Proste wyjaśnienie naiwnej klasyfikacji Bayesa
Trudno mi zrozumieć proces naiwnego Bayesa i zastanawiałem się, czy ktoś mógłby to wyjaśnić prostym procesem krok po kroku po angielsku. Rozumiem, że bierze porównania przez razy wystąpił jako Prawdopodobieństwo, ale nie mam pojęcia, jak dane treningowe jest związane z rzeczywistym zestawem danych.
Proszę o wyjaśnienie, jaką rolę odgrywa zestaw treningowy. Podaję tutaj bardzo prosty przykład dla owoców, np. banana
training set---
round-red
round-orange
oblong-yellow
round-red
dataset----
round-red
round-orange
round-red
round-orange
oblong-yellow
round-red
round-orange
oblong-yellow
oblong-yellow
round-red
5 answers
Twoje pytanie, jak rozumiem, jest podzielone na dwie części. Jednym z nich jest to, że potrzebujesz więcej zrozumienia dla naiwnego klasyfikatora Bayesa , a drugim jest zamieszanie wokół zestawu treningowego.
Ogólnie rzecz biorąc, wszystkie algorytmy uczenia maszynowego muszą być przeszkolone do nadzorowanych zadań edukacyjnych, takich jak klasyfikacja, przewidywanie itp. lub dla nienadzorowanych zadań edukacyjnych, takich jak grupowanie.
Przez szkolenie oznacza szkolenie ich na konkretnych wejściach, abyśmy później mogli przetestować je pod kątem nieznanych dane wejściowe (których nigdy wcześniej nie widzieli), dla których mogą klasyfikować lub przewidywać itp. (w przypadku uczenia nadzorowanego) na podstawie ich uczenia się. To właśnie większość technik uczenia maszynowego, takich jak sieci neuronowe, SVM, bayesowskie itp. są oparte na.
Tak więc w ogólnym projekcie uczenia maszynowego zasadniczo musisz podzielić swój zestaw wejściowy na zestaw programistyczny (zestaw treningowy + zestaw Dev-testowy) i zestaw testowy (lub zestaw ewaluacyjny). Pamiętaj, że Twoim podstawowym celem będzie to, że Twój system uczy się i klasyfikuje nowe wejścia, których nigdy wcześniej nie widzieli w zestawie Dev lub testowym.
Zestaw testowy zazwyczaj ma taki sam format jak zestaw treningowy. Bardzo ważne jest jednak, aby zestaw testów był odrębny od korpusu treningowego: jeśli po prostu ponowne wykorzystanie zestawu treningowego jako zestawu testowego, a następnie model, który po prostu zapamiętał swój wkład, bez uczenia się, jak uogólniać na nowe przykłady, otrzymałby mylnie wysokie wyniki.
Ogólnie, na przykład, 70% mogą być przypadki zestawów treningowych. Pamiętaj również, aby podzielić oryginalny zestaw na zestawy treningowe i testowe losowo.
Teraz przechodzę do drugiego pytania o naiwnego Bayesa.Źródło na przykład poniżej: http://www.statsoft.com/textbook/naive-bayes-classifier
Aby zademonstrować pojęcie naiwnej klasyfikacji Bayesa, rozważ poniższy przykład:
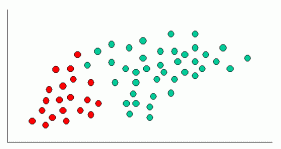
Jak wskazano, obiekty mogą być klasyfikowane jako albo GREEN albo RED. Naszym zadaniem jest klasyfikowanie nowych przypadków w miarę ich powstawania, tzn. decydowanie, do której klasy należą, na podstawie aktualnie istniejących obiektów.
Ponieważ istnieje dwa razy więcej obiektów GREEN niż RED, rozsądne jest sądzić, że nowy przypadek (który nie został jeszcze zaobserwowany) ma dwa razy większe prawdopodobieństwo członkostwa GREEN niż RED. W analizie bayesowskiej przekonanie to znane jest jako prawdopodobieństwo wcześniejsze. Wcześniejsze prawdopodobieństwo opiera się na wcześniejszych doświadczeniach, w w tym przypadku procent obiektów GREEN i RED, i często używany do przewidywania wyników, zanim rzeczywiście się wydarzy.
