Jak korzystać z walidacji krzyżowej K-fold w sieci neuronowej
Piszemy mały ANN, który ma kategoryzować 7000 produktów na 7 klas w oparciu o 10 zmiennych wejściowych.
Aby to zrobić, musimy użyć walidacji krzyżowej K-fold, ale jesteśmy trochę zdezorientowani.
Mamy ten fragment slajdu z prezentacji:

Czym dokładnie są zestawy walidacyjne i testowe?
Z tego, co rozumiemy, to to, że biegamy przez 3 zestawy treningowe i dostosowujemy wagi (pojedyncza Epoka). Więc co zrobimy z zatwierdzeniem? Ponieważ z tego, co rozumiem, jest to, że zestaw testowy jest używany do uzyskania błędu sieci.
To, co dzieje się dalej, również jest dla mnie mylące. Kiedy odbywa się crossover?
Jeśli nie jest to zbyt wiele, lista punktowa kroku będzie mile widziana
2 answers
Wydajesz się być trochę zdezorientowany (pamiętam, że też byłem) więc zamierzam uprościć rzeczy dla Ciebie. ;)
Przykładowy Scenariusz Sieci Neuronowej]}Ilekroć otrzymujesz zadanie, takie jak opracowanie sieci neuronowej, często otrzymujesz również przykładowy zestaw danych do wykorzystania w celach szkoleniowych. Załóżmy, że trenujesz prosty układ sieci neuronowej Y = W · X Gdzie Y jest wyjściem obliczonym z obliczenia iloczynu skalarnego ( · ) wektora wagi W z danym wektorem próbki X. Naiwnym sposobem, by to zrobić, byłoby użycie całego zbioru danych, powiedzmy, 1000 próbek, do wytrenowania sieci neuronowej. Zakładając, że trening się zbiega, a twoje ciężary ustabilizują, możesz śmiało powiedzieć, że dane treningowe zostaną prawidłowo sklasyfikowane przez sieć. ale co się stanie z siecią, jeśli zostaną przedstawione wcześniej niewidoczne dane? oczywistym celem takich systemów jest możliwość uogólnienia i poprawnej klasyfikacji danych innych niż te wykorzystywane w szkoleniu.
Overfitting Explained
W każdej realnej sytuacji, jednak wcześniej niewidoczne / nowe dane są dostępne tylko po wdrożeniu sieci neuronowej w, nazwijmy to, środowisku produkcyjnym. Ale ponieważ nie przetestowałeś go odpowiednio, prawdopodobnie będziesz miał zły czas. :) Zjawisko, dzięki któremu każdy system uczenia się prawie idealnie dopasowuje się do swojego zestawu treningowego, ale ciągle zawodzi z niewidocznymi danymi, nazywa się[36]}overfitting {37]}.
The Three Zestawy
Oto część walidacji i testowania algorytmu. Wróćmy do oryginalnego zbioru 1000 próbek. To co robisz to dzielisz go na trzy zestawy -- trening, Walidacja i testowanie (Tr, Va i Te) -- przy użyciu starannie dobranych proporcji. (80-10-10)% to zwykle dobra proporcja, gdzie:
Tr = 80%Va = 10%Te = 10%
Szkolenie i Walidacja
Teraz co zdarza się, że sieć neuronowa jest trenowana na zestawie Tr, a jej wagi są prawidłowo aktualizowane. Zestaw walidacji Va jest następnie używany do obliczenia błędu klasyfikacji E = M - Y przy użyciu ciężarów wynikających z treningu, gdzie M jest oczekiwanym wektorem wyjściowym pobranym z zestawu walidacji, a {[2] } jest obliczonym wynikiem wynikającym z klasyfikacji (Y = W * X). Jeśli błąd jest wyższy niż próg zdefiniowany przez użytkownika, powtarza się cały okres szkolenia -Walidacja. Ta faza szkolenia kończy się, gdy błąd obliczony przy użyciu zestawu walidacji zostanie uznany za wystarczająco niski.
Inteligentny Trening
Teraz, inteligentny podstęp tutaj jest losowo wybrać, które próbki do wykorzystania do szkolenia i walidacji Z całkowitego zestawu Tr + Va w każdej iteracji epoki. Zapewnia to, że sieć nie będzie nadmiernie dopasowana do zestawu treningowego.
Testowanie
Zestaw testowy Te jest następnie używany do pomiaru wydajności sieci. Te dane są idealne dla ten cel, ponieważ nigdy nie był używany przez cały etap szkolenia i walidacji. W rzeczywistości jest to mały zestaw wcześniej niewidocznych danych, który ma naśladować to, co stanie się po wdrożeniu sieci w środowisku produkcyjnym.
