Co to jest krzywa uczenia się w uczeniu maszynowym?
Chcę wiedzieć, czym jest krzywa uczenia się w uczeniu maszynowym. Jaki jest standardowy sposób kreślenia? Jaka powinna być oś x i y mojego wykresu?
7 answers
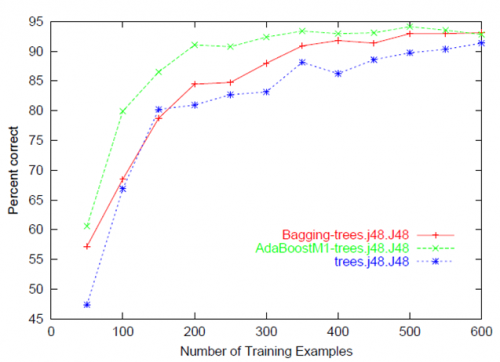
Myślę, że zwykle odnosi się do wykresu dokładność przewidywania / błąd vs. rozmiar zestawu treningowego (tj.]}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-01-07 02:45:49
Chcę tylko zostawić krótką notatkę na to stare pytanie, aby podkreślić, że learning curve i Roc curve nie są synonimami.
Jak wskazano w innych odpowiedziach na to pytanie, krzywa uczenia się konwencjonalnie przedstawia poprawę wydajności na osi pionowej, gdy występują zmiany w innym parametrze (na osi poziomej), takie jak rozmiar zestawu treningowego (w uczeniu maszynowym) lub iteracja/czas (zarówno w uczeniu maszynowym, jak i biologicznym). One salient chodzi o to, że wiele parametrów modelu zmienia się w różnych punktach na wykresie. Inne odpowiedzi tutaj wykonały świetną robotę ilustrując krzywe uczenia się.
(istnieje również inne znaczenie krzywej uczenia się w produkcji przemysłowej, pochodzące z obserwacji w 1930 roku, że liczba godzin pracy potrzebnych do wytworzenia pojedynczej jednostki maleje w jednolitym tempie, ponieważ ilość wyprodukowanych jednostek podwaja się. Nie jest to do końca istotne, ale warto zwrócić uwagę na kompletności i aby uniknąć nieporozumień w wyszukiwarkach internetowych.)
Natomiast Krzywa charakterystyczna pracy odbiornika , lub krzywa ROC , nie pokazuje uczenia się; pokazuje wydajność. Krzywa ROC jest graficznym przedstawieniem wyników klasyfikatora, który pokazuje kompromis między wzrostem rzeczywistych wskaźników dodatnich (na osi pionowej) i wzrostem wskaźników fałszywie dodatnich (na osi poziomej), ponieważ próg dyskryminacji klasyfikatora jest zróżnicowany. Tak więc tylko jeden parametr (próg decyzji / dyskryminacji) związany z modelem zmienia się w różnych punktach na wykresie. Ta krzywa ROC (z Wikipedii) pokazuje wydajność trzech różnych klasyfikatorów.
{kind=link}
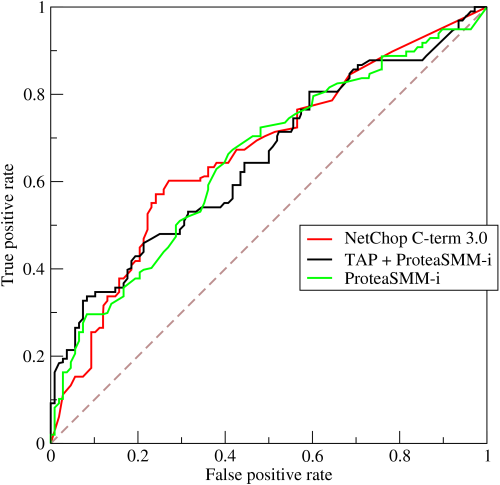
Nie przedstawiono tu nauki, ale raczej wyniki w odniesieniu do dwóch różnych klas sukcesu/błędu, ponieważ próg decyzyjny klasyfikatora jest łagodniejszy/surowy. Patrząc na obszar pod krzywą, możemy zobaczyć ogólny wskazanie zdolności klasyfikatora do rozróżniania klas. Ta metryka obszaru pod krzywą jest niewrażliwa na liczbę członków w dwóch klasach, więc może nie odzwierciedlać rzeczywistej wydajności, jeśli członkostwo w klasie jest niezrównoważone. Krzywa ROC ma wiele napisów i zainteresowani czytelnicy mogą sprawdzić:
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-12-05 02:14:52
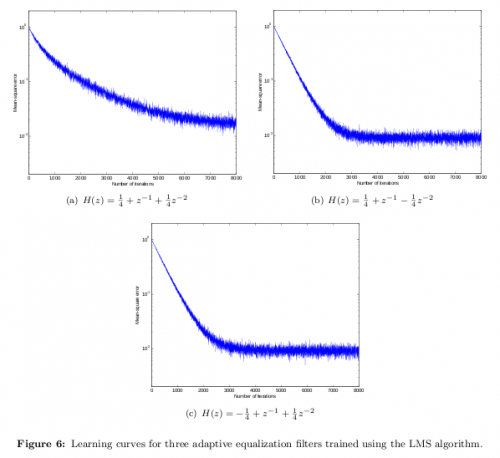
Niektórzy używają "krzywej uczenia się", aby odnieść się do błędu procedury iteracyjnej jako funkcji liczby iteracji, tzn. ilustruje zbieżność pewnej funkcji użytkowej. W poniższym przykładzie wykreśliłem błąd mean-square (MSE) algorytmu least-mean-square (LMS) jako funkcję liczby iteracji. To ilustruje, jak szybko LMS "uczy się", w tym przypadku, impulsowej odpowiedzi kanału.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-01-07 00:21:40
Zasadniczo, krzywa uczenia maszynowego pozwala znaleźć punkt, od którego algorytm zaczyna się uczyć. Jeśli weźmiesz krzywą, a następnie pokroisz styczną nachylenia dla pochodnej w punkcie, w którym zaczyna osiągać stałą, to zaczyna budować swoją zdolność uczenia się.