Tak więc możemy napisać:
Wcześniejsze prawdopodobieństwo wystąpienia GREEN: number of GREEN objects / total number of objects
Wcześniejsze prawdopodobieństwo wystąpienia RED: number of RED objects / total number of objects
Ponieważ istnieje łącznie 60 obiektów, 40 z których są GREEN i 20 RED, nasze wcześniejsze prawdopodobieństwo członkostwa w klasie to:
Prawdopodobieństwo wstępne dla GREEN : 40 / 60
Wcześniejsze Prawdopodobieństwo dla RED: 20 / 60
Po sformułowaniu naszego wcześniejszego prawdopodobieństwa, jesteśmy teraz gotowi sklasyfikować nowy obiekt (WHITE okrąg na poniższym diagramie). Ponieważ obiekty są dobrze zgrupowane, rozsądne jest założenie, że im więcej GREEN (LUB RED) obiektów w pobliżu X, tym bardziej prawdopodobne jest, że nowe przypadki należą do tego konkretnego koloru. Aby zmierzyć to prawdopodobieństwo, narysujemy okrąg wokół X, który obejmuje liczbę (aby wybrać priori) punktów niezależnie od ich klas. Następnie obliczamy liczbę punktów w okręgu należącym do każdej z klas. Na podstawie tego obliczamy prawdopodobieństwo:
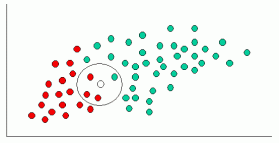
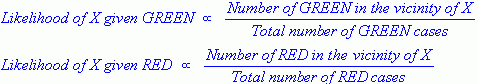
Z powyższej ilustracji wynika, że prawdopodobieństwo X podane GREEN jest mniejsze niż prawdopodobieństwo X podane RED, ponieważ okrąg obejmuje 1 GREEN obiekt i 3 RED jeden. Tak więc:
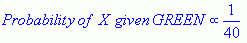
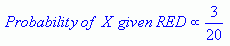
Chociaż wcześniejsze prawdopodobieństwa wskazują, że X może należeć do GREEN (biorąc pod uwagę, że jest dwa razy więcej GREEN w porównaniu do RED), prawdopodobieństwo wskazuje inaczej; że przynależność do klasy X jest RED (biorąc pod uwagę, że jest więcej RED obiektów w pobliżu X niż GREEN). W analizie bayesowskiej Klasyfikacja końcowa jest wytwarzana przez połączenie obu źródeł informacji, tj. wcześniejszego i prawdopodobieństwa, aby utworzyć prawdopodobieństwo tylne za pomocą tzw. reguły Bayesa (nazwanej na cześć ks. Thomasa Bayesa 1702-1761).

Ostatecznie klasyfikujemy X jako RED, ponieważ jego przynależność do klasy osiąga największe prawdopodobieństwo.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-02-01 18:12:07
Zdaję sobie sprawę, że to stare pytanie, z ustaloną odpowiedzią. Powodem, dla którego piszę jest to, że akceptowana odpowiedź ma wiele elementów k - NN (k -najbliżsi sąsiedzi), inny algorytm.
Zarówno K-NN, jak i NaiveBayes są algorytmami klasyfikacyjnymi. Koncepcyjnie k-NN używa pojęcia "bliskości" do klasyfikacji nowych Bytów. W k-NN "bliskość" jest modelowana za pomocą idei takich jak odległość euklidesowa lub odległość cosinusa. Natomiast w naiwności pojęcie "prawdopodobieństwo" jest używane do klasyfikacji nowych podmiotów.
Ponieważ pytanie dotyczy naiwnego Bayesa, oto jak opisałbym komuś pomysły i kroki. Postaram się to zrobić z jak najmniejszą ilością równań i w jak największym stopniu po angielsku.
