Problem w szkoleniu Ukryty model markowa i zastosowanie do klasyfikacji
Mam problemy z wymyśleniem, jak korzystać z Kevina Murphy ' ego HMM toolbox Toolbox . Byłoby to bardzo pomocne, gdyby ktoś, kto ma doświadczenie z nim może wyjaśnić pewne koncepcyjne pytania. Jakoś zrozumiałem teorię stojącą za HMM, ale to jest mylące, jak ją wdrożyć i wspomnieć o wszystkich parametrach.
Są 2 klasy, więc potrzebujemy 2 HMMs.
Załóżmy, że wektory treningowe to: class1 O1={ 4 3 5 1 2} I class O_2={ 1 4 3 2 4}.
Teraz system musi sklasyfikować nieznaną sekwencję O3 = {1 3 2 4 4} jako class1 lub class2.
- co będzie w obsmat0 i obsmat1?
- Jak określić / składnię prawdopodobieństwa przejścia transmat0 i transmat1?
- jakie będą zmienne dane w tym przypadku?
- czy liczba stanów Q=5 skoro jest pięć unikalnych liczb/symboli?
- liczba symboli wyjściowych = 5 ?
- Jak wspomnę o prawdopodobieństwie przejścia transmat0 i transmat1?
2 answers
Zamiast odpowiadać na każde indywidualne pytanie, pozwól mi zilustrować, jak używać HMM toolbox z przykładem -- weather example , który jest zwykle używany przy wprowadzaniu ukrytych modeli Markowa.
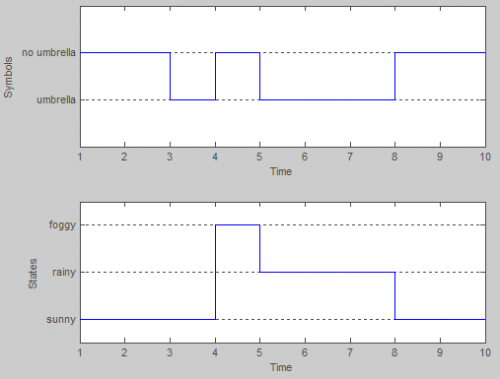
Zasadniczo Stany modelu to trzy możliwe rodzaje pogody: słoneczna, deszczowa i mglista. W danym dniu Zakładamy, że pogoda może być tylko jedną z tych wartości. Tak więc zbiór stanów HMM to:
S = {sunny, rainy, foggy}
Jednak w tym przykładzie nie możemy obserwuj pogodę bezpośrednio (najwyraźniej jesteśmy zamknięci w piwnicy!). Zamiast tego jedynym dowodem, jaki mamy, jest to, czy osoba, która codziennie Cię sprawdza, nosi parasol, czy nie. W terminologii HMM są to dyskretne obserwacje:
x = {umbrella, no umbrella}
Model HMM charakteryzuje się trzema rzeczami:
- prawdopodobieństwo wcześniejsze: wektor prawdopodobieństwa bycia w pierwszym stanie sekwencji.
- prob przejścia: macierz opisująca prawdopodobieństwo przechodzenie z jednego stanu pogody do drugiego.
- prob emisji: macierz opisująca prawdopodobieństwo obserwacji wyjścia (parasol lub nie) ze względu na stan (pogodę).
Następnie otrzymujemy albo te prawdopodobieństwa, albo musimy nauczyć się ich z zestawu treningowego. Gdy to zrobimy, możemy wykonać rozumowanie, takie jak obliczanie prawdopodobieństwa sekwencji obserwacji w odniesieniu do modelu HMM (lub kilku modeli i wybrać najbardziej prawdopodobny)...
