wyjściowej jest ustalany przez zmienną odpowiedzi (pojedynczy węzeł dla odpowiedzi numerycznej zmienna, and (zakładając, że używany jest softmax, jeśli zmienna odpowiedzi jest etykietą klasy, Liczba węzłów w warstwie wyjściowej jest po prostu równa liczbie unikalnych etykiet klasy).
To pozostawia tylko dwa parametry, dla których istnieje Dowolna dowolność -- liczba ukrytych warstw i liczba węzłów składających się na każdą z tych warstw.
Liczba ukrytych warstw
Jeśli Twoje dane są rozdzielne liniowo (o czym często wiesz przed rozpocznij kodowanie NN) wtedy nie potrzebujesz żadnych ukrytych warstw. (Jeśli tak jest w rzeczywistości, nie użyłbym NN do tego problemu-wybierz prostszy klasyfikator liniowy). Pierwsza z nich-liczba ukrytych warstw-jest prawie zawsze jedna. Za tym założeniem kryje się dużo empirycznej wagi-w praktyce bardzo niewiele problemów, których nie da się rozwiązać za pomocą pojedynczej warstwy ukrytej, rozpuszcza się poprzez dodanie kolejnej warstwy ukrytej. Podobnie, istnieje konsensus jest różnica wydajności z dodawanie dodatkowych warstw ukrytych: sytuacje, w których wydajność poprawia się z drugą (lub trzecią, itp.) ukryta warstwa jest bardzo mała. Jedna ukryta warstwa jest wystarczająca dla większości problemów.
W twoim pytaniu wspomniałeś, że z jakiegokolwiek powodu nie możesz znaleźć optymalnej architektury sieci metodą prób i błędów. Innym sposobem dostrojenia konfiguracji NN (bez użycia prób i błędów) jest ' przycinanie '. Istotą tej techniki jest usunięcie węzłów z sieci podczas szkolenia, identyfikując te węzły, które w przypadku usunięcia z sieci nie wpłynęłyby zauważalnie na wydajność sieci (np. rozdzielczość danych). (Nawet bez użycia formalnej techniki przycinania, możesz uzyskać przybliżony obraz, które węzły nie są ważne, patrząc na swoją matrycę wagi po treningu; Szukaj ciężarów bardzo blisko zera-to węzły na obu końcach tych ciężarów, które są często usuwane podczas przycinania.) Oczywiście, jeśli użyjesz algorytmu przycinania podczas szkolenie rozpoczyna się od konfiguracji sieci, która jest bardziej narażona na nadmiar (np. "przycinanie") węzłów-innymi słowy, decydując się na architekturę sieci, błądzi po stronie większej liczby neuronów, jeśli dodasz krok przycinania.
Mówiąc inaczej, stosując algorytm przycinania do swojej sieci podczas treningu, możesz znacznie bliżej zoptymalizowanej konfiguracji sieci niż jakakolwiek teoria a priori.
Liczba węzłów składających się na Ukryte Warstwa
Ale co z liczbą węzłów składających się na ukrytą warstwę? Wartość ta jest mniej lub bardziej nieograniczona-tzn. może być mniejsza lub większa niż rozmiar warstwy wejściowej. Poza tym, jak zapewne wiesz, istnieje Góra komentarzy na temat konfiguracji ukrytych warstw w NNs(zobacz słynny NN FAQ dla doskonałego podsumowania tego komentarza). Istnieje wiele empirycznie wyprowadzonych reguł, ale z nich najczęściej opartymi są rozmiar ukrytej warstwy znajduje się pomiędzy warstwą wejściową i wyjściową. Jeff Heaton, autor "Introduction to Neural Networks in Java " oferuje kilka innych, które są recytowane na stronie, którą właśnie podlinkowałem. Podobnie, skan literatury sieci neuronowych zorientowanych na aplikacje prawie na pewno ujawni, że ukryty rozmiar warstwy jest zwykle pomiędzy rozmiarami warstwy wejściowej i wyjściowej. Ale pomiędzy nie oznacza w środku; w rzeczywistości jest zwykle lepiej ustawić rozmiar ukrytej warstwy bliżej wielkości wektora wejściowego. Powodem jest to, że jeśli ukryta warstwa jest zbyt mała, sieć może mieć trudności ze zbieżnością. W przypadku początkowej konfiguracji, błąd przy większym rozmiarze-większa ukryta warstwa daje sieci większą pojemność, co pomaga jej się zbliżyć, w porównaniu z mniejszą warstwą ukrytą. Rzeczywiście, to uzasadnienie jest często używane, aby zalecić Ukryty rozmiar warstwy większy niż (więcej węzłów)warstwa wejściowa -- czyli zaczyna się od wstępna architektura, która zachęci do szybkiej konwergencji, po której można przyciąć "nadmiarowe" węzły (zidentyfikować węzły w ukrytej warstwie o bardzo niskich wartościach wagi i wyeliminować je z odnowionej sieci).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-07-15 13:42:30
Użyłem MLP dla komercyjnego oprogramowania, które ma tylko jedną ukrytą warstwę, która ma tylko jeden węzeł. Ponieważ węzły wejściowe i wyjściowe są stałe, musiałem tylko zmienić liczbę ukrytych warstw i pobawić się uzyskanym uogólnieniem. Nigdy tak naprawdę nie miałem wielkiej różnicy w tym, co osiągnąłem z tylko jedną ukrytą warstwą i jednym węzłem, zmieniając liczbę ukrytych warstw. Użyłem tylko jednej ukrytej warstwy z jednym węzłem. Działało całkiem dobrze, a także zredukowane obliczenia były bardzo kuszące w moim założeniu oprogramowania.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-09-10 14:11:57