Po Pierwsze, Prawdopodobieństwo Warunkowe & Reguła Bayesa
Zanim ktoś może zrozumieć i docenić niuanse naiwnego Bayesa, musi najpierw poznać kilka powiązanych pojęć, a mianowicie ideę prawdopodobieństwa warunkowego i Bayesa Zasada. (Jeśli znasz te pojęcia, przejdź do sekcji zatytułowanej Getting to Naive Bayes')
Prawdopodobieństwo warunkowe w prostym języku angielskim: jakie jest prawdopodobieństwo, że coś się wydarzy, biorąc pod uwagę, że coś innego już się wydarzyło.
Powiedzmy, że istnieje jakiś wynik O. i jakiś dowód E. ze sposobu, w jaki te prawdopodobieństwa są zdefiniowane: prawdopodobieństwo posiadania zarówno wynik o jak i dowód E jest: (Prawdopodobieństwo wystąpienia O) pomnożone przez (Prob E biorąc pod uwagę, że O się stało)
jeden przykład do zrozumienia prawdopodobieństwa warunkowego:
Powiedzmy, że mamy kolekcję amerykańskich senatorów. Senatorami mogą być Demokraci lub Republikanie. Są to zarówno mężczyźni, jak i kobiety.
Jeśli wybierzemy jednego senatora całkowicie losowo, jakie jest prawdopodobieństwo, że ta osoba jest Demokratką? Prawdopodobieństwo warunkowe może pomóc nam na to odpowiedzieć.Prawdopodobieństwo (Demokrata i kobieta Senator) = Prob (Senator jest Demokratą) pomnożony przez Prawdopodobieństwo warunkowe bycia kobietą, biorąc pod uwagę, że są Demokratą.
P(Democrat & Female) = P(Democrat) * P(Female | Democrat)
Możemy obliczyć dokładnie to samo, odwrotnie:
P(Democrat & Female) = P(Female) * P(Democrat | Female)
Zrozumienie Zasady Bayesa
Koncepcyjnie jest to sposób przejścia od P (Evidence| Known Outcome) do P (Outcome|Known Evidence). Często wiemy, jak często obserwuje się pewne szczególne dowody, biorąc pod uwagę znany wynik. Musimy użyć tego znany fakt, aby obliczyć odwrotność, aby obliczyć szansę, że wynik wydarzy się , biorąc pod uwagę dowody.
P (wynik biorąc pod uwagę, że znamy jakiś dowód) = P (dowód biorąc pod uwagę, że znamy wynik) razy Prob (wynik), skalowany przez P (dowód)
Klasyczny przykład do zrozumienia zasady Bayesa:]}Probability of Disease D given Test-positive =
Prob(Test is positive|Disease) * P(Disease)
_______________________________________________________________
(scaled by) Prob(Testing Positive, with or without the disease)
Getting to Naive Bayes'
Do tej pory mówiliśmy tylko o jednym kawałku dowód. W rzeczywistości, musimy przewidzieć wynik biorąc pod uwagę wiele dowodów. W takim przypadku matematyka staje się bardzo skomplikowana. Aby obejść tę komplikację, jednym z podejść jest "uwolnienie" wielu dowodów i traktowanie każdego z dowodów jako niezależnego. To podejście nazywa się naiwnym Bayesem.
P(Outcome|Multiple Evidence) =
P(Evidence1|Outcome) * P(Evidence2|outcome) * ... * P(EvidenceN|outcome) * P(Outcome)
scaled by P(Multiple Evidence)
Wiele osób decyduje się zapamiętać to jako:
P(Likelihood of Evidence) * Prior prob of outcome
P(outcome|evidence) = _________________________________________________
P(Evidence)
Zwróć uwagę na kilka rzeczy na temat tego równania:
- jeśli Prob (evidence|outcome) wynosi 1, wtedy po prostu mnożymy przez 1.