1) znany model parametry
Oto przykładowy kod, który pokazuje, jak wypełnić istniejące prawdopodobieństwa, aby zbudować model:
Q = 3; %# number of states (sun,rain,fog)
O = 2; %# number of discrete observations (umbrella, no umbrella)
%# prior probabilities
prior = [1 0 0];
%# state transition matrix (1: sun, 2: rain, 3:fog)
A = [0.8 0.05 0.15; 0.2 0.6 0.2; 0.2 0.3 0.5];
%# observation emission matrix (1: umbrella, 2: no umbrella)
B = [0.1 0.9; 0.8 0.2; 0.3 0.7];
Następnie możemy wypróbować kilka sekwencji z tego modelu:
num = 20; %# 20 sequences
T = 10; %# each of length 10 (days)
[seqs,states] = dhmm_sample(prior, A, B, num, T);
Na przykład piąty przykład brzmiał:
>> seqs(5,:) %# observation sequence
ans =
2 2 1 2 1 1 1 2 2 2
>> states(5,:) %# hidden states sequence
ans =
1 1 1 3 2 2 2 1 1 1
Możemy ocenić prawdopodobieństwo logowania sekwencji:
dhmm_logprob(seqs(5,:), prior, A, B)
dhmm_logprob_path(prior, A, B, states(5,:))
Lub obliczyć ścieżkę Viterbiego (najbardziej prawdopodobny ciąg stanu):
vPath = viterbi_path(prior, A, multinomial_prob(seqs(5,:),B))
2) nieznane parametry modelu
Szkolenie odbywa się za pomocą algorytmu EM, a najlepiej zrobić to za pomocą zestawu sekwencji obserwacji.
Kontynuując ten sam przykład, możemy użyć wygenerowanych danych powyżej, aby wytrenować nowy model i porównać go z oryginalnym:
%# we start with a randomly initialized model
prior_hat = normalise(rand(Q,1));
A_hat = mk_stochastic(rand(Q,Q));
B_hat = mk_stochastic(rand(Q,O));
%# learn from data by performing many iterations of EM
[LL,prior_hat,A_hat,B_hat] = dhmm_em(seqs, prior_hat,A_hat,B_hat, 'max_iter',50);
%# plot learning curve
plot(LL), xlabel('iterations'), ylabel('log likelihood'), grid on
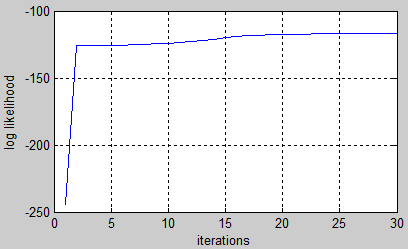
Pamiętaj, że porządek Stanów nie musi się zgadzać. Dlatego musimy permutować Stany przed porównaniem obu modeli. W tym przykładzie trenowany model wygląda blisko oryginału:
>> p = [2 3 1]; %# states permutation
>> prior, prior_hat(p)
prior =
1 0 0
ans =
0.97401
7.5499e-005
0.02591
>> A, A_hat(p,p)
A =
0.8 0.05 0.15
0.2 0.6 0.2
0.2 0.3 0.5
ans =
0.75967 0.05898 0.18135
0.037482 0.77118 0.19134
0.22003 0.53381 0.24616
>> B, B_hat(p,[1 2])
B =
0.1 0.9
0.8 0.2
0.3 0.7
ans =
0.11237 0.88763
0.72839 0.27161
0.25889 0.74111
Są więcej rzeczy, które możesz zrobić z ukrytymi modelami Markowa, takimi jak klasyfikacja lub rozpoznawanie wzorców. Będziesz miał różne zestawy sekwencji oberwania należących do różnych klas. Zaczynasz od treningu modelu dla każdego zestawu. Następnie, biorąc pod uwagę nową sekwencję obserwacji, można go sklasyfikować, obliczając jego Prawdopodobieństwo w odniesieniu do każdego modelu i przewidzieć model z największym prawdopodobieństwem logowania.
argmax[ log P(X|model_i) ] over all model_i
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-03-18 00:10:00
Nie używam toolboxa, o którym wspominasz, ale używam HTK. Istnieje książka, która bardzo wyraźnie opisuje funkcję HTK, dostępna za darmo
Http://htk.eng.cam.ac.uk/docs/docs.shtml
Rozdziały wprowadzające mogą pomóc ci zrozumieć.
Mogę mieć szybką próbę odpowiedzi na #4 na twojej liście. . . Liczba stanów emisyjnych jest związana z długością i złożonością wektorów funkcji. Jednak z pewnością nie musi równać się długość tablicy wektorów cech, ponieważ każdy stan emisyjny może mieć prawdopodobieństwo przejścia z powrotem do siebie lub nawet do poprzedniego stanu w zależności od architektury. Nie jestem również pewien, czy wartość, którą podajesz, obejmuje stany nie emitujące na początku i na końcu hmm, ale należy je również wziąć pod uwagę. Wybór liczby stanów często sprowadza się do prób i błędów.
Powodzenia!
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-03-16 18:52:25