Jak sprawić, by organizmy wirtualne uczyły się za pomocą sieci neuronowych? [zamknięte]
Robię prostą symulację uczenia się, gdzie na ekranie Jest wiele organizmów. Powinni nauczyć się jeść, używając prostych sieci neuronowych. Mają 4 neurony, a każdy neuron aktywuje ruch w jednym kierunku (jest to płaszczyzna 2D oglądana z perspektywy ptaka, więc są tylko cztery kierunki, dlatego wymagane są cztery wyjścia). Ich jedynym wkładem są cztery "oczy". Tylko jedno oko może być aktywne w tym czasie i zasadniczo służy jako wskaźnik do najbliższego obiektu (albo zielony blok żywności, lub inny organizm).
Tak więc sieć można sobie wyobrazić tak:
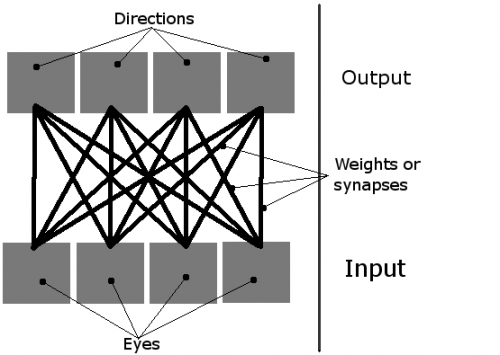
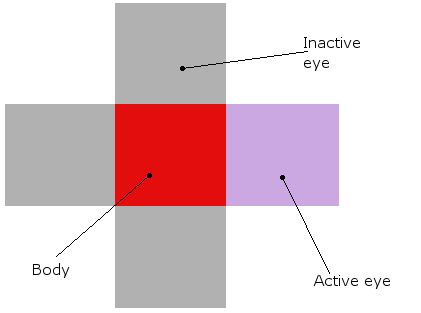
A organizm wygląda tak (zarówno w teorii, jak i w rzeczywistej symulacji, gdzie naprawdę są czerwonymi klockami z oczami wokół nich):
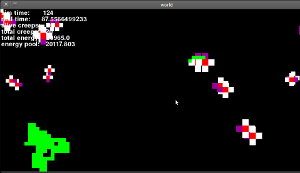
I tak to wszystko wygląda (to stara wersja, gdzie oczy nadal nie działały, ale jest podobnie):
Teraz, gdy opisałem moją ogólną ideę, pozwól mi dotrzeć do serca problem...
Inicjalizacja | Po pierwsze, tworzę pewne organizmy i jedzenie. Następnie wszystkie 16 wag w ich sieciach neuronowych są ustawione na wartości losowe, jak to: weight = random.random () * threshold * 2. Threshold jest globalną wartością, która opisuje, jak wiele danych wejściowych musi uzyskać każdy neuron, aby aktywować ("ogień"). Zwykle jest ustawiony na 1.
Nauka | Domyślnie wagi w sieciach neuronowych są obniżane o 1% na każdym kroku. Ale jeśli jakiś organizm rzeczywiście udaje się coś zjeść, połączenie między ostatnim aktywnym wejściem i wyjściem jest wzmocnione.
Ale jest duży problem. Myślę, że to nie jest dobre podejście, ponieważ tak naprawdę niczego się nie uczą! Tylko ci, którzy mieli swoje początkowe ciężary losowo ustawione na korzystne, będą mieli szansę coś zjeść, a wtedy tylko oni będą mieli swoje ciężary wzmocnione! A co z tymi, którzy mieli źle skonfigurowane kontakty? Oni po prostu umieraj, nie ucz się.
Jak tego uniknąć? Jedyne rozwiązanie, które przychodzi na myśl, to losowo zwiększyć / zmniejszyć wagi, tak, że w końcu ktoś dostanie odpowiednią konfigurację, i zjeść coś przez przypadek. Ale uważam to rozwiązanie za bardzo prymitywne i brzydkie. Masz jakieś pomysły?
EDIT: Dziękuję za odpowiedzi! Każdy z nich był bardzo przydatny, niektóre były po prostu bardziej istotne. Postanowiłem zastosować następujące podejście:
- Ustaw wszystkie wagi do liczb losowych.