- jeśli Prob (jakiś konkretny dowód|wynik) jest równy 0, to cały prob. staje się 0. Jeśli zobaczysz sprzeczne dowody, możemy wykluczyć ten wynik.
- ponieważ dzielimy wszystko przez P (dowód), możemy nawet uciec bez obliczania tego.
- intuicja stojąca za mnożeniem przez przed jest taka, że dajemy wysokie prawdopodobieństwo bardziej powszechnym rezultatom, a niskie prawdopodobieństwo mało prawdopodobnym wyniki. Są one również nazywane
base ratesi są sposobem na skalowanie naszych przewidywanych prawdopodobieństw.
Jak zastosować NaiveBayes, aby przewidzieć wynik?
Wystarczy uruchomić powyższy wzór dla każdego możliwego wyniku. Ponieważ staramy się sklasyfikować , każdy wynik nazywa się class i ma class label., naszym zadaniem jest przyjrzeć się dowodom, rozważyć, jak prawdopodobne jest to, że będzie to ta lub inna klasa, i przypisać Etykietę każdej jednostce.
Ponownie, podejmiemy bardzo proste podejście: Klasa, która ma największe prawdopodobieństwo, zostaje uznana za "zwycięzcę", a etykieta klasy zostaje przypisana do tej kombinacji dowodów.
Przykład Owoców
Wypróbujmy to na przykładzie, aby zwiększyć nasze zrozumienie: OP poprosił o przykład identyfikacji "owoców".
Powiedzmy, że mamy dane na 1000 sztuk owoców. Banan, pomarańczowy lub jakiś inny owoc . Znamy 3 cechy każdego owoc:- czy jest długa
- czy jest słodki i
- jeśli jego kolor jest żółty.
Type Long | Not Long || Sweet | Not Sweet || Yellow |Not Yellow|Total
___________________________________________________________________
Banana | 400 | 100 || 350 | 150 || 450 | 50 | 500
Orange | 0 | 300 || 150 | 150 || 300 | 0 | 300
Other Fruit | 100 | 100 || 150 | 50 || 50 | 150 | 200
____________________________________________________________________
Total | 500 | 500 || 650 | 350 || 800 | 200 | 1000
___________________________________________________________________
Możemy wstępnie obliczyć wiele rzeczy o naszej kolekcji owoców.
Tzw. "wcześniejsze" prawdopodobieństwo. (Gdybyśmy nie znali żadnych atrybutów owoców, to byłoby nasze przypuszczenie.) Są to nasze base rates.
P(Banana) = 0.5 (500/1000)
P(Orange) = 0.3
P(Other Fruit) = 0.2
Prawdopodobieństwo "dowodu"
p(Long) = 0.5
P(Sweet) = 0.65
P(Yellow) = 0.8
Prawdopodobieństwo "prawdopodobieństwa"
P(Long|Banana) = 0.8
P(Long|Orange) = 0 [Oranges are never long in all the fruit we have seen.]
....
P(Yellow|Other Fruit) = 50/200 = 0.25
P(Not Yellow|Other Fruit) = 0.75
Dany owoc, jak go sklasyfikować?
Powiedzmy, że otrzymujemy właściwości nieznanego owocu i poprosimy o jego klasyfikację. Mówi się nam, że owoce są długie, słodkie i żółte. Czy to banan? Czy to pomarańcza? A może to jakiś inny owoc?Możemy po prostu uruchomić liczby dla każdego z 3 wyników, jeden po drugim. Następnie wybieramy największe prawdopodobieństwo i "sklasyfikować" nasze nieznane owoce jako należące do klasy, która miała największe prawdopodobieństwo na podstawie naszych wcześniejszych dowodów (nasz zestaw treningowy 1000 owoców): {]}
P(Banana|Long, Sweet and Yellow)
P(Long|Banana) * P(Sweet|Banana) * P(Yellow|Banana) * P(banana)
= _______________________________________________________________
P(Long) * P(Sweet) * P(Yellow)
= 0.8 * 0.7 * 0.9 * 0.5 / P(evidence)
= 0.252 / P(evidence)
P(Orange|Long, Sweet and Yellow) = 0
P(Other Fruit|Long, Sweet and Yellow)
P(Long|Other fruit) * P(Sweet|Other fruit) * P(Yellow|Other fruit) * P(Other Fruit)
= ____________________________________________________________________________________
P(evidence)
= (100/200 * 150/200 * 50/200 * 200/1000) / P(evidence)
= 0.01875 / P(evidence)
Przez przytłaczający margines (0.252 >> 0.01875), klasyfikujemy ten słodki / długi / żółty owoc jako prawdopodobnie Banan.
