Jak obliczyć parametr regularyzacji w regresji liniowej
Gdy mamy wielomian liniowy wysokiego stopnia, który jest używany do dopasowania zbioru punktów w konfiguracji regresji liniowej, aby zapobiec nadmiernemu dopasowaniu, używamy regularyzacji i uwzględniamy parametr lambda w funkcji kosztów. Lambda jest następnie używana do aktualizacji parametrów theta w algorytmie opadania gradientu.
Moje pytanie brzmi jak obliczyć ten parametr regularyzacji lambda?
3 answers
Parametr regularyzacji (lambda) jest danymi wejściowymi do twojego modelu, więc prawdopodobnie chcesz wiedzieć, jak wybrać wartość lambda. Parametr regularyzacji zmniejsza nadmierne dopasowanie, co zmniejsza wariancję szacowanych parametrów regresji; jednak robi to kosztem dodania błędu do oszacowania. Zwiększenie lambda powoduje mniejsze przekłamanie, ale także większe odchylenie. Więc prawdziwe pytanie brzmi :" ile stronniczości jesteś gotów tolerować w swoim oszacowanie?"
Jedną z metod, które możesz zastosować, jest losowo próbkowanie danych kilka razy i przyjrzenie się zmianom w szacunkach. Następnie powtórz proces dla nieco większej wartości lambda, aby zobaczyć, jak wpływa to na zmienność twojego oszacowania. Należy pamiętać, że niezależnie od tego, jaką wartość lambda zdecydujesz, jest odpowiednia dla Twoich podsamplowanych danych, prawdopodobnie możesz użyć mniejszej wartości, aby osiągnąć porównywalną regularyzację na pełnym zestawie danych.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2012-08-29 16:24:35
FORMA ZAMKNIĘTA (TIKHONOV) A ZEJŚCIE GRADIENTU
Cześć! ładne wyjaśnienia dla intuicyjnego i najwyższej klasy podejścia matematycznego. Chciałem tylko dodać kilka specyfików, które tam, gdzie nie "rozwiązywanie problemów", mogą zdecydowanie przyspieszyć i dać pewną spójność procesowi znalezienia dobrego hiperparametru regularyzacyjnego.Zakładam, że mówisz o L2 (vel "rozpad masy") regularyzacji, liniowo ważonej przez lambda term, i że optymalizujesz wagę swojego modelu albo za pomocą postaci zamkniętej Tikhonova równania (wysoce zalecane dla niskowymiarowych modeli regresji liniowej), albo z jakimś wariantem zejścia gradientu z odwrotnością . I że w tym kontekście chcesz wybrać wartość lambda , która zapewnia najlepszą zdolność uogólniania.
FORMA ZAMKNIĘTA (TIKHONOV)
Jeśli jesteś w stanie przejść do Metoda tikhonowa z Twoim modelem (Andrew Ng mówi o wymiarach poniżej 10K, ale ta sugestia ma co najmniej 5 lat) Wikipedia-określenie współczynnika Tikhonowa oferuje interesujące rozwiązanie w formie zamkniętej, które okazało się zapewniać optymalną wartość. Ale to rozwiązanie prawdopodobnie rodzi jakieś problemy implementacyjne (złożoność czasowa/stabilność numeryczna), których nie jestem świadomy, ponieważ nie ma głównego nurtu algorytmu do jego wykonania. To 2016 papier wygląda bardzo obiecująco i może być warty wypróbowania, jeśli naprawdę musisz zoptymalizować swój model liniowy w najlepszy sposób.
- dla szybszej implementacji prototypu, to 2015 pakiet Pythona wydaje się radzić sobie z nim iteracyjnie, można pozwolić mu zoptymalizować, a następnie wyodrębnić końcową wartość dla lambda:
[17]} w tej nowej innowacyjnej metodzie wypracowaliśmy iteracyjne podejście do rozwiązania ogólnego problemu regularyzacji Tikhonova, który zbiega się do rozwiązania bezgłośnego, nie zależy silnie od wyboru lambda, a mimo to unika problemu inwersji.
I z GitHub README projektu:
InverseProblem.invert(A, be, k, l) #this will invert your A matrix, where be is noisy be, k is the no. of iterations, and lambda is your dampening effect (best set to 1)
ZEJŚCIE GRADIENTU
wszystkie linki tej części pochodzą z niesamowitej książki internetowej Michaela Nielsena "Sieci neuronowe i głębokie uczenie", zalecany wykład!
Dla tego podejścia wydaje się być jeszcze mniej do powiedzenia: funkcja kosztów jest zwykle nie-wypukła, optymalizacja jest wykonywana numerycznie, a wydajność modelu jest mierzona przez jakąś formę walidacji krzyżowej (zobacz Overfitting and Regularization i dlaczego regularyzacja pomaga zmniejszyć overfitting , jeśli nie masz tego dość). Ale nawet przy sprawdzaniu krzyżowym, Nielsen sugeruje coś: możesz rzucić okiem na to szczegółowe wyjaśnienie na temat tego, w jaki sposób regularyzacja L2 zapewnia efekt rozpadu masy, ale podsumowanie jest że jest odwrotnie proporcjonalna do liczby próbek n, tak więc przy obliczaniu równania opadania gradientu z terminem L2,
Lambda jest jedną z najbardziej rozpoznawalnych i najbardziej rozpoznawalnych postaci na świecie.]}Po prostu użyj odwrotności, jak zwykle, a następnie dodaj
(λ/n)*wdo pochodnej cząstkowej wszystkich terminów wagi.