- zmniejszyć wagę w czasie.
- czasami losowo zwiększyć lub zmniejszyć wagę. Im bardziej udana jest jednostka, tym mniej zmienia się jej waga. Nowy
- kiedy organizm coś zje, zwiększ wagę między odpowiednim wejściem a wyjściem.
6 answers
Jest to podobne do problemów z próbą znalezienia globalnego minimum, gdzie łatwo jest utknąć w lokalnym minimum. Rozważ znalezienie globalnego minimum dla poniższego profilu: umieszczasz piłkę w różnych miejscach i podążasz za nią w dół wzgórza do minimum, ale w zależności od tego, gdzie ją umieścisz, możesz utknąć w lokalnym zanurzeniu.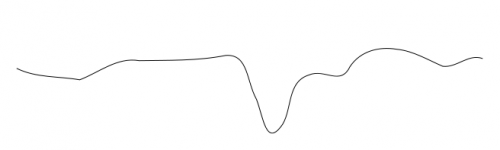
Oznacza to, że w skomplikowanych sytuacjach nie zawsze można dostać się do najlepszego rozwiązania ze wszystkich punktów wyjścia za pomocą małych optymalizacja przyrostów. ogólne rozwiązania tego są wahania parametrów ( to znaczy , wagi, w tym przypadku) bardziej energicznie (i zwykle zmniejszyć rozmiar wahań w miarę postępów symulacji-jak w symulowanym wyżarzaniu), lub po prostu uświadomić sobie, że kilka punktów początkowych nie pójdzie nigdzie interesujące.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-01-25 18:00:48
Jak wspomniał Mika Fischer, brzmi to podobnie do sztucznych problemów życiowych, więc to jedna z dróg, na którą można spojrzeć.
Brzmi to trochę tak, jakbyś próbował na nowo odkryć Wzmocnienie uczenia się . Polecam lekturę Reinforcement Learning: an Introduction, która jest bezpłatnie dostępna w formie HTML na tej stronie, lub do kupienia w formacie dead tree. Przykładowy kod i rozwiązania są również dostępne na tej stronie.
Wykorzystanie sieci neuronowych (i inne aproksymatory funkcji) i techniki planowania są omówione w dalszej części książki, więc nie zniechęcaj się, jeśli początkowe rzeczy wydają się zbyt podstawowe lub nie dotyczy Twojego problemu.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-01-25 17:44:19
Jak chcesz się tego nauczyć? Nie podoba Ci się fakt, że losowo zasiane organizmy albo umierają lub prosperują, ale jedynym czasem, gdy przekazujesz informacje zwrotne do swojego organizmu, jest to, czy losowo otrzymują jedzenie.
Modelujmy to jako gorące i zimne. Obecnie wszystko odżywia się "na zimno", z wyjątkiem sytuacji, gdy organizm znajduje się tuż nad jedzeniem. Więc jedyną okazją do nauki jest przypadkowe rozjechanie po jedzeniu. Możesz dokręcić tę pętlę, aby zapewnić bardziej ciągłą informację zwrotną, jeśli chcesz. Informacje zwrotne cieplej, jeśli jest ruch w kierunku jedzenia, zimno, jeśli odejdzie.
Minusem tego jest to, że nie ma wejścia dla niczego innego. Masz tylko technikę uczenia się poszukującego jedzenia. Jeśli chcesz, aby Twoje organizmy znalazły równowagę między głodem a czymś innym (np. unikaniem przeludnienia, kojarzeniami itp.), cały mechanizm prawdopodobnie wymaga ponownego przemyślenia.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-01-25 18:03:26
Istnieje kilka algorytmów, które można wykorzystać do optymalizacji wag w sieci neuronowej, z których najczęstszym jest algorytm backropogacji.
Z lektury twojego pytania wnioskuję, że próbujesz zbudować boty sieci neuronowych, które będą szukać jedzenia. Sposobem na osiągnięcie tego z backpropogation byłoby mieć początkowy okres nauki, gdzie wagi są początkowo losowo ustawiane (jak robisz) i stopniowo udoskonalane za pomocą backropogation algorytm, aż osiągną poziom wydajności, z którego jesteś zadowolony. W tym momencie możesz powstrzymać ich naukę i pozwolić im swobodnie igrać w flatland.