W zależności od sposobu odwzorowania osi x i y, jedna z osi zacznie zbliżać się do stałej wartości, podczas gdy wartości drugiej osi będą rosły. To wtedy zaczynasz się uczyć. Na Cała krzywa w dużej mierze pozwala zmierzyć szybkość, z jaką algorytm jest w stanie się nauczyć. Punkt maksymalny jest zwykle wtedy, gdy nachylenie zaczyna się cofać. Można zastosować szereg miar pochodnych do punktu maksymalnego/minimalnego.
Więc z powyższych przykładów widać, że krzywa stopniowo zmierza w kierunku stałej wartości. Początkowo zaczyna wykorzystywać swoją naukę poprzez przykłady treningowe, a nachylenie rozszerza się w punkcie maksymalnym / mimimum, w którym ma tendencję do zbliżania się coraz bliżej do stanu stałego. W tym momencie jest w stanie odebrać nowe przykłady z danych testowych i znaleźć nowe i unikalne wyniki z danych. Miałbyś takie miary osi X / y dla epok vs błąd.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-05-29 22:43:47
Jak można określić dla danego modelu, czy więcej punktów treningowych będzie pomocnych? Przydatną diagnostyką są krzywe uczenia się.
* Wykres dokładności przewidywania / błędu a rozmiar zestawu treningowego (tj.: jak lepiej model uzyskuje przewidywanie celu, gdy zwiększa się liczba instancji używanych do jego treningu)
* krzywa uczenia konwencjonalnie przedstawia poprawę wydajności na osi pionowej, gdy występują zmiany w innym parametrze (na pozioma oś), takie jak rozmiar zestawu treningowego (w uczeniu maszynowym) lub iteracja/czas
• krzywa uczenia się jest często przydatna do wykreślenia algorytmicznego sprawdzania rozsądku lub poprawy wydajności
• Nauka wykreślania krzywej może pomóc zdiagnozować problemy, z którymi będzie borykał się twój algorytm
Osobiście dwa poniższe linki pomogły mi lepiej zrozumieć tę koncepcję
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-06-14 21:19:09
W klasie Andrew ' s machine learning krzywa uczenia się jest wykresem błędu szkolenia/weryfikacji krzyżowej w porównaniu z wielkością próby. Krzywa uczenia może być używana do wykrywania, czy model ma wysokie odchylenie lub wysoką wariancję. Jeśli model cierpi z powodu wysokiego błędu stronniczości, wraz ze wzrostem wielkości próby, błąd szkolenia wzrośnie, a błąd weryfikacji krzyżowej zmniejszy się, a w końcu będą one bardzo blisko siebie, ale nadal z wysokim poziomem błędu zarówno dla szkolenia, jak i klasyfikacji błąd. A zwiększenie wielkości próby nie pomoże wiele dla problemu wysokiego odchylenia.
Jeśli model cierpi na wysoką wariancję, ponieważ stale zwiększa się wielkość próby, błąd szkolenia będzie stale wzrastał, a błąd weryfikacji krzyżowej będzie malał, a skończy się na niskim poziomie błędu szkolenia i weryfikacji krzyżowej. Tak więc więcej próbek pomoże poprawić wydajność przewidywania modelu, jeśli model cierpi z powodu wysokiej wariancji.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-06-22 18:30:16
Przykład X = Poziom y = pensja
X Y 0 2000 2 4000 4 6000 6 8000
Regresja daje dokładność 75% jest to linia stanu
wielomian daje dokładność 85% ze względu na krzywą
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-06-14 05:29:26