Musimy zmodyfikować parametr regularyzacji. Powodem jest to, że rozmiar
nzestawu treningowego zmienił się zn=1000nan=50000, a to zmienia współczynnik rozpadu masy ciała1−learning_rate*(λ/n). Gdybyśmy nadal używaliλ=0.1, oznaczałoby to znacznie mniejszy spadek masy ciała, a tym samym znacznie mniejszy efekt regularyzacji. Kompensujemy zmieniając naλ=5.0.
Jest to przydatne tylko przy stosowaniu tego samego modelu do różnych ilości tych samych danych, ale myślę, że otwiera to drzwi do pewnej intuicji, jak to powinno działać, a co ważniejsze, przyspiesz proces hiperparametryzacji, umożliwiając finetune lambda w mniejszych podzbiorach, a następnie skalowanie w górę.
Przy wyborze dokładnych wartości, w swoich wnioskach na temat[90]}Jak wybrać hiperparametry sieci neuronowej {26]}, sugeruje czysto empiryczne podejście: zacznij od 1, a następnie stopniowo mnożyć i dzielić przez 10, aż znajdziesz odpowiedni rząd wielkości, a następnie wykonaj Lokalne wyszukiwanie w tym regionie. W komentarzach do: ten SE podobne pytanie , użytkownik Brian Borchers sugeruje również bardzo znaną metodę, która może być przydatna dla tego lokalnego wyszukiwania:-
W 2007 roku, po raz pierwszy w Polsce, w 2008 roku, w Polsce i za granicą, w 2009 roku, w 2009 roku, w Polsce i za granicą.]}
W tym celu należy wykonać kilka prostych czynności, które można wykonać w celu sprawdzenia, czy dany model jest gotowy do użycia.]}
- będziesz obserwować trzy rzeczy:
- CV funkcja utraty będzie konsekwentnie wyższa niż treningowa, ponieważ twój model jest zoptymalizowany wyłącznie dla danych treningowych (EDIT: po pewnym czasie widziałem przypadek MNIST, w którym dodanie L2 pomogło zmniejszyć utratę CV szybciej niż treningowa aż do konwergencji. Prawdopodobnie ze względu na śmieszną spójność danych i nieoptymalną hiperparametryzację).
- funkcja training loss będzie miała swoje minimum dla
λ=0, a następnie zwiększy się wraz z regularyzacją, ponieważ zapobieganie optymalnemu dopasowaniu modelu do danych treningowych jest dokładnie tym, co robi regularyzacja. - funkcja CV loss rozpocznie się wysoko w
λ=0, następnie zmniejszy się, a następnie zacznie ponownie rosnąć w pewnym momencie (EDIT: zakładając, że konfiguracja jest w stanie przerodzić się dlaλ=0, tzn. model ma wystarczającą moc i żadne inne środki regularyzacji nie są mocno stosowane).
- optymalna wartość dla
λbędzie prawdopodobnie gdzieś w okolicach minimum funkcja utraty CV, może również zależeć trochę od tego, jak wygląda funkcja utraty treningu. Zobacz obrazek dla możliwej (ale nie jedynej) reprezentacji tego: zamiast" złożoności modelu " powinieneś zinterpretować Oś x jakoλbędącą zerem po prawej stronie i rosnącą w kierunku lewej.
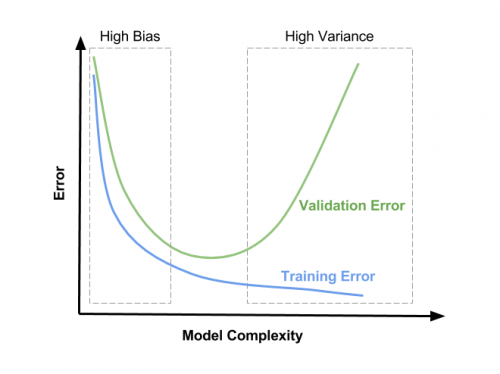
Mam nadzieję, że to pomoże! Pozdrawiam,
Andres
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-04-05 01:41:39
Walidacja krzyżowa opisana powyżej jest metodą często stosowaną w uczeniu maszynowym. Jednak wybór niezawodnego i bezpiecznego parametru regularyzacji jest nadal bardzo gorącym tematem badań w matematyce. Jeśli potrzebujesz pomysłów (i masz dostęp do przyzwoitej Biblioteki Uniwersyteckiej), możesz rzucić okiem na ten artykuł: http://www.sciencedirect.com/science/article/pii/S0378475411000607
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2013-10-18 16:29:02