Jednak myślę, że może być kilka problemów z projektowaniem sieci. Po pierwsze, jeśli w dowolnym momencie jest aktywne tylko 1 oko, bardziej sensowne byłoby posiadanie tylko jednego węzła wejściowego i śledzenie orientacji w inny sposób (jeśli dobrze to Rozumiem). Po prostu, jeśli jest tylko jedno aktywne oko i cztery możliwe działania (do przodu, back, left, right) wtedy wejścia z nieaktywnych oczu (przypuszczalnie zero) nie będą miały wpływu na decyzję wyjścia, w rzeczywistości podejrzewam, że wagi dla każdego wejścia do wszystkich wyjść zbiegłyby się, zasadniczo powielając tę samą funkcję. Co więcej, niepotrzebnie zwiększa złożoność sieci i wydłuża czas uczenia się. Po drugie, nie potrzebujesz tak wielu neuronów wyjściowych, aby reprezentować wszystkie możliwe działania. Tak jak to tam opisałeś, Twój wynik będzie {1,0,0,0} = prawo, / Align = "left" / W zależności od typu neuronu modelowanego, można to zrobić za pomocą 2 lub nawet 1 neuronu wyjściowego. Jeśli używasz neuronu binarnego (każde wyjście jest 1 lub 0), zrób coś w stylu {0,0} = do tyłu, {1,1} = do przodu, {1,0} = W lewo, {0,1} = w prawo. Za pomocą funkcji sigmoidalnej neuron (wyjście może być liczbą rzeczywistą od 0..1), można zrobić {0} = back, {0.33} = left, {0.66} = right, {1} = forward.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-01-25 18:13:16
Widzę kilka potencjalnych problemów.
Po pierwsze i najważniejsze, nie jestem jasny co do algorytmu, który aktualizuje Twoje wagi. Podoba mi się obniżka o 1% jako koncepcja. wygląda na to, że próbujesz zdyskontować odległe wspomnienia, co w zasadzie jest dobre. ale reszta pewnie nie wystarczy. Musisz przyjrzeć się niektórym standardowym algorytmom aktualizacji, takim jak backpropagation, ale to dopiero początek, ponieważ....
...Przyznajesz kredyt swojej sieci tylko na ostatni etap jedzenia jedzenia. Wydaje się, że nie ma żadnego bezpośredniego mechanizmu, aby Twoja sieć stopniowo zbliżała się do jedzenia lub grudek jedzenia. Nawet biorąc kierunkowość oczu na wartość nominalną, twoje oczy są bardzo proste i nie ma zbyt wiele pamięci długotrwałej.
Również, jeśli twój diagram sieciowy jest dokładny, prawdopodobnie nie jest wystarczający. Naprawdę chcesz mieć ukrytą warstwę (przynajmniej jedną) między czujnikami a siłownikami, jeśli używasz czegoś związanego z backpropagation. Za tym stwierdzeniem kryje się szczegółowa matematyka, ale sprowadza się ona do tego, że " ukryte warstwy pozwolą na dobre rozwiązanie większej liczby problemów."
Zauważ, że wiele moich komentarzy mówi o architekturze sieci, ale tylko w kategoriach ogólnych, nie mówiąc konkretnie: "to zadziała" lub " to zadziała."To dlatego, że ja też nie wiem (chociaż myślę, że sugestia Kwatforda dotycząca uczenia się przez wzmocnienie jest bardzo dobra.) Czasami można ewoluuj parametry sieci, jak również instancje sieciowe. Jedną z takich technik jest Neuroewolucja topologii rozszerzających, czyli "schludna". Może warto zajrzeć.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-01-25 19:56:39
Myślę, że bardziej złożony przykład tego, co robisz, przedstawia Polyworld .
Możesz również zobaczyć prezentację Google Tech Talks z 2007 roku: http://www.youtube.com/watch?v=_m97_kL4ox0
Jednak podstawową ideą jest przyjęcie podejścia ewolucyjnego w Twoim systemie: użyj małych losowych mutacji w połączeniu z genetycznym cross-over (jako główną formę dywersyfikacji) i wybierz osoby, które są "lepiej" przystosowane do przetrwania środowisko.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-01-25 18:26:36