Dlaczego Bayes Classifier jest tak popularny?
Zobacz, do czego to ostatecznie sprowadza. Tylko trochę liczenia i mnożenia. Możemy wstępnie obliczyć wszystkie te terminy, dzięki czemu klasyfikacja staje się łatwa, szybka i wydajny.Let z = 1 / P(evidence). teraz szybko obliczamy następujące trzy ilości.
P(Banana|evidence) = z * Prob(Banana) * Prob(Evidence1|Banana) * Prob(Evidence2|Banana) ...
P(Orange|Evidence) = z * Prob(Orange) * Prob(Evidence1|Orange) * Prob(Evidence2|Orange) ...
P(Other|Evidence) = z * Prob(Other) * Prob(Evidence1|Other) * Prob(Evidence2|Other) ...
Przypisz Etykietę klasy, która jest największą liczbą, i gotowe.
Pomimo nazwy naiwny Bayes okazuje się być doskonały w niektórych zastosowaniach. Klasyfikacja tekstu jest jednym z obszarów, w których naprawdę świeci.
Nadzieję, że pomoże to w zrozumieniu pojęć stojących za naiwnym algorytmem Bayesa.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-12-25 10:53:42
Ram Narasimhan bardzo ładnie wyjaśnił tę koncepcję poniżej znajduje się alternatywne Wyjaśnienie na przykładzie kodu naiwnych Bayesa w działaniu
Wykorzystuje przykładowy problem z tej książki na stronie 351
Jest to zbiór danych, z którego będziemy korzystać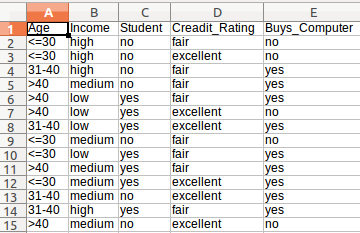
W powyższym zbiorze danych jeśli podamy hipotezę = {"Age":'<=30', "Income":"medium", "Student":'yes' , "Creadit_Rating":'fair'} to jakie jest prawdopodobieństwo, że kupi lub nie kupi komputera.
Poniższy kod dokładnie odpowiada na to pytanie.
Wystarczy utworzyć plik wywołane nazwane new_dataset.csv i wklej następującą treść.
