Jak interpretować macierz wiedzy scikita i raport klasyfikacyjny?
Mam zadanie do analizy nastrojów, dla tego im za pomocą tego corpus opinie mają 5 klas (very neg, neg, neu, pos, very pos), od 1 do 5. Więc robię klasyfikację w następujący sposób:
from sklearn.feature_extraction.text import TfidfVectorizer
import numpy as np
tfidf_vect= TfidfVectorizer(use_idf=True, smooth_idf=True,
sublinear_tf=False, ngram_range=(2,2))
from sklearn.cross_validation import train_test_split, cross_val_score
import pandas as pd
df = pd.read_csv('/corpus.csv',
header=0, sep=',', names=['id', 'content', 'label'])
X = tfidf_vect.fit_transform(df['content'].values)
y = df['label'].values
from sklearn import cross_validation
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X,
y, test_size=0.33)
from sklearn.svm import SVC
svm_1 = SVC(kernel='linear')
svm_1.fit(X, y)
svm_1_prediction = svm_1.predict(X_test)
Następnie z metrykami uzyskałem następującą macierz zamieszania i raport klasyfikacyjny, w następujący sposób:
print '\nClasification report:\n', classification_report(y_test, svm_1_prediction)
print '\nConfussion matrix:\n',confusion_matrix(y_test, svm_1_prediction)
To jest wynik:
Clasification report:
precision recall f1-score support
1 1.00 0.76 0.86 71
2 1.00 0.84 0.91 43
3 1.00 0.74 0.85 89
4 0.98 0.95 0.96 288
5 0.87 1.00 0.93 367
avg / total 0.94 0.93 0.93 858
Confussion matrix:
[[ 54 0 0 0 17]
[ 0 36 0 1 6]
[ 0 0 66 5 18]
[ 0 0 0 273 15]
[ 0 0 0 0 367]]
Jak mogę zinterpretować powyższą macierz zamieszania i raport klasyfikacyjny. Próbowałem przeczytać dokumentacja i to pytanie. Ale nadal może zinterpretować to, co się tutaj stało, szczególnie z tymi danymi?. Wny ta matryca jest jakoś "przekątna"?. Z drugiej strony, co oznacza recall, precision, f1score i wsparcie dla tych danych?. Co mogę powiedzieć o tych danych?. Z góry dzięki chłopaki
3 answers
Raport klasyfikacyjny musi być prosty - raport pomiaru P / R / F dla każdego elementu danych testowych. W problemach Multiclass nie jest dobrym pomysłem, aby odczytać precyzję / przypomnienie i F-Measure na całych danych jakikolwiek brak równowagi sprawi, że poczujesz, że osiągnąłeś lepsze wyniki. Właśnie w tym pomagają takie raporty.
Coming to confusion matrix, it is much detailed representation of what ' s going on with your labels. W pierwszej klasie było więc 71 punktów (Etykieta 0). Z tych, twój model udało się zidentyfikować 54 z nich poprawnie w etykiecie 0, ale 17 zostało oznaczonych jako etykieta 4. Podobnie wygląda drugi rząd. W klasie 1 były 43 punkty, ale 36 z nich zostało oznaczonych poprawnie. Twój klasyfikator przewidział 1 w klasie 3 i 6 w klasie 4.
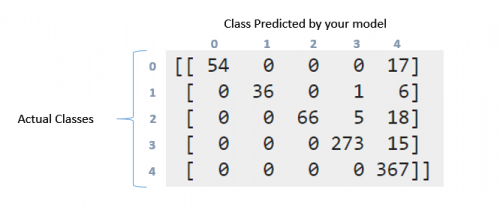
Teraz możesz zobaczyć wzór, który następuje. Idealny klasyfikator ze 100% dokładnością stworzyłby czystą macierz diagonalną, która miałaby wszystkie przewidywane punkty w swojej poprawnej klasie.
Coming to Przypomnienie / Precyzja. Są to niektóre z najczęściej stosowanych środków w ocenie, jak dobry system działa. Teraz miałeś 71 punktów w pierwszej klasie(nazwij to klasą 0). Z nich Twój klasyfikator był w stanie poprawnie uzyskać 54 elementy. To twoje przypomnienie. 54/71 = 0.76. Teraz spójrz tylko na pierwszą kolumnę w tabeli. Jest jedna komórka z wpisem 54, reszta to zera. Oznacza to, że Twój klasyfikator zdobył 54 punkty w klasie 0, a wszystkie 54 z nich były w rzeczywistości w klasie 0. To jest precyzja. 54/54 = 1. Zobacz też kolumna oznaczona numerem 4. W tej kolumnie znajdują się elementy rozrzucone we wszystkich pięciu wierszach. 367 z nich zostało poprawnie oznaczonych. Reszta jest niepoprawna. To zmniejsza twoją precyzję.
Miara F jest średnią harmoniczną precyzji i przypomnienia. Koniecznie przeczytaj szczegóły na ten temat. https://en.wikipedia.org/wiki/Precision_and_recall
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-06-10 05:48:57
Oto dokumentacja dla sklearn scikit-learn.metryki.metoda precision_recall_fscore_support: http://scikit-learn.org/stable/modules/generated/sklearn.metrics.precision_recall_fscore_support.html#sklearn.metrics.precision_recall_fscore_support
Wydaje się wskazywać, że wsparcie to liczba wystąpień poszczególnych klas w prawdziwych odpowiedziach (odpowiedzi w twoim zestawie testowym). Można ją obliczyć sumując wiersze macierzy pomieszania.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-10-11 03:59:25
Macierz zamieszania mówi nam o rozkładzie naszych przewidywanych wartości we wszystkich rzeczywistych wynikach.Accuracy_scores, Recall( sensitivity), Precision, Specificity i inne podobne metryki są podzbiorami macierzy pomieszania. Wyniki F1 są harmonicznymi środkami precyzji i przywoływania. Kolumny wsparcia w Classification_report mówią nam o rzeczywistych liczbach każdej klasy w danych testowych. Cóż, odpoczynek jest pięknie wyjaśniony powyżej. Dziękuję.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-12-03 17:06:18