Wydajność jest ponownie mierzona w terminie błędu klasyfikacji, jak wyjaśniono powyżej. Wydajność może również (a może nawet powinna) być mierzona w kategoriach precyzji i przypomnienia , aby wiedzieć, gdzie i jak występuje błąd, ale to temat na kolejne pytania i odpowiedzi.]}
Weryfikacja Krzyżowa
Po zrozumieniu tego mechanizmu szkolenia-walidacji-testowania, można dodatkowo wzmocnić sieć przed nadmiernym dopasowaniem, wykonując K-fold cross-validation . Jest to w pewnym sensie ewolucja sprytnego podstępu, który wyjaśniłem powyżej. Technika ta obejmuje wykonywanie K rund treningowych-Walidacja-testowanie na, różnych, Nie nakładających się, jednakowo proporcjonalnych Tr, Va oraz Te zestawy .
Biorąc pod uwagę k = 10, dla każdej wartości K podzielisz swój zbiór danych na Tr+Va = 90% i Te = 10% i uruchomisz algorytm, rejestrując wydajność testów.
k = 10
for i in 1:k
# Select unique training and testing datasets
KFoldTraining <-- subset(Data)
KFoldTesting <-- subset(Data)
# Train and record performance
KFoldPerformance[i] <-- SmartTrain(KFoldTraining, KFoldTesting)
# Compute overall performance
TotalPerformance <-- ComputePerformance(KFoldPerformance)
Overfitting Pokazane
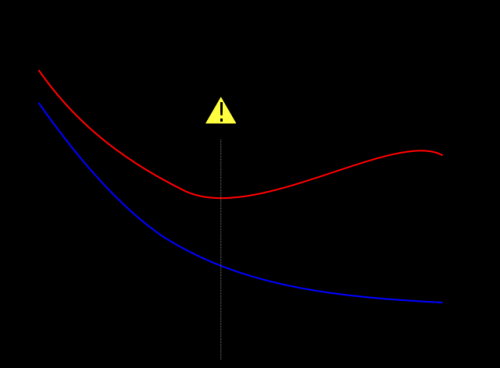
Biorę słynny na całym świecie wykres poniżej z wikipedia aby pokazać, w jaki sposób zestaw walidacji pomaga zapobiegać nadmiernemu dopasowaniu. Błąd szkolenia, w Kolorze Niebieskim, ma tendencję do zmniejszania się wraz ze wzrostem liczby epok: sieć próbuje zatem dopasować zestaw treningowy dokładnie. Błąd walidacji, w kolorze czerwonym, z drugiej strony następuje inny profil w kształcie litery U. Minimum krzywej jest wtedy, gdy idealnie trening powinien zostać zatrzymany, ponieważ jest to punkt, w którym trening i Błąd walidacji są najniższe.
Referencje
Aby uzyskać więcej odniesień ta doskonała książka da ci zarówno solidną wiedzę na temat uczenia maszynowego, jak i kilku migren. Od Ciebie zależy, czy warto. :)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-05-23 12:02:51
-
Podziel dane na K, które nie nakładają się na siebie. Jeśli każdy fold K zawiera taką samą liczbę elementów z każdej z klas m (stratyfikowana weryfikacja krzyżowa; jeśli masz 100 elementów z klasy A i 50 z klasy B i robisz walidację 2 razy, każdy fold powinien zawierać losowe 50 elementów z A i 25 Z B).
-
Dla i w 1..k:
- Oznacz fold i test fold
- wyznaczyć jeden z pozostałych K-1 fałdów fałdu walidacji (może to czy funkcja i jest przypadkowa, nie ma znaczenia)
- wyznacz wszystkie pozostałe fałdy fałdu treningowego
- Wykonaj wyszukiwanie w siatce wszystkich wolnych parametrów (np. szybkość uczenia się, # neuronów w warstwie ukrytej) treningu na danych treningowych i straty obliczeniowe na danych walidacyjnych. Parametry Pick minimalizujące straty
- Użyj klasyfikatora z parametrami wygranej, aby ocenić przegraną testu. Akumuluj wyniki
-
Teraz zebrałeś łącz wyniki we wszystkich fałdach. To twój ostatni występ. Jeśli masz zamiar zastosować to na serio, w dziczy, użyj najlepszych parametrów z wyszukiwania siatki, aby trenować na wszystkich danych.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-09-17 13:06:25