Age,Income,Student,Creadit_Rating,Buys_Computer
<=30,high,no,fair,no
<=30,high,no,excellent,no
31-40,high,no,fair,yes
>40,medium,no,fair,yes
>40,low,yes,fair,yes
>40,low,yes,excellent,no
31-40,low,yes,excellent,yes
<=30,medium,no,fair,no
<=30,low,yes,fair,yes
>40,medium,yes,fair,yes
<=30,medium,yes,excellent,yes
31-40,medium,no,excellent,yes
31-40,high,yes,fair,yes
>40,medium,no,excellent,no
Oto kod komentarze wyjaśniają wszystko, co tu robimy! [python]
import pandas as pd
import pprint
class Classifier():
data = None
class_attr = None
priori = {}
cp = {}
hypothesis = None
def __init__(self,filename=None, class_attr=None ):
self.data = pd.read_csv(filename, sep=',', header =(0))
self.class_attr = class_attr
'''
probability(class) = How many times it appears in cloumn
__________________________________________
count of all class attribute
'''
def calculate_priori(self):
class_values = list(set(self.data[self.class_attr]))
class_data = list(self.data[self.class_attr])
for i in class_values:
self.priori[i] = class_data.count(i)/float(len(class_data))
print "Priori Values: ", self.priori
'''
Here we calculate the individual probabilites
P(outcome|evidence) = P(Likelihood of Evidence) x Prior prob of outcome
___________________________________________
P(Evidence)
'''
def get_cp(self, attr, attr_type, class_value):
data_attr = list(self.data[attr])
class_data = list(self.data[self.class_attr])
total =1
for i in range(0, len(data_attr)):
if class_data[i] == class_value and data_attr[i] == attr_type:
total+=1
return total/float(class_data.count(class_value))
'''
Here we calculate Likelihood of Evidence and multiple all individual probabilities with priori
(Outcome|Multiple Evidence) = P(Evidence1|Outcome) x P(Evidence2|outcome) x ... x P(EvidenceN|outcome) x P(Outcome)
scaled by P(Multiple Evidence)
'''
def calculate_conditional_probabilities(self, hypothesis):
for i in self.priori:
self.cp[i] = {}
for j in hypothesis:
self.cp[i].update({ hypothesis[j]: self.get_cp(j, hypothesis[j], i)})
print "\nCalculated Conditional Probabilities: \n"
pprint.pprint(self.cp)
def classify(self):
print "Result: "
for i in self.cp:
print i, " ==> ", reduce(lambda x, y: x*y, self.cp[i].values())*self.priori[i]
if __name__ == "__main__":
c = Classifier(filename="new_dataset.csv", class_attr="Buys_Computer" )
c.calculate_priori()
c.hypothesis = {"Age":'<=30', "Income":"medium", "Student":'yes' , "Creadit_Rating":'fair'}
c.calculate_conditional_probabilities(c.hypothesis)
c.classify()
Wyjście:
Priori Values: {'yes': 0.6428571428571429, 'no': 0.35714285714285715}
Calculated Conditional Probabilities:
{
'no': {
'<=30': 0.8,
'fair': 0.6,
'medium': 0.6,
'yes': 0.4
},
'yes': {
'<=30': 0.3333333333333333,
'fair': 0.7777777777777778,
'medium': 0.5555555555555556,
'yes': 0.7777777777777778
}
}
Result:
yes ==> 0.0720164609053
no ==> 0.0411428571429
Peace
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-03-29 12:00:28
Naiwny Bayes: Naiwne Bayes jest pod nadzorem uczenia maszynowego, które używane do klasyfikacji zbiorów danych. Jest on używany do przewidywania rzeczy w oparciu o jego wcześniejsze założenia wiedzy i niezależności.
Nazywają to naiwne ponieważ jego założenia (zakłada, że wszystkie funkcje w zbiorze danych są równie ważne i niezależne) są naprawdę optymistyczne i rzadko prawdziwe w większości rzeczywistych aplikacji.
Jest to algorytm klasyfikacji, który podejmuje decyzję o nieznanym zbiorze danych. Opiera się ona na twierdzeniu Bayesa , które opisuje prawdopodobieństwo zdarzenia w oparciu o jego wcześniejszą wiedzę.
Poniższy schemat pokazuje jak działa naiwny Bayes

Wzór do przewidzenia NB:
Jak wykorzystać naiwny algorytm Bayesa ?
Weźmy przykład jak n. b woksKrok 1: najpierw poznajemy tabelę, która pokazuje prawdopodobieństwo tak lub nie na poniższym diagramie. Krok 2: Znajdź tylne prawdopodobieństwo każdej klasy.
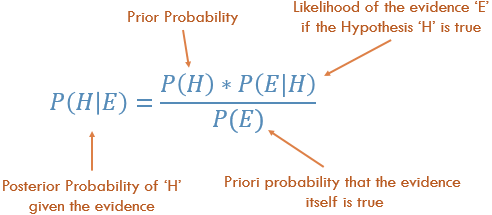
Problem: Find out the possibility of whether the player plays in Rainy condition?
P(Yes|Rainy) = P(Rainy|Yes) * P(Yes) / P(Rainy)
P(Rainy|Yes) = 2/9 = 0.222
P(Yes) = 9/14 = 0.64
P(Rainy) = 5/14 = 0.36
Now, P(Yes|Rainy) = 0.222*0.64/0.36 = 0.39 which is lower probability which means chances of the match played is low.
Więcej informacji można znaleźć na blogu .
Zobacz Repozytorium GitHub Naive-Bayes-Examples
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-05-17 03:29:57
Staram się wyjaśnić zasadę Bayesa na przykładzie.
Przypuśćmy, że wiesz, że 10% ludzie palą. Wiesz też, że 90% palaczy są mężczyźni i 80% z nich mają powyżej 20 lat.
Teraz widzisz kogoś, kto jest mężczyzną i 15 lat. Chcesz poznać szansę, że jest palaczem:
X = smoker | he is a man and under 20
Ponieważ wiesz, że 10% ludzi to palacze, Twoje początkowe przypuszczenie wynosi 10% (wcześniejsze prawdopodobieństwo , nie wiedząc nic o osobie), ale inne dowody (że jest człowiekiem i ma 15 lat) mogą mieć wpływ na to przypuszczenie.
Każdy dowód może zwiększyć lub zmniejszyć tę szansę. Na przykład fakt, że jest on mężczyzną może zwiększyć szansę, pod warunkiem, że odsetek ten (bycie mężczyzną) wśród osób niepalących jest niższy, na przykład, 40%. Innymi słowy, bycie mężczyzną musi być dobrym wskaźnikiem bycia palaczem, a nie niepalącym.Możemy pokazać ten wkład w inny sposób. Dla każdej funkcji, trzeba porównać powszechność (prawdopodobieństwo) tej funkcji (f) sam z jego powszechności w danych warunkach. (P(f) vs. P(f | x). Na przykład, jeśli wiemy, że prawdopodobieństwo bycia mężczyzną wynosi 90% w społeczeństwie i 90% palaczy to również mężczyźni, to wiedza, że ktoś jest mężczyzną, nie pomaga nam (10% * (90% / 90%) = 10%). Ale jeśli mężczyźni przyczyniają się do 40% społeczeństwa, ale 90% palaczy, wiedza, że ktoś jest mężczyzną, zwiększa szansę na bycie palaczem (10% * (90% / 40%) = 22.5% ). W ten sam sposób, jeśli prawdopodobieństwo bycia mężczyzną wynosiło 95% w społeczeństwie, to niezależnie od tego, że odsetek mężczyzn wśród palaczy jest wysoki (90%)! dowody na to, że ktoś jest mężczyzną zmniejszają szansę na to, że jest palaczem! (10% * (90% / 95%) = 9.5%).
Mamy więc:
P(X) =
P(smoker)*
(P(being a man | smoker)/P(being a man))*
(P(under 20 | smoker)/ P(under 20))
Zauważ, że w tym wzorze założyliśmy, że bycie człowiekiem i bycie poniżej 20 są cechami niezależnymi, więc pomnożyliśmy je, to znaczy, że wiedząc, że ktoś jest poniżej 20 Nie ma wpływu na zgadywanie, że jest mężczyzną lub kobietą. Ale to może nie być prawda, na przykład może większość dojrzewania w społeczeństwie są mężczyźni...
Aby użyć tego wzoru w klasyfikatorze
Klasyfikator jest podany z pewnymi cechami (bycie mężczyzną i bycie poniżej 20 lat) i musi zdecydować, czy jest palaczem, czy nie. Używa powyższej formuły, aby to znaleźć. Aby zapewnić wymagane prawdopodobieństwa (90%, 10%, 80%...) korzysta z zestawu treningowego. Na przykład liczy się osób w zestawie treningowym, które są palaczy i stwierdzają, że stanowią one 10% próbki. Następnie dla palaczy sprawdza, ilu z nich to mężczyźni lub kobiety .... ile jest powyżej 20 lub poniżej 20....
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-05-27 20:20:46